Evite buscas em cascata no cliente para acelerar seu app
Evite buscas em cascata no cliente executando requisições em paralelo ou agregando-as no servidor, reduzindo o tempo de carregamento e o tempo até a interatividade.
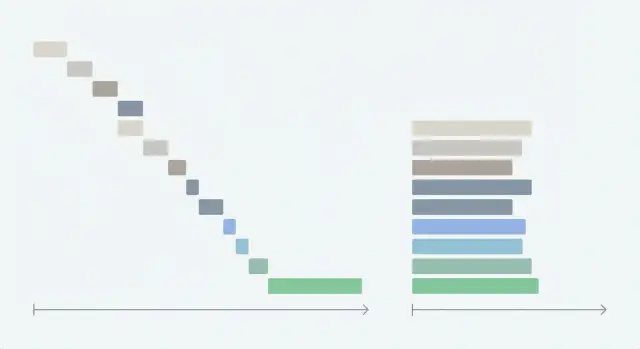
O que são buscas em cascata e por que elas deixam seu app lento
Uma “busca em cascata” acontece quando sua aplicação faz uma requisição de rede, espera ela terminar e então inicia a próxima. Cada requisição adiciona seu próprio atraso, então o tempo total vira a soma de todas as esperas em vez de algo próximo à maior delas.
Isso prejudica o tempo até a interatividade porque a tela muitas vezes não consegue mostrar algo útil até a última requisição retornar. Usuários percebem isso como uma página em branco, um spinner que demora demais, ou uma interface que aparece pela metade e continua se deslocando.
As cascatas geralmente aparecem em alguns padrões repetidos:
- Fetches encadeados onde a requisição B só começa no handler de sucesso da requisição A.
- Renderização ligada à chegada dos dados, de modo que partes mais profundas da página nem montam até os dados anteriores voltarem.
- Componentes aninhados que cada um “faz fetch no mount”, forçando as requisições filhas a esperar pelas dos pais.
- Código “por conveniência” que transforma uma tela em cinco endpoints, mesmo quando os dados sempre são usados juntos.
Isso é especialmente comum em protótipos gerados por IA. Eles geralmente parecem bem numa máquina rápida local, mas ficam lentos em produção porque chamadas sequenciais se acumulam.
A boa notícia é que geralmente você pode evitar buscas em cascata no cliente sem reescrever tudo. Muitas correções são diretas: execute requisições independentes em paralelo, comece a carregar mais cedo e mova o trabalho de coordenação para o servidor quando o cliente estiver fazendo demais.
Como identificar rapidamente uma cascata do lado do cliente
Comece observando a tela como um usuário faria. Cascatas costumam parecer “ocupadas” mas não responsivas.
Uma pista forte é a experiência de carregamento. Se um spinner aparece, some e volta a aparecer, o app provavelmente está esperando uma cadeia. Outro sinal é a UI que chega em etapas: cabeçalho primeiro, depois a barra lateral, depois a tabela, depois os filtros. Essa sensação escalonada normalmente significa que os dados estão chegando uma requisição por vez.
Foque nas telas sobre as quais as pessoas mais reclamam. Cascatas adoram dashboards, páginas de configurações e qualquer visualização com muitas necessidades de dados “pequenos”.
O que procurar no navegador
Abra o DevTools e vá para a aba Network. Recarregue a página e procure:
- Uma longa cadeia onde cada requisição começa só depois da anterior terminar
- Lacunas de inatividade entre requisições (nada acontece enquanto a UI espera)
- Muitas chamadas semelhantes que diferem apenas um pouco
- Requisições que bloqueiam o primeiro conteúdo significativo
- Um “fan-out” que acontece tarde (uma chamada volta e então dispara várias outras)
Depois de identificar uma cadeia suspeita, clique na primeira requisição e verifique o que a disparou (Initiator ou stack trace, dependendo do navegador). Se um fetch em um componente dispara outro fetch em um componente filho, você encontrou o formato de cascata.
Verifique também os logs do backend
Uma cascata também pode aparecer como chamadas repetidas pelos mesmos dados. Um dashboard pode buscar o usuário atual em três componentes diferentes porque cada um “se resguarda” e pede de novo.
Em bases de código geradas por IA, isso é comum: componentes copiam e colam lógica de fetch e acabam criando cadeias e duplicações.
Exemplo: uma tela de dashboard que espera por cinco endpoints
Uma cascata comum no mundo real é um dashboard construído a partir de um protótipo que carrega dados passo a passo. Cada requisição espera a anterior, então a página não se estabiliza.
Imagine que a página faz isso no mount: buscar o usuário, depois o time, depois as permissões, depois a lista de widgets e então os dados de cada widget. Se cada chamada demora 200–400 ms, usuários podem esperar facilmente 1,5–3 segundos antes que a tela pareça utilizável, mesmo numa conexão decente.
Aqui está um conjunto típico de endpoints (nomes variam, o comportamento é o que importa):
GET /api/me(dados de perfil como nome, avatar)GET /api/team(id do time, nome do time)GET /api/permissions?teamId=...(papéis, flags de recurso)GET /api/widgets?teamId=...(quais cards mostrar)GET /api/widgets/:id/data(números, gráficos, itens recentes)
O que faz disso uma cascata não é o número de requisições. É a ordem forçada.
Frequentemente a página espera /api/me antes de começar /api/team, mesmo quando essas chamadas poderiam rodar juntas. Depois espera as permissões antes de renderizar qualquer card, então os usuários ficam olhando uma concha vazia. Mais tarde, os cards aparecem um por um e se deslocam conforme os dados chegam.
Para evitar buscas em cascata no cliente, separe o que é realmente dependente do que foi apenas codificado assim.
Algumas chamadas podem rodar em paralelo (como /api/me e /api/team, e às vezes /api/widgets). Outras são realmente dependentes (como /api/permissions, que precisa de um teamId, e chamadas de dados dos widgets que precisam dos IDs dos widgets).
A ideia principal: normalmente você só precisa de um pequeno conjunto de campos imediatamente para renderizar uma primeira vista estável (cabeçalho, layout, placeholders). Todo o resto pode ser paralelizado ou agrupado.
Vitórias rápidas antes de um grande refactor
Nem sempre é preciso um reescrita completa para evitar buscas em cascata no cliente. Algumas mudanças direcionadas podem cortar segundos do tempo até a interatividade e reduzir a sensação de “pular”.
Comece confirmando o que realmente está lento. No painel Network, ordene por Duration e encontre o endpoint que domina a linha do tempo. É fácil refatorar três chamadas “óbvias” e perder o problema real, como uma checagem de permissões lenta.
Depois, faça a primeira tela utilizável mais cedo. Se um dado não é necessário para a primeira vista significativa (por exemplo, “itens recomendados”, “atividade recente” ou um gráfico pesado), carregue-o depois que o usuário já puder clicar. Pessoas toleram carregamento em segundo plano muito melhor do que uma página em branco.
Um conjunto curto de ganhos rápidos que normalmente compensa:
- Inicie requisições mais cedo (na navegação ou mudança de rota), não só depois que componentes profundos montarem.
- Pare com fetches duplicados buscando dados compartilhados uma vez e reutilizando-os.
- Faça cache em memória por um curto período para que navegações rápidas não repitam as mesmas chamadas.
- Prefetch da próxima tela provável quando o app estiver ocioso, mas apenas se for seguro e não sensível.
- Mova chamadas não críticas para “após o paint”, para que a página fique interativa primeiro.
Exemplo: dashboards frequentemente refazem /me em cada tile porque cada widget pede o usuário separadamente. Uma correção simples é buscar o usuário uma vez no nível da tela e passar para baixo.
Passo a passo: refatorar requisições sequenciais para chamadas paralelas
Comece listando cada requisição que uma tela faz e por que ela existe. Marque cada uma como independente (pode carregar imediatamente) ou dependente (precisa de um ID ou valor da outra resposta).
Uma cadeia comum é: carregar usuário, depois carregar time usando user.teamId, depois carregar projetos usando team.id. Só as chamadas de time e projetos são realmente dependentes. Qualquer outra coisa que não precise desses IDs não deveria ficar presa na cadeia.
1) Mapeie o que pode rodar junto
Agrupe requisições em dois baldes: “pode buscar agora” e “deve esperar por X”. Planeje duas ondas:
- Onda 1: inicie tudo que for independente ao mesmo tempo.
- Onda 2: quando tiver os IDs necessários, inicie também as chamadas dependentes em paralelo.
2) Substitua awaits encadeados por chamadas paralelas
Se você vê await após await para chamadas não relacionadas, esse é seu primeiro alvo de refactor.
async function loadScreenData() {
const [me, flags, notifications] = await Promise.all([
api.get("/me"),
api.get("/feature-flags"),
api.get("/notifications"),
]);
const [team, projects] = await Promise.all([
api.get(`/teams/${me.teamId}`),
api.get(`/teams/${me.teamId}/projects`),
]);
return { me, flags, notifications, team, projects };
}
Mantenha os grupos paralelos pequenos e significativos. Se uma chamada for opcional (como “dicas” ou “notícias”), carregue-a após o primeiro paint.
3) Centralize o carregamento de dados por tela
Em vez de espalhar fetches pelos widgets, crie uma função única “load screen data” (ou um hook no nível da rota) que seja responsável pelos dados da tela.
Isso torna as dependências mais fáceis de entender. Também facilita retry e caching, e evita “cinco spinners” por toda parte.
Busque ter um estado de carregamento por tela quando possível. Usuários normalmente preferem “o dashboard está carregando” a cinco spinners separados que terminam em tempos diferentes.
Meça antes e depois. Acompanhe o tempo até o primeiro conteúdo (quando algo útil aparece) e o tempo até a interatividade (quando os controles respondem).
Quando agregar no servidor em vez de no cliente
Agregação no servidor significa que uma requisição retorna tudo o que a tela precisa, em vez do navegador fazer muitas chamadas pequenas.
Se você quer prevenir buscas em cascata no cliente, isso pode ser a correção mais limpa porque o cliente para de coordenar uma cadeia de requisições dependentes.
A agregação ajuda mais quando:
- A tela precisa de muitos endpoints pequenos.
- A latência é perceptível (usuários móveis, regiões distantes).
- Cada endpoint repete o mesmo trabalho (cheques de auth, verificações de permissão, consultas ao banco).
Cinco requisições que cada uma leva 150–300 ms podem facilmente virar mais de um segundo antes da UI se estabilizar.
Um contrato simples mantém as coisas previsíveis. Por exemplo, um dashboard pode chamar um endpoint e obter o básico em uma resposta:
GET /dashboard->{ profile, team, widgets }
Fique de olho no escopo. Evite agregação quando ela criar um payload enorme, puxar dados raramente usados “por via das dúvidas” ou misturar dados com regras de privacidade diferentes. Outro sinal de alerta é quando a resposta fica tão ampla que uma pequena alteração quebra muitas partes não relacionadas da UI.
Um plano de migração seguro é adicionar o endpoint agregado enquanto mantém os endpoints antigos funcionando. Lance a mudança do cliente atrás de uma feature flag, compare resultados e então migre o tráfego gradualmente. Quando o novo caminho estiver estável, aposente as chamadas antigas.
Reduza o tamanho do payload e chamadas redundantes
Não olhe só para a ordem das requisições. Veja o quão grande cada resposta é e com que frequência você pede pelos mesmos dados. Mesmo requisições perfeitamente paralelas podem parecer lentas se cada resposta for pesada ou repetida.
Corte as respostas da API para apenas o que a tela usa. Se um card precisa de name, status e updatedAt, não envie o registro completo com logs, comentários e descrições longas.
Agrupe consultas semelhantes quando possível. Um padrão comum é buscar uma lista e depois buscar detalhes de cada item um a um. Esse comportamento N+1 adiciona atrasos ocultos e carga extra no servidor. Prefira um endpoint que aceite IDs e retorne os itens correspondentes numa única resposta.
Chamadas redundantes frequentemente vêm de vários componentes pedindo a mesma coisa de forma independente. Um header, sidebar e painel principal podem buscar o usuário atual, plano e feature flags. Coloque dados compartilhados atrás de uma camada única de requisição (ou de uma store) para que sejam buscados uma vez e reutilizados.
Verificações práticas que normalmente compensam:
- Adicione paginação ou limites para que o primeiro carregamento permaneça pequeno.
- Solicite apenas os campos necessários (evite expansões “incluir tudo”).
- Agrupe chamadas “fetch por ID” em uma chamada “fetch por IDs”.
- Desduplique requisições em voo para que dois componentes não disparem duas chamadas idênticas.
- Observe padrões N+1 também no backend (uma chamada de API causando muitas consultas ao banco).
Exemplo: se seu dashboard carrega 200 projetos no primeiro render mas só mostra 20, peça 20 e carregue mais via scroll ou busca.
Estados de carregamento, erros e cache sem novos bugs
Depois de refatorar para evitar buscas em cascata no cliente, o próximo risco são bugs de UX: telas em branco, spinners que não param e dados que piscam ou mudam inesperadamente.
Decida o que realmente bloqueia a interação e o que pode chegar depois.
Separe os dados em dois grupos:
- Dados bloqueantes: necessários para renderizar a estrutura da página ou permitir a primeira ação significativa.
- Dados não bloqueantes: bons de ter, mas seguros para carregar depois que a página estiver utilizável.
Mostre UI parcial sem enganar
Skeletons funcionam melhor quando combinam com o layout final. Use-os para reservar espaço e mostrar a estrutura, depois preencha com os valores reais.
Para widgets pesados (gráficos, editores, mapas), renderize um placeholder leve e carregue o widget depois que o conteúdo principal estiver pronto.
Um padrão simples:
- Renderize o layout imediatamente com padrões seguros
- Mostre skeletons apenas onde os dados vão aparecer
- Carregue widgets pesados depois do conteúdo primário
- Desabilite botões apenas se eles realmente precisarem de dados faltantes
- Prefira texto “última atualização” a um spinner interminável
Erros: falhe pequeno, não alto
Chamadas paralelas significam que algumas requisições podem falhar enquanto outras têm sucesso. Trate falhas por seção, não como “a página inteira quebrou”. Mostre uma pequena mensagem de erro com retry para aquela parte e mantenha o resto interativo.
Evite re-tentativas automáticas em loop apertado. Use backoff e um número máximo de tentativas para não criar tempestades de retry.
O cache ajuda, mas só com regras claras. Decida por quanto tempo os dados são “frescos” (por exemplo, 30 segundos para notificações, 5 minutos para perfil). Quando estiverem stale, você pode mostrar dados em cache instantaneamente e atualizar em background, mas avise se a precisão for importante.
Por fim, proteja-se contra condições de corrida quando usuários se movem rápido. Se o usuário navegar para outra tela, cancele requisições em voo e ignore respostas tardias. Caso contrário, uma resposta antiga pode sobrescrever um estado mais novo.
Erros comuns que trazem cascatas de volta
Cascatas muitas vezes retornam depois de uma refatoração “bem-sucedida” porque o fetching de dados é permitido em muitos lugares. O objetivo não é apenas chamadas paralelas uma vez. É manter a arquitetura do app de modo que ela continue paralela com o tempo.
1) Fetches ocultos dentro de componentes aninhados
Uma armadilha comum é mover a tela principal para requisições paralelas, mas deixar componentes filhos que ainda fazem fetch no mount. A página parece ok localmente, então um novo widget é adicionado e o cliente silenciosamente começa a esperar por ele.
Uma regra simples ajuda: faça fetch em um nível (rota ou tela) e passe dados para baixo. Se um componente realmente precisa ser dono dos seus dados, torne essa decisão explícita e mensurável.
2) Requisições “dependentes” que na verdade não são
Times às vezes encadeiam chamadas porque parece mais seguro. Mas frequentemente a requisição B só precisa de um pequeno pedaço de A (como um ID) que você já tem, ou poderia obter antes.
Um teste rápido: “Se A falhar, B ainda pode rodar?” Se sim, elas não são verdadeiramente dependentes.
3) Parallelar demais e sobrecarregar o backend
Paralelo é bom até virar um pico de requisições. Lançar 20 requisições de uma vez pode acionar limites de taxa, deixar o banco lento ou causar retries que adicionam ainda mais atraso.
Mantenha o paralelismo controlado:
- Limite a concorrência (por exemplo, 4–6 ao mesmo tempo)
- Desduplique chamadas idênticas entre componentes
- Cacheie dados estáveis (como o usuário atual)
- Adicione backoff para retries
4) O mega-endpoint que retorna informação demais
A agregação no servidor pode ajudar, mas um endpoint único que retorna “tudo” tende a crescer até se tornar o novo gargalo. O cliente faz uma chamada só, mas essa chamada fica pesada, lenta de calcular e difícil de cachear.
5) Viagens extras por cheques de auth
Se a autenticação é verificada tardiamente, você pode acabar com: carregar página, receber 401, renovar token, re-tentar todas as requisições.
Deixe o estado de auth disponível cedo e evite disparar requisições até saber que a sessão é válida.
Checklist rápido antes de enviar a refatoração
Faça uma última passada focada no tempo do usuário, não só em código mais limpo. Cascatas podem reaparecer por pequenas mudanças como um novo call de feature flag ou um fetch “por via das dúvidas”.
Percorra a tela principal como um usuário de primeira vez em cold load (cache vazio). Se a página não mostrar algo útil até muitas chamadas terminarem, você provavelmente ainda tem uma cadeia oculta.
Um checklist pré-ship curto:
- Comece com uma ou duas requisições “essenciais” e carregue o resto depois que o primeiro conteúdo for visível.
- Inicie chamadas independentes no mesmo momento (mesmo tick), não depois que outra promise resolver.
- Tenha um dono claro para o carregamento de dados da tela (uma função ou hook único).
- Remova duplicatas por design (cache cliente compartilhado, loaders memoizados ou uma resposta agregada).
- Reavalie o timing de Network e o tempo até a interatividade após a refatoração usando o mesmo throttling.
Um rápido teste de realidade: se seu dashboard dispara profile, permissions e workspace em paralelo e já mostra header e navegação rápido, deve permanecer assim. Se um novo badge de “status de cobrança” depois esperar permissões antes de começar, você introduziu uma nova mini-cascata.
Próximos passos: deixe seu app rápido e confiável no carregamento
Se seu app ainda parecer lento após refatorar, assuma que há mais cascatas escondidas. Isso é comum em bases de código geradas por IA, onde um componente de tela parece limpo mas um hook embaixo está encadeando requisições, repetindo chamadas a cada render ou refazendo os mesmos dados para cada linha.
Escolha uma tela real que os usuários usam (geralmente um dashboard ou home) e meça uma coisa: quanto tempo até a primeira tela utilizável aparecer. Então planeje a menor mudança que mova esse número.
Uma auditoria focada ajuda a evitar “correções de velocidade” que geram novos bugs. Procure por:
- Fetches encadeados disparados por updates de estado (fetch A seta estado, que dispara fetch B)
- Requisições N+1 (um request de lista mais um por item)
- Chamadas repetidas causadas por falta de memoização ou dependências instáveis
- Endpoints do servidor que retornam dados demais, forçando parsing e render lento
- Atalhos arriscados que surgem em refactors (como segredos no cliente ou construção insegura de queries)
Se você herdou código gerado por IA e quer uma segunda opinião, FixMyMess (fixmymess.ai) faz diagnóstico e correções em codebases quebradas por ferramentas de IA, incluindo desembaraçar cadeias sequenciais de fetch e otimizar chamadas de API para que telas carreguem de forma previsível em produção.
Perguntas Frequentes
What is a client-side waterfall fetch in plain terms?
Uma busca em cascata acontece quando sua aplicação inicia a requisição B somente depois que a requisição A termina, mesmo que ambas pudessem rodar ao mesmo tempo. Essa ordem forçada faz o tempo total somar, e costuma aparecer como um spinner longo, um esqueleto em branco ou uma interface que vai aparecendo aos poucos.
How can I quickly confirm I have a waterfall in the browser?
Abra o DevTools → Network, recarregue a página e procure por uma cadeia em que cada requisição começa depois que a anterior termina. Fique de olho também em lacunas de inatividade e no “fan-out”, quando uma resposta dispara várias requisições depois; esse padrão de tempo normalmente indica que seu código está coordenando requisições tarde demais.
What’s the fastest fix for sequential `await` calls?
Se as requisições são independentes, troque await sequenciais por Promise.all para que comecem juntas. Se algumas dependem de IDs, execute tudo que for possível na “onda 1” e, quando tiver os IDs, dispare as dependentes em paralelo na “onda 2”.
How do I stop multiple components from re-fetching the same data?
Busque os dados uma vez no nível da tela ou rota e passe o resultado para baixo, em vez de permitir que vários componentes aninhados façam fetch no mount. Isso reduz chamadas duplicadas e evita cadeias ocultas em que componentes filhos começam a carregar só depois dos pais renderizarem.
What data should load first versus in the background?
Carregue primeiro os dados mínimos “bloqueantes” para que o layout e as interações principais apareçam, e deixe dados não críticos (por exemplo, gráficos, recomendações ou tabelas pesadas) carregarem em segundo plano após o primeiro paint.
How do I make loading feel smooth after parallelizing requests?
Use skeletons que reflitam o layout final para evitar saltos visuais quando os dados chegam. Evite empilhar spinners; prefira um estado de carregamento claro por tela e marcadores menores por seção, assim o conteúdo parcial pode aparecer sem parecer quebrado.
What’s the right way to handle errors when requests run in parallel?
Trate falhas por seção e mantenha o resto da tela utilizável, já que chamadas paralelas podem falhar independentemente. Ofereça um pequeno botão de retry para a parte com erro e evite loops agressivos de auto-retry que deixem a UI presa ou sobrecarreguem seu backend.
When should I aggregate data on the server instead of the client?
Quando a tela precisa de muitos endpoints pequenos, a latência é notável ou cada endpoint repete o mesmo trabalho de auth/permission, faz sentido agregar no servidor. Um endpoint único que retorna os dados principais da tela remove a coordenação no cliente, mas mantenha o escopo sob controle para não criar um payload enorme ou um endpoint frágil demais.
How do I avoid N+1 requests on a dashboard or list view?
É quando você busca uma lista e depois busca detalhes para cada item um a um, o que gera muitas requisições extras. Corrija com um endpoint em lote (fetch por IDs) ou retornando os campos necessários na resposta inicial da lista, evitando a cascata.
Why do AI-generated codebases get waterfall fetches so often, and what can I do if I inherited one?
Protótipos gerados por IA frequentemente espalham fetches por muitos componentes, copiam e colam lógica de requisição e acidentalmente encadeiam chamadas via atualizações de estado. Se você herdou um app gerado por IA (Lovable, Bolt, v0, Cursor, Replit) e ele parece rápido localmente mas lento em produção, FixMyMess pode auditar o código e desfazer cadeias de fetch, duplicações e padrões arriscados de API com uma auditoria grátis e a maioria das correções feita em 48–72 horas.