Limites de concorrência para workers em segundo plano que protegem seu banco de dados
Limites de concorrência para workers em segundo plano mantêm a carga do banco de dados estável ao limitar jobs paralelos e a profundidade da fila. Aprenda regras simples, checagens rápidas e um exemplo.
Por que workers em background podem sobrecarregar seu banco de dados
Um “pico no BD” costuma aparecer como uma reação em cadeia. Páginas que estavam rápidas começam a travar. Logins falham. Você vê timeouts na sua API e uma pilha crescente de jobs falhados ou re-tentados. Mesmo que só uma funcionalidade rode em background, ela pode deixar o app inteiro com sensação de quebra porque o banco de dados é o gargalo compartilhado.
Workers em background sobrecarregam bancos de dados mais rápido que tráfego web porque foram feitos para serem persistentes e paralelos. Uma requisição web é limitada por cliques de usuários e por timeouts de requisição. Workers vão puxar job após job e rodar tão rápido quanto suas CPUs permitem. Se cada job faz algumas consultas, isso vira centenas ou milhares de queries por minuto sem uma pausa natural.
A parte complicada é que isso pode parecer “queries lentas” quando o problema real é o paralelismo. Quando muitos jobs atingem o BD ao mesmo tempo, o banco fica sem conexões, começa a enfileirar trabalho internamente e tudo fica mais lento junto.
Sintomas que frequentemente apontam para concorrência como causa raiz:
- Muitas consultas diferentes ficam mais lentas ao mesmo tempo (não só um endpoint)
- Erros de pool de conexão ou mensagens de “too many connections”
- Pico de retries logo após um deploy ou quando uma tarefa agendada começa
- CPU do BD sobe enquanto o throughput não melhora
O objetivo de um limite de concorrência não é deixar os jobs mais lentos. É manter o throughput estável em vez de em rajadas: carga do BD previsível, menos incidentes e latência consistente para usuários reais.
Exemplo: um job noturno de “reconstruir índice de busca” lança 20 workers. Cada worker lê linhas, atualiza status e grava progresso. O site está calmo à noite, mas o BD ainda satura e o tráfego da manhã encontra um sistema cansado e com fila.
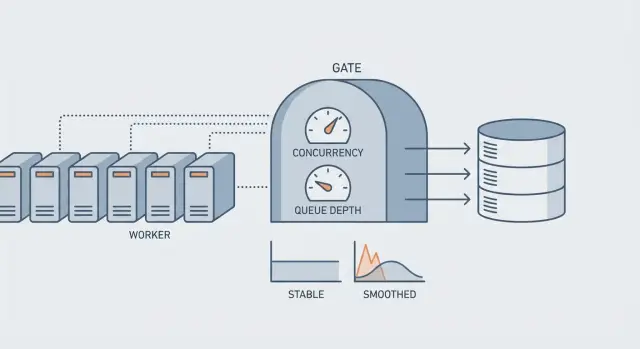
Concorrência, taxa e profundidade de fila em termos simples
Quando as pessoas dizem “precisamos de mais workers”, geralmente querem ajustar um de três controles. Cada um resolve um problema diferente, e mexer no errado pode sobrecarregar seu banco.
Concorrência é quantos jobs rodam ao mesmo tempo. Se a concorrência é 20, você pode ter 20 jobs batendo no BD em paralelo.
Taxa é com que velocidade você inicia jobs ao longo do tempo, como “5 jobs por segundo”, mesmo que pudesse rodar mais.
Profundidade da fila é quantos jobs estão esperando. A idade do backlog é há quanto tempo o job mais antigo está aguardando.
Profundidade da fila diz o volume. Idade do backlog diz a dor. Uma fila pode ser profunda e estar bem se estiver drenando constantemente. Uma fila pequena pode ser uma crise se os jobs estiverem travados e o mais antigo esperar horas.
Por que “mais workers” frequentemente piora as coisas primeiro: workers competem nas mesmas poucas partes do sistema. O gargalo oculto costuma ser o banco de dados, seja limite de pool de conexões, locks em linhas/tabelas ou transações longas. Ao aumentar concorrência, você não faz só mais trabalho. Você aumenta contenção. Requisições aguardam por conexões, transações ficam abertas por mais tempo, locks duram mais, e tudo fica mais lento.
Um exemplo rápido: 10 workers rodando cada um um job que mantém uma transação por 300 ms. Parece pouco. Mas se esses jobs tocam as mesmas tabelas, dobrar para 20 workers pode dobrar as esperas por lock e empurrar o tempo da transação para segundos. Suas requisições web passam a disputar conexões com os workers, e o app inteiro parece fora do ar embora esteja apenas sobrecarregado.
O que costuma quebrar primeiro no banco de dados
Quando workers disparam um pico, a primeira falha muitas vezes não é “o banco está lento”. É “o banco não aceita mais trabalho agora”. Isso aparece como timeouts, uma pilha de queries esperando e taxas de erro que saltam mesmo com CPU parecendo normal.
1) Exaustão do pool de conexões
A maioria das aplicações tem um pool de conexões fixo por processo. Cada thread ou processo worker precisa de uma conexão para cada query que executa. Se você sobe mais workers do que o pool suporta, eles começam a esperar por conexões. Workers esperando ainda consomem memória e ficam re-tentando, o que aumenta a pressão em todo lugar.
Um padrão comum: seu app web precisa de 20 conexões para se manter saudável, mas os workers ocupam o restante do pool e o site começa a falhar em logins ou checkout.
2) Locks por transações longas
Locking é a próxima falha comum. Mesmo se as queries forem rápidas, transações longas mantêm linhas bloqueadas. Se muitos jobs tocam as mesmas linhas ou tabelas “quentes” (por exemplo atualizando o mesmo usuário, saldo, ou um campo "last_processed_at"), o trabalho vira serial: só um job pode avançar de cada vez, e o resto espera.
As esperas por lock podem parecer lentidão aleatória, mas a causa raiz é paralelismo demais batendo nos mesmos dados.
3) Padrões de query caros nos jobs
Jobs frequentemente fazem trabalho pequeno em loops apertados, o que gera muitas consultas. Causas comuns incluem padrões N+1, atualizações por item em vez de operações em lote, recalcular agregados repetidamente, filtros sem índices, e buscar muito mais dados do que o job realmente precisa.
4) Chamadas externas dentro de uma transação
Se um job inicia uma transação e então chama uma API externa (email, pagamentos, IA, storage) antes de commitar, a conexão e os locks ficam presos enquanto o worker espera na rede. Multiplique isso por workers paralelos e você tem rápida saturação de conexões.
Limites de concorrência ajudam, mas funcionam melhor junto com transações curtas e custo de query previsível.
Como escolher limites sensatos (sem adivinhar)
Um bom limite não é um número que você acha que “parece certo”. É um número que seu banco de dados consegue aguentar em um dia ruim, quando o tráfego está alto e os cache misses disparam. O objetivo é simples: manter o BD dentro de faixas seguras de conexões e tempo de query enquanto ainda faz progresso constante.
Comece com uma linha de base conservadora ligada ao banco, não ao servidor de aplicação. Olhe para seu pool de conexões do BD (ou conexões máximas) e reserve espaço para requisições web, tarefas administrativas e migrações. Depois, considere quanto tempo em média um job mantém uma conexão.
Uma base prática:
- Reserve 50–70% das conexões do BD para tráfego online e trabalho desconhecido.
- Use os 30–50% restantes como orçamento total para todos os workers combinados.
- Comece com paralelismo baixo (frequentemente 1–3 workers por fila) e aumente só depois que a latência do BD se mantiver estável.
- Reavalie após adicionar features. Limites que funcionaram mês passado podem falhar depois de uma mudança de query ou de um índice faltando.
Não use um número global para todo job. Separe limites por fila com base no impacto no negócio. Uma fila crítica (reset de senha, onboarding) deve continuar responsiva mesmo se uma fila bulk (backfills, imports) estiver grande.
Alguns tipos de job são conhecidos por “brigar” com o BD: exports, billing runs, imports grandes, qualquer coisa que escaneie tabelas grandes. Coloque limites por job nesses casos mesmo se o pool de workers geral for maior. Por exemplo, permita 10 workers no total, mas só 1 export por vez.
Decida também o que acontece quando a fila cresce. Ignorar frequentemente causa picos surpresa depois, quando os workers se recuperam.
- Backpressure: desacelerar produtores (reduzir frequência de agendamento, adicionar delays, limitar enqueues por minuto).
- Descartar trabalho: dropar ou fundir jobs de baixo valor (juntar duplicados, manter apenas o mais recente).
- Adiar: mover tarefas pesadas para janelas de menor tráfego com limites rígidos.
- Dividir: quebrar um job gigante em pedaços menores com limite por pedaço.
Passo a passo: definir limites de concorrência e profundidade da fila
Comece nomeando seus tipos de job. Anote o que dispara cada job, com que frequência roda e se lê ou grava muitas linhas. Marque os pesados no BD (imports, analytics backfills, “sincronizar tudo”, envios de email que atualizam estado do usuário). Esses são os primeiros a controlar.
Em seguida, defina um teto de quantos jobs podem rodar ao mesmo tempo, depois divida esse teto entre filas. Uma configuração comum é uma fila padrão para trabalho normal e uma fila “pesada” para jobs intensivos no BD. Isso impede que um tipo barulhento roube todas as conexões.
Uma configuração prática inicial:
- Teto global: mantenha o total de jobs concorrentes abaixo do seu orçamento seguro de conexões do BD.
- Teto por fila: dê jobs pesados uma fatia menor que jobs rápidos.
- Teto por job (se suportado): permita apenas 1–2 instâncias de um mesmo job caro ao mesmo tempo.
- Prioridade: mantenha trabalho voltado ao usuário acima de manutenção.
- Janelas de tempo: rode filas pesadas em horas de baixo tráfego.
Depois, limite a profundidade da fila. Decida o que acontece quando a fila encher: pausar novos enqueues, adiá-los (com hora agendada) ou rejeitar com erro claro. Se sua fila heavy chegar a 1.000 jobs, você pode parar de aceitar novos imports e pedir para o usuário tentar novamente mais tarde.
Retries também podem criar picos. Adicione jitter (pequenos atrasos aleatórios) para evitar reintentos em sincronia e use backoff que cresça rápido para erros de BD como timeouts.
Implemente mudanças gradualmente. Reduza concorrência primeiro, monitore o BD, depois aumente limites em passos pequenos. Se o tempo de query subir ou conexões travarem no máximo, recue antes que usuários sintam impacto.
Monitoramento que diz se os limites estão funcionando
Limites funcionam quando seu banco permanece estável mesmo com variação no volume de jobs. Você deve ver picos controlados, não quedas súbitas onde tudo fica lento de uma vez.
Sinais do banco que importam
Monitore um conjunto pequeno de métricas juntas:
- Conexões ativas (e tempo de espera no pool)
- Contagem de queries lentas e p95 de tempo de query
- Esperas por lock e deadlocks
- Uso de CPU e pressão de memória
- IOPS de disco e latência de leitura/gravação
Se conexões estão no teto enquanto a CPU está baixa, provavelmente há muitas queries concorrentes esperando por locks ou I/O. Se a CPU está no máximo e as queries lentas aumentam, o BD está fazendo muito trabalho por consulta.
Sinais dos workers que mostram se o throttling ajuda
Monitore jobs em execução, jobs enfileirados, duração dos jobs (p50 e p95), taxa de retries e dead letters. Um sistema saudável tem uma fila que cresce e encolhe, mas a idade do backlog se mantém mais ou menos estável.
Alertas acionáveis:
- Idade do backlog subindo por 10–15 minutos
- Taxa de retries subindo junto com timeouts do BD
- Conexões do BD presas perto do máximo por vários minutos
- Duração de job subindo (especialmente p95)
Como decidir o que mudar: se reduzir concorrência acalma as métricas do BD e a duração dos jobs melhora, então você precisava de limites mais rígidos. Se reduzir concorrência mal ajuda, mas queries lentas e esperas por locks continuam altas, você precisa de queries mais rápidas ou melhores índices, não só throttling.
Exemplo: se um job noturno de email causa picos de retries e aumento de esperas por lock, o limite pode estar correto, mas a query que seleciona destinatários talvez precise de batch menor ou um índice melhor.
Erros comuns que ainda causam picos
Muitas equipes adicionam limites e ainda veem picos. Normalmente o limite foi definido com base na capacidade dos workers, não no que o banco aguenta. Definir concorrência igual ao número de núcleos de CPU pode parecer sensato, mas ignora tamanho do pool de conexões, contenção de locks e queries lentas. Um banco pode cair muito antes do host worker estar “ocupado”.
O comportamento de retry é outro gerador silencioso de picos. Retries ilimitados, ou retries que disparam todos ao mesmo tempo (como “retry em 30 segundos” para todos), podem criar uma tempestade de reintentos. Uma breve indisponibilidade vira uma segunda onda quando milhares de jobs acordam juntos e batem nas mesmas tabelas.
Design da fila também pode amplificar o problema. Se você usa uma fila única para tudo, trabalho bulk pode sufocar tarefas críticas. Um grande backfill ou export atrasa jobs voltados ao usuário, e então alguém aumenta a concorrência para recuperar o atraso — o que agride o BD ainda mais.
Durante incidentes, um erro comum é aumentar limites para “limpar a fila”. Isso muitas vezes transforma uma fila gerenciável em saturação do pool de conexões. Você pode limpar a fila mais rápido, mas também aumentar timeouts, esperas por locks e deadlocks, fazendo o backlog voltar.
Guardrails que previnem falhas usuais:
- Baseie concorrência em conexões do BD e custo de query, não em núcleos de CPU.
- Adicione jitter e backoff exponencial aos retries, com um máximo rígido.
- Separe filas para trabalho crítico vs bulk.
- Trate “aumentar limites” como último recurso e faça em pequenos passos.
- Defina uma política clara de adiar, descartar ou rejeitar quando a fila encher.
Checklist rápido antes de liberar em produção
Antes de soltar workers em produção, assuma o pior: um deploy, um restart ou uma recuperação de incidente onde cada worker acorda ao mesmo tempo. Seu banco não liga que jobs estão “em background” — ele só vê uma onda de conexões e queries.
Checklist:
- Matemática de conexões no pico está documentada. Some web servers + processos workers x threads e compare com o limite do BD (deixando folga).
- Jobs pesados estão separados e limitados. Coloque tipos caros (imports, backfills, grandes disparos de email, syncs) em filas próprias com concorrência menor que jobs normais.
- Profundidade da fila tem um teto rígido e a idade do backlog é monitorada. Um comprimento máximo evita acúmulos infinitos e um alerta na idade do job mais antigo pega lentidões cedo.
- Retries não criam tempestade. Espalhe reintentos, pare após uma janela razoável e evite retries imediatos em erros de BD por carga.
- Você tem um botão de emergência seguro. Saiba como cortar concorrência rápido (e como pausar só a fila pesada) sem redeploy.
Um exemplo prático: se um job noturno de relatório toca muitas linhas, dê a ele uma fila própria com concorrência 1–2, limite a profundidade dessa fila e alerte se o job mais antigo tiver mais que 15 minutos.
Exemplo: evitar que um job noturno derrube seu app
Imagine um SaaS onde usuários ficam ativos até tarde, e então um import noturno inicia à 1:00 AM. O import lê um CSV grande, enriquece cada linha e grava atualizações nas mesmas tabelas usadas para sign-ins, dashboards e billing.
Sem limites, o sistema de workers tenta terminar mais rápido rodando o máximo de jobs que puder. Em minutos, conexões do BD atingem o limite. Queries que levavam 50 ms passam a levar segundos. Requisições web dão timeout. Depois começam os retries, e agora você tem uma segunda onda de trabalho re-enfileirado disputando o mesmo BD.
Um plano simples muda a história:
- Coloque os imports em uma fila própria, separada de jobs críticos ao usuário (emails, webhooks, pagamentos).
- Limite a concorrência do import para um número pequeno baseado na capacidade do BD (por exemplo, 3–5 workers).
- Adicione um limite de profundidade para a fila para parar de enfileirar quando o backlog estiver grande.
- Adicione rate limiting nas operações de BD mais pesadas (como upserts) para suavizar rajadas.
Agora o import roda mais tempo, mas de forma previsível. Requisições de usuário mantêm sua fatia de conexões. Se o import gerar mais trabalho do que o sistema aguenta, ele espera em vez de causar um engarrafamento.
A troca é simples: um job em lote um pouco mais lento em troca de um app estável. A maioria das equipes prefere o import terminar mais tarde a ter tickets de suporte e rollbacks de emergência.
Quando limites não bastam (e o que mudar em seguida)
Limites de concorrência são um guarda-rail, não uma cura. Se você atinge os limites todo dia e a fila nunca fica em dia, o problema geralmente é o job, não o número de workers.
Escale workers quando o job já for eficiente e você só tiver mais volume. Corrija a lógica do job quando cada execução for pesada demais (muitas queries, trabalho repetido ou manter locks por muito tempo).
Reduza carga no BD antes de adicionar mais workers
A maioria dos incidentes vem de jobs fazendo muitas idas ao banco em paralelo. Mudanças que normalmente dão retorno:
- Trabalho em lote: atualize/inserir em chunks em vez de linha a linha.
- Torne jobs idempotentes: seguros para re-executar sem duplicar efeitos colaterais.
- Corte round trips: busque o que precisa uma vez e opere em memória.
- Adicione índices corretos: scans lentos se multiplicam sob paralelismo.
- Encurte transações: faça menos trabalho enquanto segura locks.
Exemplo: um job noturno de “recalcular estatísticas” que carrega 10.000 usuários e faz 10 queries por usuário vai detonar seu BD mesmo com baixa concorrência. Reescrever para processar em batches (ou com uma query agregada) transforma uma tempestade de queries em algumas queries previsíveis.
Separação leitura/escrita: útil, mas não mágica
Enviar trabalho somente de leitura para réplicas ajuda se o job realmente só lê e as réplicas conseguem acompanhar. Não vai ajudar quando a dor são gravações, locks de linha ou uma tabela quente que todo job toca. Monitore também o lag das réplicas: um job que lê réplica e grava no primário pode fazer decisões com dados defasados.
Se você depende de throttling para sempre, estabeleça uma meta concreta (reduzir queries por job pela metade ou manter runtime do job abaixo de 30 segundos) e reavalie limites depois de otimizar a carga.
Próximos passos para codebases geradas por IA
Apps gerados por IA frequentemente chegam com defaults inseguros porque o objetivo é “fazer funcionar” em vez de “sobreviver em produção”. É assim que você acaba com filas sem limite, workers que criam tantas tarefas quanto a máquina permite e sem backpressure quando o banco começa a desacelerar.
Um padrão comum: um job lê 50.000 linhas e faz escrita por registro sem batching. Mesmo que cada escrita seja rápida, a carga combinada pode saturar conexões, criar filas de locks e transformar requisições normais em timeouts. Nesse caso, aplicar limites sensatos ajuda, mas é só parte da correção.
Se você herdou um protótipo gerado por IA de ferramentas como Lovable, Bolt, v0, Cursor ou Replit e já vê comportamento de pico, FixMyMess (fixmymess.ai) pode começar com uma auditoria de código gratuita para apontar a origem exata da pressão no BD e recomendar configurações seguras de workers e filas antes do deploy.
Perguntas Frequentes
Por que workers em background sobrecarregam o banco de dados mais rápido que o tráfego web normal?
Workers em background podem rodar continuamente e em paralelo, gerando pressão constante no banco de dados sem pausas naturais. Se cada job faz mesmo algumas consultas, alta concorrência rapidamente vira espera no pool de conexões, contenção de locks e timeouts que afetam toda a aplicação.
Como saber se o problema é concorrência e não uma consulta lenta?
Se várias consultas não relacionadas ficam mais lentas ao mesmo tempo, isso normalmente indica contenção e não uma única consulta ruim. Erros de pool de conexões, aumento de reintentos logo após uma tarefa agendada, e CPU do BD subindo sem melhora de throughput são sinais fortes de paralelismo excessivo.
Qual a diferença entre concorrência, limitação de taxa e profundidade da fila?
Concorrência é quantos jobs rodam ao mesmo tempo. Rate limiting é quão rápido você inicia jobs ao longo do tempo. Profundidade da fila é quantos jobs estão esperando (e a idade do backlog diz há quanto tempo o job mais antigo espera). Aumentar concorrência enquanto o BD é o gargalo costuma piorar a situação antes de melhorar.
O que normalmente quebra primeiro no banco de dados durante um pico de workers?
A exaustão do pool de conexões costuma ser a primeira falha: workers e requisições web competem por um número limitado de conexões. Depois disso, transações longas e locks em linhas/tabelas tornam o trabalho efetivamente serial, então mais workers só significam mais espera.
Por que é perigoso chamar APIs externas dentro de uma transação de BD?
Mantenha transações curtas e evite chamadas de rede enquanto uma transação está aberta. Se um job chama uma API externa dentro de uma transação, ele prende conexão e locks enquanto espera; multiplicado por workers paralelos, uma pequena latência vira uma grande falha.
Como escolher um limite seguro de concorrência sem adivinhar?
Comece orçando conexões do BD: reserve a maior parte para tráfego web e trabalho desconhecido, e aloque o restante para todos os workers combinados. Comece com baixa concorrência por fila e só aumente se latência do BD e esperas por locks se mantiverem estáveis sob carga.
Devo usar uma fila única para tudo ou separar filas?
Separe jobs por impacto e custo no BD, para que trabalho bulk não consiga bloquear tarefas críticas para o usuário. Dê filas pesadas uma concorrência menor e considere limites por job para "agressores do BD" conhecidos como exports, backfills e imports grandes.
Como devo limitar a profundidade da fila e o que acontece quando ela enche?
Defina um teto rígido e escolha o comportamento quando ele for atingido: adiar, pausar produtores ou rejeitar novos trabalhos bulk com uma mensagem clara. Um limite de profundidade evita acúmulos infinitos e força um tratamento intencional da sobrecarga.
Como evitar que reintentos criem um segundo pico?
Use jitter mais backoff exponencial com um prazo máximo de reintentos, especialmente para timeouts do BD. Sem jitter, muitos jobs reexecutam ao mesmo tempo e geram uma "tempestade de retries" que transforma uma lentidão breve em uma nova falha.
Quais métricas mostram que meus limites estão funcionando e o que mudar em seguida?
Monitore conexões do BD e tempo de espera no pool, p95 de tempo de query, esperas por locks/deadlocks e idade do backlog junto com taxas de retry. Se reduzir concorrência estabiliza métricas e melhora duração dos jobs, os limites estavam altos; se não, provavelmente é preciso otimizar queries ou índices.