Implantação azul-verde para apps pequenos: trocas de tráfego e reversões mais seguras
Aprenda implantação azul-verde para apps pequenos com dois ambientes, trocas seguras, rollbacks rápidos e orientação prática para bancos de dados e sessões.
Por que apps pequenos ainda sofrem com deploys arriscados
Apps pequenos normalmente caem por motivos banais. Um deploy envia uma pequena mudança e, de repente, o login falha para todo mundo. Ou um job em background roda duas vezes e escreve linhas duplicadas. Ou uma variável de configuração aponta para o banco errado e os usuários recebem erros por uma hora.
Esses apagões parecem injustos porque o app não é “grande”. Mas o risco costuma ser maior em times pequenos: menos olhos nas mudanças, menos tempo para testar e ninguém de plantão que possa largar tudo para consertar a produção.
Os piores deploys quebram coisas que são difíceis de ver localmente. Autenticação e sessões podem falhar porque cookies são invalidados, callbacks estão mal configurados ou tokens são rejeitados. Dados ficam em risco quando migrações travam tabelas, ou quando o código grava novos campos antes deles existirem. Configurações de runtime mordem quando segredos estão faltando, variáveis de ambiente estão erradas ou regras de rede diferem do dev. E mesmo quando tudo funciona em um teste calmo, o tráfego real pode derrubar um endpoint que parecia ok em desenvolvimento.
Blue-green deployment reduz esse risco sem transformar releases em uma grande cerimônia.
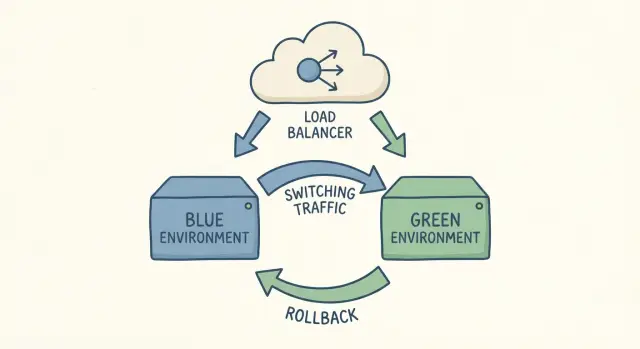
Quando se fala em “dois ambientes”, significa duas cópias completas da sua configuração de app rodando ao mesmo tempo: uma está no ar (blue) e a outra é a nova versão que você quer liberar (green). Ambas devem usar o mesmo tipo de servidor, as mesmas dependências e configurações semelhantes às de produção. A chave é que apenas uma delas recebe tráfego real de usuários.
Um cutover é simplesmente trocar o tráfego do blue para o green. Se algo der errado, você troca de volta. Essa é a ideia toda.
Não se trata de processo pesado. É sobre ter um lugar seguro para responder perguntas práticas antes que os usuários paguem o preço: o login ainda funciona, páginas chave carregam, jobs em background se comportam e é possível reverter rápido se algo foi perdido.
Um cenário comum em apps pequenos é uma mudança “rápida” feita às pressas. Funciona para você, mas quebra para os usuários porque a produção tem cookies, domínios ou segredos diferentes. Com o green esperando, você pode testar esses detalhes específicos de produção primeiro e só então virar o tráfego quando tiver confiança.
Se sua base de código foi gerada por IA e já é instável, o risco aumenta. Times muitas vezes herdam autenticação quebrada, segredos expostos e lógica enredada que se comporta diferente sob tráfego real. Blue-green não corrige código ruim por si só, mas pode evitar que um deploy ruim vire uma longa indisponibilidade.
Blue-green em termos simples
Blue-green deployment é a ideia simples de manter duas cópias prontas do seu app.
Blue é o que os usuários estão usando agora. É a versão atual no ar, lidando com tráfego real. Green é a nova versão que você quer liberar. Você a constrói, configura e testa enquanto o blue continua servindo usuários.
Quando estiver satisfeito com o green, você faz uma troca de tráfego controlada para que os usuários comecem a atingir o green em vez do blue. Essa troca normalmente acontece em um único lugar: uma regra de load balancer ou reverse proxy, um toggle da plataforma se o host suportar swap, uma configuração de roteador no gateway de containers ou (menos ideal) DNS. DNS funciona, mas o cache torna o timing menos previsível.
A grande vantagem é velocidade e confiança. Se algo der errado depois do cutover, o rollback frequentemente é só voltar o tráfego para o blue. Você não está reconstruindo a versão antiga sob pressão. Ela já está lá e funcionando.
Imagine um SaaS simples com login, cobrança e um dashboard. Você faz deploy do green com um novo layout de dashboard, testa rapidamente na infraestrutura real e então vira o switch. Se clientes reportarem gráficos quebrados, você pode voltar ao blue em minutos enquanto conserta o green.
Blue-green não resolve tudo magicamente. Duas áreas que mais pegam times:
-
Mudanças no banco de dados: se o green precisa de uma nova tabela ou colunas diferentes, é preciso planejar para que ambos, blue e green, rodem com segurança durante a transição.
-
Sessões e logins: se sessões ficam na memória de cada instância, os usuários podem ser desconectados quando o tráfego mudar. Um armazenamento de sessão compartilhado (ou autenticação stateless) previne isso.
Quando blue-green é adequado (e quando não é)
Blue-green funciona melhor quando você quer releases mais seguras sem ferramentas de release complicadas. Você mantém dois ambientes parecidos com produção, testa o novo com configurações reais e depois troca o tráfego.
É uma boa opção quando o app é majoritariamente stateless e suas mudanças são fáceis de testar ponta a ponta. Isso inclui web apps simples, APIs com requisições curtas e independentes, ferramentas internas com um conjunto conhecido de usuários e produtos SaaS iniciais que liberam pequenas mudanças com frequência. Também ajuda quando você pode arcar com rodar duas cópias durante a janela de release.
Exemplo simples: um pequeno SaaS com Next.js e uma API. Você deploya a nova versão no green, faz um smoke test rápido (login, criar um item, exportar) e então troca o tráfego. Se algo parecer estranho, você volta em minutos.
Não é uma boa opção quando a parte mais difícil do release é o banco de dados, ou quando trabalho não pode ser duplicado com segurança entre ambientes. Sinais de alerta incluem reescritas frequentes de esquema que travam tabelas, jobs longos que não podem ser pausados ou duplicados, estado pesado em memória como WebSockets ou armazenamento de sessão customizado, e efeitos colaterais de terceiros (pagamentos, emails) que você não pode reexecutar sem precauções. Também vai mal quando o time não tem uma checklist escrita de cutover e rollback.
Há um custo: você paga por duas cópias durante releases. Para apps pequenos isso pode ser barato, mas planeje o dobro de compute mais serviços duplicados (filas, caches) se você precisar deles.
Ferramentas importam menos que hábitos do time. Uma checklist curta (quem troca o tráfego, o que verificar, o que dispara rollback) evita pânico.
O que você precisa antes de tentar
Blue-green funciona melhor quando você trata blue e green como duas cópias separadas e completas da produção. Se o básico não estiver sólido, você ainda pode trocar o tráfego, mas não saberá qual lado está saudável, e o rollback pode ficar confuso.
Comece pela configuração. Blue e green devem rodar o mesmo código, mas não devem compartilhar segredos errados por acidente. Separe variáveis de ambiente claramente e facilite confirmar qual ambiente um serviço está usando. Uma falha comum é apontar o green para o banco errado, um callback OAuth incorreto ou uma chave de pagamento de teste.
Checklist mínimo de preparação
Antes do seu primeiro cutover, você quer poder dizer “sim” para isto:
- Configurações separadas para blue e green (env vars, segredos, chaves de terceiros), com nomenclatura clara e forma fácil de verificar o que está carregado.
- Um artefato de build reproduzível que é promovido (build uma vez, deploy muitas). Não reconstrua para o green.
- Um health check que prove mais do que “o servidor está no ar” (inclua dependências críticas como banco e cache).
- Monitoramento básico do que o usuário sente (taxa de erro e latência) mais uma ou duas ações chave (cadastro, checkout, upload de arquivo).
- Logs legíveis sob estresse (IDs de requisição, erros úteis e uma forma de comparar blue vs green).
Health checks merecem atenção extra. Um endpoint “200 OK” serve para o load balancer, mas você também quer um sinal mais profundo antes de cortar: por exemplo, o app consegue alcançar o banco, ler uma linha e gravar um registro leve? Se não puder testar gravações com segurança, pelo menos verifique se conecta e roda uma query simples.
Mantenha releases entediantes. A maior vantagem do blue-green é a confiança de estar trocando para exatamente aquilo que você testou. Se o build muda entre ambientes, você está testando uma coisa e entregando outra.
Passo a passo: um runbook simples de release azul-verde
Blue-green funciona melhor como uma checklist curta e repetível. Você não está tentando ser sofisticado. Está tentando ser chato e seguro.
1) Escolha como vai trocar o tráfego
Escolha um método de cutover e mantenha-se nele:
- Troca no load balancer ou reverse proxy
- Swap na plataforma (se o host suportar)
- Mudança de DNS (funciona, mas cache torna o timing imprevisível)
Decida antecipadamente quem tem acesso, quanto tempo leva e como desfazer.
2) Deploy no green para corresponder ao blue
Faça deploy da nova versão no green com a mesma “forma” do blue: mesmos serviços (fila, cache, storage), mesma abordagem de gerenciamento de segredos, mesmo setup de workers em background e configurações de runtime equivalentes. Valores podem diferir, mas a estrutura deve ser consistente.
A maioria das falhas blue-green acontece porque o green não é realmente parecido com produção. Green aponta para um banco diferente, falta um segredo que causa falha na autenticação só depois da troca, ou um runner de jobs não está conectado da mesma forma.
3) Verifique o green antes que usuários o alcancem
Execute smoke tests rápidos contra o green usando uma conta real (ou uma conta segura de staging). Mantenha simples e foque no que quebra receita e confiança:
- Fazer login e logout
- Carregar algumas páginas chave
- Criar e atualizar um registro real
- Acionar um job em background (email, webhook, relatório)
- Escanear logs por novos picos de erro
Se seu app usa caches ou workers, inicie-os cedo e deixe-os aquecer. Um padrão comum é “funcionou em teste” mas falha quando caches estão frios e workers começam a processar filas reais.
4) Troque o tráfego e monitore de perto
Troque o tráfego de forma controlada. Se sua infraestrutura permite tráfego gradual (até 10% primeiro), faça isso. Se for tudo-ou-nada, faça em um horário silencioso.
Nos próximos 10 a 30 minutos, observe um conjunto curto de sinais: taxa de erro, latência, sucesso de login, checkout ou sua ação chave, e carga do banco. Decida antecipadamente quais números significam “parar e voltar”.
Mudanças de banco de dados sem perder gravações
A parte mais difícil do blue-green geralmente não é a troca — é o banco de dados.
O risco central é simples: por um tempo, duas versões do app podem estar ativas. Se ambas falam com o mesmo banco mas esperam tabelas ou colunas diferentes, uma versão pode começar a dar erros. Pior, pode gravar dados que a outra versão não consegue ler, ou sobrescrever campos de forma inesperada.
Um padrão mais seguro é tornar mudanças no banco compatíveis com versões antigas primeiro. Adicione antes de remover. Mantenha o código antigo funcionando enquanto o novo é lançado.
Use a abordagem “expandir, depois contrair”
A maioria dos apps pequenos evita downtime dividindo o trabalho de esquema em movimentos menores:
- Expandir: adicionar colunas ou tabelas novas, mantendo as antigas.
- Gravar com sobreposição: atualizar a nova versão para gravar no novo local, enquanto mantém leituras compatíveis.
- Contrair: após o cutover e uma janela segura, remover colunas, tabelas ou caminhos de código antigos.
Exemplo: você quer renomear users.fullname para users.display_name. Não drope fullname durante a troca. Adicione display_name, envie código que grave ambos os campos (ou grave um e faça backfill no outro) e limpe depois.
Separe o deploy de migrações destrutivas
Tente não agrupar “drop column”, “rewrite table” ou “backfill de 50 milhões de linhas” no mesmo momento em que vira o tráfego. Faça trabalhos lentos ou arriscados antes, enquanto a versão atual ainda está atendendo usuários. Se uma migração vai levar minutos ou travar linhas, trate-a como pré-migração e torne-a segura com o app antigo ainda em produção.
Durante a janela de cutover, verifique compatibilidade em ambos os sentidos: app antigo lendo linhas criadas pelo novo, e app novo lendo linhas criadas pelo antigo. É aí que suposições ocultas aparecem, como listas de colunas hard-coded, ausência de tratamento de null ou defaults inseguros.
Sessões e autenticação: mantenha usuários logados na troca
A forma mais rápida de transformar uma troca segura em um pesadelo de suporte é desconectar todo mundo por acidente. Sessões geralmente quebram porque algo mudou entre blue e green: nome de cookie, chave de assinatura, formato de token ou até domínio/subdomínio.
Mantenha regras de identidade idênticas nos dois lados
Na janela de cutover, trate estes itens como contratos compartilhados que não podem mudar:
- Chaves de assinatura e criptografia de sessão (segredos de cookie, chaves JWT, segredos CSRF)
- Configurações de cookie (nome, domínio, path, Secure, HttpOnly, SameSite)
- Formatos de token e sessão (claims, regras de expiração, serialização)
- Callbacks de autenticação e URLs de redirecionamento (para OAuth)
Se precisar rotacionar chaves, faça com sobreposição. Green deve aceitar tanto a chave antiga quanto a nova para verificação, enquanto só emite novas sessões com a chave nova. Usuários existentes permanecem logados e logins novos usam a chave mais segura.
Prefira autenticação stateless (mas mantenha compatibilidade)
Se seu app puder usar tokens de acesso de curta duração mais um fluxo de refresh, cutovers ficam mais simples porque o servidor não precisa lembrar sessões. O importante é compatibilidade: green deve aceitar tokens emitidos pelo blue até que expirem naturalmente. Evite mudar nomes de claims ou regras de audience no mesmo release.
Se usar sessões server-side, compartilhe o armazenamento de sessão. Blue e green devem ler e escrever no mesmo backend (geralmente Redis ou uma tabela no banco). Se cada ambiente tiver seu próprio store, os usuários vão para o green e parecerão “desconhecidos”, mesmo com o cookie correto.
Checkout e formulários longos são pontos comuns de dor. Alguém está no meio de um pagamento, a troca acontece e a próxima requisição vai para o green. Proteja isso armazenando estado de carrinho/pedido no banco (não só na memória), usando idempotência em ações de pagamento e tornando submissões tolerantes a retries. Quando possível, troque o tráfego gradualmente e deixe o blue terminar requisições em voo antes do corte final.
Reverter rápido sem piorar a situação
No blue-green, rollback normalmente não significa desfazer mudanças de código. Significa trocar o tráfego de volta para o ambiente anterior (de green para blue). Se o roteamento for limpo, isso pode ser rápido.
O objetivo é velocidade e certeza. Escolha um dono da decisão e mantenha uma ação óbvia que reverta o tráfego (um botão, um comando, um passo no runbook). Quando todo mundo tenta um “conserto rápido” diferente, rollbacks atrasam e ficam bagunçados.
Combine gatilhos de rollback antes do cutover. Comuns são picos repentinos de 5xx/timeouts, falhas de login ou signup, falhas de pagamento, problemas claros de integridade de dados (pedidos faltando, duplicados, totais estranhos) ou salto de latência que torna o app inutilizável.
O mais difícil continua sendo o banco. Depois que o green começa a receber gravações, voltar ao blue só é seguro se o blue conseguir ler o novo formato. Se seu release incluiu uma migração que removeu uma coluna, renomeou campos ou alterou constraints, o blue pode travar ou se comportar mal silenciosamente. É assim que um rollback vira uma indisponibilidade maior.
Uma regra prática é manter mudanças no banco retrocompatíveis por uma janela curta. Adicione colunas novas primeiro, mantenha as antigas, deploy código que lide com ambos e só remova campos antigos depois que a poeira baixar.
Defina uma janela de decisão. Por exemplo: “Se vermos falhas críticas nos primeiros 10 a 20 minutos, voltamos. Depois disso, consertamos para frente a menos que haja perda de dados.” Isso evita debates intermináveis enquanto usuários estão afetados.
Sequência simples de rollback:
- Declare um dono de incidente e congele outras mudanças
- Vire o tráfego de volta para o ambiente anterior
- Verifique logins, pagamentos e os fluxos centrais do usuário
Erros comuns que causam outages
Blue-green parece simples, mas a maioria das quedas acontece nas lacunas entediantes entre “dois ambientes” e “tráfego trocado”.
Um grande erro é tratar blue e green como dois aplicativos diferentes. Começa pequeno: uma variável de ambiente faltando, um segredo rotacionado só em um lado ou uma feature flag com valores distintos. Aí vem a troca e pagamentos falham ou emails param de sair. Blue e green devem ser o mesmo build e ter a mesma forma de configuração, com as mínimas diferenças (cor do deploy e hostnames).
Outro deslize comum é trabalho em background. O tráfego web pode trocar limpo, mas o job runner ainda aponta para o ambiente antigo, ou ambos os ambientes executam a mesma tarefa agendada. Isso pode causar faturas duplicadas, notificações em dobro ou dois jobs de limpeza brigando.
Mudanças no banco são onde as pessoas mais se machucam. Times fazem uma migração breaking exatamente no momento da troca. Se o green usa o novo esquema e o blue ainda grava no formato antigo (ou vice-versa), você pode perder gravações ou corromper dados rapidamente. O padrão mais seguro é: mudanças compatíveis primeiro, deploy, troca, depois remoção de campos antigos.
Testes locais não bastam. Blue-green falha em detalhes específicos de produção: provedores de auth reais, cookies reais, caches reais, timeouts reais e carga real. Se você só testa o green no seu laptop, não está testando o que vai servir aos usuários.
Por fim, times hesitam durante um incidente porque não definiram uma regra de “parar a linha”. Decida antes o que dispara um rollback imediato: pico de erros, falhas de login passando um limite, fluxo chave (cadastro, checkout, reset de senha) quebrado, aumento de erros de banco (deadlocks, timeouts), trabalho duplicado em background, ou simplesmente não conseguir explicar o problema em alguns minutos.
Checklist rápido e próximos passos
Blue-green funciona melhor quando cada release é uma rotina curta que pega as poucas coisas que mais prejudicam os usuários: login quebrado, gravações falhando e lentidão logo após a troca.
Antes de mexer no tráfego, faça uma checagem pré-deploy: confirme health checks no novo ambiente (incluindo dependências críticas), verifique variáveis de ambiente e segredos, revise migrações quanto à segurança (aditivas primeiro, nada de exclusões surpresa) e garanta que logs e monitoramento estão funcionando.
Logo após o cutover, teste como um usuário real. Para muitos apps pequenos isso significa: cadastrar-se ou logar, criar ou atualizar um registro e completar uma ação central de dinheiro ou mensagem (checkout, pagamento, envio de convite, salvar um rascunho).
Após os primeiros minutos, pare de clicar por aí e observe sinais. Procure por mudanças, não números perfeitos: um aumento súbito de erros, pico de latência ou acúmulo em filas.
Decida as regras de rollback antes de precisar delas. Um rollback não é só uma troca — é também uma decisão sobre dados: quem tem autoridade para reverter, a ação exata e quanto tempo leva, o que acontece com gravações feitas depois do cutover, como tratar sessões e quando parar de voltar e começar a consertar para frente.
Se você herdou um app gerado por IA e os deploys continuam falhando, trate isso como um problema de saúde do código, não só de processo. Times na FixMyMess (fixmymess.ai) fazem diagnóstico de codebase, reparo de lógica, endurecimento de segurança e preparação de deploys para protótipos gerados por IA, o que pode fazer cutovers e rollbacks azul-verde parecerem previsíveis em vez de estressantes.
Perguntas Frequentes
What is blue-green deployment in simple terms?
Blue-green deployment significa manter dois ambientes completos e prontos para rodar. Um (blue) atende usuários reais, enquanto você faz deploy e testa a nova versão no outro (green). Quando estiver satisfeito, você muda o tráfego para o green; se algo quebrar, muda de volta para o blue.
Why do small apps get so much downtime from “small” deploys?
Apps pequenos costumam ter menos verificações antes de um release: menos tempo de testes, menos revisores e resposta a incidentes mais lenta. Um pequeno erro de configuração ou mudança na autenticação pode derrubar tudo. Blue-green oferece um passo seguro de “testar na infraestrutura real primeiro” sem adicionar muita burocracia.
What’s the best way to switch traffic between blue and green?
O switch mais comum é no load balancer ou no reverse proxy, porque é rápido e reversível. Se a sua plataforma de hospedagem tiver um swap de ambiente, isso pode ser ainda mais simples. DNS funciona, mas é menos previsível por causa de cache.
What should I test on green before I cut over?
Faça um smoke test rápido que reflita o que importa para os usuários: login, algumas páginas chave, uma ação de criar/atualizar e um job ou efeito colateral que você dependa. Confirme que os mesmos segredos e variáveis de ambiente da produção estão realmente carregados. Depois, monitore erros e latência logo após a troca para poder reverter rápido se necessário.
How do I avoid green pointing at the wrong database or secrets?
Trate a configuração como o principal risco. Torne óbvio em qual ambiente você está, mantenha configs separadas para blue e green e verifique dois pontos críticos: endpoints do banco de dados e URLs de callback OAuth, além de domínios de cookie e chaves de pagamento. A maioria das trocas dolorosas não é bug de código — são configurações erradas.
How do I prevent users from getting logged out during the switch?
Mantenha regras de identidade idênticas nos dois lados durante a janela de corte: chaves de assinatura/criptografia de sessão, configurações de cookie (nome, domínio, path, Secure, HttpOnly, SameSite), formato de tokens e callbacks de OAuth. Se precisar rotacionar chaves, faça com sobreposição: green deve aceitar a chave antiga e a nova enquanto só emite sessões com a nova.
How do I handle database migrations without losing writes?
Assuma que blue e green podem operar contra o mesmo banco por um tempo, então mudanças no esquema precisam ser compatíveis com versões antigas. Adicione colunas/tabelas antes de remover; faça o código escrever de forma compatível com ambos os formatos e só remova campos antigos depois de um período seguro. Evite migrações destrutivas no momento exato da troca.
When should I roll back vs fix forward?
Faça rollback trocando o tráfego de volta para o blue, não tentando reconstruir a versão antiga sob pressão. Decida gatilhos de rollback antes da troca — picos de 5xx, falhas de login, problemas de pagamento, ou inconsistências claras nos dados. Tenha cautela se green já gravou dados em um formato que o blue não consegue ler.
How do I stop background jobs from running twice in blue and green?
Executar o mesmo job agendado em ambos os ambientes pode gerar duplicatas (faturas, notificações). Antes da troca, confirme que apenas um conjunto de workers/cron jobs fará tarefas “únicas” ou periódicas durante a transição. Após a troca, verifique filas, crons e processadores de webhooks para garantir que estão apontando corretamente.
Does blue-green help if my app is AI-generated and already unstable?
Código gerado por IA frequentemente tem autenticação frágil, lógica emaranhada e tratamento inconsistente de configuração, tornando o comportamento em produção imprevisível. Blue-green limita o impacto, mas não corrige fundamentos ruins como migrações inseguras, segredos hard-coded ou sessões falhas. Se os deploys continuam a falhar, vale fazer uma revisão focalizada do código.