Fila dead-letter para jobs em segundo plano: tentativas e reexecução segura
Aprenda como uma dead-letter queue para jobs em segundo plano captura mensagens venenosas, limita retentativas e permite reexecução segura sem duplicar efeitos colaterais.
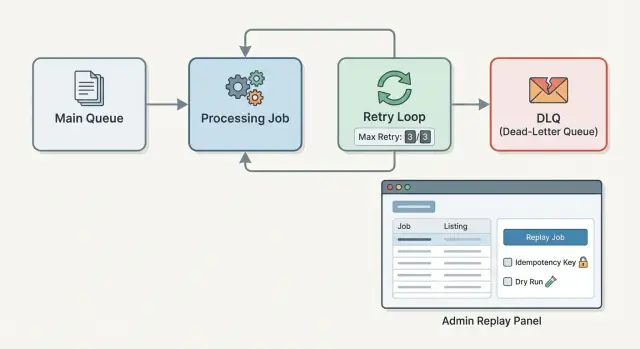
O que dá errado quando jobs em segundo plano continuam falhando
Um job em segundo plano normalmente roda fora da vista: enviar um email, cobrar um cartão, redimensionar uma imagem, sincronizar um registro. Quando ele falha uma vez, uma retentativa muitas vezes resolve. O problema começa quando o mesmo job falha repetidas vezes, sem limite e sem um lugar claro para colocá-lo.
Esse tipo de job costuma ser chamado de mensagem venenosa (poison message). Significado simples: uma entrada ruim ou uma situação quebrada que faz o worker falhar sempre que a toca. Pode ser um payload malformado, uma linha de banco de dados ausente, uma chave de API expirada ou um bug no código que só aparece para um cliente.
Retentativas intermináveis prejudicam mais do que você imagina. Elas podem:
- Criar uma interrupção ao manter workers ocupados com o mesmo trabalho que falha, em vez de processar jobs saudáveis.
- Aumentar custos (mais computação, mais operações na fila, mais tráfego no banco).
- Lotar logs e alertas até que problemas reais sejam ignorados.
- Disparar efeitos colaterais repetidos, como cobrar ou enviar email duas vezes, se o job falhar depois de executar a ação.
Um padrão comum de falha é o sucesso parcial. Exemplo: seu job envia um email e depois trava ao gravar “enviado” no banco. A próxima retentativa não vê a flag “enviado” e manda o email de novo. Agora você tem duplicatas, usuários irritados e um rastro de auditoria confuso.
É por isso que equipes adicionam uma dead-letter queue (DLQ) para jobs em segundo plano. Em vez de retentar para sempre, você limita as tentativas e move o job com seus detalhes de erro para um lugar à parte. Depois você corrige a causa e reexecuta intencionalmente.
Uma configuração sólida tem três peças: uma política de retentativa que para antes das coisas derreterem, um registro na DLQ que preserva o que aconteceu e um fluxo de replay cuidadoso sobre duplicações. Se você herdou um worker instável (inclusive gerado rapidamente por uma ferramenta de IA), essas proteções podem transformar um sistema barulhento em algo confiável.
Filas dead-letter, explicadas sem jargão
Uma dead-letter queue (DLQ) é uma área de retenção para jobs que falharam e não deveriam continuar sendo retentados automaticamente. Não é um lugar onde o trabalho desaparece silenciosamente. É onde as falhas se tornam visíveis, inspecionáveis e corrigíveis.
Pense nela como mover um job travado para fora da linha principal para que o resto do sistema continue avançando. Você está escolhendo clareza ao invés de retentativas infinitas.
Alguns termos que se misturam:
- Fila de retentativa: jobs que falharam mas se espera que tenham sucesso depois (por exemplo, um problema temporário de rede). Eles rodam de novo após um atraso.
- DLQ: jobs que falharam e precisam de atenção humana, correção de código, correção de dados ou uma decisão antes de tentar novamente.
- Parking lot queue: um bucket mais amplo que algumas equipes usam para itens “não urgentes”. Na prática, muitas vezes vira uma DLQ informal sem regras claras.
Quando retentar versus enviar para a DLQ? Retente quando a falha provavelmente for temporária e segura de repetir. Mova para a DLQ quando retentativas provavelmente não vão ajudar ou podem causar dano. Por exemplo, “taxa limitada pelo provedor” geralmente é retryável. “ID do cliente inválido” ou “campos obrigatórios ausentes” normalmente precisa de correção de dados ou código, então pertence à DLQ.
Quando um job é movido para a DLQ, ele deve carregar contexto suficiente para debugar e reexecutar com segurança depois:
- O payload do job (entradas exatas usadas)
- Mensagem de erro e stack trace (ou equivalente)
- Contagem de tentativas e timestamps (primeira falha, última tentativa)
- Uma chave de idempotência estável ou fingerprint do job
- O último estado conhecido de efeitos colaterais (se houver), como “cobrança criada” ou “email enviado”
Esse último detalhe importa. Uma DLQ não é só sobre capturar falhas. É sobre tornar a próxima tentativa uma decisão controlada e informada.
Decida o que é retryable e o que não é
Retentativas só ajudam quando o problema é temporário. Quando o problema é permanente, retentar só desperdiça o tempo dos workers e esconde o problema real. Essa é a primeira decisão por trás de qualquer dead-letter queue para jobs em segundo plano: o que deve ser tentado de novo e o que deve parar rápido.
Uma regra simples funciona bem: retente quando o job puder ter sucesso mais tarde sem mudar o código ou a entrada. Se nunca puder dar certo com o mesmo payload, não retente.
Classifique falhas por intenção
Ao invés de tratar todas as exceções da mesma forma, mapeie-as em alguns buckets claros:
- Transiente: timeouts de rede, quedas de conexão com o banco, 5xx temporários de um provedor.
- Throttling: limites de taxa (429), cota excedida, “tente novamente em 60 segundos”.
- Não encontrado / estado ausente: registro relacionado deletado, usuário que não existe mais.
- Entrada inválida: payload falha na validação, campo obrigatório ausente, formato errado.
- Auth / permissões: credenciais expiradas, acesso revogado, ação proibida.
Essa classificação deve guiar o que acontece a seguir: retentativa imediata, retentativa com atraso ou mover para a DLQ com uma razão clara.
Exemplo: um job que cobra um cartão falha com timeout da API de pagamento. Isso é transiente, então retentar faz sentido. Mas se o job falha porque o ID do cliente está faltando no payload, retentar nunca vai consertar. Coloque na DLQ e alerte alguém para corrigir os dados (ou o produtor do job).
Por que isso importa para alertas e replay
Uma DLQ não é apenas um estacionamento. A razão pela qual você moveu um job para lá diz o que fazer a seguir:
- Falhas transientes frequentemente significam que você precisa de um backoff melhor, não de um humano.
- Entrada inválida geralmente significa correção de bug ou de dados antes do replay.
- Falhas de autenticação normalmente significam rotacionar chaves antes de qualquer outra coisa.
Isso também torna o replay mais seguro. Se um job está na DLQ por “payload inválido”, sua ferramenta administrativa pode bloquear o replay por padrão e pedir correção primeiro. Muitos workers herdados falham aqui porque tudo é tratado como “retryable” até alguém definir categorias e regras de parada claras.
Defina uma política de retentativas que não derruba seu sistema
Retentativas são úteis, mas retentativas sem controle podem transformar um job quebrado em uma queda de sistema. Uma boa política limita danos, espalha a carga no tempo e para cedo quando um job claramente não vai funcionar.
Tentativas máximas devem corresponder ao tipo de falha. “Tamanho único para todos” é como você acaba retentando as coisas erradas. Uma chamada de rede instável pode merecer 5–10 tentativas. Um payload ruim (campos faltando) não deveria ganhar 10 tentativas — deveria ir para a DLQ rapidamente. Trate a DLQ como o lugar onde os jobs vão quando seu orçamento de retries acabar.
Backoff e jitter, em termos simples
Backoff significa esperar mais entre as tentativas. Isso dá tempo para serviços downstream se recuperarem e evita que seus workers ataquem o mesmo endpoint.
- Backoff fixo: espera o mesmo tempo em cada tentativa.
- Backoff exponencial: espera tempos maiores a cada nova tentativa.
- Jitter: adiciona um pequeno atraso aleatório para que muitos jobs não tentem exatamente ao mesmo segundo.
Exemplo: seu provedor de pagamentos tem uma queda breve. Sem jitter, todo job falhado retenta exatamente aos 30 segundos e causa uma segunda onda de falhas.
Limites de tempo que evitam “dor infinita”
Defina dois relógios:
- Timeout por tentativa (quanto tempo uma tentativa pode rodar antes de ser cancelada).
- Janela de tempo total (por quanto tempo você está disposto a continuar retentando antes de desistir).
Um padrão prático para muitas equipes é: 3–5 tentativas, backoff exponencial começando em 10–30 segundos, jitter pequeno (como 0–10 segundos), um timeout por tentativa que combine com o tempo normal de chamadas, e uma janela total como 15–60 minutos. O objetivo não é perfeição. É parar retentativas descontroladas antes que se acumulem e bloqueiem trabalho saudável.
O que registrar quando você move um job para a DLQ
Quando um job em segundo plano cai numa dead-letter queue (DLQ), você não está apenas salvando uma “mensagem falhada”. Está criando um dossiê que alguém pode precisar para entender, consertar e reexecutar com segurança dias depois.
Comece com os dados mínimos necessários para reproduzir a falha e decidir o que fazer a seguir. Um bom registro na DLQ costuma incluir:
- Tipo do job (qual worker deve tratá-lo) e versão (se o formato do payload muda com o tempo)
- Payload original (como recebeu) mais um resumo seguro e redigido para admin
- Contagem de tentativas e histórico de retries (quantas vezes e por que continuou falhando)
- Timestamps: primeiro visto, última tentativa, movido para a DLQ
- Detalhes do erro: última mensagem/stack, mais a cadeia de causa raiz se você tiver
Um ID de job estável é crítico. Gere um quando o job for criado e mantenha o mesmo entre retentativas e replays. Depois acrescente uma chave de deduplicação ou idempotência que represente o efeito que você quer causar (por exemplo, send_invoice_email:invoice_123:recipient_456). Isso permite reexecutar sem repetir a ação.
Cuidado com o que admins veem. Payloads frequentemente contêm segredos, tokens ou dados pessoais. Armazene o payload bruto se necessário para debug, mas também grave um campo de resumo seguro que esteja redigido (por exemplo, exiba o ID do usuário, não o email; mostre os 4 últimos dígitos do cartão, não o token completo).
Por fim, guarde tanto o último erro quanto a causa original quando puder. Exemplo: um job pode terminar com “timeout chamando provedor”, mas o erro raiz era “chave de API ausente”. Se a DLQ mantiver a cadeia, a correção fica óbvia e o replay mais seguro.
Passo a passo: adicione DLQ e retentativas limitadas ao seu worker
Trate cada execução de job como uma pequena transação: ou termina, ou falha de um jeito que você pode raciocinar depois. Uma dead-letter queue para jobs em segundo plano é só o lugar onde ficam os jobs “já tentamos o suficiente, agora um humano precisa olhar”.
Um fluxo simples que funciona na maioria das stacks:
- Rode o handler dentro de um try/catch (ou equivalente) que capture um erro tipado, não só uma string.
- Em falha, incremente um contador de tentativas e calcule o próximo horário usando backoff (por exemplo: 1m, 5m, 20m), com um pouco de jitter para que retries não se acumulem.
- Se o erro for claramente não retryable (entrada ruim, registro ausente, permissão negada), ou as tentativas atingiram o máximo, mova o job para a DLQ em vez de retentar.
- Dispare um alerta com contexto suficiente para debugar (tipo do job, id, tentativa, classe do erro, hora que foi visto pela primeira vez). Evite colocar payloads completos nos alertas, pois frequentemente contêm segredos ou dados pessoais.
- Acompanhe alguns contadores para que o problema apareça cedo.
try {
handle(job)
markDone(job)
} catch (err) {
attempts = job.attempts + 1
if (!isRetryable(err) || attempts \u003e= MAX_ATTEMPTS) {
moveToDLQ(job, err)
alert(job, err)
} else {
reschedule(job, backoff(attempts))
}
}
Para dashboards, você não precisa de nada fancy. Monitore jobs em andamento, jobs agendados para retry, profundidade da DLQ e “DLQ adicionados por hora”.
Prevenindo efeitos colaterais duplicados ao reexecutar
Reexecutar um job falhado é onde o risco real se esconde. O job original pode já ter feito a parte perigosa (cobrar um cartão, enviar um email, gravar uma linha) e ter caído antes de logar ou atualizar o status. Se você reexecutar direto da DLQ sem proteção, pode cobrar em dobro, enviar emails duplicados ou criar registros duplicados.
A maneira mais simples de ficar seguro é idempotência. Em termos simples: a mesma requisição deve produzir o mesmo resultado mesmo se for executada duas vezes. Seu job deve ser capaz de dizer “isso já foi feito” e sair sem repetir o efeito.
Maneiras práticas de fazer isso:
- Chaves de idempotência: gere uma chave estável por ação do mundo real (como
invoice_123_charge) e grave o resultado. No replay, verifique a chave antes. - Restrições únicas: faça o banco garantir “apenas um” (uma payout por pedido, um email de boas-vindas por usuário) e trate duplicatas como sucesso.
- Padrão outbox: grave a intenção no banco uma vez e tenha um sender separado para entregar. Replays checam e só enviam o que ainda está pendente.
Um bom modelo mental é “gravar uma vez, enviar depois”. Primeiro, registre um fato durável como “Pagamento do pedido 8821 autorizado” em uma transação. Só depois chame o serviço externo (provedor de email, gateway de pagamento). Se o job morrer no meio, o replay vê o fato gravado e faz o mínimo restante.
Exemplo: um job envia um email de recibo após uma compra. Se ele enviar o email e depois cair antes de marcar receipt_sent=true, reexecutá-lo vai enviar um segundo recibo. Conserte isso gravando receipt_sent_at com uma chave única como receipt:{order_id} antes de enviar, ou enfileirando o email em uma tabela outbox e deixando um sender dedicado cuidar da entrega.
Construa um fluxo administrativo de replay seguro por padrão
Se as pessoas puderem reexecutar jobs da DLQ com um clique, elas vão. O fluxo administrativo tem que supor erros, pressão e contexto parcial. Seguro por padrão significa que a ação mais fácil também é a mais segura.
Comece com um conjunto pequeno de visões que respondam o básico rapidamente:
- Lista da DLQ: filtre por tipo de job, classe de erro, data e ambiente.
- Visão de detalhe: payload, chave de idempotência, headers/metadata e o erro exato.
- Replay: opções para reexecutar agora vs agendar, único vs batch.
- Dismiss/resolve: um lugar para marcar “não vamos corrigir” com uma razão.
Na visão de detalhe, mostre o histórico de tentativas: timestamps, versão do worker, contagem de retries e quaisquer efeitos colaterais registrados (por exemplo, “criou fatura #1234”). É com isso que se tomam boas decisões.
Os controles de replay devem forçar o operador a declarar intenção. Replay em batch deve exigir uma pré-visualização de filtro (“32 jobs batem com esse filtro”) e uma segunda confirmação que nomeie o tipo de job e o risco de efeito colateral (“pode enviar emails”). Um modo dry run vale a pena: valide entradas e dependências sem escrever ou chamar serviços externos e mostre o que aconteceria.
Guardrails evitam que um replay transforme um job ruim em dois resultados ruins:
- Bloquear replay se a mesma chave de idempotência já tiver sucesso.
- Padrão para agendar (alguns minutos depois) ações em lote, não executar imediatamente.
- Exigir escolha explícita quando o job for conhecido por ser não idempotente.
- Limitar a taxa de replays por tipo de job para evitar rajadas.
- Sempre registrar uma entrada de auditoria.
Permissões importam. Restrinja replay a um papel pequeno e registre quem reexecutou o quê e quando, incluindo a nota de motivo.
Erros comuns e armadilhas a evitar
A maioria das DLQs falha por motivos entediantes: regras pouco claras, retentativas agressivas demais ou tratar o replay como um botão inofensivo.
Armadilhas comuns (e como evitá-las):
- Retry em tudo para sempre. Se toda falha é “tente de novo”, você nunca aprende o que está quebrado. Defina regras claras de DLQ (entrada ruim, registros ausentes, falhas de auth, 4xx de terceiros) e mova esses jobs para fora do caminho quente rapidamente.
- Sem limite + sem backoff = tempestades de retentativas. Uma queda pode virar uma enchente que retarda todo o sistema. Defina tentativas máximas, use backoff exponencial com jitter e pare de retentar quando o erro não for temporário.
- Um botão de replay que pode duplicar efeitos. Reexecutar um job que já cobrou ou já enviou um email pode causar dano real. Torne handlers idempotentes (chave de idempotência, constraints únicas ou marcador “já processado”) e desenhe o replay para ser seguro mesmo se clicado duas vezes.
- Logar segredos dentro de payloads ou erros. DLQs muitas vezes armazenam o corpo original do job. Se isso inclui tokens, senhas, chaves de API ou dados de clientes, você criou uma fuga silenciosa. Redija campos sensíveis antes de enfileirar e sanitize mensagens de erro antes de armazená-las.
- Usar a DLQ como armazenamento de longo prazo. Uma DLQ sem dono vira um cemitério. Atribua um responsável, defina uma política de retenção e agende limpeza. Monitore algumas métricas (tamanho da DLQ, idade do item mais antigo, taxa de sucesso de replays) para mantê-la sob controle.
Uma regra simples ajuda: sua DLQ deve ser uma caixa de entrada de curto prazo para investigação, não um depósito. Se crescer, é bug de produto ou problema de ops, e alguém deve ser responsável por consertar.
Exemplo: um job de email falhado que não deve enviar duas vezes
Um usuário se cadastra e sua app enfileira um job “enviar email de boas-vindas”. O job inclui user_id, to_email, template_id e um send_id (uma chave de idempotência única para este email).
Um cadastro tem um endereço ruim como alex@@example.com. O worker chama o provedor de email, recebe 400 “recipient inválido” e falha.
Sua política de retries tenta algumas vezes (por exemplo, 3 tentativas ao longo de 10 minutos) caso o erro seja temporário. Cada tentativa falha do mesmo jeito, então o job é movido para a DLQ com uma razão clara e não retryable: “Formato de email inválido: alex@@example.com”. Essa frase única importa porque diz a um admin o que consertar sem cavar em stack traces.
Durante o incidente, seus logs e métricas devem contar a história claramente:
- Tentativas do job: 3 (todas falharam com o mesmo 400)
- Contagem na DLQ: +1 (tagged
reason=invalid_recipient) - Envios de email: 0 (nenhum message id do provedor armazenado)
- Tempo até ir para a DLQ: 10m (mostra que retries foram limitados)
Um admin abre o item da DLQ, edita a entrada (ou corrige o registro do usuário) e clica em replay. O fluxo de replay deve ser seguro por padrão: reenfileira o job com o mesmo send_id, e o worker checa primeiro uma tabela sent_emails. Se já existir uma linha para send_id, ele para. Se não, envia o email, grava o message id do provedor e marca o job como completo.
Para evitar a mesma falha no futuro, valide cedo (rejeite emails ruins antes de enfileirar) e mantenha idempotência para cada efeito colateral (emails, cobranças, webhooks).
Lista rápida e próximos passos
Uma DLQ só ajuda em produção se os detalhes chatos estiverem certos. Esses detalhes são o que impede que falhas virem duplicatas, outages ou bagunça silenciosa de dados.
Checklist de construção para retentativas e captura em DLQ:
- Limite tentativas e defina backoff (por exemplo, 5 tentativas com backoff exponencial e jitter), além de timeout rígido por tentativa.
- Documente o que é retryable vs não retryable (pequenos problemas de rede, 429/503, locks temporários de DB) e trate todo o resto como não retryable por padrão.
- Adicione uma condição de parada para mensagens venenosas (assinatura de erro repetida, payload inválido, campos obrigatórios faltando) para que elas vão cedo para a DLQ.
- Registre o básico da DLQ: tipo do job, args (redigidos), contagem de tentativas, última classe de erro e mensagem, stack trace, timestamps e versão do worker.
- Redija segredos e dados pessoais antes de armazenar (tokens, senhas, emails completos, corpos de requisição brutos) e mantenha um rastro de auditoria de quem mudou o quê.
Checklist de segurança para replay:
- Escolha uma estratégia de idempotência por tipo de job (chave de idempotência, constraint única ou marcador “já processado”) e teste reenfileirando o mesmo job duas vezes.
- Separe replay de retry: replay deve requerer decisão humana e idealmente uma nota de motivo.
- Restrinja permissões (apenas admins), adicione um passo de confirmação claro e mostre uma pré-visualização do que acontecerá (incluindo efeitos colaterais como pagamentos ou emails).
- Decida que mudanças são permitidas antes do replay (editar payload, mudar destino, sobrepor config) e registre cada edição.
- Após o replay, grave o resultado (sucedido, falhou de novo com novo erro ou cancelado) para que a DLQ não vire um buraco negro.
Se você está lidando com um código gerado por IA onde retries, idempotência e replay seguro nunca foram projetados, FixMyMess (fixmymess.ai) pode ajudar a diagnosticar o comportamento do worker e da fila, reparar a lógica e endurecê-la para produção.
Perguntas Frequentes
What is a “poison message” in a background job queue?
Uma "mensagem venenosa" é um job que falha toda vez com a mesma entrada, de modo que retentativas não ajudam. A correção é parar as retentativas automáticas cedo, mover para uma DLQ com o erro e o payload, e então corrigir o código ou os dados antes de reexecutá-lo conscientemente.
What’s the difference between a retry queue and a dead-letter queue (DLQ)?
Uma retry queue é para falhas que provavelmente são temporárias e seguras de repetir, como timeouts ou quedas breves. Uma DLQ é para jobs que precisam de uma decisão ou correção primeiro, como payloads inválidos, registros faltando ou problemas de permissão, para que não encravem os workers.
How many retries should a background job get before going to the DLQ?
Um padrão prático é um número pequeno de tentativas com atrasos crescentes e um limite rígido no tempo total. Comece com 3–5 tentativas com backoff exponencial; quando o orçamento de retentativas acabar, mova o job para a DLQ para que um job ruim não canse todo o sistema.
How do I decide what errors are retryable vs non-retryable?
Retente somente quando o mesmo payload puder ter sucesso mais tarde sem mudar o código ou os dados. Timeouts, 5xx temporários e desconexões de banco geralmente são retryáveis; payload inválido, campos obrigatórios faltando e "not found" normalmente devem ir para a DLQ rapidamente.
What should I store when a job is moved to the DLQ?
Registre o suficiente para reproduzir e reexecutar com segurança: tipo do job, payload (com campos sensíveis redigidos), contagem de tentativas e horários, e os detalhes completos do erro. Guarde também um ID estável do job e uma chave de idempotência para que o replay detecte “já processado” em vez de repetir efeitos colaterais.
How do I prevent double charges or duplicate emails when replaying DLQ jobs?
Idempotência é a principal proteção: o job deve poder rodar duas vezes e produzir o mesmo resultado sem repetir o efeito colateral. Use uma chave de idempotência estável, imponha uma constraint única para a ação do mundo real, ou grave um marcador de “já processado” antes de enviar emails, cobrar cartões ou criar recursos externos.
What does a safe admin replay flow look like?
Faça o replay requerer intenção e acrescente guardrails: mostre o payload e o erro, bloqueie o replay se a chave de idempotência já tiver sucesso e registre quem reexecutou e por quê. Em caso de dúvida, reexecute um job único primeiro e verifique o estado dos efeitos colaterais antes de um replay em massa.
Why are endless retries so dangerous in production?
Retentativas infinitas podem consumir workers e transformar um job ruim em uma queda do sistema. Aumentam custos de computação e filas, afundam alertas reais em ruído e elevam a chance de efeitos colaterais repetidos quando o job termina parcialmente antes de cair.
How do I avoid leaking secrets or personal data through DLQ payloads and errors?
Sanitize o payload e os detalhes de erro antes de armazenar ou mostrar, porque jobs frequentemente contêm tokens, credenciais ou dados pessoais. Mantenha um resumo redigido para administradores, guarde apenas o necessário para debugar e evite jogar segredos brutos em logs e alertas.
Can FixMyMess help if my background job system was generated by an AI tool and keeps failing?
Sim. Especialmente quando o worker e a lógica de retry foram gerados rápido e nunca projetados para idempotência ou replay seguro. FixMyMess pode auditar o comportamento das filas e workers, identificar por que jobs falham e duplicam efeitos, e então reparar e fortalecer o código para produção, frequentemente em 48–72 horas após uma auditoria gratuita de código.