Limpeza de dados após um protótipo apressado: dedupe e reparo de integridade
Limpeza de dados após um protótipo apressado: passos de deduplicação e reparo de integridade para encontrar duplicados, consertar linhas órfãs, aplicar constraints e validar com scripts.
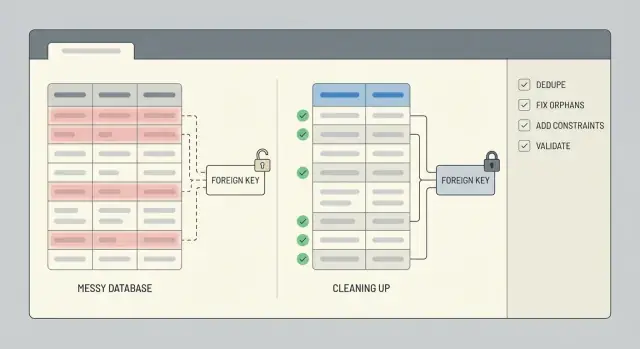
O que costuma quebrar depois de um protótipo apressado
Um protótipo apressado é feito para provar um ponto, não para proteger seus dados. Regras costumam faltar, campos mudam de nome no meio do desenvolvimento, e alguém acaba “corrigindo direto no banco” para desbloquear um problema. Se o app foi gerado por uma ferramenta de IA, você também vê padrões de cópia rápida: tabelas sobrepostas, IDs armazenados como texto em um lugar e números em outro, e lógica que salva o mesmo registro duas vezes.
Duplicados aparecem de maneiras chatas e caras: duas contas de usuário com o mesmo email em diferenças de caixa, várias assinaturas “ativas” para um cliente, ou o mesmo pedido salvo no clique e de novo ao atualizar a página. Às vezes não são correspondências exatas. Você pode ver quase-duplicados como “Acme, Inc” vs “ACME Inc.” ou dois contatos compartilhando um telefone.
Relacionamentos quebrados são igualmente comuns. Você encontrará pedidos apontando para um user_id que não existe mais, comentários ligados a um post deletado, ou linhas que referenciam 0 ou string vazia porque o app nunca validou entradas. Essas linhas órfãs nem sempre derrubam a aplicação, mas quebram silenciosamente totais, dashboards e exportações.
Usuários percebem dados ruins como problemas de login, totais errados (pedidos contados em dobro, estoque inflado), histórico faltando e telas que funcionam para alguns registros e não para outros.
Limpe agora se você vai cobrar, precisa de relatórios confiáveis ou o suporte está gastando tempo consertando registros à mão. Esperar só dificulta: cada nova feature grava mais dados sobre a bagunça.
Antes de mexer nos dados: snapshot, escopo e rollback
A limpeza dá errado quando você começa a editar linhas sem saber o que importa e como desfazer mudanças. Trate isso como uma operação controlada, não um conserto rápido.
Comece mapeando as partes do banco que afetam pessoas e dinheiro. Liste as tabelas e os fluxos de usuário que elas suportam: cadastros, checkout, assinaturas, publicação de conteúdo. Se você pular isso, pode deduplicar uma tabela e acidentalmente quebrar um fluxo a jusante que ainda espera a forma antiga.
Uma nota simples de escopo costuma bastar: users, sessões/autenticação, orders, payments, invoices, subscriptions e tabelas centrais de conteúdo (posts, comments, files). Também anote a fonte da verdade para cada campo chave (por exemplo, se você confia mais num external_id do provedor de pagamento que em um email).
Em seguida, faça um snapshot seguro e defina rollback antes de executar um único UPDATE. O snapshot pode ser um backup do banco, um ponto de restauração, ou uma cópia exportada das tabelas afetadas. Rollback não é “vamos ter cuidado”. É um passo escrito: como restaurar, quanto tempo leva e quem pode fazê-lo.
Sempre que possível, execute a limpeza em uma cópia primeiro. Um clone recente da produção em staging é ideal porque contém casos de borda reais sem arriscar dados ao vivo. Só vá para produção quando seus scripts forem repetíveis e os resultados previsíveis.
Finalmente, defina uma janela de tempo. Se possível, congele ou blinde escritas arriscadas (novos cadastros, criação de pedidos, jobs de sincronização) durante a limpeza. Se não der para congelar, registre um timestamp de corte e limite suas mudanças a registros criados antes daquele ponto.
Decida o que é um duplicado (e o que você vai manter)
Antes de deletar qualquer coisa, seja específico sobre o que “duplicado” significa para seu app. Em um protótipo, duas linhas podem parecer idênticas para uma pessoa, mas ainda representar usuários ou eventos diferentes na vida real. Se você errar, a limpeza vira perda de dados.
Comece escolhendo a fonte da verdade para cada entidade. Para usuários, pode ser o registro atrelado a um login verificado, a conta mais antiga, ou a que é referenciada pelo maior número de pedidos. Para pedidos, pode ser a linha que realmente foi paga, e não a criada numa tentativa de checkout que falhou.
Escreva regras simples de merge e siga-as. Decida como resolver conflitos e como tratar campos em branco. Algumas regras cobrem a maioria dos casos:
- Se um registro tem um valor e o outro é nulo, mantenha o valor.
- Se ambos têm valor, prefira o verificado ou o mais recentemente atualizado.
- Não sobrescreva campos de auditoria importantes (
created_at,signup_sourcee campos semelhantes).
Depois, decida a chave canônica que usará para identificar duplicados. Opções comuns são email, um external_id de um provedor de autenticação, número de telefone, ou um composto como (workspace_id, normalized_email). Tenha cuidado: protótipos costumam armazenar emails com caixa diferente, espaços extras ou variações de plus-addressing.
Casos de borda queimam equipes. Caixas compartilhadas (team@), contas de teste, CSVs importados com emails placeholder e dados seed gerados por IA podem criar repetições legítimas. Capture essas exceções desde o início e mantenha uma lista curta de padrões que você vai excluir da deduplica.
Métodos para detectar duplicados
Comece pelo sinal mais simples: duas linhas que compartilham a mesma chave. Mesmo que seu protótipo nunca tenha definido uma chave verdadeira, geralmente você tem algo próximo (email, external_id, order_number ou uma combinação natural como user_id mais dia de criação).
Um primeiro passo rápido é contar por essa chave suspeita, filtrando para chaves que aparecem mais de uma vez:
SELECT email, COUNT(*) AS c
FROM users
GROUP BY email
HAVING COUNT(*) > 1
ORDER BY c DESC;
Em seguida, procure por quase-duplicados. Normalize o campo na query para ver colisões que passariam despercebidas:
SELECT LOWER(TRIM(email)) AS email_norm, COUNT(*) AS c
FROM users
GROUP BY LOWER(TRIM(email))
HAVING COUNT(*) > 1;
Também verifique duplicados gerados por retries. Se seu app insere o mesmo evento duas vezes após um timeout, você pode ver múltiplas linhas com o mesmo event_id, provider_charge_id, idempotency_key, ou (user_id + exact payload hash). Se não tiver esses campos, o padrão costuma ser linhas idênticas criadas segundos uma da outra.
Antes de deletar ou mesclar qualquer coisa, construa uma amostra para revisão. Pegue os 20 principais grupos de duplicados e inspecione manualmente para saber o que “manter” deve significar. Puxe os conjuntos duplicados completos para revisão, compare timestamps, verifique se linhas filhas (orders, sessions, invoices) apontam para um dos duplicados e escreva a regra que vai aplicar. Salve a query que produziu sua amostra para poder rodá-la novamente depois das mudanças.
Deduplicação sem perder histórico importante
Se outras tabelas apontam para um registro, deletá-lo costuma ser a forma mais rápida de criar problemas novos. Uma abordagem mais segura é mesclar duplicados e reapontar tudo para uma única linha keeper para que o histórico permaneça conectado.
Escolha um keeper para cada grupo de duplicados, mova referências dos IDs perdedores para o ID keeper, depois arquive os perdedores ou marque-os como inativos. Isso evita quebrar orders, invoices, mensagens e permissões que ainda precisam estar ligadas à mesma pessoa ou conta.
Quando duplicados discordam, decida previamente como resolver conflitos. Mantenha previsibilidade: prefira registros verificados sobre não verificados, prefira status pago/ativo sobre gratuito/inativo, mantenha valores válidos mais recentes quando ambos parecem razoáveis e nunca sobrescreva campos não vazios com campos vazios.
Mantenha um rastro de auditoria para que o trabalho seja reversível. Uma tabela de mapeamento pequena como dedupe_map(old_id, new_id, merged_at, reason) permite responder “o que aconteceu com este usuário?” meses depois e facilita depuração.
Não se esqueça dos dados ao redor da linha. Perfis, configurações, memberships, arquivos enviados e notas muitas vezes vivem em tabelas separadas. Reaponte essas linhas filhas primeiro e fique atento a conflitos de unicidade (por exemplo, duas linhas de configuração que precisam virar uma só).
Execute a dedupe em lotes (por exemplo, 100 a 1.000 grupos por vez). Lotes menores reduzem tempo de lock, facilitam isolar falhas e dão chance de inspecionar resultados entre execuções.
Encontrar e reparar linhas órfãs
Um órfão é uma linha que aponta para algo que não existe. Na prática, é uma linha filha cujo parent_id não corresponde a nenhum pai existente. Isso aparece muito depois de protótipos apressados, especialmente quando o app pulou transações ou deletou registros sem limpar tabelas relacionadas.
Comece medindo o problema. Um simples left join diz quantas linhas filhas não encontram pai:
-- Example: orders should reference users
SELECT COUNT(*) AS orphan_orders
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
WHERE u.id IS NULL;
-- Inspect a sample to understand patterns
SELECT o.*
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
WHERE u.id IS NULL
LIMIT 50;
Se você usa soft deletes, fique atento a "órfãos escondidos": o pai existe, mas foi logicamente removido (por exemplo users.deleted_at IS NOT NULL). Decida se esses ainda contam como válidos.
Uma vez que você saiba com o que está lidando, escolha um caminho de reparo baseado no significado dos dados:
- Recriar o pai ausente quando realmente falhou ao salvar.
- Reatribuir a criança a um pai real (comum após dedupe de usuários).
- Arquivar ou deletar a criança órfã se não puder ser confiável (dados de teste, escritas parciais).
- Criar um pai “Unknown” ou “System” apenas se a lógica do produto aceitar isso limpamente.
Seja o que for, registre cada mudança para poder reexecutar com segurança. Um bom padrão é: gravar mudanças em uma tabela de staging (ou marcar linhas com um batch ID), atualizar em pequenos lotes e logar contagens antes e depois.
Imponha integridade com constraints (e os índices certos)
Depois da limpeza, constraints são o que impedem a mesma bagunça de voltar na semana seguinte. Adicione-as só depois que você deduplicar e reparar relacionamentos quebrados, ou vai bloquear seu próprio trabalho.
Comece com chaves primárias. Garanta que cada tabela tenha uma, que seja realmente única e que nunca seja reutilizada. Se seu protótipo usou IDs significativos (por exemplo um ID baseado em hash de email), considere migrar para uma chave surrogada estável (como um inteiro autoincremental ou UUID) e tratar o valor significativo como um campo único separado.
Em seguida, trave os identificadores dos quais o negócio realmente depende. Para muitos apps, isso significa uma constraint única em email (frequentemente case-insensitive) e em qualquer external_id vindo de pagamento, CRM ou sistema de auth.
Foreign keys previnem órfãos. Escolha o comportamento de delete que corresponda à realidade: às vezes você quer bloquear deletes, às vezes quer cascadear, e às vezes quer manter histórico definindo a FK como null. Exemplo: se seu MVP permitia deletar um usuário mas deixava orders para trás, você pode impedir a exclusão quando existirem orders, ou manter orders e anonimizar o usuário.
Check constraints pegam valores ruins cedo. Mantenha-os simples: totals devem ser >= 0, status deve estar em um conjunto permitido, timestamps obrigatórios não devem ser nulos, e quantity deve ser > 0.
Por fim, adicione os índices certos para que essas regras não deixem tudo lento. Constraints únicas e foreign keys geralmente precisam de índices de suporte, e vale alinhar índices às suas consultas mais comuns (por exemplo, orders por user_id).
Passo a passo: construir scripts de limpeza repetíveis
Consertos em dados falham quando feitos manualmente, de forma pontual ou sem uma ordem clara. Trate o trabalho como um pequeno release: aplique mudanças em uma sequência que você consiga repetir em staging e produção.
Uma estrutura simples de script
Use migrations ordenadas ou scripts que sigam as mesmas três fases: setup, backfill, enforce. Mantenha queries de detecção (read-only) separadas das etapas de escrita para revisar o que mudará antes de executar.
Um fluxo prático que funciona na maioria dos bancos:
- 01-detect.sql (read-only): lista duplicados, órfãos e valores ruins
- 02-setup.sql: adiciona tabelas/colunas auxiliares (por exemplo, uma tabela de mapeamento old_id -> kept_id)
- 03-backfill.sql: reatribui foreign keys, mescla linhas, arquiva o que for removido
- 04-enforce.sql: adiciona unique constraints, foreign keys e índices necessários
- 05-validate.sql (read-only): checagens que provam que a limpeza funcionou
Faça scripts de escrita idempotentes (seguros para rodar duas vezes). Use guardas claros como WHERE NOT EXISTS (...), cheque existência de coluna/constraint e prefira upserts nas tabelas de mapeamento. Envolva updates arriscados em transações quando possível e falhe rápido se pré-condições esperadas não forem atendidas (por exemplo, se um grupo de duplicados tiver duas linhas “ativas”).
O que registrar a cada execução
Logue o que mudou para poder explicar resultados e detectar regressões depois. No mínimo, registre contagens por etapa: linhas mescladas, reatribuídas, arquivadas e linhas não resolvidas.
Um padrão útil é retornar contagens de cada passo de escrita:
-- Example: reassign child rows to the kept parent
UPDATE orders o
SET user_id = m.kept_user_id
FROM user_merge_map m
WHERE o.user_id = m.duplicate_user_id;
-- Example: archive duplicates (guarded)
INSERT INTO users_archived
SELECT u.*
FROM users u
JOIN user_merge_map m ON u.id = m.duplicate_user_id
WHERE NOT EXISTS (
SELECT 1 FROM users_archived a WHERE a.id = u.id
);
Armazene os scripts em version control com um runbook curto (entradas, ordem, tempo estimado, notas de rollback).
Valide resultados com checagens rápidas e testes repetíveis
O trabalho só termina quando você pode provar que o banco está mais seguro do que antes. Comece escrevendo alguns números antes/depois que você possa comparar sempre que rerodar a limpeza.
Acompanhe métricas que mostrem se o problema diminuiu: total de linhas, chaves de negócio distintas, grupos de duplicados e contagem de órfãos. Salve esses números em um arquivo de texto pequeno ou em uma tabela para detectar regressões.
Aqui estão algumas queries que você pode rodar após cada correção:
-- Row counts (sanity)
SELECT COUNT(*) AS users_total FROM users;
-- Distinct keys (did dedupe work?)
SELECT COUNT(DISTINCT email) AS users_distinct_email FROM users;
-- Duplicate groups (should trend to 0)
SELECT email, COUNT(*)
FROM users
GROUP BY email
HAVING COUNT(*) > 1;
-- Orphans (child rows without a parent)
SELECT COUNT(*) AS orphan_orders
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
WHERE u.id IS NULL;
Números ajudam, mas não substituem comportamento real. Valide alguns fluxos críticos de forma que reflitam o uso do app: um usuário consegue entrar, um pedido carrega, um invoice bate com os itens do pedido. Depois, confira 10 a 20 registros reais ponta a ponta.
Para evitar que aquilo volte, adicione checagens automatizadas leves que você rode após cada deploy: um script que gera métricas e falha se duplicados ou órfãos aumentarem, uma checagem de constraints na CI ou na checklist de release, e um job diário que reporte novas violações antes que cresçam.
Se dados ruins ainda podem entrar (importadores antigos, validação frouxa na API), planeje limpeza contínua: bloqueie a fonte e mantenha as checagens ativas.
Por que duplicados e órfãos voltam
Duplicados e órfãos raramente são acidente único. Se seu app continua a criá-los, limpar só compra tempo a menos que você corrija as causas no código e no fluxo.
Um gatilho comum são retries. Um job em background expira, reexecuta e insere o mesmo "create order" ou "send invite" novamente porque não existe idempotency key. O job fez o que foi pedido — só fez duas vezes.
Fluxos assíncronos também competem entre si. Por exemplo, um fluxo de signup cria o usuário numa request e o perfil em outra. Se a request do perfil rodar antes ou a inserção do usuário falhar, você fica com um profile órfão. A falta de transações piora porque trabalho parcialmente concluído pode ser commitado.
Ações humanas importam também. Edições rápidas de admin ou “corrigir direto no banco” contornam validações que o app normalmente executa, especialmente quando não existem constraints para impedir escritas ruins. Imports adicionam outro caminho: o CSV tem emails com caixa diferente, telefones com caracteres extras ou IDs externos inconsistentes, então a mesma pessoa chega como múltiplos registros.
Guardrails que evitam a recaída
Aponte para algumas mudanças que bloqueiem dados ruins na origem:
- Torne operações de criação idempotentes (armazene uma request/event key e ignore repetidos).
- Envolva escritas multi-step em uma transação para que ou tudo dê commit, ou nada.
- Normalize identificadores antes de gravar (emails em minúsculas, formatos de telefone, IDs trimados).
- Trave caminhos de admin para usar a mesma validação do app, não updates diretos.
- Adicione constraints + monitoramento para que falhas fiquem visíveis e sejam corrigidas rápido.
Se você herdou um MVP gerado por IA, esses problemas são comuns. O banco geralmente não é a raiz — são caminhos de escrita frouxos.
Exemplo: limpar users e orders depois de um MVP gerado por IA
Um caso comum é um fluxo de signup gerado por IA que cria uma nova linha de usuário a cada retry. Se a mesma pessoa tocar “Sign up” três vezes, você pode terminar com três contas que compartilham email mas têm IDs e dados de perfil parciais.
Agora some outro problema: após uma mudança de esquema, alguns usuários foram deletados (ou mesclados) sem atualizar tabelas relacionadas. Orders ainda apontam para o user_id antigo, então você tem pedidos órfãos que não batem com usuário real.
Uma forma prática de consertar sem chutar:
- Escolha um usuário canônico por email (por exemplo, o que tem
verified = trueou ocreated_atmais antigo). - Crie uma tabela de mapeamento de IDs que registre
old_user_id -> canonical_user_id. - Atualize orders fazendo join com a tabela de mapeamento para que todo pedido aponte para o
user_idcanônico. - Só então delete (ou arquive) as linhas de usuário extras.
- Adicione proteções para que o problema não volte.
Sua tabela de mapeamento pode ser simples: (old_user_id, canonical_user_id), preenchida por uma query que agrupa por email e escolhe o vencedor. Depois da atualização, rode checagens rápidas: contar usuários por email, contar orders sem usuário e conferir alguns clientes de alto valor ponta a ponta.
Por fim, trave a integridade. Adicione uma constraint única em email e uma foreign key de orders.user_id para users.id. Se temer que isso quebre escritas, adicione após a limpeza e teste primeiro em uma cópia da produção.
Checklist rápido e próximos passos
Duas coisas importam no final: os dados atuais estão corretos e é difícil a mesma bagunça voltar. Mantenha notas para que outra pessoa repita o trabalho depois.
Checklist para a limpeza em si:
- Existe um snapshot recente e você sabe como restaurá-lo.
- Regras de duplicados estão escritas (campos de correspondência, critérios de desempate, o que manter).
- Queries de detecção foram executadas e salvas com timestamps e contagens.
- Mudanças foram registradas (IDs antes/depois, merges, deletes e decisões manuais).
- Scripts de limpeza podem rodar em uma cópia da produção e produzir os mesmos resultados.
Depois que os dados parecerem bons, fixe para que fiquem assim:
- Foreign keys e unique constraints foram adicionadas (ou planejadas) e suportadas pelos índices certos.
- Checagens de validação passam (contagens, integridade referencial, unicidade de chaves, totais críticos).
- Rollback foi testado ponta a ponta em um staging.
- Monitoramento tem um dono claro (alertas, relatório semanal ou gate de release).
Se você herdou um protótipo gerado por IA e precisa de um caminho rápido e seguro para produção, FixMyMess (fixmymess.ai) foca em diagnosticar o código, reparar lógica e integridade de dados e endurecer o app para que os mesmos problemas não reapareçam.
Perguntas Frequentes
When should I stop building features and clean up the database?
Se sua aplicação vai cobrar dinheiro, se você precisa de relatórios confiáveis, ou se o suporte está corrigindo registros manualmente, limpe agora. Quanto mais tempo esperar, mais recursos e novas funcionalidades escreverão dados bagunçados sobre o problema, dificultando merges e reparos.
What’s the safest first step before I run any UPDATE statements?
Comece por fazer um snapshot que possa ser restaurado rapidamente e escreva o escopo e o plano de rollback antes de qualquer UPDATE. Se possível, execute toda a limpeza em uma cópia recente da produção em staging para ver casos de borda reais sem arriscar os dados ao vivo.
How do I decide what counts as a duplicate user?
Defina duplicados usando uma chave de negócio clara e uma regra para escolher o registro "keeper". Um padrão comum é “mesmo email normalizado pertence a um único usuário”; mantenha o registro verificado ou o que tem mais histórico relevante, como pedidos pagos.
How can I find near-duplicates like email casing or extra spaces?
Normalize o campo nas suas queries de detecção — por exemplo, trime espaços e coloque emails em minúsculas — para capturar colisões que você perderia. Depois revise manualmente uma pequena amostra dos piores grupos de duplicados para confirmar que suas regras batem com o comportamento real.
Is it better to delete duplicates or merge them?
Não delete primeiro se outras tabelas referenciam a linha, porque isso quebra o histórico. Faça merge: escolha um ID keeper, repontos as foreign keys para ele e só então arquive ou desative as linhas duplicadas.
What is an orphaned row, and why does it matter?
Um órfão é uma linha filha que aponta para um pai que não existe, por exemplo um pedido com user_id ausente. Pode não travar a aplicação, mas estraga totais, exportações e gera casos de suporte confusos.
How do I fix orphaned orders or comments without guessing?
Meça primeiro com um left join para contar e amostrar órfãos, e então escolha um caminho de reparo apropriado. Normalmente você reatribui a criança ao pai correto após a deduplicação, ou arquiva/exclui linhas que são dados de teste ou escritas parciais.
What constraints should I add to prevent this mess from coming back?
Adicione constraints depois da limpeza, não antes, para não bloquear o seu próprio trabalho. Uma linha de base útil é: constraints únicas em identificadores reais (email normalizado, external_id) e foreign keys para relações que não podem quebrar.
How do I make my cleanup scripts safe to run more than once?
Separe a detecção (read-only) das etapas de escrita e use guardas para que rodar de novo não cause merges duplo ou re-arquivos. Logar contagens e manter uma tabela simples de mapeamento de IDs antigos para IDs mantidos facilita a reversão e o troubleshooting.
How do I validate the cleanup worked and the app won’t regress?
Compare números antes/depois para duplicados e órfãos, e valide fluxos críticos fim-a-fim (login, checkout). Automatize checagens leves que rodem após cada deploy: métricas que falhem se duplicados ou órfãos aumentarem, checagens de constraints na CI, e um job diário que reporte novas violações.