Error boundaries no Next.js com Retry para recuperação do usuário
Aprenda a criar error boundaries no Next.js com Retry que mostram uma mensagem clara, capturam contexto para suporte e ajudam usuários a se recuperar em vez de verem uma tela em branco.
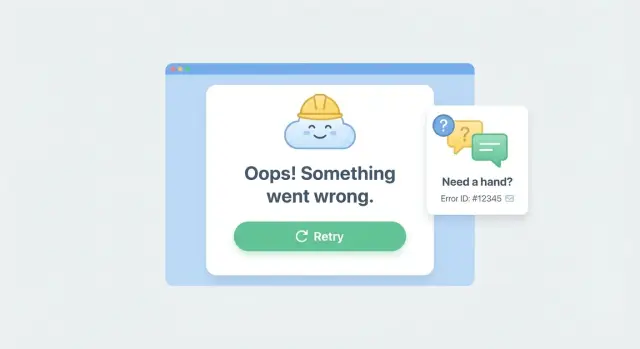
Por que telas em branco fazem os usuários irem embora (e perdem a confiança)
Quando um app trava e mostra uma tela em branco, a maioria das pessoas presume que fez algo errado. Elas clicam em voltar, atualizam a página ou fecham a aba — e geralmente não retornam.
O dano real não é o erro em si. É a incerteza: "Meu trabalho foi salvo?", "Minha conta quebrou?", "Isso é seguro de usar?" Uma falha silenciosa ensina os usuários a não confiar em cada botão.
Telas em branco também escondem o que importa no momento: o próximo passo. Se o checkout falhar, o usuário precisa de uma maneira de tentar novamente. Se um envio de formulário falhar, ele precisa saber se a operação foi concluída e como evitar digitar tudo de novo.
A recuperação importa mais do que a redação perfeita porque as pessoas estão tentando completar uma tarefa, não ler uma explicação. Uma boa experiência de erro mantém o app utilizável quando possível. Quando não é possível, ela guia o usuário para a próxima melhor ação.
Um objetivo prático para a UI de fallback:
- Dizer ao usuário o que aconteceu em linguagem simples
- Oferecer uma ação clara (Tentar novamente, Recarregar, Voltar)
- Proteger o trabalho do usuário (manter o estado do formulário, se possível)
- Fornecer uma forma de obter ajuda (com um código de referência)
É por isso que error boundaries com uma ação Retry são tão eficazes: transformam um beco sem saída em um desvio. Mesmo um botão simples "Tentar novamente" pode salvar uma sessão quando o crash foi um problema temporário de rede ou uma API instável.
Às vezes mostrar uma tela de erro útil é melhor do que esconder as falhas. Se seu app quebra em produção, fingir que está tudo bem só desperdiça o tempo do usuário. Uma tela de recuperação clara transforma relatos vagos como "parou de funcionar" em algo acionável.
O que os error boundaries do React e Next.js realmente fazem
Um error boundary é uma rede de segurança para sua UI. Quando um componente dá erro durante a renderização (ou em um método de ciclo de vida), o boundary pode capturar essa falha e mostrar uma tela de fallback em vez de derrubar a página inteira.
Em termos simples, ele captura problemas que acontecem enquanto o React tenta desenhar a tela. Ele não captura erros em manipuladores de evento (como um clique), erros em código assíncrono que roda depois (como uma promise de fetch), ou problemas fora do React (como uma extensão do navegador quebrando algo). Esses casos precisam de tratamento próprio.
No Next.js, ele também ajuda a separar falhas do cliente e do servidor.
Erros no cliente são crashes no código rodando no navegador do usuário (um componente quebrado, estado incorreto, forma de dados inesperada). Erros no servidor acontecem enquanto o Next.js constrói a página no servidor (uma query ao banco falha, uma API dá timeout, checagens de auth disparam).
Uma boa UI de fallback deve ajudar uma pessoa real a dar o próximo passo:
- Dizer o que aconteceu em palavras simples (sem stack traces)
- Oferecer uma ação como Retry ou Recarregar
- Manter o resto da página utilizável quando possível
- Fornecer um pequeno código de suporte para que alguém possa ajudar
O maior ganho é reduzir o blast radius. Em vez de um widget ruim quebrar o checkout, apenas aquele widget falha enquanto o carrinho, a navegação e os campos do formulário continuam vivos.
O padrão recovery-first: mensagem + ação + contexto
Um bom error boundary não é só um capturador de crashes. É uma tela de recuperação que ajuda alguém a terminar o que veio fazer. O objetivo é reduzir o pânico, oferecer um próximo passo seguro e capturar detalhes suficientes para corrigir a causa raiz.
Um fallback recovery-first tem três ingredientes: uma mensagem clara, uma ação segura que o usuário pode tomar agora mesmo, e um pequeno pedaço de contexto que ele pode compartilhar com o suporte (como um ID de referência).
Comece pela ação, não pelo pedido de desculpas. Se uma seção da página falhar, permita que o usuário tente novamente só aquela seção. Se a rota inteira falhou, ofereça Recarregar a página ou Voltar. Mantenha ações de baixo risco: elas não devem apagar dados ou repetir uma compra acidentalmente.
Para a mensagem, diga o que o usuário precisa saber, não o que o código sabe. Evite stack traces, nomes de componentes ou "TypeError: undefined is not a function". Uma mensagem melhor é: "Não foi possível carregar seus projetos. Suas alterações estão salvas. Tente novamente."
Depois, adicione contexto que transforme um relato vago em algo reproduzível. Mostre um ID de referência curto como ERR-7F3A2C e um timestamp. Se você logar esse mesmo ID, o suporte pode achar o erro correspondente rapidamente.
Planeje seus boundaries antes de escrever código
Error boundaries funcionam melhor quando você os trata como parte do design do produto, não como um remendo de última hora. Antes de adicionar componentes, decida o que "recuperação" significa para cada parte do app.
Comece mapeando onde as falhas devem ser contidas. Um boundary no nível de página é útil quando a rota inteira depende de uma única requisição ou de um layout crítico. Boundaries menores, a nível de componente, funcionam melhor quando é possível manter o resto da página utilizável (por exemplo, a sidebar carrega mas o feed de atividade falha).
Uma regra rápida de posicionamento:
- Coloque um boundary no nível de página/rota para fluxos críticos como checkout, login ou salvar configurações.
- Coloque um boundary ao redor de widgets opcionais como recomendações, gráficos ou comentários.
- Adicione um boundary em integrações de risco como SDKs de terceiros, editores embutidos e uploads de arquivo.
- Evite envolver cada componente pequeno. Isso torna os erros mais difíceis de entender.
Em seguida, defina o que Retry realmente faz. Retry deve ser previsível: re-renderizar o segmento, refetch dos dados ou resetar uma fatia específica de estado. Se Retry só reproduzir o mesmo estado quebrado, usuários vão apertar o botão em loop e ficar presos.
Deixe o comportamento explícito com uma regra simples: "Retry reseta X e refaz Y." Por exemplo, se "Salvar perfil" falhar, retry deve reexecutar a requisição de salvar e reabilitar o formulário, não apagar o que o usuário digitou.
Por fim, decida que contexto você vai capturar para o suporte e o que nunca mostrará. Contexto útil pode ser tão simples quanto nome da rota/tela, o que o usuário clicou, timestamp e ambiente (prod vs staging), e um código curto de erro. Tenha linhas vermelhas estritas: nunca inclua segredos, tokens, corpos completos de requisição ou dados pessoais na UI.
Passo a passo: adicionar error boundaries com Retry no Next.js
Um bom error boundary faz duas coisas: diz ao usuário o que aconteceu em palavras simples e dá um próximo passo claro (Retry ou voltar). Aqui vão duas maneiras práticas de adicionar isso.
App Router: error.tsx + reset()
No App Router, adicione um arquivo error.tsx dentro do segmento de rota que você quer proteger. O Next.js o renderizará quando algo nesse segmento lançar.
'use client'
export default function Error({
error,
reset,
}: {
error: Error & { digest?: string }
reset: () => void
}) {
return (
<div style={{ padding: 16 }}>
<h2>Something went wrong</h2>
<p>Try again. If it keeps happening, you can go back to a stable page.</p>
<div style={{ display: 'flex', gap: 8, marginTop: 12 }}>
<button onClick={() => reset()}>Retry</button>
<button onClick={() => (window.location.href = '/')}>Go to Home</button>
</div>
<p style={{ marginTop: 12, fontSize: 12, opacity: 0.8 }}>
Error code: {error.digest ?? 'unknown'}
</p>
</div>
)
}
Use rótulos amigáveis. "Retry" é mais claro que "Reset boundary", e "Go to Home" é mais seguro do que deixar alguém preso.
Pages Router: componente ErrorBoundary reutilizável
Se você estiver no Pages Router (ou quiser um wrapper que possa ser colocado ao redor de um widget específico), use um componente de classe React.
import React from 'react'
type Props = { children: React.ReactNode; fallback?: React.ReactNode }
type State = { hasError: boolean }
export class ErrorBoundary extends React.Component<Props, State> {
state: State = { hasError: false }
static getDerivedStateFromError() {
return { hasError: true }
}
retry = () => this.setState({ hasError: false })
render() {
if (this.state.hasError) {
return (
this.props.fallback ?? (
<div style={{ padding: 16 }}>
<h2>We hit a problem</h2>
<p>You can retry, or go back to a stable page.</p>
<button onClick={this.retry}>Retry</button>{' '}
<button onClick={() => (window.location.href = '/')}>Go to Home</button>
</div>
)
)
}
return this.props.children
}
}
Coloque esse boundary ao redor da menor área arriscada (um formulário complexo, widget de pagamento ou painel pesado em dados) para que o resto da página continue utilizável.
Adicione contexto de suporte sem expor dados sensíveis
Quando algo falha, usuários não querem um mistério. Dê a eles uma referência simples que possam compartilhar, e capture contexto suficiente para que você reproduza o problema.
Comece gerando um ID de erro (uma string curta aleatória ou UUID). Mostre na UI de fallback como "Error ID: ABC123" e facilite a cópia. Se o usuário apertar Retry, mantenha o mesmo ID para que você conecte a primeira falha à tentativa de retry nos logs.
Capture contexto leve que responda: onde eles estavam, o que tentavam fazer e quando aconteceu. Normalmente você precisa de poucos campos:
- Rota ou página (por exemplo, /settings/billing)
- Área de recurso (Billing, Checkout, Editor)
- Última ação do usuário (Clicou em "Salvar", Enviou formulário)
- Timestamp e fuso horário
- Versão/build do app
Envie ou armazene o erro detalhado com segurança. Uma boa regra: se você não colaria aquilo em um chat público, não colete automaticamente. Evite segredos (API keys, tokens), corpos completos de requisição, senhas, detalhes de pagamento e cookies brutos. Se logar no servidor, prefira redaction e allowlists (registre apenas os campos esperados).
Se adicionar um botão "Reportar" ou "Contatar suporte" na UI de erro, pré-preencha o ID de erro e o contexto básico para que o usuário não precise explicar tudo.
Projetando a UI de fallback que os usuários realmente usam
Uma boa tela de erro deve parecer um pouso seguro, não um beco sem saída. Pule termos técnicos e evite culpar o usuário. "Algo deu errado" já é suficiente. "Token inesperado em JSON" é ruído.
Mantenha a estrutura da página familiar para que ainda pareça seu app. Preserve o cabeçalho, a navegação e o espaço onde o conteúdo normalmente aparece. Quando o layout permanece estável, as pessoas têm mais probabilidade de tentar novamente em vez de ir embora.
Deixe o próximo passo óbvio. O botão primário deve ser o centro visual da tela, não um link pequeno. Coloque a ação primária primeiro e nomeie-a em linguagem simples.
Um conjunto simples de ações que cobre a maioria dos casos:
- Retry
- Voltar
- Recarregar a página
- Contatar suporte
Adicione uma frase curta que diga o que acontece se eles tentarem novamente (por exemplo, "Vamos tentar carregar seus dados outra vez"). Se houver chance de perda de alterações, diga isso claramente e ofereça uma opção mais segura como "Copiar detalhes" ou "Salvar rascunho" se você tiver.
Acessibilidade importa aqui. Quando o fallback aparecer, mova o foco do teclado para o heading ou para o botão primário para que usuários de leitor de tela e teclado saibam que algo mudou. Garanta contraste legível, alvos de toque grandes e que Enter e Space ativem o botão principal.
Finalmente, inclua contexto pequeno e não sensível que ajude o suporte sem assustar os usuários: um timestamp, um código de referência curto e o que eles estavam tentando fazer ("Salvando configurações").
Erros comuns (e como evitá-los)
Error boundaries servem para proteger usuários, não para esconder problemas. Uma tela amigável não ajuda se o mesmo bug continuar acontecendo. Isso só move a dor da UI para o suporte.
Os maiores erros costumam ser simples.
Erros que silenciosamente pioram as coisas
- Capturar demais: Um boundary global pode transformar um pequeno "widget de perfil falhou" em uma falha de página inteira. Coloque boundaries em volta de features para que o resto da página continue funcionando.
- Retry sem saída: Se Retry continua falhando, usuários ficam presos. Depois de 1–2 tentativas, ofereça um caminho diferente (voltar, recarregar ou contatar suporte).
- Mostrar texto bruto de erro: Stack traces e mensagens de banco assustam usuários e podem vazar detalhes. Mostre uma mensagem simples e mantenha o técnico nos logs.
- Sem ID de erro: Se o suporte não consegue relacionar o que o usuário viu com o que foi logado, triagem vira palpites.
- Fallback genérico para tudo: "Algo deu errado" sempre treina usuários a abandonar o app. Personalize o fallback para a feature: salvar, carregar, auth, pagamentos.
Como evitar (regras simples)
Trate retry como ferramenta de recuperação, não como botão de reset. Desabilite o botão Retry enquanto a tentativa está em andamento e mude a mensagem se falhar novamente.
Inclua contexto para debug sem expor segredos: error ID, horário, nome da página/feature e última ação. Mantenha tokens, emails e payloads completos fora da UI.
Teste o caminho de falha de propósito. Desligue a rede, force um 500 e confirme que a UI dá um próximo passo claro e algo rastreável para o suporte.
Checklist rápido antes de enviar para produção
Antes de lançar error boundaries com retry, faça uma rodada focada em recuperação real do usuário. Você quer provar duas coisas: o fallback aparece quando deve, e o usuário tem um caminho claro de volta ao que estava fazendo.
Dispare um erro controlado de propósito (por exemplo, jogue inside de um componente que normalmente carrega dados). Então verifique:
- O fallback renderiza com uma mensagem clara (sem stack traces).
- Retry ou recupera totalmente ou falha de novo com uma UI calma e consistente.
- Um ID de erro é mostrado ao usuário e aparece nos logs.
- A UI e os logs não contêm segredos ou dados pessoais (tokens, emails, queries completas, headers de requisição).
- O fluxo funciona em celular e em conexão lenta. Botões devem ser fáceis de acertar e Retry não deve spammar requisições.
Confirme que Retry reseta qualquer estado travado, desabilita-se enquanto roda e mostra um status curto como "Tentando novamente...". Se Retry não puder funcionar (offline, permissões faltando), diga isso e ofereça uma ação segura.
Um exemplo realista: "Falha ao salvar" sem perder o usuário
Um usuário edita seu endereço de cobrança e clica em Salvar. A requisição bate num backend instável, retorna 500 e uma parte da UI dispara um erro. Sem boundary, a página pode cair numa tela em branco. O usuário fica preso, sem saber se as alterações foram salvas, e provavelmente abandona o fluxo.
Com uma configuração recovery-first, o error boundary captura o crash e mostra um fallback que mantém o usuário orientado. O formulário permanece na tela se possível (ou re-renderiza com os últimos valores digitados), e a mensagem é simples: "Não conseguimos salvar suas alterações." Oferece um próximo passo óbvio: Retry. Se Retry falhar de novo, o usuário ainda tem uma saída segura como "Voltar ao painel" ou "Cancelar alterações".
O que torna isso utilizável é o contexto extra que viaja com o erro, sem expor dados sensíveis:
- O usuário vê uma mensagem curta, um botão Retry e uma maneira clara de sair da página.
- O usuário vê um ID de erro que pode copiar (exemplo: FM-8K2Q) ao contatar o suporte.
- O suporte vê o ID de erro mais contexto básico: rota, timestamp, versão do app, navegador e última ação.
- O suporte pode reproduzir mais rápido porque sabe qual requisição falhou e qual estado a UI tinha, sem precisar que o usuário explique tudo.
Próximos passos: implante com cuidado e peça ajuda se estiver complicado
Trate error boundaries como qualquer outra feature de interface: lance em passos pequenos, monitore o que acontece e então expanda.
Comece por um fluxo frágil onde um crash faz mais mal, como checkout, login ou salvar. Adicione um boundary, garanta que o fallback explique o que aconteceu em palavras simples e confirme que Retry realmente faz algo útil (não apenas retriga o mesmo crash).
Antes de espalhar boundaries por todo o app, decida propriedade. Alguém precisa revisar o copy de erro, as ações (Retry, Voltar, Contatar suporte) e o contexto de suporte para que continue útil e seguro.
Se você está implementando isso em um codebase gerado por ferramentas de IA, espere surpresas: estado emaranhado, fluxos de salvar frágeis, auth quebrado, segredos expostos ou queries inseguras que tornam o "Retry" impossível. Se precisar de diagnóstico rápido e um plano prático de correção, FixMyMess (fixmymess.ai) se concentra em transformar protótipos gerados por IA em software pronto para produção, incluindo diagnóstico de codebase, reparo de lógica, endurecimento de segurança e preparação de deploy.
Perguntas Frequentes
Por que telas em branco fazem os usuários irem embora tão rápido?
Uma tela em branco gera incerteza. Usuários não sabem se o trabalho foi salvo, se a conta ficou comprometida ou o que fazer a seguir, então acabam indo embora.
Um fallback simples que explica o que aconteceu e oferece um próximo passo seguro mantém as pessoas em andamento em vez de abandonar a tarefa.
Que problemas os error boundaries do React pegam (e não pegam)?
Um error boundary captura falhas que ocorrem durante a renderização de componentes React e mostra uma UI de fallback em vez de quebrar a página inteira.
Ele não captura erros de manipuladores de evento (como um clique), rejeições de promises assíncronas que acontecem depois, ou problemas fora do React — então você ainda precisa de try/catch e tratamento de erros em requisições.
Quando devo usar `error.tsx` vs um ErrorBoundary reutilizável?
Use error.tsx no App Router quando quiser que o Next.js renderize automaticamente uma UI de recuperação para um segmento de rota quando algo lançar.
Use um componente ErrorBoundary reutilizável quando quiser proteger um widget ou parte específica da página para que o resto da UI continue utilizável.
O que uma boa UI de fallback deve dizer e fazer?
Um padrão prático é: uma mensagem simples, uma ação primária (normalmente Retry) e uma saída (Voltar ou Home).
Se puder, reafirme o estado, por exemplo “Suas mudanças foram salvas” ou “Pode ser necessário tentar novamente”, mas só diga isso quando tiver certeza.
O que o botão Retry realmente deveria fazer?
Retry deve redefinir a parte quebrada da UI e reexecutar exatamente o que falhou, como refazer uma requisição de dados ou tentar salvar novamente.
Se Retry só re-renderizar o mesmo estado ruim, usuários ficarão presos — faça com que Retry mude algo significativo (resetar um slice de estado, limpar cache ou refazer uma requisição).
Como evitar prender usuários em um loop infinito de Retry?
Depois de uma ou duas tentativas falhas, mude a UI de “Tentar novamente” para oferecer uma saída como Voltar, Recarregar a página ou Contatar suporte.
Isso evita que usuários fiquem apertando o botão indefinidamente e dá um caminho claro para continuar o trabalho em outro lugar estável.
Que contexto de suporte devo mostrar aos usuários quando algo quebra?
Mostre uma referência curta, como um Error ID, juntamente com um timestamp, e logue o mesmo ID no seu backend.
Mantenha leve e não sensível para que o usuário possa copiar com segurança para uma mensagem de suporte sem expor dados privados.
Que dados nunca devem aparecer na tela de erro?
Não mostre stack traces, tokens, cookies, corpos completos de requisição, dados de pagamento ou qualquer coisa que você não gostaria que fosse publicada em uma conversa pública.
Uma regra segura é exibir apenas um código de erro curto e contexto básico como “Salvando configurações”, mantendo detalhes técnicos em logs protegidos com redaction.
Onde devo colocar error boundaries em um app Next.js?
Coloque boundaries ao redor das menores áreas de risco para que um widget com falha não derrube o checkout ou a página inteira.
Use boundaries de página/rota para fluxos críticos como login e pagamento, e boundaries de componente para painéis opcionais como gráficos, comentários ou embeds de terceiros.
Como posso testar error boundaries antes de lançar?
Force falhas de propósito: jogue um erro dentro de um componente, simule uma resposta 500 e teste no modo offline para ver a experiência do usuário.
Confirme que o fallback aparece, que Retry não dispara requisições em spam e que o Error ID bate com o que você loga, sem vazar segredos.