Migrar de blob JSON para tabelas normalizadas com backfills
Aprenda a migrar de um blob JSON para tabelas normalizadas com um plano por fases: novo esquema, backfills, gravações duplas, cutover seguro e opções de rollback.
Por que colunas blob JSON deixam de funcionar conforme você cresce
Uma coluna blob JSON é um único campo no banco que guarda um objeto inteiro como texto, por exemplo: { "status": "paid", "coupon": "NEW10", "notes": "..." }. Times começam com isso porque parece rápido. Você pode adicionar campos sem mudar o esquema, e muitos geradores de código por IA escolhem isso quando querem agir rápido.
O problema aparece quando o app tem usuários reais, volume real de dados e perguntas reais que o banco precisa responder. O que antes era uma escrita simples vira leituras lentas, relatórios confusos e muitos casos especiais no código.
Normalmente você sente o blob JSON se quebrando de formas previsíveis:
- As consultas ficam lentas porque filtrar e ordenar dentro de JSON é mais difícil de otimizar.
- Campos derivam para formatos inconsistentes (às vezes
phone, às vezesphoneNumber, às vezes ausente). - Relatórios viram tentativa e erro porque você não pode confiar em tipos, campos obrigatórios ou relacionamentos.
- Correções de dados ficam arriscadas porque você edita blobs grandes em vez de atualizar uma coluna clara.
- Bugs ficam escondidos por meses porque dados ruins ainda “cabem” dentro do JSON.
Blobs JSON também escondem problemas de qualidade de dados até que seja caro consertá-los. Um valor que deveria ser número pode virar string silenciosamente. Um campo que deveria ser obrigatório pode desaparecer. Depois, quando você precisa de totais precisos, remoção de duplicatas ou logs de conformidade, descobre que nunca aplicou as regras.
“Tabelas normalizadas” significa dividir esse blob em tabelas e colunas separadas que representam uma coisa cada, com tipos claros e relacionamentos. Em vez de um order.data blob, você pode ter orders, order_items, payments e addresses, com colunas que dá para indexar e validar.
Há casos em que você deve esperar. Não migre ainda se o produto muda diariamente, o volume de dados é minúsculo ou você não tem definição clara do que os campos significam. Primeiro decida o que precisa ficar estável.
Se você herdou um app gerado por IA onde “tudo está em JSON”, esse padrão é comum: funciona em demo e desmorona em produção. A boa notícia é que dá para migrar com segurança em fases com backfills, sem reescrita monumental.
Mapeie seus dados atuais antes de mudar qualquer coisa
Antes de mover de um blob JSON para tabelas normalizadas, entenda claramente como o blob é usado hoje. A maioria das migrações que falham começa com suposições sobre o que está no JSON e quais partes importam.
Anote os principais fluxos de leitura e escrita que tocam o blob, baseando-se em comportamento real: páginas que as pessoas carregam, formulários que submetem, chamadas de API que você serve, jobs que executa e exports que sua equipe usa. Em muitos apps, os primeiros são previsíveis: uma página de usuário, uma ação de salvar, pelo menos um job em segundo plano, uma visão administrativa/relatório que lê muitas linhas e uma ou duas integrações ou webhooks que tocam parte do blob.
Abra algumas linhas reais de produção e liste os campos que direcionam decisões. Ignore ruídos como estado temporário de UI, flags antigas que nunca são lidas ou chaves aleatórias que apareceram uma vez e nunca mais voltaram.
Ao listar campos, marque cada um como obrigatório, opcional ou depreciado.
- Obrigatório: o app quebra ou regras de negócio falham sem ele.
- Opcional: útil, mas nem sempre presente.
- Depreciado: seguro para remover mais tarde, depois de confirmar que ninguém lê.
Fique atento a dados armazenados duas vezes em formatos diferentes. Um sinal comum é quando um campo existe tanto como coluna de topo quanto dentro do JSON, ou quando duas chaves JSON representam o mesmo conceito (como userId vs customer_id). Essas duplicações confundem backfills e tornam bugs difíceis de rastrear.
Defina sucesso em termos mensuráveis antes de tocar o esquema. Consultas mais rápidas em telas específicas. Relatórios que não exigem parsing customizado de JSON. Menos bugs de dados. Validações mais simples. Menos carga de suporte por “dados faltando”. Se você não consegue medir a melhoria, é difícil saber quando a migração realmente acabou.
Projete o esquema normalizado em fatias pequenas e seguras
Não tente substituir toda a coluna JSON de uma vez. Escolha uma primeira fatia que importe claramente: uma tela com reclamações de usuários, um relatório lento ou um endpoint de API que está estourando timeout. Uma pequena vitória força clareza e mantém o trabalho limitado.
Comece nomeando entidades reais. Se o blob mistura “perfil do usuário”, “plano de assinatura”, “pagamentos” e “eventos de auditoria”, essas não são campos de uma tabela só. São tabelas separadas com relacionamentos. Um teste simples: você consegue descrever cada tabela em uma frase sem mencionar “JSON"?
Escolha identificadores que não vão mudar. Se você já tem uma chave primária para a linha pai (como account_id), mantenha-a e use-a como foreign key nas novas tabelas. Para registros filhos, adicione IDs estáveis (payment_id, event_id) em vez de confiar em posições de arrays dentro do JSON. Isso importa durante backfills e replays, porque você precisa de uma forma confiável de casar linhas.
Aplique constraints que você consegue sustentar hoje, não o conjunto perfeito que você desejaria. Para a primeira fatia, foque em:
NOT NULLem colunas essenciais (comouser_id,created_at).- Foreign keys básicas onde você confia na tabela pai.
- Unicidade onde duplicatas quebrariam a funcionalidade (como um plano ativo por conta).
Se precisar de rastreabilidade durante a transição, mantenha isso explícito e temporário. Uma coluna raw_json na nova tabela pode ajudar a depurar mapeamentos, mas deve ser uma escolha consciente, não um novo depósito genérico.
Planeje índices a partir das consultas reais, não da teoria. Se o app sempre busca “ultimos eventos por conta” ou “plano atual por usuário”, indexe esses filtros e padrões de ordenação exatos. Uma fatia pequena com os índices corretos vence um esquema gigante que ninguém consegue consultar rapidamente.
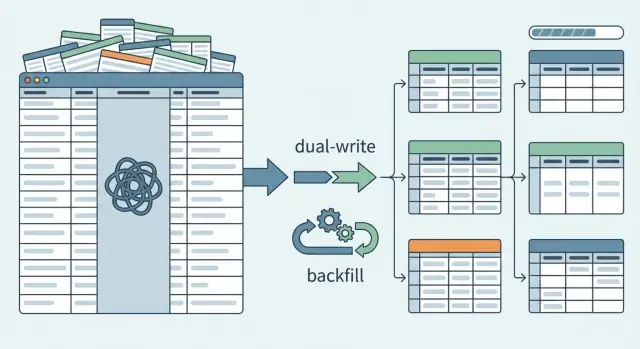
Configure uma migração por fases com risco mínimo
O caminho mais seguro é adicionar, não substituir. Crie as novas tabelas primeiro e mantenha a coluna JSON existente. A produção fica estável enquanto você prova que o novo caminho funciona.
No começo, mantenha o comportamento antigo como padrão. Leituras continuam vindo do JSON mesmo depois de criar as novas tabelas. Nos bastidores, você pode ativar a nova rota de leitura para um pequeno conjunto de tráfego ou algumas contas internas.
Um feature flag ajuda aqui. Ele permite alternar leituras entre a fonte antiga (JSON) e a nova (tabelas) sem apostar tudo em um deploy. Também dá rollback instantâneo se algo estiver errado.
A seguir, comece com gravações duplas (dual writes). Quando um registro é criado ou atualizado, grave tanto no blob JSON quanto nas tabelas normalizadas. Isso permite que novos dados se acumulem na nova estrutura enquanto o app ainda depende da antiga.
Gravações duplas podem divergir se você não adicionar guardrails simples. Um padrão prático é armazenar um timestamp updated_at e um pequeno schema_version em ambos os lados. Quando as versões diferem, você sabe que a linha está desatualizada e precisa de atenção antes de confiar nela.
Uma configuração mínima por fases que aguenta em produção costuma ser:
- Adicionar novas tabelas e índices, sem remover a coluna JSON.
- Adicionar um feature flag de leitura, padrão para a fonte JSON.
- Implementar dual writes para creates e updates.
- Armazenar
updated_ate umschema_versionsimples para comparações. - Logar divergências e manter um switch de rollback rápido.
Backfills: mover dados existentes do JSON para as novas tabelas
Um backfill é onde você transforma JSON bagunçado em linhas limpas. Trate como um pipeline de dados real, não um script único. Você precisa poder parar, reiniciar e rodar de novo sem duplicar dados ou corromper as tabelas destino.
Faça o job idempotente e reiniciável. Um padrão comum é: parsear o JSON, mapear para as novas colunas e depois upsert nas tabelas de destino usando uma chave natural estável (como user_id + nome do campo) ou um ID determinístico gerado. Guarde um checkpoint para sempre saber o que foi processado.
Para reduzir risco, backfille em pequenos lotes e acompanhe o progresso. Ranges de ID funcionam bem quando IDs são densos. Janelas de tempo funcionam quando seus dados são orientados a eventos. Uma fila de chaves primárias é mais segura quando IDs são esparsos. Muitas equipes também fazem uma passagem de “mudou desde a última execução” no final para pegar o que se movimentou durante o backfill.
Validação importa mais que velocidade. JSON costuma esconder tipos ruins e campos faltando, então seja explícito sobre regras de parsing: valores padrão, conversões de tipo e o que “vazio” significa. Se você vê "age": "", armazena NULL, 0 ou rejeita? Decida a regra e mantenha-a consistente.
Assuma que parte do JSON está quebrada e projete para isso. Não deixe o job travar. Quarentena e log as falhas para consertá-las deliberadamente:
- Registre o ID da linha origem e o caminho JSON que falhou.
- Salve o fragmento raw do JSON que causou o erro.
- Marque o motivo (JSON inválido, campo obrigatório faltando, incompatibilidade de tipo).
- Continue processando a próxima linha.
É aqui que migrações costumam falhar em apps gerados por IA: casos de borda parcialmente parseados, truncamento silencioso e conversões “melhor esforço” que parecem ok até que relatórios ou faturamento dependam deles. Um log rigoroso do que não pôde ser migrado, e por quê, transforma surpresas em uma lista curta e acionável.
Verifique a correção com comparações e guardrails
A parte mais assustadora não é mover dados. É confiar no resultado. Você precisa de checagens simples que digam, em termos claros, se as novas tabelas correspondem ao que o app costumava ler do JSON.
Comece com comparações que computem o mesmo valor de duas formas: (1) parsear a coluna JSON como o código antigo fazia e (2) ler das novas tabelas. Faça isso primeiro para comportamentos visíveis ao usuário: permissões, preços, limites de plano, flags de status. Depois expanda para campos mais profundos.
Implemente por amostragem antes de tentar validar tudo. Amostre um conjunto pequeno (por exemplo, registros recentes por tenant ou por dia), reveja divergências, corrija seu mapeamento e então aumente a cobertura até ter confiança para rodar checagens no dataset completo.
Ao rastrear divergências, mantenha categorias fáceis de agir:
- Ausente: valor existe no JSON, mas não há linha nas novas tabelas.
- Diferente: ambos existem, mas não batem após a normalização (tipos, arredondamento, caixa).
- Inválido: JSON não pode ser parseado ou falha na validação.
- Inesperado: novas tabelas contêm valores que nunca existiram no JSON.
Decida a fonte da verdade durante a transição e registre por escrito. Escolhas comuns são “JSON é a verdade (novas tabelas são derivadas)” ou “novas tabelas são a verdade (JSON é espelho de compatibilidade)”. Escolha uma por fase. Caso contrário, engenheiros vão “consertar” divergências atualizando ambos os lados de maneiras diferentes.
Guardrails tornam erros mais baratos: feature flags para leituras, limites rígidos de quantas linhas um job de backfill pode alterar por execução e alertas quando a taxa de divergência sobe. Mantenha cada fase reversível com um caminho claro de rollback: alternância de volta para leituras JSON, forma de pausar gravações e um plano de limpeza para dados parcialmente migrados.
Mude as leituras gradualmente sem quebrar usuários
Quando as novas tabelas estiverem populadas e atualizadas, mude como você lê dados em passos pequenos. Trate cada caminho de leitura como um release separado, não um único grande corte.
Coloque a nova leitura atrás de um feature flag. Lance para uma fatia mínima de tráfego primeiro (ou só contas internas), depois aumente. Isso mantém falhas contidas e facilita rollback.
Uma sequência prática que funciona para a maioria dos apps:
- Troque uma tela ou endpoint de API de cada vez.
- Mantenha a leitura do JSON como fallback para esse endpoint.
- Compare resultados em background e registre divergências.
- Aumente exposição gradualmente (1%, 10%, 50%, 100%).
- Remova o fallback somente depois que os resultados baterem por um tempo.
Após cada mudança, observe o que os usuários sentem primeiro: taxas de erro, timeouts e queries lentas. Leituras normalizadas podem virar muitas consultas pequenas acidentalmente, e um índice faltando pode deixar uma página antes rápida muito lenta. Adicione alertas antes do rollout, não depois.
Mantenha dual writes até confiar nas novas leituras sob carga real. Se você parar de escrever no blob cedo demais, um rollback vira um incidente de perda de dados. Dual write é seguro. Remova-o apenas quando tiver confiança de que não precisará voltar.
Enquanto migra, torne dependências que só leem do blob explícitas. Se uma funcionalidade ainda depende de uma chave só no JSON, decida se vira coluna/tabela real ou é removida. Deixar vago é como equipes ficam lendo de ambos os modelos para sempre.
Erros comuns que causam perda de dados ou downtime
A maioria dos incidentes numa migração JSON→tabelas acontece porque o trabalho é tratado como um único corte. Na prática, você está rodando dois modelos de dados ao mesmo tempo por um período, e a sobreposição é onde as coisas quebram.
Um erro comum é ativar dual writes sem decidir o que acontece quando as duas gravações discordam. Mesmo que as duas atualizações ocorram na mesma requisição, você ainda precisa de uma política de conflito (qual lado vence) e uma forma de detectar e reaplicar gravações faltantes.
Backfills também causam problemas quando não conseguem retomar. Jobs longos são interrompidos: deploys, timeouts, linhas travadas ou um registro ruim. Se o job reinicia do começo, você arrisca duplicatas, atualizações parciais ou carga alta que parece um ataque de negação de serviço no seu próprio banco.
Deriva silenciosa de dados é outro grande problema. Equipes “limpam” o significado de campos durante a migração (como mudar valores de status ou formatos de data) e esquecem de documentar o mapeamento. Tudo parece ok até relatórios, emails ou lógica de faturamento se comportarem diferente.
Os erros que mais aparecem:
- Sem política clara de conflito para dual writes e sem trilha de auditoria para detectar divergências.
- Backfills que não são idempotentes (seguros para rodar duas vezes) e não usam checkpoints.
- Mudar significado de campo no meio da migração sem mapeamento versionado e testes.
- Esquecer leitores a jusante: queries de analytics, exports, webhooks e jobs background.
- Dropar a coluna JSON cedo demais, antes das leituras estarem totalmente movidas e verificadas.
Um exemplo real: um app guarda “perfil do usuário”, “assinatura” e “permissões” em uma coluna JSON. Um backfill copia dados para novas tabelas, mas um job noturno ainda lê o JSON e sobrescreve as tabelas normalizadas, apagando mudanças recentes. A correção geralmente não é código mais inteligente. É regras claras: backfills reiniciáveis, mapeamentos estritos e manter a coluna antiga até provar que o novo modelo bate com a realidade.
Checklist rápido antes do cutover
O dia do cutover deve ser chato. Se ainda parecer um salto de fé, provavelmente falta um dry run.
- Tabelas e releases são seguros para shipar: novas tabelas existem em produção, migrations são seguras para reexecutar e você verificou índices e constraints importantes.
- Backfill é visível e repetível: você vê progresso, totais de erro e checkpoints, e pode rodar de novo sem duplicar linhas.
- Dual write está ativo e regras de conflito estão documentadas: você sabe qual fonte vence (por exemplo, timestamp mais novo vence) e loga conflitos.
- Switches de leitura são protegidos: leituras podem ser alternadas por endpoint ou tenant via feature flags, e você pode reverter rapidamente.
- Taxa de divergência é aceitável e rollback foi testado: compara-se totais chave, faz spot-checks e praticou rollback em dados semelhantes à produção.
Cenário de exemplo: consertando um app gerado por IA que armazenou tudo em JSON
Um fundador lança um protótipo CRM gerado por IA em um fim de semana. Funciona em demos, mas cada perfil de cliente é um blob JSON em uma única coluna. Um perfil pode incluir nome, email, status, last_contacted, notas e campos customizados.
Três meses depois, a dor aparece. Relatórios ficam lentos porque o banco precisa escanear e parsear JSON para cada gráfico. Pior: o campo status é uma bagunça: "Active", "active", "ACTIV", "In progress", "In-Progress" e "inprogress" significam mais ou menos a mesma coisa. Filtros perdem registros, dashboards discordam e notas de vendas acabam ligadas ao estágio errado.
Uma primeira fatia segura é normalizar apenas o que dirige o dashboard: clientes e status.
Essa fatia pode ser:
- Uma tabela
customerscom colunas estáveis (id,name,email,created_at). - Uma tabela de lookup
statuses(id,canonical_name) com um conjunto permitido. - Uma forma de conexão (ou
customers.status_idou uma tabela separadacustomer_status, dependendo de necessidades históricas).
Depois, backfill a partir do JSON existente:
- Parseie cada blob de perfil e insira ou atualize a linha do cliente.
- Mapeie strings de status bagunçadas para statuses canônicos, com um bucket claro para “unknown”.
- Logue tudo que falhar no parsing para você consertar dados em vez de adivinhar.
O cutover permanece em etapas. Primeiro, troque apenas as leituras do dashboard para as novas tabelas. Mantenha leituras do JSON no resto do app enquanto compara contagens e totais. Quando o dashboard estiver correto e rápido, migre as telas restantes uma a uma.
Próximos passos: terminar a migração e manter tudo limpo
Quando suas leituras estiverem totalmente nas novas tabelas e você tiver um período estável sem surpresas, decida o que fazer com a coluna JSON antiga. A maioria das equipes ou a congela (sem mais gravações, mantém por uma janela de segurança) ou a remove após backups e sign-off.
Se você adiou proteções para mover rápido, adicione-as agora. Tabelas normalizadas compensam a longo prazo quando previnem dados ruins, não só quando armazenam dados.
Fixe o novo contrato
Escreva as regras das quais o app agora depende: quais campos são obrigatórios, o que “válido” significa e onde cada pedaço de dado vive. Isso vira o contrato de dados para features futuras e ajuda novos colegas a não reintroduzirem um blob “só por enquanto”.
Uma página é suficiente: nomes de tabelas, colunas chave, ownership (quem grava o quê) e um exemplo curto de um registro válido.
Evite voltar a usar blobs
Após a migração, o maior risco é deriva: novas features começam a enfiar campos extras de volta num JSON catch-all.
Congele ou remova a coluna JSON depois de uma janela de estabilidade definida. Adicione as constraints e índices que você adiou (foreign keys, unique constraints, NOT NULL e os índices que suas principais queries precisam). Se mantém um campo JSON para metadados “misc”, adicione uma checagem leve para que novas chaves não apareçam sem plano.
Se você herdou uma base gerada por IA que depende muito de blobs JSON e precisa colocá-la em produção, o FixMyMess (fixmymess.ai) foca em diagnosticar e reparar esse tipo de arquitetura gerada por IA, incluindo migrações por fases, correção de lógica e hardening de segurança, com verificação humana antes das mudanças irem à produção.