Exaustão do pool de conexões do banco de dados: ajustes para serverless
Entenda por que a exaustão do pool de conexões pode acontecer mesmo com tráfego leve e como ajustar pooling para serverless vs servidores long-lived para evitar outages.
Como a exaustão do pool de conexões se manifesta em produção
Exaustão do pool de conexões significa que seu app não consegue obter uma conexão ao banco de dados quando precisa. As requisições se acumulam, o app espera e então desiste após um timeout. Para os usuários, parece que o site quebra aleatoriamente.
A maioria das equipes percebe primeiro como “tudo está lento” mesmo que CPU e tráfego pareçam normais. Páginas que normalmente carregam em um segundo ficam presas por 10 a 30 segundos e depois falham. Geralmente atinge fluxos sensíveis primeiro: login, checkout, salvar um formulário.
Os sintomas para usuários costumam ser:
- Páginas lentas que às vezes voltam ao normal ao atualizar
- Erros 500 aleatórios que somem e reaparecem
- Falhas de login ou sessões que caem
- Jobs em background que param de progredir
- Apps móveis dando timeout em ações simples
No lado de engenharia, o padrão é mais específico: filas de requisições crescem, mais tempo é gasto esperando o banco, e os logs mostram erros como “timeout acquiring connection”. No banco, conexões ativas podem ficar próximas do limite ou apresentar picos curtos.
A parte confusa é o descompasso: o tráfego pode parecer “leve” enquanto o sistema está preso aguardando.
Uma causa comum é que algumas poucas requisições seguram conexões por mais tempo do que o esperado. Uma query lenta, uma transação deixada aberta ou código que esquece de liberar um cliente pode travar o pool. Depois disso, mesmo alguns usuários podem causar um engarrafamento.
Por que acontece mesmo com tráfego leve
“Usuários online” não é a mesma coisa que “conexões ativas ao banco”. A maioria dos bancos permite menos conexões concorrentes do que se imagina, e cada conexão custa memória e CPU.
No Postgres, max_connections frequentemente é configurado de forma conservadora. Mesmo um limite como 100 pode ser alto demais na prática se cada conexão for pesada. Some ferramentas administrativas, workers em background, migrations e scripts ocasionais, e você pode ficar sem conexões mais cedo do que imagina.
Além disso, uma única requisição pode tocar o banco várias vezes: a query principal, uma escrita de analytics, atualização de sessão e talvez enfileirar um job. Se isso não for gerenciado com cuidado, “tráfego leve” ainda gera muito trabalho concorrente.
A exaustão do pool geralmente vem de um (ou mais) destes:
- Conexões vazadas após erros ou timeouts, que nunca retornam ao pool
- Queries lentas que seguram conexões por mais tempo, forçando outras requisições a enfileirar
- Retries que multiplicam o tráfego (retries do cliente, do servidor ou do ORM)
- Ruído de background como bots, cron jobs, health checks, polling de filas
- Tarefas de startup ou migrations abrindo conexões extras em momentos ruins
Um exemplo concreto: você tem 10 usuários, mas um endpoint às vezes executa uma query de 4 segundos. Com um pool de 10, um pequeno pico (por refreshes, retries ou um bot) pode ocupar todas as conexões. Novas requisições então esperam, atingem o timeout do pool, falham, reencenam o retry e pioram o pico.
Incidentes sob “tráfego leve” geralmente são sobre tempo de vida das conexões e concorrência, não sobre contagem bruta de requisições.
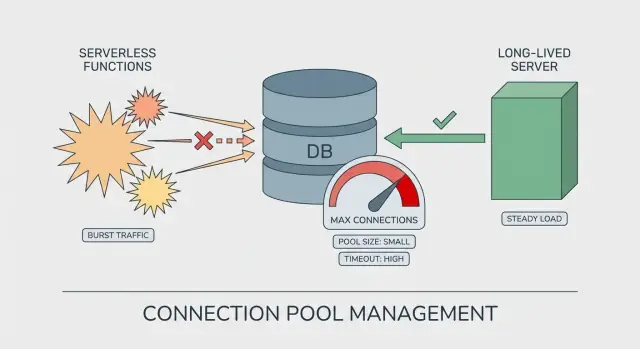
Serverless vs servidores long-lived: a diferença no pooling
Em um servidor de longa duração (VM, container, app server clássico), o processo fica ativo por horas ou dias. O pool do banco é reutilizado por muitas requisições. Ele “aquece”, se estabiliza e você pode raciocinar sobre quantas conexões existem a qualquer momento.
Serverless é diferente. Seu código pode rodar em muitas instâncias de curta duração. Cada instância pode criar seu próprio pool, mesmo que só trate algumas requisições. É assim que a exaustão do pool aparece com tráfego aparentemente leve: o tráfego está disperso por mais instâncias do que você esperava.
Por que serverless multiplica conexões
O salto geralmente vem de cold starts e eventos de escala. Quando a plataforma quer mais paralelismo, ela inicia mais instâncias, e cada instância pode abrir seu próprio conjunto de conexões ao banco.
Um tamanho de pool que parece seguro em um servidor pode ser arriscado no serverless:
- Servidor long-lived: 1 instância x pool de 20 = cerca de 20 conexões
- Rajada serverless: 30 instâncias x pool de 20 = cerca de 600 conexões
Mesmo que esse pico seja breve, já basta para atingir limites do Postgres, causar queries lentas e timeouts.
Uma forma simples de pensar nisso
Em servidores long-lived, você ajusta o pool para reuso constante e throughput. No serverless, ajuste para raio de explosão: assuma que pode haver muitas cópias do seu app rodando ao mesmo tempo.
Números para coletar antes de mudar configurações
Chutar configurações do pool transforma pequenos problemas em incidentes de produção. Antes de mexer em qualquer coisa, colete alguns números para saber se você está curto de conexões, segurando-as por muito tempo, ou ambos.
Comece pelo limite do banco. Encontre max_connections do Postgres e liste quem usa essas conexões: seu app, ferramentas administrativas, jobs em background, migrations, ferramentas de BI, réplicas de leitura. Muitas equipes acham que têm “100 conexões” quando 30 já estão reservadas.
Depois, foque em concorrência, não em tráfego diário. Um site com 200 usuários por dia ainda pode ter picos de 20 requisições concorrentes se uma página dispara várias chamadas à API ou algumas pessoas atualizarem ao mesmo tempo. Observe requests concorrentes máximos nos seus 5 a 15 minutos mais ocupados e desconstrua por instância (ou por função no serverless).
A velocidade das queries importa tanto quanto a contagem de conexões. Extraia queries lentas por tempo total e por latência p95/p99. Algumas queries de 2 a 5 segundos podem prender conexões tempo suficiente para bloquear todo o resto.
Os sinais que geralmente explicam outages “súbitos”:
- Conexões abertas vs limite do Postgres e a velocidade de crescimento delas
- Tempo de espera por conexão (tempo gasto aguardando por uma conexão livre)
- Timeouts do pool e picos de erro (frequência e timestamps)
- Concorrência de requisições no momento em que os erros começam
- Se workers em background compartilham o mesmo banco e pool
Um check rápido: se seu timeout de aquisição do pool é 10 segundos e você vê latência end-to-end de 12 segundos, os usuários culpam “o servidor” quando o atraso real é esperar por uma conexão.
Passo a passo: ajustar pooling para servidores long-lived
Em servidores long-lived (VMs, containers, pods sempre ativos), a maior armadilha é esquecer que cada processo pode ter seu próprio pool. Dez web workers com pool de 20 não são 20 conexões; são até 200.
Comece com um alvo que deixe folga em relação ao limite do banco. Se o Postgres permite 100 conexões, raramente você quer que seu app possa tomar todas as 100. Deixe espaço para migrations, sessões administrativas, ferramentas e deploys.
1) Defina um tamanho de pool que corresponda à concorrência real
Pense em termos de “quantas queries rodam ao mesmo tempo”, não “quantos usuários”. Queries lentas fazem com que cada conexão fique ocupada por mais tempo, o que aumenta o pool necessário.
Uma abordagem prática é estabelecer um orçamento total de conexões para toda a aplicação (frequentemente 60% a 80% do limite do DB) e dividir entre processos que podem se conectar. Comece pequeno e só aumente se vir enfileiramento e o banco ainda tiver folga. Faça orçamento separado para workers de jobs.
2) Adicione timeouts que falhem rápido (e permitam recuperação)
Duas configurações evitam acúmulos silenciosos: timeout de aquisição (quanto tempo uma requisição espera por uma conexão livre) e timeout de ociosidade (quanto tempo uma conexão não usada fica aberta). Timeouts de aquisição curtos transformam um derretimento lento em um erro visível e contido que você pode alertar.
Se tiver que escolher, um pool menor com timeouts claros é mais seguro do que um pool grande que empurra o banco para sobrecarga.
3) Limite a concorrência acima do pool
Se seu servidor aceita 500 requisições concorrentes mas seu orçamento total de BD é 60 conexões, você precisa de um limite: número de workers, concorrência de requisições ou paralelismo do job runner.
Verifique sempre se as conexões são devolvidas, inclusive em caminhos de erro. Procure por blocos finally faltando, transações abandonadas ou sessões ORM de longa duração.
Passo a passo: ajustar pooling para serverless
Serverless muda a matemática. O código pode parecer igual, mas a plataforma pode criar muitas instâncias de curta duração ao mesmo tempo.
1) Defina limites rígidos por instância
Faça cada instância “pequena” do ponto de vista do banco. Em muitos setups serverless, você não quer um pool grande dentro de cada função.
Mantenha simples:
- Limite o tamanho do pool para um número baixo (frequentemente 1 a 4 por instância)
- Use um timeout de aquisição curto para que requisições falhem rápido em vez de se acumular
- Use um idle timeout para que conexões não usadas fechem rapidamente
- Reuse o pool entre invocações (crie-o uma vez, fora do handler de requisição)
- Garanta que toda query libere a conexão, mesmo em erros
Checagem de sanidade: se o Postgres permite 100 conexões e a plataforma pode subir 50 instâncias, um pool de 5 pode tentar 250 conexões. Isso já basta para quebrar a produção.
2) Controle a concorrência antes de tocar o banco
Seu melhor “pool” muitas vezes é um limite de concorrência. Restrinja quantas requisições uma versão do serviço pode rodar ao mesmo tempo. Isso impede que um novo deploy, uma tempestade de retries ou um pico de jobs em background inunde o banco.
Fique de olho em paralelismo oculto também: Promise.all em lote, handlers de webhooks que disparam fan-out, consumidores de fila que processam múltiplas mensagens ao mesmo tempo. Isso pode multiplicar conexões mesmo com tráfego de usuário leve.
3) Use um pooler externo ou proxy gerenciado quando possível
Se sua plataforma oferece um proxy de banco (ou você pode rodar um pooler externo), ele pode absorver a escala do serverless e manter conexões ao banco estáveis. Ainda assim, conheça os limites: o proxy pode ficar sem capacidade ou pode enfileirar requisições por mais tempo que o timeout da sua função.
Um modo realista de falha é “novo pool por requisição” junto com retries. Dez invocações concorrentes podem virar 30 tentativas de conexão em segundos.
Guardrails que impedem pequenos problemas de virar outage
A maioria dos incidentes de exaustão do pool começa como uma pequena lentidão. Algumas requisições esperam um pouco mais, então tudo se empilha. Guardrails servem para falhar rápido, recuar e manter o app utilizável enquanto o banco recupera.
Decida um comportamento claro de falha. Se uma requisição não conseguir uma conexão rapidamente, ela deve parar e retornar um erro claro, não ficar pendurada até o timeout de camadas superiores. Timeouts curtos do pool também protegem seus workers porque liberam threads para que o serviço continue respondendo.
Retries precisam de limites rígidos. Retries em todas as queries podem transformar um soluço breve em uma tempestade. Mantenha retries para operações seguras (leitura idempotente), adicione jitter (atraso aleatório) e limite o tempo total de retry.
Circuit breakers são o próximo passo. Quando houver falhas repetidas no BD, abra o breaker por uma janela curta e falhe imediatamente requisições que dependem do BD. É melhor falhar rápido do que arrastar todo o sistema para um colapso lento.
Degradação graciosa mantém os usuários em movimento. Dependendo do produto, isso pode significar modo somente leitura quando writes falham, servir resultados em cache para leituras comuns, desabilitar temporariamente recursos pesados como relatórios, ou retornar uma mensagem amigável “tente novamente em 30 segundos” para endpoints que dependem do BD.
Alerta em sinais iniciais, não apenas em erros duros. Aumento do tempo de espera por conexão, crescimento da profundidade da fila e p95 maior normalmente aparecem minutos antes de “conexões demais”.
Erros comuns que disparam exaustão súbita do pool
A maioria dos incidentes não vem de um grande pico de tráfego. Acontecem quando algumas escolhas pequenas se somam e removem sua margem de segurança.
Uma armadilha comum é dimensionar o pool do app para o limite do banco. Se o Postgres permite 100 conexões e você configura seu pool para 100, não sobrou espaço para migrations, workers, sessões administrativas ou uma segunda cópia do app durante um deploy.
Escala serverless é outra causa frequente. Se cada instância da função cria seu próprio pool, você não tem “um pool de 20”. Você tem “20 vezes N instâncias”, o que pode transformar tráfego leve em uma tempestade de conexões em segundos.
Os erros que mais frequentemente disparam falha súbita:
- Usar o máximo do DB como tamanho do pool do app em vez de reservar folga
- Criar um pool separado por instância serverless (ou por requisição)
- Vazamento de conexões em caminhos de erro (returns antecipados, exceções, requisições canceladas)
- Segurar conexões por muito tempo (queries lentas, índices faltando, transações longas)
- Permitir que ruído de background compita com usuários reais (health checks, cron jobs, polling de filas)
Um padrão realista é um app “ocioso” onde um health check bate a cada poucos segundos, um cron roda a cada minuto e uma query lenta leva 10 segundos. Com um pool pequeno, apenas alguns overlaps já o preenchem.
Checklist rápido antes do lançamento
Muitos incidentes rotulados como exaustão do pool são, na verdade, falta de checagens finais: limites desconhecidos, timeouts inconsistentes e concorrência deixada ao acaso.
Primeiro, escreva o teto rígido. O Postgres tem um limite de conexões, e provedores gerenciados frequentemente reservam algumas conexões para uso administrativo. Se você não conhece seu máximo utilizável, não pode dimensionar pools com segurança.
Antes do release, confirme:
- Seu orçamento de conexões:
max_connections, conexões reservadas e o teto alvo para o app - Tamanho do pool e timeouts com folga, incluindo um timeout de aquisição claro
- Configurações de concorrência (especialmente em serverless) para que um deploy não crie uma onda de novas conexões
- As queries mais lentas e as principais correções (índices e N+1 acidentais são comuns)
- Visibilidade: dashboards e alertas para contagem de conexões, tempo de espera por conexão e timeouts do pool (não apenas 500s genéricos)
Um teste prático: rode um pequeno teste de carga que imite “tráfego leve” (alguns usuários clicando por aí) e observe tempo de espera do pool e conexões ativas. Se algum deles subir continuamente, você já está perto de um incidente.
Um exemplo realista: um outage com poucos usuários online
Uma pequena SaaS teve uma terça-feira tranquila: seis pessoas logadas, algumas visualizações de dashboard por minuto. Então os usuários relataram que o login girava eternamente e o dashboard retornava 500s aleatórios.
Nos logs, o app não estava “down” no sentido usual. CPU estava ok. Memória estava ok. A pista real eram mensagens repetidas como “timeout acquiring a client” e “remaining connection slots are reserved.” Clássico: exaustão do pool, mesmo com tráfego leve.
Duas pequenas mudanças foram lançadas juntas.
Primeiro, um novo job em background rodou a cada minuto para atualizar uma tabela de estatísticas. Segundo, uma query do dashboard ficou mais lenta por causa de um índice faltando. Essa query começou a levar 8 a 12 segundos, e o job segurava uma conexão o tempo todo.
Então o deploy mudou de um servidor de longa duração para serverless. Nada no código parecia mais arriscado, mas o paralelismo subiu da noite para o dia. Algumas requisições concorrentes de página mais alguns jobs concorrentes significaram muito mais tentativas de conexão ao mesmo tempo. Cada instância tinha seu próprio pool, então o total de conexões abertas subiu rápido.
A correção não foi uma configuração mágica. Foi um conjunto de pequenos guardrails:
- Reduzir o tamanho do pool por instância para que cada instância não possa agarrar muitas conexões
- Limitar a concorrência para que a plataforma não crie trabalho paralelo ilimitado
- Encurtar timeouts do pool para que requisições falhem rápido e recuperem em vez de se empilharem
- Otimizar a query lenta (adicionar o índice e reduzir joins desnecessários)
Depois disso, o app ficou estável. Alertas em “tempo de espera do pool” e “conexões ativas” deram ao time um aviso minutos antes dos usuários sentirem o problema.
Próximos passos: estabilizar o pooling e ter uma segunda opinião
Se você acabou de enfrentar exaustão do pool, não comece mexendo em números aleatórios. Comece nomeando seu modelo operacional: serverless (muitas instâncias curtas), servidores long-lived (poucos processos estáveis) ou híbrido. Pooling é um problema diferente em cada caso.
Escreva um orçamento de pooling simples que torne impossível que sua camada de aplicação demande mais conexões do que o Postgres pode fornecer com segurança. Capture três coisas: seu teto utilizável de conexões do Postgres, seu pico de instâncias (ou contagem de rajada) e limite por instância, e seus timeouts “sinal de pare” para que requisições falhem rápido em vez de se empilharem.
Depois rode um teste de carga focado que reflita a realidade. Muitas equipes testam alto throughput mas perdem o padrão que aciona a exaustão: rajadas breves, queries lentas e retries. Inclua fluxos de login/signup, sua página mais lenta e tasks em background rodando ao mesmo tempo.
Se você herdou uma base de código gerada por IA, vale checar os problemas comuns: padrões de “conectar por requisição”, limpeza faltando em caminhos de erro e retries ocultos que multiplicam a concorrência. Se quiser um check rápido, a FixMyMess oferece uma auditoria de código gratuita que aponta onde conexões são criadas, vazadas ou mantidas por muito tempo, para que você corrija a causa em vez de chutar números do pool.
Perguntas Frequentes
O que “exaustão do pool de conexões” realmente significa?
Significa que seu app está aguardando por uma conexão livre ao banco de dados e não há nenhuma disponível. As requisições se enfileiram, atingem o tempo limite de aquisição e os usuários veem páginas lentas seguidas por falhas intermitentes.
Por que a exaustão do pool acontece mesmo quando o tráfego parece leve?
CPU e tráfego podem parecer normais porque o app não está processando mais trabalho ativo; ele está principalmente esperando. Algumas requisições que seguram conexões por mais tempo do que o esperado podem bloquear todo o pool, então mesmo um tráfego “leve” pode travar o sistema.
Quais são os sintomas mais comuns visíveis para usuários em produção?
Procure por pausas longas (frequentemente 10–30 segundos) seguidas de erros 500, falhas de login ou jobs em background que param de progredir. Um refresh às vezes “resolve” temporariamente porque uma conexão é liberada, mas o problema volta quando o pool enche de novo.
Como vazamentos de conexão normalmente acontecem no código real?
Vazamentos acontecem quando o código retira uma conexão do pool e não a devolve em todos os caminhos, especialmente em rotas de erro. Exceções não tratadas, retornos antecipados, requisições canceladas e lógica de limpeza ausente são maneiras comuns de prender conexões.
O problema real é “muitos usuários” ou outra coisa?
Pense em termos de concorrência e tempo de retenção da conexão. O problema não é necessariamente “muitos usuários”; é que cada conexão fica ocupada por mais tempo (queries lentas, transações abertas) e isso faz o pool esgotar mais rápido.
Como o pooling difere em serverless comparado a servidores long-lived?
Em servidores de longa duração, o pool é reutilizado dentro de processos estáveis, então o total de conexões é mais previsível. No serverless, muitas instâncias curtas podem subir de repente e cada uma pode criar seu próprio pool, multiplicando o total de conexões rapidamente.
Quais números devo coletar antes de mudar as configurações do pool?
Comece pelo limite do banco (por exemplo, max_connections) e subtraia conexões reservadas para administradores, migracoes e workers. Depois meça requests concorrentes de pico, tempo de espera por conexão e quais queries são lentas no p95/p99 — esses números explicam a maioria dos incidentes “súbitos”.
Quais timeouts e guardrails evitam um colapso lento?
Defina um timeout de aquisição para que requisições falhem rapidamente em vez de se acumularem, e um idle timeout para que conexões não usadas fechem logo. Em seguida, limite a concorrência de requisições e jobs para que sua aplicação não aceite muito trabalho paralelo para o orçamento de conexões disponível.
Quais são os maiores erros que causam exaustão do pool?
Evite configurar o pool do app igual ao máximo do banco, porque deploys, migrações, ferramentas administrativas e workers ainda precisam de conexões. Também evite criar um pool por requisição, permitir retries descontrolados e executar queries lentas dentro de transações longas que seguram conexões além do necessário.
Como estabilizar rapidamente um app gerado por IA que continua esgotando o pool?
Comece verificando padrões como “conectar por requisição”, limpeza faltando em caminhos de erro, retries ocultos e queries lentas que mantêm transações abertas — protótipos gerados por IA frequentemente incluem esses problemas. Se quiser uma opinião rápida, a FixMyMess oferece uma auditoria de código que aponta onde conexões são criadas, vazadas ou mantidas por muito tempo.