Migrar SQLite para Postgres: um playbook de cutover em fases
Um playbook prático para migrar SQLite para Postgres em apps gerados por IA: mapeamento de esquema, tipos de dados, mudanças de indexação, cutovers em fases e checagens.
Por que essa migração é arriscada em apps gerados por IA
Protótipos gerados por IA frequentemente “funcionam” porque o SQLite é tolerante. Ele aceita valores estranhos, tipos soltos e permite avançar com pouca configuração. Muitas ferramentas de IA também usam SQLite por padrão por ser zero-config e fácil de distribuir. O problema é que esses atalhos iniciais viram pressupostos escondidos no código.
Ao migrar SQLite para Postgres, as primeiras quebras geralmente parecem pequenas, mas se propagam rápido. Uma query que funcionava no SQLite pode falhar no Postgres por tipagem mais rigorosa, comportamento diferente com datas e booleanos, e comparações sensíveis a maiúsculas. Migrations também podem falhar porque o SQLite permitiu adicionar colunas ou alterar tabelas de formas que não se traduzem bem para o Postgres.
O que tende a quebrar primeiro:
- Autenticação e sessões (tratamento de timestamps, constraints de unicidade, sensibilidade a maiúsculas)
- Queries que “funcionavam localmente” (casts implícitos, comportamento permissivo de GROUP BY)
- Jobs em background e imports (dados ruins que o SQLite tolerou)
- Performance (índices ausentes que o SQLite não deixava óbvios)
- Scripts de deployment (pressupostos sobre BD baseado em arquivo vs servidor)
A migração vale a pena quando você precisa de concorrência, backups reais, melhor planejamento de queries, controles de acesso mais seguros ou quando está ultrapassando um setup de nó único. Não vale a pena se o app ainda é descartado toda semana, você não tem requisitos estáveis ou o gargalo principal é ajuste de produto, não limites do banco.
“Sem surpresas de downtime” não significa ausência de risco. Significa que você planejou para os modos de falha comuns, pode medir progresso e tem um caminho de rollback limpo. Na prática, você mira em não ter interrupção visível ao usuário ou apenas uma janela programada curta com uma rota de fuga clara.
Este playbook segue um arco simples: inventariar o que você realmente tem, traduzir o esquema com cuidado, converter dados com segurança, planejar índices e performance, executar um cutover em fases com sincronização, aplicar mudanças no app que costumam ser esquecidas e, então, testar e ensaiar rollback. Se seu app foi gerado por ferramentas como Lovable, Bolt, v0, Cursor ou Replit, times como o FixMyMess costumam começar por um diagnóstico rápido do código para descobrir suposições específicas do SQLite antes de tocar nos dados de produção.
O que inventariar antes de mexer no banco
Antes de migrar SQLite para Postgres, esclareça o que você realmente tem. Apps gerados por IA frequentemente “funcionam” em demo, mas escondem surpresas como coerção silenciosa de tipos, SQL ad-hoc e jobs em background que continuam escrevendo enquanto você tenta mover dados.
Comece com um mapa tabela a tabela. Você quer nomes, contagens de linhas e quais tabelas crescem rápido. As maiores tabelas normalmente guiam seu plano de cutover porque demoram mais a copiar e são as mais dolorosas para reindexar.
Se possível, capture um snapshot rápido de tamanho e crescimento:
-- SQLite: approximate quick checks
SELECT name FROM sqlite_master WHERE type='table';
SELECT COUNT(*) FROM your_big_table;
Em seguida, entenda o tráfego. Uma migração raramente é bloqueada por reads. É bloqueada por writes que você esqueceu: webhooks, filas, tarefas agendadas e “scripts auxiliares” que alguém roda manualmente.
Aqui está um checklist simples de inventário que previne a maioria das surpresas de downtime:
- Tabelas: contagens de linhas, maiores tabelas e quaisquer tabelas “quentes” com atualizações frequentes
- Fluxo de dados: quais endpoints escrevem, quais apenas leem e quais jobs rodam agendados
- Estilo de query: onde você usa um ORM vs SQL cru no código
- Peculiaridades do SQLite: lugares que dependem de tipagem frouxa, booleanos implícitos ou tratamento estranho de datas
- Config: onde strings de conexão, chaves de API e segredos do banco estão armazenados e injetados
SQL cru é a armadilha clássica. Um ORM pode adaptar queries para Postgres, mas um snippet de SQL copiado de uma ferramenta de chat pode usar sintaxe só do SQLite ou assumir comportamento de ordenação com NULLs.
Exemplo concreto: um protótipo gerado no Replit pode armazenar booleanos como "true"/"false" texto em uma tabela, 0/1 inteiros em outra, e confiar que o SQLite aceita ambos. Postgres vai forçar uma escolha, e essa escolha afeta queries, índices e lógica do app.
Se você herdou um app gerado por IA bagunçado, um diagnóstico curto do código (como o FixMyMess faz) pode descobrir esses escritores escondidos e suposições do SQLite antes que virem um cutover fracassado.
Tradução de esquema que não te surpreenda depois
Ao migrar SQLite para Postgres, o maior risco não é copiar os dados. É descobrir que seu app dependia de comportamentos do SQLite que você nunca documentou.
O SQLite muitas vezes “aceita” um esquema vago: chaves estrangeiras ausentes, tipos de coluna soltos e regras implícitas no código do app. Apps gerados por IA tornam isso pior porque o esquema pode ter sido gerado rápido e depois remendado in loco.
Torne o esquema explícito (tabelas, chaves, relacionamentos)
Comece escrevendo um mapa claro de cada tabela e como as linhas se conectam. Não confie no que você acha que o app faz — confirme com o esquema real e dados reais.
Uma maneira prática de traduzir é trabalhar nesta ordem:
- Defina a chave primária de cada tabela e se ela deve mudar algum dia.
- Decida como cada relacionamento funciona (1:1, 1:muitos) e adicione foreign keys de propósito.
- Adicione constraints que você vinha assumindo implicitamente (NOT NULL, UNIQUE, CHECK).
- Trate relacionamentos circulares criando tabelas primeiro e depois adicionando as foreign keys.
- Mantenha nomes consistentes (colunas como userId vs user_id causam bugs silenciosos depois).
IDs autoincrement: escolha a versão do Postgres agora
No SQLite, INTEGER PRIMARY KEY é um caso especial que auto-incrementa. No Postgres você deve escolher GENERATED BY DEFAULT AS IDENTITY (ou ALWAYS) em vez do antigo SERIAL, e documentar essa escolha.
Exemplo: um protótipo de IA pode inserir usuários sem um id explícito e assumir que ids nunca colidem. Se você retropreencher dados e esquecer de ajustar a sequência de identidade, o próximo insert pode falhar ou, pior, reutilizar ids.
Por fim, faça seus scripts de migração reexecutáveis. O Postgres é mais estrito, então mire em scripts idempotentes: crie objetos apenas se estiverem faltando e adicione constraints de forma controlada para que uma execução parcial possa ser retomada sem adivinhação.
Incompatibilidades de tipos e conversões seguras
Ao migrar SQLite para Postgres, os bugs mais assustadores vêm de diferenças silenciosas de tipos. O SQLite aceita sem reclamar "true" em uma coluna que você achava ser inteira. O Postgres não aceita, e isso é bom, mas significa que você precisa de conversões explícitas.
As incompatibilidades que causam quebras reais
Alguns padrões aparecem repetidamente em apps gerados por IA:
- Booleanos: apps SQLite costumam usar 0/1, "true"/"false" ou até string vazia. No Postgres, use
booleane converta com regras claras (por exemplo: apenas 1 e "true" viram true). - Inteiros armazenados como texto: IDs e contadores podem estar gravados como strings. Converta só se todo valor estiver limpo; caso contrário, mantenha como texto e adicione uma nova coluna inteira que você retropreencha com segurança.
- Nulls e defaults: o SQLite pode se comportar de forma frouxa com valores ausentes. Postgres aplicará
NOT NULLe defaults. Se linhas antigas contêm nulls, adicione a constraint só depois de backfill.
Datetime é outra armadilha. Projetos SQLite frequentemente guardam datas como strings em horário local, formatos mistos ou segundos epoch. Escolha um padrão primeiro: timestamptz em UTC é geralmente o mais seguro. Depois, converta de um formato conhecido por vez e registre linhas que não parseiem. Se seu app mostra “ontem” para usuários em fusos horários diferentes, isso costuma ser sinal de mistura de horário local com UTC.
Campos JSON precisam de uma escolha deliberada. Se você filtra ou indexa dentro do JSON, armazene como jsonb. Se apenas grava e recupera blobs, text pode bastar, mas você perde validação e poder de consulta.
Dinheiro e decimais não devem usar floats. Se um checkout gerado por IA totaliza $19.989999, corrija usando numeric(12,2) (ou a escala necessária) e arredonde durante a conversão.
Uma abordagem prática é rodar uma conversão seca em uma cópia dos dados de produção, contar falhas por coluna e só então definir os tipos finais e constraints.
Indexação e mudanças de performance para planejar
Ao migrar SQLite para Postgres, a aplicação muitas vezes “funciona” mas fica mais lenta. Uma grande razão é que SQLite e Postgres fazem escolhas diferentes sobre quando e como usar índices.
O SQLite se vira com menos índices porque roda in-process, com um planejador simples e cargas menores. O Postgres é feito para concorrência e dados maiores, mas é rigoroso sobre estatísticas, seletividade de índices e formato das queries. Se um app de IA foi lançado com scans acidentais de tabela inteira, o Postgres vai executá-los fielmente, só que com um custo maior e mais visível.
Comece escolhendo índices a partir de queries reais, não achismos. Extraia as principais queries de leitura e escrita (login, listagem, busca, dashboards) e desenhe em torno delas. Um exemplo rápido: se sua app executa frequentemente WHERE org_id = ? AND created_at >= ? ORDER BY created_at DESC LIMIT 50, um índice composto em (org_id, created_at DESC) costuma ser mais útil do que dois índices por coluna.
Índices compostos e unicidade
A ordem importa em índices compostos no Postgres. Coloque o filtro mais seletivo primeiro (frequentemente org_id ou user_id), depois a coluna usada para ordenação ou scans por faixa. Adicione direção de ordenação quando bater com a query.
Também separe a ideia de “deve ser único” de “ajuda na performance”. Uma constraint UNIQUE faz valer regra de negócio e cria um índice único de suporte. Um índice único isolado pode ser útil para casos parciais, mas se for realmente regra de negócio, modele como constraint para ficar claro.
O que checar quando queries ficam lentas
Depois da migração, foque em:
- Índices compostos faltando para padrões comuns de filtro + sort
- Tipos errados causando casts (o que pode bloquear uso de índice)
- Estatísticas desatualizadas (rode ANALYZE após cargas em massa)
- Scans sequenciais em tabelas grandes onde você esperava índices
- Sobrecarga de escrita por ter muitos índices em tabelas quentes
Se você herdou um esquema gerado por IA com “indexar tudo” ou “indexar nada”, é aqui que uma auditoria curta (como a que o FixMyMess faz) paga rápido.
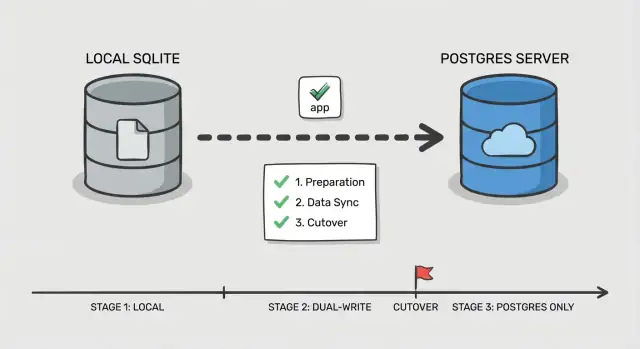
Plano de cutover passo a passo em fases
Um cutover seguro é menos sobre um grande switch e mais sobre provar que cada peça funciona enquanto os usuários continuam usando o app. Isso importa ainda mais ao migrar SQLite para Postgres em apps gerados por IA, onde queries escondidas e casos de borda são comuns.
Fase 0: Decida como você vai trocar
Escolha uma ordem simples: mude first reads, depois writes. Reads são mais fáceis de validar e de reverter. Writes mudam a fonte da verdade, então trate-os como o passo final.
Adicione um ponto de controle no app: um feature flag ou toggle de configuração que selecione qual banco lida com reads e qual lida com writes. Mantenha simples e explícito para poder alternar rápido em caso de incidente.
Fase 1-5: Execute o cutover em pequenos passos
Antes de tocar o tráfego, configure o Postgres (database, usuários, roles e acesso com privilégio mínimo). Garanta que seu app consegue conectar no mesmo ambiente onde roda hoje.
Então siga um fluxo em fases:
- Cópia bulk: tire um snapshot do SQLite e carregue no Postgres.
- Sincronização incremental: mantenha o Postgres atualizado com novas mudanças enquanto o app continua escrevendo no SQLite.
- Cutover de leitura: direcione queries de leitura para o Postgres, mantenha writes no SQLite e monitore erros e queries lentas.
- Cutover de escrita: direcione writes para o Postgres, mantendo uma janela curta onde você ainda pode reverter.
- Finalização: pare a sincronização, revogue credenciais antigas e mantenha o SQLite em modo somente leitura por um período definido.
Defina o rollback antes de mudar qualquer coisa: qual toggle reverte, que dados você pode perder e como irá lidar com isso. Por exemplo, se seu app de IA grava sessões de usuário e resets de senha, decida se essas tabelas precisam de tratamento especial para que um rollback não quebre logins.
Se precisar de uma segunda opinião, o FixMyMess costuma ajudar times a ensaiar esse plano em codebases geradas por IA antes do cutover real.
Manter dados em sincronia durante a transição
Ao migrar SQLite para Postgres com um cutover em fases, a parte difícil não é copiar o snapshot inicial. É manter mudanças consistentes enquanto usuários reais continuam interagindo.
Dois padrões simples de sync (e quando usar)
Se o app tem baixo tráfego e mudanças fáceis de reexecutar, jobs periódicos de backfill podem funcionar: faça a cópia inicial e rode um job agendado que copia linhas mudadas desde a última execução (usando updated_at ou uma tabela append-only de eventos). Isso é simples, mas aumenta o risco de diferenças de última hora antes do cutover.
Se o app está ativo, dual-write é mais seguro: cada escrita vai para ambos os bancos por um período. Dá mais trabalho, mas reduz a lacuna e torna o cutover menos estressante.
Manter IDs consistentes
Decida cedo qual sistema controla chaves primárias. A regra mais simples: mantenha os mesmos IDs no Postgres e nunca os renumere. Se o SQLite usou IDs inteiros, ajuste as sequências do Postgres para começar acima do máximo atual para evitar colisões. Se você está mudando para UUIDs, acrescente uma coluna UUID primeiro, retropreencha e mantenha o ID antigo como referência externa estável até a migração estar completa.
Para evitar confusão, defina regras de conflito desde o começo:
- Escolha uma fonte de verdade para writes (frequentemente o Postgres uma vez que o dual-write começar)
- Em caso de divergência, prefira “latest updated_at wins” só se relógios forem confiáveis
- Para dinheiro, permissões e auth, prefira regras explícitas em vez de timestamps
- Registre todo conflito para revisão
Rode ambos os sistemas em paralelo tempo suficiente para cobrir o uso normal (geralmente alguns dias, às vezes um ciclo de negócio completo). Faça logs que detectem drift rápido: contagens por tabela, checksums amostrais para tabelas quentes, falhas de escrita por endpoint e um pequeno rastro de auditoria de IDs alterados. É aqui que times frequentemente pedem ao FixMyMess para verificar comportamento de dual-write e pegar drift antes dos clientes notarem.
Mudanças no nível do app que costumam ser esquecidas
A troca de banco é só metade do trabalho. Muitas equipes migram dados, apontam o app para o Postgres e passam o dia seguinte caçando erros estranhos que não apareciam no SQLite.
Configurações de conexão e pooling
SQLite normalmente significa “um arquivo, baixa concorrência”. Postgres é um servidor e aceitará muitas conexões até chegar num ponto crítico. Se seu app usa um pool, defina limites e timeouts reais. Um padrão de falha comum é background jobs e o web app abrirem seus próprios pools, multiplicando conexões e causando lentidão que parece “Postgres está lento” quando na verdade é “conexões demais”.
Queries que dependiam da tolerância do SQLite
O SQLite muitas vezes retorna resultados mesmo com SQL meio torto. O Postgres é mais estrito, e essa estricção geralmente é positiva.
Fique atento a comparações entre tipos (texto vs números), casts implícitos e uso frouxo de GROUP BY. Também revise regras de comparação de strings e case sensitivity, porque uma busca que “funcionava” no SQLite pode mudar comportamento se você dependia de insensibilidade a maiúsculas.
Transações e suposições de locking também podem inverter. Código que funcionava com “escreva quando quiser” pode agora enfrentar deadlocks ou contenção se envolver leituras e escritas longas em uma mesma transação.
Auth e armazenamento de sessões é outra armadilha silenciosa. Se sessões de login, tokens de reset ou refresh vivem no banco, pequenas diferenças (timestamps, constraints de unicidade ou jobs de limpeza) podem causar logouts súbitos ou falhas no fluxo de login.
Aqui vai um conjunto rápido de checagens do lado do app que pegam a maioria das surpresas:
- Confirme que cada processo do app (web, workers, cron) lê a mesma config de BD e limites de pool.
- Substitua SQL só do SQLite (quirks em upserts, funções de data ou tratamento de booleanos).
- Faça auditoria de SQL cru por diferenças de escape e estilo de parâmetros.
- Reveja limites de transação e garanta que jobs longos não segurem locks além do necessário.
- Verifique tabelas de sessão e tokens, lógica de expiração e constraints únicas para garantir comportamento equivalente.
Exemplo: um protótipo gerado por IA pode armazenar sessões em uma tabela com coluna "createdAt" em texto e comparar com "now" como string. Isso pode parecer funcionar no SQLite, mas quebrar checagens de expiração no Postgres a menos que você converta para timestamp.
Se você herdou um codebase gerado por IA de ferramentas como Replit ou Cursor, serviços como o FixMyMess geralmente encontram os pontos de quebra mais escondidos aqui: os dados estão bem, mas a lógica do app assumia o comportamento do SQLite.
Testes, monitoramento e ensaio de rollback
A maioria das surpresas de downtime acontece porque o cutover é tratado como um evento único, não como um procedimento ensaiado. Apps gerados por IA são mais arriscados aqui pois costumam ter validação fraca, queries inconsistentes e casos de borda que só aparecem com dados reais.
Comece com um smoke test repetível que você possa rodar em minutos em ambos os bancos. Mantenha pequeno e focado em caminhos reais de usuário, não em todo o recurso.
- Cadastro/login/logout (incluindo reset de senha, se houver)
- Criar um registro central (por exemplo: projeto, pedido ou nota)
- Editar o registro e verificar a alteração onde deveria aparecer
- Deletar (ou soft-delete) e confirmar permissões ainda funcionam
- Rodar uma tela admin/relatório que faça joins entre várias tabelas
Em seguida, faça um teste de leitura shadow. Para uma fração do tráfego ou um job cron, leia em Postgres e SQLite em paralelo e compare resultados. Logue divergências com contexto suficiente para debugar (id do usuário, inputs da query e PKs retornadas). Isso pega diferenças sutis como ordem diferente, tratamento de NULL, sensibilidade a maiúsculas e conversões de fuso horário.
Load teste os endpoints que atingem suas tabelas mais ocupadas, não o app todo. Um caso comum ao migrar SQLite para Postgres é que uma query que “funcionava” antes agora precisa de um índice faltante ou de um join melhor. Observe latência p95 e saturação do pool de conexões.
Finalmente, ensaie o rollback uma vez, cronometrado. Escreva passos exatos, quem executa e como é o “stop the world” (flip de feature flag, modo somente leitura ou dreno de tráfego). Defina métricas de sucesso antes de começar: taxa de erro aceitável, teto de latência p95 e contagem de divergências que deve chegar a zero (ou uma lista de exceções justificada).
Erros comuns e como evitá-los
O SQLite é tolerante. O Postgres é estrito. Muitas equipes se queimam porque o app “funcionava de algum jeito” no SQLite e falha quando migram para Postgres.
Uma armadilha comum é assumir que tipos de dados “simplesmente funcionarão”. O SQLite guarda texto em colunas que parecem inteiras, ou datas como strings aleatórias. O Postgres não. Antes de mover dados, escaneie colunas com valores mistos ("", "N/A" ou "0000-00-00") e decida qual é o tipo real.
Índices são outra tarefa clássica adiada que vira incêndio em produção. O SQLite pode parecer rápido em datasets pequenos sem índices. O Postgres pode ficar lento no primeiro pico real de tráfego se você esquecer índices para foreign keys, filtros comuns e colunas de ordenação.
Cutovers falham quando writes mudam cedo demais. Se você começar a escrever no Postgres antes de poder detectar drift, não vai saber qual banco está “certo” quando algo der errado. Adicione checagens de drift (contagens, faixas de updated_at, checksums) antes de confiar no novo sistema.
Também fique atento a um caminho de arquivo SQLite escondido. Apps gerados por IA frequentemente têm um default como ./db.sqlite embutido numa env var ou imagem Docker. Tudo parece ok em staging, mas produção continua escrevendo no arquivo antigo.
Migrations longas são o assassino silencioso em tabelas grandes. Um único ALTER TABLE ou backfill pode bloquear writes tempo suficiente para causar timeouts.
Evite esses problemas com um checklist curto pre-flight:
- Audite colunas “bagunçadas” e normalize valores antes de alterar tipos.
- Crie índices no Postgres antes de terminar a carga completa.
- Mantenha dual-write ou change capture desligado até as verificações de drift estarem rodando.
- Procure configs e containers por caminhos SQLite perdidos.
- Divida backfills grandes em batches com limites de tempo.
Se você herdou um codebase precário gerado por IA, times como o FixMyMess costumam começar com uma auditoria rápida para expor esses riscos antes da janela de cutover.
Checklist rápido e próximos passos
Se lembrar de só uma coisa ao migrar SQLite para Postgres, lembre-se disto: a maioria das surpresas de downtime vem de pequenos gaps entre seu plano e o que o app realmente faz em produção.
Pré-cutover (prepare-se)
Faça isto antes de tocar o tráfego de produção. Se algum item estiver incerto, pause e confirme com um teste rápido.
- Confirme que backups restauram corretamente (não apenas que existem) e capture o estado exato da janela de cutover.
- Valide que o esquema traduzido bate com o uso real: constraints, defaults e comportamento de timestamps.
- Garanta que o caminho de sync já está rodando e estável (dual writes ou change capture), com ownership claro de falhas.
- Rode um teste de carga curto parecido com produção no Postgres e verifique as páginas/endpoints principais.
Cutover (troque com segurança)
O objetivo é um switch rápido e entediante com sinais claros e uma saída definida.
- Use um único toggle explícito (env var, flag de configuração ou switch no router) e defina quem o aciona.
- Coloque monitoramento visível antes do switch: taxa de erro, latência, conexões DB e lag de replicação/sync.
- Tenha rollback pronto e praticado: como apontar o app de volta e como lidar com writes durante o cutover.
Após a troca, verifique correção primeiro, depois velocidade. Compare contagens e checksums de tabelas-chave, rode queries críticas fim-a-fim (login, checkout, fluxos de criar/editar) e escaneie logs por novos erros como violações de constraint ou surpresas de fuso horário.
Em seguida, trate performance com foco. Puxe as queries mais lentas na produção, confirme uso de índices e corrija as poucas que causam a maior dor ao usuário.
Se seu app foi gerado por ferramentas como Lovable, Bolt, v0, Cursor ou Replit, a camada de banco muitas vezes oculta suposições bagunçadas (datas em string, constraints ausentes, queries inseguras). O FixMyMess oferece uma auditoria gratuita de código para identificar esses riscos de migração cedo, antes de você se comprometer com um plano de cutover.