IDs de correlação para rastrear cliques entre APIs e tarefas em segundo plano
IDs de correlação conectam um clique do usuário aos logs da API e às tarefas em segundo plano para você identificar falhas rápido, compartilhar relatórios claros de bugs e consertar problemas com menos chute.
Por que depurar parece aleatório sem um ID compartilhado
Um relato de bug geralmente começa simples: “Cliquei em Salvar e falhou.” Aí você abre os logs e tudo vira chute. O console do navegador tem um conjunto de mensagens, os logs da API ficam em outro lugar, e os logs dos jobs estão num sistema diferente. Mesmo que cada lugar registre bastante informação, nada se alinha.
É aí que a depuração parece aleatória. Você busca por intervalo de tempo, ID do usuário, ou texto vago como “pagamento falhou”, na esperança de cair nas linhas certas. Se vários usuários estão ativos, ou retries estão acontecendo, é fácil seguir o fio errado.
Também é por isso que “funcionou na minha máquina” aparece tanto. No seu laptop, você tenta o mesmo clique de novo e ele funciona. Em produção, aquele mesmo clique pode atingir outro servidor, perder um cache, chamar um serviço externo lento, ou enfileirar um job que falha depois. Sem uma forma de conectar esses eventos, a história se divide em fragmentos.
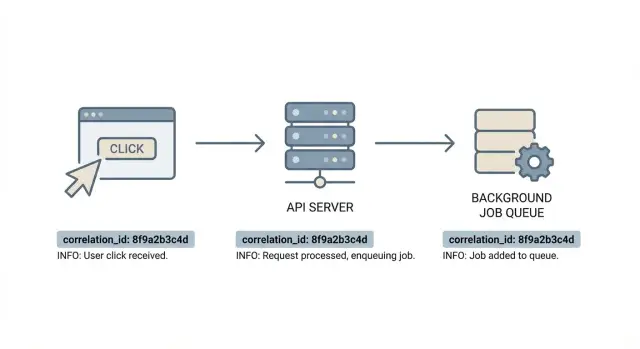
Uma ação do usuário pode se espalhar rapidamente: um clique no frontend aciona uma ou mais chamadas API; a API toca no banco e talvez em outros serviços; pode enfileirar jobs para email, cobrança, processamento de imagens ou indexação; e esses jobs podem rodar depois em máquinas diferentes, às vezes com retries. Webhooks e callbacks podem adicionar ainda mais etapas.
O objetivo é simples: uma trilha que você possa seguir do início ao fim. Com IDs de correlação, você pega um ticket de suporte, pega um identificador e puxa o evento do frontend relacionado, a requisição exata da API e cada linha de log dos jobs que rodaram depois. Depurar deixa de ser uma caça e vira uma linha do tempo confiável.
O que é um ID de correlação (e o que não é)
Um ID de correlação é um rótulo único que acompanha uma peça de trabalho enquanto ela se move pelo seu sistema. Pense nele como o contexto de “uma ação do usuário”: um clique, uma requisição API, os jobs em segundo plano que isso aciona e quaisquer chamadas downstream.
Cada linha de log pertencente àquela cadeia inclui o mesmo ID. Isso permite buscar uma vez e ver toda a história.
Um ID de correlação não é um identificador de usuário. Não deve descrever quem é o usuário, o que ele clicou ou quais dados estavam envolvidos. É uma etiqueta opaca que ajuda a conectar eventos entre sistemas sem adivinhação.
As pessoas frequentemente confundem com outros IDs:
- Session ID liga muitas ações ao longo do tempo a uma sessão do navegador. Útil para autenticação e analytics, mas amplo demais para traçar uma única ação quebrada.
- ID de registro no banco identifica uma linha (como um ID de pedido). Útil para lógica de negócio, mas não conecta automaticamente frontend, API e processamento de filas.
- Correlation ID (request ID) junta todos os passos de um fluxo, mesmo quando múltiplos serviços e jobs estão envolvidos.
Quando criá-lo? Idealmente na borda: no navegador quando a ação começa (e então enviar como header), ou no primeiro ponto de entrada da API (gateway/load balancer/app server) se você não confiar no cliente. Muitas equipes aceitam um ID fornecido pelo cliente, validam o formato e geram um novo se estiver faltando ou for inválido.
Como deve ser? Faça-o único, opaco e seguro para logar. Um UUID ou um valor no estilo ULID funciona bem. Não embedar emails, IDs de usuário ou qualquer coisa sensível.
Onde o ID deve viajar em um app típico
Um ID de correlação só ajuda se sobreviver toda a viagem. Pense nele como um rótulo que segue a ação do usuário do navegador, pela sua API, até o trabalho em segundo plano, para que cada linha de log possa ser ligada ao mesmo momento.
Na maioria dos apps, isso significa carregar o mesmo ID por:
- o evento do frontend (clique ou envio de formulário)
- a requisição da API
- chamadas downstream (serviços internos e terceiros)
- jobs em segundo plano (publicação e processamento pelo worker)
- efeitos colaterais finais (gravações, emails, processamento de arquivos)
Use os mesmos “contêineres” em todos os lugares. Na web, o carrier mais comum é um header HTTP (muitas equipes usam um nome como X-Request-Id ou X-Correlation-Id). No servidor, armazene-o no contexto por requisição para que toda linha de log o inclua automaticamente. Para jobs, inclua-o nos metadados ou no payload do job para que o worker possa restaurá-lo antes de logar.
A rastreabilidade costuma quebrar em fronteiras:
- redirecionamentos e navegação cross-domain que descartam headers customizados
- retries e timeouts que criam um novo request ID sem copiar o anterior
- publishers de filas que esquecem de incluir o ID no payload do job
- código do worker que loga antes de carregar o ID no contexto de logs
- fan-out (um clique que dispara muitos jobs) sem relação pai-filho clara
Uma regra simples que evita muita confusão: o primeiro backend que recebe a requisição é a fonte da verdade. O frontend pode encaminhar um ID existente quando já tiver um, mas o backend decide o que é aceito e o que é gerado.
Passo a passo: adicionar IDs de correlação ponta a ponta
Escolha um nome de header e use-o em todos os lugares. Consistência importa mais que a grafia exata, porque cada salto (navegador, API, fila, worker) precisa reconhecer o mesmo campo.
Comece no frontend. Quando o usuário clica num botão, reutilize um ID existente para a ação atual ou crie um novo. Mantenha-o na memória (ou num objeto de contexto de curta duração) e anexe-o a cada chamada API disparada por esse clique.
No lado da API, leia o header em middleware. Se estiver ausente, gere um. Salve-o no contexto da requisição para que logs, erros e chamadas downstream possam incluí‑lo. Também ecoe-o no header da resposta, para que o navegador (e o suporte) possam referenciar o ID exato usado.
Um fluxo prático fica assim:
- Frontend define
X-Correlation-Iduma vez por ação do usuário e o reutiliza para requisições relacionadas. - API aceita o header (ou cria um), o armazena no contexto da requisição e o inclui nas respostas.
- Enfileiramento copia o mesmo ID para os metadados ou payload do job.
- Worker restaura o ID no contexto do worker antes de logar.
- Erros incluem o ID nas respostas exibidas a usuários ou suporte.
Retries são onde equipes frequentemente perdem a trilha. Se uma requisição é reexecutada por timeout, mantenha o mesmo ID para que seja óbvio que ainda é a mesma ação do usuário. Se o usuário clicar novamente mais tarde, gere um novo ID.
Se você trabalha em uma base de código bagunçada, implemente isso em um lugar por camada primeiro: um helper no frontend, um middleware na API e um wrapper de job. Isso normalmente já é suficiente para fazer a depuração parecer previsível.
Logging que torna o ID útil
Um ID de correlação só ajuda se aparecer nos logs que você realmente lê. A forma mais fácil de torná-lo pesquisável é logar em um formato consistente e estruturado. Logs em JSON são fáceis de filtrar por correlation_id e comparar entre frontend, API e jobs em segundo plano.
No mínimo, cada linha de log relacionada a uma requisição deve incluir alguns campos confiáveis:
correlation_idroute(ouaction)status(status HTTP ou resultado do job)message(curto, legível)duration_ms(quando aplicável)
Não logue tudo. Uma linha limpa de baseline é: uma no começo da requisição, uma no fim, e linhas extras apenas para ramificações importantes como falhas de validação, retries, chamadas externas e exceções.
Aqui está o que “visível em sucesso e falha” parece:
{"level":"info","message":"request_start","correlation_id":"c-9f3a","route":"POST /checkout","user_id":"u_42"}
{"level":"info","message":"request_end","correlation_id":"c-9f3a","route":"POST /checkout","status":200,"duration_ms":184}
{"level":"error","message":"payment_failed","correlation_id":"c-9f3a","route":"POST /checkout","status":402,"error":"card_declined"}
Tenha cuidado com o que loga. Não despeje corpos de requisição completos, headers de auth, tokens, cookies ou segredos. Em vez disso, registre resumos pequenos como items_count, plan=pro, provider=stripe ou email_domain=gmail.com. Isso importa ainda mais em protótipos construídos rápido, onde logs às vezes imprimem variáveis de ambiente ou URLs de banco sem querer.
Jobs em segundo plano: manter a trilha pelas filas
Logs de requisição e logs de job respondem a perguntas diferentes. Logs de requisição cobrem o que aconteceu enquanto o usuário esperava: o clique, a chamada API, a resposta. Logs de job cobrem o que aconteceu depois: emails enviados, arquivos processados, retries e falhas que aparecem minutos depois. Sem um identificador compartilhado, esses dois mundos nunca se encontram.
Quando publicar uma mensagem numa fila, anexe o mesmo ID usado na requisição da API. Algumas equipes colocam nos metadados da mensagem (headers/attributes) e também no payload como fallback. O importante é consistência: escolha um nome de campo e use-o em todo lugar para que a busca nos logs seja previsível.
Um padrão legível:
- Use um ID raiz por ação do usuário.
- Quando a API enfileirar um job, inclua esse ID raiz e opcionalmente um ID do job separado.
- Se um clique criar múltiplos jobs, mantenha o mesmo ID raiz para todos.
- Para jobs agendados sem clique do usuário, gere um novo ID raiz no agendador.
No lado do worker, trate o ID como a primeira coisa a ser lida. Antes de logar qualquer coisa, puxe o ID da mensagem, coloque-o no contexto de logs e então comece o processamento. Caso contrário, a falha mais dolorosa acontece: o job faz trabalho útil, lança um erro e só então loga algo sem o ID.
Fan‑out merece uma regra extra: mantenha o ID raiz compartilhado, mas acrescente um identificador filho por job para que você veja qual ramo falhou.
Tornando o ID visível para suporte e relatórios de bug
Se só engenheiros conseguem ver o ID, ele não vai ajudar quando um cliente reportar “o botão não fez nada”. Faça o ID de correlação fácil de encontrar quando algo der errado, para que o suporte possa pedi‑lo e a engenharia possa pular direto para os logs certos.
Uma abordagem simples é mostrar um rótulo curto em estados de erro, não em todas as telas. Coloque onde usuários já procuram detalhes: um toast de erro, a mensagem de submissão de formulário falhada, ou uma página “Algo deu errado”.
Como mostrar sem confundir usuários
Use uma linha calma como: “Reference: ABCD-1234.” Evite palavras como “trace” ou “distribuído.” Se o ID for longo, mostre uma versão abreviada (por exemplo, os primeiros 8–12 caracteres) e mantenha o valor completo disponível via um botão “Copiar”.
O suporte também precisa de um script consistente. Mantenha simples: peça o código “Reference”, e se não o encontrarem, peça para reproduzir e tirar um screenshot do erro. Se possível, coletem o horário aproximado e o que foi clicado, então cole o código no ticket para que engenharia possa buscar imediatamente.
Nota sobre privacidade
Trate IDs de correlação como um rótulo diagnóstico, não dados pessoais. Não codifique emails, IDs de usuário ou impressões de dispositivo dentro do valor. Mantenha-o entediante e aleatório para que seja seguro compartilhar em screenshots ou tickets.
Erros comuns que quebram a rastreabilidade
A maioria das falhas de tracing não são bugs sofisticados. São escolhas pequenas que cortam a cadeia entre um clique, uma requisição API e um job em background.
- Gerar um novo ID em cada salto. IDs novos são ok para sub-operações, mas mantenha o original como pai.
- Sobrescrever um ID vindo de upstream. Gateways, CDNs ou serviços parceiros podem já enviar um request ID. Se você substituir, perde a capacidade de casar os logs deles com os seus.
- Descartar o ID ao enfileirar trabalho. Se o log da API mostra o ID mas o log do job não, você ficará chutando.
- Logar só em um nível. IDs apenas no frontend não ajudam quando o servidor falha antes de responder. IDs apenas no servidor não ajudam suporte a conectar com o que o usuário viu.
- Tratar o ID como segurança. Um ID de correlação não é um token de sessão. Não o use para autenticação e não coloque segredos nele.
Um exemplo rápido: um usuário clica “Export”. O navegador cria um ID, mas a API gera um novo e registra apenas esse. O job de export depois loga seu próprio ID aleatório. Agora você tem três IDs não relacionados para um único clique.
Uma regra simples corrige a maior parte: aceite um ID de entrada, valide seu formato e passe-o adiante inalterado. Se precisar de detalhe extra, adicione um segundo campo como parent_id ou job_id.
Checklist rápido para confirmar que funciona
Você sabe que IDs de correlação estão fazendo seu trabalho quando um ID responde: “o que aconteceu depois daquele clique?”
Teste uma ação (staging serve): clique “Salvar”, pegue o ID de correlação na UI ou no header da resposta, então busque por ele nos logs do servidor. Você deve ver um claro início e fim da requisição, mais quaisquer chamadas downstream.
Checklist:
- Um ID encontra o início da requisição, passos-chave e o fim da requisição.
- O mesmo ID aparece em cada job em segundo plano criado por aquela requisição (enqueue, start do job, fim do job).
- Erros incluem o ID e uma mensagem simples sobre o que falhou (não apenas uma stack trace).
- Retries mantêm o mesmo ID de correlação para a mesma ação do usuário e adicionam um número de tentativa.
- O suporte pode pedir o ID e encontrar a trilha completa sem adivinhação.
Checagens de realidade: se buscar por ID de correlação retorna só uma linha, você não está anexando a todos os logs. Se um clique gera múltiplos IDs não relacionados, você está gerando novos IDs na API ou no runner do job em vez de passar o original adiante.
Exemplo: rastreando um clique que falhou por uma API e um job
Um cliente clica “Pagar” na sua página de checkout. O botão gira por um segundo, então a UI mostra um erro genérico: “Algo deu errado.” Sem um ID compartilhado você chuta. Com IDs de correlação, você segue um fio do navegador ao backend e à fila.
No navegador, o app cria um ID assim que o clique acontece e o envia com a chamada API em um header (por exemplo, X-Correlation-Id). O usuário só o vê se você escolher exibir um código de referência em erros.
O que procurar, em ordem:
- Console do navegador:
pay_click correlationId=7f3a... - Log de acesso da API:
POST /api/pay correlationId=7f3a... status=500 - Log de erro da API:
correlationId=7f3a... error="Stripe token missing" userId=... - Registro na fila:
job=enrich_receipt correlationId=7f3a... queued - Log do worker:
correlationId=7f3a... failed error="DB timeout" retry=1
Agora a busca é rápida. Em vez de vasculhar todos os erros de pagamento da última hora, você filtra logs por correlationId=7f3a... e obtém uma linha do tempo precisa: clique às 10:14:03, erro da API às 10:14:04, retry do job às 10:14:20.
Frequentemente você descobre dois problemas ao mesmo tempo: o bug do produto (“Stripe token missing”) e a observabilidade que faltou e fez tudo parecer aleatório (o worker não logou o mesmo ID, ou a mensagem na fila o descartou).
Próximos passos se seu app é difícil de depurar hoje
Se seu app parece impossível de seguir, não tente consertar tudo de uma vez. Faça rollout em uma fatia pequena, prove que funciona e então expanda.
Comece com uma ação de usuário que costuma quebrar (por exemplo, “Salvar configurações”) e trace-a por um endpoint da API e um tipo de job. Escolha algo que você consiga acionar repetidas vezes. Quando você puder pegar um único ID no navegador e encontrar todas as linhas de log relacionadas, você construiu o padrão que vai reutilizar em todo lugar.
Escreva uma nota curta de convenção para evitar deriva:
- qual nome de header vocês aceitam e encaminham
- qual nome de campo de log vocês escrevem
- onde o ID é gerado e quando é reusado
- como é passado para jobs em segundo plano
- onde o suporte pode vê‑lo na UI
Se você herdou um protótipo gerado por IA que está quebrando em produção, muitas vezes ajuda começar com uma auditoria focada de onde os IDs e o contexto de logging se perdem entre API, filas e workers. Equipes usam FixMyMess (fixmymess.ai) para esse tipo de diagnóstico e reparo de base de código, especialmente quando precisam que o app existente vire production‑ready rápido.
Uma vez que o primeiro endpoint e job estejam rastreáveis, expanda uma fatia por vez. A depuração melhora a cada semana, sem esperar por uma grande reescrita.
Perguntas Frequentes
What is a correlation ID in plain English?
Um ID de correlação é um valor opaco único que marca um fluxo de ponta a ponta, como um clique e tudo o que ele aciona. Ele permite buscar os logs uma única vez e ver o evento no frontend, a requisição da API, chamadas downstream e tarefas em segundo plano relacionadas.
Where should the correlation ID be generated?
Crie-o na borda mais confiável possível, normalmente no primeiro ponto de entrada do backend (gateway ou middleware da API). Se o cliente enviar um ID, aceite-o apenas se corresponder ao formato esperado; caso contrário, gere um novo e use esse como fonte de verdade.
Should a correlation ID contain user or business data?
Trate-o como um rótulo de diagnóstico, não como um identificador de usuário. Não deve incluir emails, IDs de usuário, IDs de pedido ou qualquer coisa sensível, porque irá parar em logs, screenshots e tickets de suporte.
How do I pass the correlation ID from the browser to the API?
Escolha um nome de header e envie-o em todas as requisições API relacionadas à mesma ação do usuário. Também devolva-o no header da resposta para que o navegador e o suporte possam referenciar o ID exato que o servidor usou.
Should retries reuse the same correlation ID or generate a new one?
Sim, desde que as tentativas sejam pela mesma ação do usuário. Manter o mesmo ID deixa claro que várias tentativas pertencem a um único clique; você pode adicionar um contador de tentativa nos logs se precisar de mais detalhes.
How do I keep the correlation ID when work moves to a queue/background job?
Copie o mesmo ID de correlação para os metadados da mensagem ou para o payload quando enfileirar o trabalho, e faça o worker carregar esse ID no contexto de logging antes de registrar qualquer coisa. Se o worker logar sem restaurar o ID primeiro, a trilha se quebra exatamente onde você mais precisa dela.
What if one click triggers multiple background jobs?
Use um ID raiz para todo o clique e adicione um identificador separado por job para cada ramo, se precisar distingui-los. Assim você pesquisa pelo ID raiz para ver a história completa e ainda consegue identificar qual job falhou.
What should I log alongside the correlation ID to make it actually useful?
Registre-o como um campo consistente em todas as linhas relacionadas a requisições e jobs, de preferência em logs estruturados para facilitar o filtro. Uma linha no início, uma no fim, e linhas extras apenas para ramificações importantes como chamadas externas, retries e exceções é uma boa linha de base.
How can I expose the correlation ID to users and support without confusing them?
Mostre-o apenas em estados de erro como um código simples “Reference” para que usuários não técnicos possam compartilhá-lo sem confusão. Se o ID for longo, exiba uma versão curta e mantenha o valor completo disponível por um botão “Copiar” para o suporte.
What’s the quickest way to implement this in a messy or AI-generated codebase?
Geralmente é mais rápido adicionar um helper no frontend, um middleware na API e um wrapper para jobs para padronizar IDs e logging, e então expandir endpoint a endpoint. Se você herdou um app gerado por IA onde IDs, auth ou logging estão embaralhados, FixMyMess pode rodar uma auditoria de código gratuita e tipicamente corrigir problemas que quebram em produção em 48–72 horas, incluindo fazer a rastreabilidade ponta a ponta funcionar.