Mascarar PII em logs: esconder e-mails, tokens e IDs
Redija PII nos logs com padrões práticos de mascaramento para e-mails, tokens e IDs — permita depurar sem expor dados de usuários.
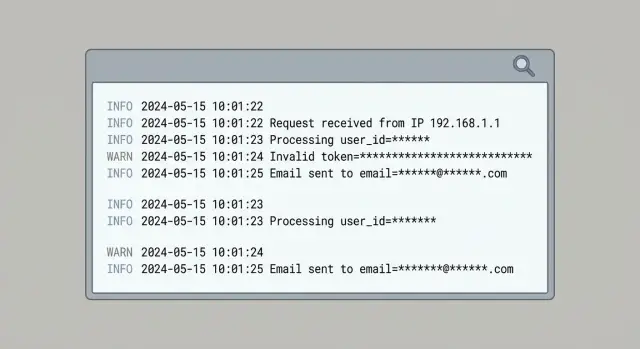
O que conta como PII nos logs (e por que continua aparecendo)
PII (informações pessoais identificáveis) é qualquer dado que pode identificar uma pessoa por si só, ou que se torna identificável quando combinado com outros dados que você já tem. Em logs e analytics, isso normalmente inclui endereços de e-mail, números de telefone, nomes, endereços residenciais ou de cobrança e endereços IP. Também abrange identificadores “técnicos” que na prática apontam para uma única pessoa: IDs de usuário, IDs de dispositivo, advertising IDs, IDs de sessão, cookies e localização precisa.
PII aparece porque o registro costuma ser adicionado na pressão, especialmente quando algo está quebrado. O atalho comum é “registre o objeto inteiro” e limpar depois. Esse “objeto inteiro” tende a incluir campos que você nunca teve a intenção de armazenar.
Pontos de entrada típicos são corpos de requisição (cadastro, redefinição de senha, mensagens de suporte), cabeçalhos (tokens de Authorization, cookies e às vezes email em cabeçalhos customizados), objetos de erro (podem incluir a requisição original ou dados serializados do usuário), query strings (parâmetros de tracking, e-mails colados em URLs) e payloads de SDKs de terceiros que capturam automaticamente informações de dispositivo e rede.
Eventos de analytics repetem o mesmo risco. Times copiam campos dos logs do servidor para eventos como user_email, session ou propriedades de “debug” para facilitar os gráficos. Esses eventos então se espalham para vários fornecedores e painéis, aumentando a área de impacto de um único erro.
A redação (redaction) vence o conselho “apenas tome cuidado” porque o modo de falha é previsível: um novo endpoint é lançado, alguém adiciona um log de debug ou uma biblioteca muda o que serializa. Trate a redação como uma camada de segurança padrão, não como uma preferência do desenvolvedor.
Decida o que você realmente precisa manter para depurar
Antes de redigir qualquer coisa, fique claro sobre para que servem seus logs. A maioria dos times coleta muito mais do que usa, e esse detalhe extra é onde endereços de e-mail, tokens e cabeçalhos brutos entram.
Anote as perguntas específicas que você espera que os logs respondam durante um incidente. Se uma linha de log não ajuda a responder uma dessas perguntas, é um bom candidato a ser removido ou reduzido.
A maioria das necessidades de depuração se resume a alguns básicos: o que falhou e quando, qual endpoint/versão foi atingida, se a falha aconteceu antes ou depois da autenticação, se uma dependência causou o erro e se múltiplas falhas pertencem à mesma requisição ou sessão.
A partir daí, defina uma forma mínima útil de log em que você confia em todos os lugares: timestamp, um request ID (ou trace ID), nome da rota, código de status e um código de erro interno. Adicione contexto pequeno e controlado, como feature flags ou um nome curto de componente. Evite despejar objetos inteiros.
Mantenha as necessidades de suporte ao usuário separadas das necessidades de engenharia. Suporte frequentemente precisa encontrar um usuário e entender impacto, mas isso não exige armazenar o e-mail do usuário em cada evento. Um padrão mais limpo é registrar uma chave interna estável do usuário nos logs e manter a busca do usuário dentro de um sistema administrativo protegido.
Algumas coisas nunca devem ser logadas, nem “temporariamente”: senhas e códigos de uso único, tokens completos e chaves de API, cookies de sessão, cabeçalhos Authorization brutos e corpos de requisição/resposta completos.
Exemplo: se usuários reportam “Falha no login”, você pode logar request_id=abc123, route=/login, status=401, error=AUTH_INVALID_TOKEN, auth_stage=post-parse. Isso é suficiente para depurar sem registrar o token.
Padrões de mascaramento para endereços de e-mail
Endereços de e-mail aparecem nos logs porque são fáceis de capturar: formulários de cadastro, redefinição de senha, convites, tickets de suporte e erros de “usuário não encontrado”. Se você quer redigir PII nos logs sem perder valor de depuração, mantenha apenas o suficiente para perceber padrões (como o domínio) sem expor o endereço completo.
Um padrão seguro é manter o domínio e só uma pequena dica da parte local, por exemplo j***@example.com ou jo***@example.com. Isso costuma bastar para notar “falhas se concentram em example.com” sem vazar identidades.
Além disso, o uso de tags (+) requer cuidado. [email protected] e [email protected] costumam ser a mesma caixa. Se você mascarar de forma ingênua, pode tratar uma pessoa como várias. Normalize antes de mascarar: converta o endereço para minúsculas, remova o +tag e então aplique sua máscara.
Se você precisa de correlação estável entre eventos, prefira um hash com chave (keyed hash) em vez de revelar parcialmente: hash(email) + "@" + domain. Use um segredo da aplicação (uma pepper) para que o hash não seja adivinhado a partir de uma lista de e-mails comuns. Nunca registre o e-mail raw junto com o hash.
Texto livre é a maior fonte de vazamentos: mensagens de exceção, prints de debug e corpos de requisição copiados. Adicione uma etapa de scan-and-replace ao seu logger para que e-mails sejam limpos mesmo quando aparecem dentro de frases.
Opções comuns que continuam úteis:
- Domínio + primeiros 1–2 caracteres locais:
ma***@gmail.com - Domínio + apenas tamanho da parte local:
[email protected] - Hash com chave + domínio:
a9f3c1…@example.com - Substituição completa quando o risco é alto:
[REDACTED_EMAIL]
Seja qual for sua escolha, aplique-a em um único lugar (um helper de logging compartilhado) para que seja consistente entre serviços e analytics.
Padrões de mascaramento para tokens, chaves de API e IDs de sessão
Segredos vazam porque ficam em lugares “comuns” que engenheiros logam sem pensar: o cabeçalho Authorization, cookies, query strings e campos JSON como token, apiKey, sessionId ou csrf. A regra é simples: nunca logue segredos brutos, mesmo em erros.
Segredos diferentes exigem tratamentos diferentes. Chaves de API costumam ser de longa duração e devem ser tratadas como senhas. JWTs podem conter claims legíveis, então logá-los pode vazar e-mails ou IDs de usuário. IDs de sessão e tokens CSRF podem ser de curta duração, mas ainda assim permitir sequestro de sessão.
Um padrão prático é manter apenas o suficiente para correlacionar eventos:
- Prefixo + sufixo: mantenha os primeiros 4 e últimos 4 caracteres
- Apenas o comprimento: logue
len=32quando a correlação não é necessária - Tags de tipo:
kind=jwtoukind=api_keypara parsing/depuração - Hash estável: um hash one-way quando você precisa de correspondência consistente
Faça seu redactor resistente a strings do mundo real. Segredos aparecem como Bearer <token>, mas também dentro de mensagens concatenadas, sem espaços e com capitalização estranha. Redija por padrão (pattern), não por “formatação bonita”.
Aqui vai um exemplo simples de antes/depois:
BEFORE error="upstream 401" Authorization="Bearer eyJhbGciOi..." cookie="sid=s%3A0f1a9..." query="?api_key=sk_live_ABC123..."
AFTER error="upstream 401" Authorization="Bearer eyJh...9Q2w" cookie="sid=<redacted len=48>" query="?api_key=sk_l...8xKQ"
Tratando IDs de usuário, IDs de dispositivo e outros identificadores
Nem todos os IDs são inofensivos. Se um identificador pode ser ligado de volta a uma pessoa (diretamente ou combinando com outros dados), trate-o como dado pessoal. Isso inclui muitos campos “internos” como user_id, account_id, device_id, ip_address e IDs de cookie “anônimos” se persistirem ao longo do tempo.
Uma regra útil: se você pode usá-lo para encontrar uma pessoa no seu banco de dados, assuma que é sensível.
Prefira IDs estáveis e não reversíveis para depuração
Você ainda precisa conectar eventos durante um incidente. O padrão mais seguro é uma representação estável mas não reversível, como um hash salgado. Você obtém correlação repetível sem expor o valor original.
Por exemplo, em vez de logar user_id=483920, logue user_key=hash(tenant_salt + user_id). Mantenha o salt fora dos logs, rode-o se necessário e use salts separados por ambiente.
Para manter os logs úteis, inclua campos de correlação que não estejam ligados a uma pessoa: request_id para uma única requisição, trace_id para seguir uma chamada entre serviços, um session_key de curta duração que expire rapidamente e tenant_id quando identifica uma organização em vez de um indivíduo.
Apps multi-tenant exigem cuidado extra. Um tenant_id costuma ser seguro se representar uma empresa ou workspace, não um único usuário. Não hasheie IDs de usuário globalmente entre tenants. Use hash(tenant_id + user_id) para que identificadores não possam ser usados para casar dados entre tenants.
Logs estruturados vs não estruturados (e como redigir cada um)
Logs não estruturados são onde PII se infiltra com mais frequência. Um rápido console.log(user) ou um erro que inclui headers da requisição pode despejar e-mails, tokens e IDs numa única linha confusa. Uma vez enviado para uma ferramenta de logs, é difícil limpar depois.
Logging estruturado (normalmente JSON) torna a redação previsível. Em vez de adivinhar com regex numa linha inteira, você pode mirar campos específicos como user.email, auth.token ou request.headers.authorization.
Redija no nível do campo primeiro, depois use regex como proteção para texto livre. Redação só por regex em linhas completas perde casos extremos e também pode sobre-redigir, o que dificulta a depuração.
Uma abordagem prática é logar metadados estáveis (endpoint, status, feature flag, código de erro curto), manter a “forma” sem o conteúdo (tamanho do token, domínio do e-mail, últimos 4 caracteres) e separar texto livre em message mais context estruturado. Depois adicione uma etapa final de limpeza para quaisquer strings restantes que pareçam e-mail ou token.
Facilite isso tendo uma única função redact() e usando-a em todo lugar (logging, reporte de erros, analytics). Se times diferentes implementarem regras próprias, você vai perder algo.
export function redact(value) {
if (value == null) return value;
const s = String(value);
// emails
const email = s.replace(/[A-Z0-9._%+-]+@([A-Z0-9.-]+\.[A-Z]{2,})/gi, "<redacted:@$1>");
// bearer tokens / api keys (best-effort)
return email.replace(/\b(Bearer\s+)?[A-Za-z0-9-_]{20,}\b/g, "<redacted:token>");
}
Passo a passo: adicione redação ao seu pipeline de logging
A redação funciona melhor quando é automática. O objetivo é remover valores sensíveis antes de qualquer coisa sair da aplicação em execução, assim você não depende de uma configuração de fornecedor ou de um trabalho de limpeza posterior.
Comece listando todos os lugares onde logs e eventos são criados. Times lembram do servidor de API e esquecem do worker, do proxy reverso, do cliente mobile ou de um report de erro no navegador.
Em seguida, defina um “mapa de redação”: nomes de campos que você nunca quer enviar (como email, authorization, cookie, set-cookie, password, token) mais regras baseadas em padrões para texto livre.
Depois adicione uma camada de redação imediatamente antes da exportação, idealmente em uma função compartilhada para ser difícil de contornar. Mantenha a implantação controlada: adicione testes, faça rollout gradual e verifique se a depuração ainda funciona.
Prove com testes, não com esperança
Use fixtures bagunçados: uma requisição com Authorization: Bearer ..., um body JSON contendo email e uma URL que inclui um token de reset. Seus testes devem confirmar que os trechos sensíveis são substituídos enquanto o contexto restante ainda explica o que aconteceu.
Redigir PII em eventos de analytics sem perder insight
Analytics vaza os mesmos tipos de dados que logs: URLs, referrers, valores de formulários e mensagens de erro. A diferença é onde isso acaba. Dados de analytics são copiados para mais lugares e frequentemente guardados por mais tempo.
Um padrão sólido é: envie menos, mas envie de forma consistente. Substitua propriedades de usuário por um ID pseudonimizado e então adicione apenas atributos grosseiros que você realmente usa (plano, versão do app, país, tipo de dispositivo). Ainda é possível responder perguntas de produto sem enviar identificadores brutos.
Os padrões são familiares: evite e-mail/telefone/nome completo como identificadores, resuma strings sensíveis (presente/não presente, tamanho ou categoria), remova query strings e fragmentos de URLs e, para erros, envie um código e categoria em vez do payload completo que pode incluir input do usuário. Se precisar correlacionar, faça hash com um salt secreto e nunca envie o valor raw.
URLs brutas são um vazamento comum. Links de reset de senha podem incluir token=..., links de convite podem incluir e-mail na query e esses valores podem ser capturados como propriedades de visualização de página.
Um evento de signup normalmente não precisa de [email protected]. Normalmente precisa de signup_method=email, opcionalmente email_domain=company.com e se a confirmação teve sucesso.
Erros comuns que ainda vazam PII
A maioria dos vazamentos não é causada por uma regra de redação “ruim”. Acontecem porque alguém precisava de mais detalhe durante um incidente, ou porque um caminho de código loga diferente do resto.
Modo incidente que nunca é desligado
Uma falha clássica é ativar logging de requisições completas durante uma queda (corpos, headers, query strings), corrigir o bug e esquecer de remover o logging extra. Semanas depois, os logs contêm senhas em payloads, bearer tokens em headers e e-mails em query params.
Redação ajuda, mas não salva se você continuar coletando muito mais do que precisa.
Redação muito estreita ou inconsistente
Mascarar apenas um campo email não é suficiente. PII aparece sob chaves diferentes e em estruturas aninhadas, e vaza de lugares que as pessoas esquecem: workers, jobs em background, logging do cliente e reporte de erros.
Se você quer garantia ponta a ponta, as mesmas regras precisam rodar em todos os lugares onde logs são produzidos e devem ter testes que incluam inputs reais e bagunçados.
Checklist rápido antes de lançar
Faça um último passe com um objetivo simples: mantenha detalhe suficiente para depurar o que aconteceu e onde, sem armazenar segredos ou identificadores diretos.
- Procure os piores offenders: senhas, cabeçalhos Authorization, cookies e tokens completos. Se precisar provar que um token existe, logue apenas uma impressão digital curta (primeiros 6 e últimos 4) ou um hash one-way.
- Garanta que endereços de e-mail e números de telefone estejam mascarados em todos os lugares, incluindo texto livre e stack traces.
- Substitua identificadores de usuário por IDs anônimos (ou hasheie-os com um salt estável) para que você possa seguir uma jornada sem expor o valor original.
- Verifique eventos de analytics quanto a identificadores brutos e URLs completas. Query strings frequentemente carregam tokens de reset, códigos de convite ou pistas de sessão.
- Adicione testes automatizados que rodem payloads comuns (signup, login, reset de senha, falhas de webhooks) através do seu logger e verifiquem que a saída não contém segredos.
Um check rápido: gere um login falho em staging e olhe a linha exata do log. Se contiver um e-mail, um cookie ou um header auth, você não terminou.
Próximos passos: verifique o que está vazando e conserte rápido
Comece com prova. Escaneie logs recentes e payloads de analytics para encontrar o que realmente aparece: padrões de e-mail, strings semelhantes a tokens, nomes completos, endereços, IPs e dumps de debug que viraram permanentes.
Quando você identificar repetições, trate-as como um pequeno backlog. Corrija primeiro as fontes de maior risco (auth, reset de senha, cadastro, billing, formulários de suporte) e depois trabalhe para fora. Pare novos vazamentos antes de se preocupar em limpar dados antigos.
Se você herdou um codebase gerado por IA, esse trabalho geralmente avança rápido porque os pontos de vazamento se repetem em arquivos (dumps completos de requisição, headers, cookies, variáveis de ambiente). Conserte uma vez na fronteira de logging e você elimina classes inteiras de erros.
Se precisar de ajuda externa, FixMyMess (fixmymess.ai) foca em diagnosticar e reparar apps gerados por IA, incluindo apertar o logging, consertar fluxos de auth quebrados e hardening de segurança para que protótipos sejam seguros em produção.