Evite registros de usuário duplicados com restrições únicas e preenchimento retroativo seguro
Aprenda a evitar registros de usuário duplicados usando restrições únicas, normalização de entrada e um plano de backfill seguro que evita downtime e perda de dados.
O problema real: por que usuários duplicados continuam acontecendo
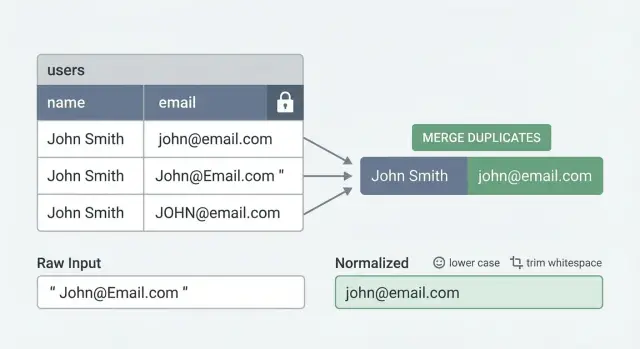
Usuários duplicados raramente aparecem como o mesmo e‑mail digitado duas vezes. Normalmente surgem como pequenas diferenças que humanos tratam como a mesma pessoa, mas que o banco de dados vê como valores diferentes.
Exemplos comuns:
- Mesmo e-mail, caixa diferente:
[email protected]vs[email protected] - Espaços invisíveis:
[email protected]vs[email protected] - Múltiplos métodos de login: uma conta criada com senha, outra depois com Google ou GitHub usando o mesmo e‑mail
- Pontos de criação diferentes: um registro criado durante o checkout e outro durante o onboarding
- Particularidades de provedores:
[email protected]usado uma vez,[email protected]usado outra vez (alguns apps querem tratar como a mesma pessoa, outros não)
O resultado parece aleatório para os clientes. Alguém faz login com “o outro” método e cai na “outra” conta. Cobranças se dividem, então um usuário pago pode parecer não pago. Atendimento vira investigação porque “não vejo meus projetos” é na verdade “você tem duas contas e seus dados estão na outra.” Analytics fica barulhenta também, então retenção e conversão deixam de ser confiáveis.
Equipes geralmente tentam impedir duplicados na UI: desabilitar o botão, mostrar “e‑mail já existe”, ou checar antes de criar o usuário. Isso ajuda, mas não basta. Seu banco pode ser escrito por apps móveis, APIs backend, painéis administrativos, imports, jobs em background, webhooks e retries após timeouts. Duas requisições também podem competir: ambas checam “esse e‑mail existe?” ao mesmo tempo, ambas veem “não” e ambas inserem.
A proteção no nível do banco é diferente. O banco aplica a regra sempre, não importa de onde venha a escrita. Você define o que deve ser único (frequentemente um e‑mail normalizado, ou uma combinação como provider + provider_user_id) e o banco rejeita inserts ou updates que criariam um segundo registro com a mesma identidade. Esse guarda‑corpo é o que transforma “tentamos não duplicar usuários” em “duplicados não podem mais acontecer”.
Formas comuns de criação de duplicados
Registros de usuários duplicados aparecem quando o app assume que o banco vai “dar conta”. Se o banco não está aplicando unicidade, casos de borda viram muitas linhas para a mesma pessoa, e você acaba tentando evitar duplicatas apenas com código de aplicação.
Uma causa frequente é condição de corrida durante o cadastro. Duas requisições podem chegar quase ao mesmo tempo (duplo clique, conexão instável, duas abas). Se ambas fazem “verifica se usuário existe” antes de inserir, as duas decidem que o usuário é novo.
Outra fonte comum são múltiplos pontos que criam usuários: web, mobile, painel admin, import CSV, fluxo de convite, ferramenta de suporte. Cada caminho evolui suas próprias regras. Um remove espaços, outro não. Um checa por usuário existente, outro pula a checagem “só para essa feature”.
OAuth também pode separar identidades. Um usuário se cadastra com e‑mail e senha e depois clica em “Continuar com Google” usando o mesmo e‑mail. Se o callback do OAuth cria uma nova linha em vez de vincular à existente, você terá duas contas válidas.
Diferenças na formatação das entradas criam duplicados sorrateiros:
- Diferenças de caixa e espaços no e‑mail (
[email protected]vs[email protected]) - Formatação de telefones (
+1 555 123 4567vs5551234567) - Campos opcionais que aparecem depois (usuário começa com telefone, adiciona e‑mail depois)
- Variações internacionais (códigos de país, zeros à esquerda)
- Unicode lookalikes (raro, mas real)
Retries e timeouts também fazem isso. Se um cliente não recebe resposta (problema de rede, timeout de gateway), ele pode tentar novamente automaticamente. Se seu servidor tratar cada retry como um cadastro novo em vez da mesma intenção, você ganha duplicados. Isso é comum em protótipos onde a lógica de cadastro é copiada entre rotas sem idempotência ou constraints no banco.
Defina o que “usuário único” significa para seu produto
Antes de adicionar constraints, decida o que “usuário único” significa no seu sistema. A maioria das duplicações acontece porque o produto tem mais de uma ideia de identidade.
Comece com os identificadores em que você confia: e‑mail, telefone e IDs de provedores externos (sub do Google, id do GitHub, sub do SSO empresarial). Se você suporta múltiplos métodos de login, decida se todos apontam para uma única linha de usuário, ou se cada método pode criar sua própria linha que depois é ligada.
Depois trate os casos confusos explicitamente:
- E se o e‑mail estiver vazio, não verificado, ou oculto (Apple private relay)?
- Você permite usuários guest que nunca se cadastram?
- Se o e‑mail pode ser
NULL, múltiplosNULLsão permitidos (frequentemente sim) e como um guest vira conta real?
Escopo por tenant/workspace importa igualmente. A unicidade é global ou por tenant? Em muitos apps B2B, o mesmo e‑mail pode existir em workspaces diferentes, mas deve ser único dentro de um workspace. Em um app consumidor, normalmente você quer unicidade global.
Um cenário concreto para decidir: alguém se cadastra com Google na segunda e depois com e‑mail/senha na terça usando o mesmo e‑mail. Se sua definição é “uma pessoa = uma linha”, você precisa de uma regra de merge e precisa documentá‑la.
Uma política simples de merge:
- Escolha um registro “primário” (e‑mail verificado vence; caso contrário último login ativo).
- Mantenha campos sensíveis de segurança do primário (hash de senha, configurações MFA).
- Mescle campos de perfil (nome, avatar) somente se estiverem faltando no primário.
- Reponte dados relacionados (pedidos, memberships, chaves API) para o primário.
- Deixe uma nota de auditoria para explicar o que aconteceu.
Escreva essas regras em linguagem simples antes de tocar no banco. Isso alinha engenharia, suporte e produto quando casos reais aparecerem.
Normalize entradas para que o banco possa impor unicidade
Constraints únicas só funcionam se os valores que você grava forem consistentes. Se uma pessoa pode se cadastrar como [email protected], [email protected] e [email protected], o banco vê três strings diferentes.
Normalizar significa escolher um formato de armazenamento para “a mesma” identidade e gravar sempre nesse formato. Esse é o passo silencioso que faz um constraint único realmente funcionar.
O que normalizar (e o que ter cuidado)
Para e‑mail, comece simples: remova espaços e aplique lowercase antes de salvar. Decida o que fazer com plus‑addressing ([email protected]). Algumas equipes removem a parte +... para reduzir duplicados, mas isso é específico do provedor e nem sempre seguro. Um padrão mais seguro é lowercase + trim, e só adicionar tratamento de plus se você tiver certeza de que faz sentido para seu produto.
Para telefones, armazene um formato consistente, idealmente com código de país e apenas dígitos. Caso contrário +1 (415) 555-0123 e 4155550123 podem escapar da unicidade.
Para usernames, faça o mesmo que o comportamento do seu produto. Se a UI trata Jane e jane como iguais, o backend deve normalizar do mesmo jeito antes do insert.
Um padrão prático é armazenar ambos:
- Entrada bruta (o que o usuário digitou, útil para exibição e suporte)
- Valor normalizado (sobre o qual você aplica unicidade)
Aplicação no backend vence dicas de frontend
Normalize no backend sempre que criar ou atualizar um usuário. Verificações no frontend ajudam a UX, mas são fáceis de contornar (clientes antigos, múltiplos apps, chamadas diretas à API).
Um modo comum de falhar: um fundador importa usuários de um CSV enquanto cadastros acontecem. O import mantém a capitalização original, o formulário de signup aplica lowercase, e agora você tem duas contas com o mesmo e‑mail. Normalização no backend mais constraint normalizada impede essa divisão.
Escolha a constraint certa para seu esquema
Uma constraint única é uma regra que o banco aplica: duas linhas não podem compartilhar o mesmo valor “único”. Um índice único é a máquina que torna a checagem rápida. Muitos bancos criam um índice único nos bastidores ao adicionar uma constraint, então a diferença prática é principalmente de intenção e tooling.
A parte difícil é escolher as colunas certas. “E‑mail deve ser único” soa simples, mas quebra rápido quando você adiciona times, vários provedores, e‑mails opcionais ou soft deletes.
Quando usar unicidade composta
Se usuários pertencem a um workspace/tenant, muitas vezes você quer unicidade dentro desse tenant, não global. Isso vira uma regra composta, como:
tenant_id + email_normalized(mesmo e‑mail pode existir em tenants diferentes)provider + provider_user_id(identidade verdadeira para logins OAuth)tenant_id + provider + provider_user_id(comum quando a mesma identidade de provedor pode entrar em vários tenants)
Unicidade composta também ajuda quando você suporta login por senha e OAuth. Você pode impor regras fortes para cada tipo de identidade sem forçar um campo (como e‑mail) a fazer todo o trabalho.
Unicidade parcial e soft deletes
Dados reais são bagunçados. Alguns usuários não têm e‑mail ainda, ou você permite contas somente por telefone. Nesse caso, imponha unicidade apenas quando o valor existir (uma regra parcial). Um exemplo comum é “e‑mail deve ser único, mas só para linhas onde o e‑mail está presente”.
Soft deletes adicionam outra decisão. Se você marca usuários como deletados em vez de removê‑los, codifique uma regra:
- Único entre usuários ativos (permitir novo cadastro com o mesmo e‑mail)
- Único entre todos os usuários, incluindo deletados (impede reuso e mantém o histórico simples)
Planeje os duplicados de hoje antes da imposição
Habilitar unicidade quando já existem duplicados vai falhar, ou vai bloquear cadastros no pior momento. Antes de impor qualquer coisa, inventarie duplicados, decida qual registro “vence” e garanta que referências (sessões, pedidos, memberships) possam ser movidas com segurança.
Passo a passo: ativando unicidade sem downtime
O objetivo é evitar registros duplicados sem congelar cadastros ou bloquear logins. A abordagem mais segura é adicionar os componentes primeiro, preencher aos poucos, corrigir casos problemáticos e só então pedir ao banco para aplicar a regra.
Sequência segura de rollout
Comece adicionando uma chave normalizada que o banco possa comparar de forma confiável. Para e‑mail, isso normalmente significa uma versão lowercase e sem espaços (mais quaisquer regras extras do seu produto).
Um rollout prático:
- Adicione uma nova coluna para o valor normalizado (ex:
email_normalized) e atualize seu app para que todo novo cadastro graveemaileemail_normalized. - Backfille
email_normalizedpara usuários existentes em pequenos lotes (faixas de ID ou janelas de tempo) para que cada lote termine rápido. - Rode detecção de duplicados usando a chave normalizada e agrupe colisões (por exemplo, todas as linhas onde
email_normalized = "[email protected]"). - Resolva cada grupo antes de impor unicidade: escolha um vencedor, mescle os dados necessários e marque os outros como mesclados/desativados.
- Adicione o índice/constraint único só depois que os duplicados desaparecerem, usando uma opção online quando seu banco suportar.
Exemplo concreto: um protótipo pode armazenar [email protected], [email protected] e [email protected] como três usuários diferentes. Depois de backfill email_normalized = "[email protected]", esses colidem e viram um único grupo que você pode mesclar.
Minimizar locks e surpresas
A maior parte do downtime acontece quando uma mudança força locks longos em tabelas. Mantenha cada operação rápida e previsível.
Algumas regras que ajudam:
- Backfille com tamanho de lote e timeout rígidos. Se um lote não terminar rápido, torne‑o menor.
- Mantenha o app gravando valores normalizados antes de começar o backfill. Caso contrário novas linhas continuam chegando com nulos e você nunca alcança a consistência.
- Monitore “novos duplicados por hora” durante o rollout. Se subir, algo ainda está gravando chaves inconsistentes.
- Crie o índice único de forma a evitar bloqueios de escrita (por exemplo, criação “concurrent/online”, dependendo do banco).
Plano de backfill: encontrar e mesclar duplicados com segurança
Backfill é menos sobre SQL chique e mais sobre ter cuidado com identidade. O objetivo é simples: escolher um registro para manter, mover tudo para ele e deixar um rastro claro.
Comece listando duplicados usando a mesma chave normalizada que você quer impor depois (por exemplo, e‑mail lowercased e trim). Faça isso primeiro em modo somente leitura e exporte os grupos para revisão.
-- Example: find duplicate emails by normalized value
SELECT
LOWER(TRIM(email)) AS email_norm,
COUNT(*) AS user_count,
ARRAY_AGG(id ORDER BY created_at) AS user_ids
FROM users
WHERE email IS NOT NULL
GROUP BY LOWER(TRIM(email))
HAVING COUNT(*) > 1
ORDER BY user_count DESC;
Para cada grupo de duplicados, escolha um usuário “primário”. Uma regra prática é manter a conta que parece real e ativa. Critérios úteis: e‑mail verificado, atividade mais recente e status de assinatura paga.
Depois mescle em uma ordem previsível para não perder dados:
- Trave o grupo duplicado (ou rode o merge em uma transação) para impedir novas escritas durante a movimentação.
- Reponte registros relacionados (pedidos, projetos, memberships, chaves API, tickets) de
duplicate_user_idparaprimary_user_id. - Resolva conflitos campo a campo (mantenha e‑mail verificado, mantenha dados de perfil mais recentes, mantenha o maior nível de privilégio).
- Escreva uma linha de auditoria:
duplicate_user_id -> primary_user_id, quando aconteceu, quem/qual processo executou. - Desative o usuário não primário (soft‑delete) e só hard‑delete mais tarde se tiver certeza de que nada depende dele.
Credenciais e e‑mails requerem cuidado especial. Se o usuário primário manter o e‑mail, remova ou deixe nulo o e‑mail no registro não primário para que ele não possa mais ser usado para login. Para senhas, sessões e identidades OAuth, migre apenas se tiver certeza de que pertencem à mesma pessoa; caso contrário revogue sessões nas contas não primárias e force um novo login.
Não quebre o login: lidando com auth e sessões durante merges
Uma mesclagem não é só mover dados de perfil. O login depende frequentemente de IDs de usuário que estão embutidos em sessões, refresh tokens, links de reset e webhooks de terceiros. Mescle duas contas e ignore essas referências, e as pessoas podem enfrentar loops de login ou erros de “conta não encontrada”.
Um padrão seguro é manter uma conta primária e tratar cada duplicado como um alias que aponta para ela. Quando alguém faz login por uma conta mesclada, você resolve para a primária e continua sem alterar o que o usuário digitou.
Redirecione duplicados para o usuário primário
Mantenha um pequeno lookup (até uma tabela) tipo merged_user_id -> primary_user_id. Em cada leitura de auth, verifique esse mapeamento e reescreva o user ID para o primário antes de criar uma nova sessão. Isso evita loops porque o sistema nunca cria sessões para contas que não “existem” mais.
Essa abordagem de alias também dá tempo para migrar clientes antigos sem indisponibilidade.
Tokens, resets e integrações: o que atualizar
Antes de acionar a mudança, decida o que você vai invalidar versus migrar:
- Sessões e refresh tokens: ou os reprojete para o user ID primário, ou os revogue e force um novo login.
- Tokens de “lembrar‑me”: rode a rotação no próximo login para evitar falhas silenciosas.
- Resets de senha e verificação de e‑mail: gere novos links atrelados à conta primária; não deixe links antigos apontando para um ID mesclado.
- Integrações externas: se um parceiro armazenou seu ID antigo, mantenha resolução de alias para que eventos entrantes sejam atrelados ao usuário primário.
- Logs de auditoria: mantenha os IDs históricos, mas exiba a identidade primária na UI administrativa para reduzir confusão.
Exemplo: se Anna criou duas contas com o mesmo e‑mail (uma via Google e outra via senha), o merge deve manter a sessão atual funcionando e qualquer reset futuro deve apontar apenas para a conta primária.
Erros comuns que causam outages ou perda de dados
A maioria dos outages acontece quando o banco é instruído a impor uma regra que os dados ainda não satisfazem. Uma constraint única é implacável: se um único duplicado existir, escritas começam a falhar, filas enchem e cadastros podem cair.
Um exemplo comum: uma equipe adiciona um índice único em users.email numa sexta, assumindo “não temos duplicados”. Durante a noite, um job antigo de import reexecuta e insere o mesmo e‑mail com capitalização diferente. Na segunda, cadastros dão 500 e o suporte é inundado.
Erros que trazem problemas:
- Ativar constraint única antes de limpar duplicados existentes.
- Normalizar em um caminho de código, mas não em outros (web aplica lowercase, import/admin não aplica).
- Assumir que o e‑mail sempre existe ou está verificado (contas só por telefone e logins sociais existem; usuários mudam de e‑mail).
- Mesclar usuários sem atualizar chaves estrangeiras por toda parte (pedidos, memberships, logs de auditoria, chaves API, sessões, campos
created_by). - Descartar dados silenciosamente durante merges sem plano de rollback.
Trate a deduplicação como uma migração de dados reversível, não como um script de limpeza. Mantenha ambos os registros, registre o que mudou e só delete quando puder provar que nada depende do registro antigo.
Uma abordagem de segurança simples que funciona bem:
- Logue cada decisão de merge (id vencedor, id perdedor, campos escolhidos, timestamp).
- Mova referências em lotes e verifique contagens antes e depois.
- Adicione um mapeamento canônico de usuário para que antigos ids ainda resolvam durante a transição.
- Teste todos os caminhos de escrita (app, admin, imports, workers) usando a mesma função de normalização.
Checklist rápido e próximos passos
Comece pela consistência. Seu banco só pode te proteger se todo caminho de escrita produzir a mesma “chave única”.
Checklist:
- Confirme que regras de normalização são aplicadas em todo caminho de escrita (signup, invite, criação admin, OAuth, imports, background jobs).
- Rode uma varredura de duplicados usando a chave normalizada e revise os resultados com o time.
- Teste a lógica de merge em uma amostra pequena e real primeiro e confirme o que acontece com perfis, memberships, assinaturas e logs de auditoria.
- Limpe duplicados completamente e só então habilite a aplicação no banco (índice/constraint único) depois que os dados estiverem seguros.
- Adicione monitoramento para novos conflitos (violações de constraint) para que você descubra problemas pelos logs, não pelos usuários.
Escolha um dono e um cronograma. “Dedupe” fica preso quando é vago. Torne concreto: defina o registro canônico, como reprojetar chaves estrangeiras e o que fazer quando dois registros discordam (nome, telefone, dados de cobrança, último login).
Um ensaio simples ajuda: pegue 50 clusters de duplicados da produção, rode seu merge em uma cópia de staging e verifique se usuários ainda conseguem entrar, ver o workspace correto e completar resets de senha.
Se você herdou um app gerado por IA e duplicatas continuam aparecendo porque constraints e normalização nunca foram aplicadas de ponta a ponta, FixMyMess (fixmymess.ai) pode ajudar diagnosticando cada caminho de criação de usuário, reparando auth e lógica de merge, e levando você a uma configuração de unicidade aplicada pelo banco sem quebrar logins.
Perguntas Frequentes
Por que continuam aparecendo contas duplicadas mesmo que verifiquemos no UI?
Porque os duplicados normalmente são criados por múltiplos caminhos de escrita e por problemas de timing, não apenas por alguém digitar o mesmo e-mail duas vezes. Duas requisições podem competir, imports podem ignorar checagens, callbacks de OAuth podem criar novas linhas, ou uma tentativa após timeout pode executar novamente o fluxo de cadastro. Só uma regra no banco bloqueia duplicatas independentemente de onde a escrita veio.
Qual a forma mais simples de evitar e-mails duplicados causados por caixa ou espaços?
Normalize o valor sobre o qual você aplica unicidade. Para e-mail, um padrão sólido é trim + lowercase no backend sempre que criar ou atualizar um usuário, e então aplicar unicidade na coluna normalizada. Mantenha o e-mail original também se quiser mostrar exatamente o que o usuário digitou.
Devemos aplicar unicidade por e-mail ou pelo provider user ID do OAuth?
Para OAuth, normalmente sim: imponha unicidade sobre a identidade do provedor, não só sobre o e-mail. Armazene e imponha algo como provider + provider_user_id para que uma identidade do Google não crie várias linhas, e então vincule essa identidade ao registro de usuário existente se o e-mail corresponder às suas regras de merge.
Devemos tratar o plus-addressing do Gmail como o mesmo usuário?
Por padrão, não remova o trecho de plus-addressing a menos que você tenha certeza de que faz sentido para seu produto. Algumas equipes querem que [email protected] e [email protected] sejam a mesma pessoa, mas isso é específico de provedores (Gmail) e pode surpreender usuários em domínios que não suportam esse comportamento. Comece com lowercase+trim e adicione regras específicas por provedor só se necessário.
Como tratar unicidade em um app multi-tenant?
Se seu produto tem workspaces/tenants, a unicidade costuma ser escopada ao tenant. Isso significa impor tenant_id + email_normalized para que o mesmo e-mail possa existir em workspaces diferentes, mas nunca duas vezes dentro do mesmo workspace. Apps consumidores normalmente usam unicidade global.
E usuários soft-deleted — alguém pode reutilizar o mesmo e-mail depois?
Decida a política primeiro e depois codifique-a na constraint. Uma escolha comum é “único entre usuários ativos”, o que permite que alguém se cadastre novamente após exclusão, mas exige uma constraint parcial baseada em um flag active ou deleted_at. Se você precisa de histórico estrito e quer evitar reuso, imponha unicidade entre ativos e deletados.
Como aplicar uma constraint única sem downtime?
Adicione a coluna normalizada e comece a gravá-la para novos cadastros antes de mais nada, depois backfille usuários existentes em pequenos lotes. Detecte colisões usando a chave normalizada, mescle ou desative duplicados e só então crie o índice/constraint único usando a opção online/concurrent se o banco suportar. Essa sequência evita a queda causada por "ligar a constraint e cadastros começarem a falhar".
Como mesclamos usuários duplicados sem quebrar login ou assinaturas?
Escolha um usuário primário, reproponha todos os registros relacionados para esse primário e mantenha um mapeamento explícito merged-to para que IDs antigos ainda resolvam durante a transição. Sessões, tokens de refresh, resets de senha e links de verificação precisam de cuidado especial; o padrão mais seguro é redirecioná-los ou reemití-los para a conta primária para que usuários não fiquem presos em loops de login.
Como evitar duplicados causados por retries, timeouts ou cadastros duplos?
Crie uma chave de idempotência para a intenção de cadastro e trate retries como a mesma operação, não como uma nova criação. Mesmo com idempotência, mantenha a constraint única no banco, porque condições de corrida e requisições paralelas ainda podem acontecer. A combinação previne repetições acidentais e problemas de concorrência reais.
Herdamos um app gerado por IA e há duplicatas por todo lado — qual a forma mais rápida de consertar?
Trate como problema de dados e de auth/modelagem. FixMyMess (fixmymess.ai) pode auditar cada caminho de criação de usuário, implementar normalização no backend, adicionar as constraints corretas e executar um plano seguro de backfill/merge para que duplicados parem sem quebrar logins. Quando o código herdado gera usuários inconsistentes, muitas vezes é mais rápido corrigir os fluxos de ponta a ponta do que remendar rota por rota.