Observabilidade de handlers de webhook: logs, IDs de evento, vista administrativa
Webhooks falham silenciosamente sem a visibilidade certa. Aprenda observabilidade de handlers de webhook com checagens de assinatura nos logs, armazenamento de IDs de evento e uma view administrativa simples.
Por que handlers de webhook parecem invisíveis quando quebram
Webhooks são mais difíceis de depurar do que chamadas de API normais porque você não é quem clica no botão que envia a requisição. Um provedor envia um evento quando quer, de uma infraestrutura que você não controla, e muitas vezes você só descobre que algo está errado depois que um cliente reclama.
Com um endpoint de API típico, você consegue reproduzir a chamada, ver a resposta e iterar. Com webhooks, a falha pode ser silenciosa: o provedor reenvia em segundo plano, seu app retorna um 500 genérico, e você fica adivinhando se a requisição era autêntica, se seu código rodou e onde parou.
A parte mais frustrante é a lacuna quando os retries começam. Você pode ver um pico de tráfego e depois nada útil: nenhum identificador de evento claro, nenhum rastro do que aconteceu em cada tentativa e nenhum registro se já processou aquilo. É assim que você acaba cobrando duas vezes, perdendo uma atualização de assinatura ou criando registros duplicados.
Observabilidade de handlers de webhook é simplesmente ser capaz de responder a algumas perguntas rápido, sem ler payloads brutos ou ativar modo debug ruidoso:
- Quem enviou essa requisição, e passou na verificação de assinatura?
- Qual foi o evento (ID, tipo, timestamp), e já o vimos antes?
- O que nosso handler fez, e por que falhou (se falhou)?
Boa observabilidade é pequena, segura e fácil de manter. Você não precisa de um sistema de monitoramento complexo. Alguns logs estruturados, um ID de evento armazenado e uma view administrativa mínima podem transformar um webhook invisível em algo que você entende em minutos.
O que “observável” significa para um endpoint de webhook
“Observável” significa que quando uma entrega falha (ou parece OK mas causa o resultado errado), você pode responder o que aconteceu sem adivinhar, reenviar às cegas ou adicionar prints pontuais.
Para qualquer entrega, você deveria conseguir responder:
- Recebemos a requisição, e quando?
- A verificação da assinatura passou ou falhou, e por quê?
- Qual foi o evento (event ID), e já processamos isso?
- Quanto tempo levou o processamento, e onde o tempo foi gasto?
- O que retornamos ao remetente (código de status e tipo de erro)?
Esse é o núcleo: um rastro claro de “chegou” até “feito”, com contexto suficiente para depurar retries, duplicatas e falhas parciais.
Uma linha de base sólida é capturar um pequeno conjunto de cabeçalhos da requisição (não todos), o resultado da verificação da assinatura (pass/fail mais uma razão curta), um identificador de evento estável, timestamps (recebido/iniciado/terminado) e um resultado final (processado, ignorado como duplicado, rejeitado como inválido).
Tenha cuidado com privacidade. Não registre segredos, assinaturas brutas, tokens de autenticação ou payloads completos por padrão. Se precisar de visibilidade do payload, armazene um snapshot minimalista e redigido (por exemplo: tipo de evento, hash do customer ID, valor) e mantenha qualquer body cru apenas para debugging de curta duração em um local protegido.
Se os payloads podem conter dados pessoais (nomes, e-mails, endereços, detalhes de saúde ou financeiros), trate logs de webhook como dados de usuário. Defina limites de retenção, restrinja acesso e documente quem pode ver. Isso frequentemente faz a diferença entre “log útil” e um incidente de conformidade.
Registre checagens de assinatura sem vazar segredos
A verificação de assinatura é o teste “você é realmente quem diz ser?” do seu webhook. Ela impede que chamadores aleatórios atinjam seu endpoint fingindo ser seu provedor de pagamentos, serviço de e-mail ou outro sistema.
Para observabilidade, você quer detalhe suficiente para responder duas coisas rápido: a verificação foi executada, e por que falhou? O truque é logar resultados e contexto, não material secreto.
Um padrão seguro é um registro de verificação por requisição, com campos úteis para suporte e debug, mas inofensivos se copiados para um ticket.
Registre coisas como:
- Resultado:
verified=true/falsee umareasonclara comomissing_signature,bad_format,timestamp_out_of_windowoumismatch - O que você esperava: nome do algoritmo (por exemplo
hmac-sha256) e qual cabeçalho você buscou (apenas o nome do cabeçalho) - Contexto de tempo: timestamp do servidor, idade da requisição (em segundos) e se proteção contra replay foi aplicada
- Identificadores: seu
request_idgerado e, se presente, o event ID do provedor
Não registre a chave secreta, o valor bruto da assinatura, o payload completo ou cabeçalhos não redigidos.
Quando a verificação falhar, evite logs tipo “dump the request”. Em vez disso, registre um resumo pequeno e redigido: tamanho do payload, content-type e quais cabeçalhos obrigatórios estavam presentes.
Adicione contadores simples para que falhas apareçam mesmo quando ninguém está olhando os logs. No mínimo, monitore totais para verified, failed e missing signature (opcionalmente por provedor). Se um deploy acidentalmente muda o nome do cabeçalho esperado, seus logs devem mostrar reason=missing_signature subindo, em vez de um 401 vago sem pista.
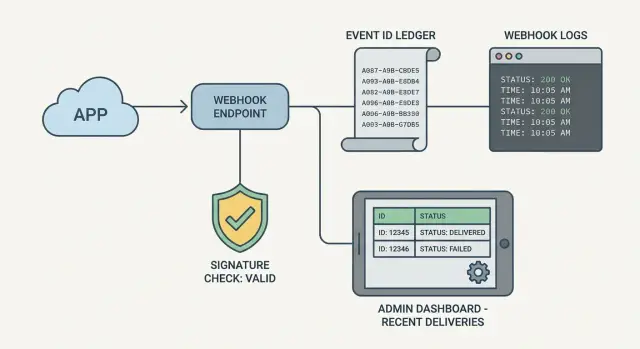
Armazene IDs de evento para deduplicar e traçar retries
A maioria dos provedores de webhook reenvia o mesmo evento se seu endpoint der timeout, retornar 500 ou ocorrer um problema de rede. Se você não armazenar um identificador de evento estável, pode cobrar duas vezes, provisionar duas vezes ou enviar e-mails duplicados. Salvar o event ID é o caminho mais simples para idempotência: o mesmo evento pode te atingir 1 vez ou 10 vezes, mas você aplica seus efeitos apenas uma vez.
Comece armazenando um pequeno registro para cada webhook recebido, mesmo que ainda não faça mais nada. Pode ficar em uma tabela de banco, numa store chave-valor ou numa fila mais uma tabela de auditoria pequena.
Um registro mínimo normalmente inclui provider, event ID, timestamp de recebimento, status (received/processed/failed/ignored) e uma mensagem de erro curta opcional.
Então, para cada requisição, faça isto em ordem: extraia o event ID, insira-o com uma restrição única em (provider, event ID), e se já existir, retorne 200 rapidamente e pule a ação de negócio. Essa única checagem transforma retries de adivinhação em uma linha do tempo confiável.
Alguns provedores não enviam um event ID claro, ou seu handler não consegue lê-lo até passar pela verificação da assinatura. Nesse caso, derive o seu a partir de partes estáveis da requisição, como um hash de provider + request path + um cabeçalho estável + bytes do body. Evite timestamps ou qualquer coisa que mude entre retries.
A retenção importa porque payloads de webhook frequentemente contêm dados pessoais. Uma regra prática é manter resumos por mais tempo e dados brutos por menos tempo (ou não mantê-los). Guarde a linha de evento (provider, event ID, timestamps, status) por 30 a 90 dias, mantenha qualquer body cru por uma janela curta (24 a 72 horas) se for guardar, e limite o tamanho de mensagens de erro para reduzir o risco de vazar segredos.
Exemplo: um provedor de pagamento reenvia o mesmo evento invoice.paid três vezes. Com event IDs armazenados, você vê um registro marcado como processado e entregas posteriores marcadas como duplicadas, então sabe que o cliente não foi cobrado duas vezes e por que o provedor continuou tentando.
Registre o ciclo de vida: recebido → processado → respondido
Um webhook pode parecer “ok” porque o remetente recebeu 200, enquanto seu app falhou depois. Para tornar a observabilidade real, separe o recebimento da entrega (o que você retorna ao remetente) do processamento de negócio (o que sua aplicação realmente fez).
Quando possível, reconheça rapidamente e faça trabalho pesado em background. Mesmo se processar inline, registre as duas partes como passos distintos para que você possa dizer se o problema foi verificação, parsing, trabalho no banco de dados ou timeout.
Um modelo simples de ciclo de vida que você pode consultar
Escolha um pequeno conjunto de estados e mantenha-os. O objetivo não é detalhe perfeito. É respostas rápidas.
Registre uma linha (ou documento) por evento recebido com:
- Timestamps: received, verified, processing started, processing finished, responded
- Durações: tempo de verificação, tempo de processamento, tempo total
- Estado: received, verified, processed, failed, ignored
- Resposta: status code, versão do handler (opcional), classe de erro (sem segredos)
- Correlação: event ID do provedor mais seu ID de correlação interno
Com isso você vê padrões rapidamente. Se a maioria das falhas acontece depois da verificação e leva 25s, provavelmente é uma chamada de banco lenta, um worker de fila travado ou um índice ausente.
IDs de correlação conectam o webhook ao resto do sistema
Um webhook raramente termina no endpoint. Ele cria um usuário, marca uma fatura paga, envia um e-mail de recibo ou atualiza acessos.
Armazene o event ID do provedor e gere um correlation ID que você passe para logs e jobs downstream. Uma única busca então mostra a cadeia: requisição recebida, assinatura verificada, job enfileirado, pagamento marcado como pago, e-mail enviado.
Isso importa em bases de código onde o handler mistura “responder ao webhook” e “fazer todo o trabalho” numa função só. Tornar o ciclo de vida explícito transforma um mistério em uma linha do tempo.
Passo a passo: adicione observabilidade a um handler existente
Toda requisição de webhook deve deixar um rastro que você possa seguir depois, mesmo que falhe no meio do caminho.
Uma ordem prática que funciona bem em um endpoint existente:
- Adicione logs estruturados com um conjunto consistente de campos em cada requisição (provider, event ID, request ID, assinatura verificada, resultado, duração).
- Verifique a assinatura cedo, então registre apenas o resultado (pass/fail) e por que falhou. Nunca registre o segredo ou a assinatura bruta.
- Persista o event ID do provedor assim que o tiver e deduplicate nele. Se for um retry, retorne uma resposta segura e registre que foi deduped.
- Envolva a lógica de negócio para sempre capturar status, tipo de erro e tempo, mesmo quando uma exceção for lançada.
- Adicione uma view administrativa mínima que mostre eventos de webhook recentes e os detalhes necessários para responder “o que aconteceu?”
Após o primeiro passo, mantenha o esquema de logs estável. Quando campos mudam toda semana, buscar vira um exercício de adivinhação. Se puder, gere um request ID na borda e carregue-o pelos logs e pelo registro de evento.
Para checagens de assinatura, torne mensagens de falha humanas. “Signature failed: missing header X” é acionável. “Invalid signature” não é. É também aqui que equipes acidentalmente vazam dados sensíveis, então seja rigoroso sobre o que registra.
Para a view administrativa, você não precisa de um dashboard completo. Uma tabela com os últimos 50 eventos e uma página de detalhe já bastam. A página de detalhe deve mostrar hora de recebimento, event ID, status de processamento, código de resposta, duração e a última classe de erro (por exemplo: ValidationError vs DatabaseError).
Uma pequena view administrativa que responde “o que aconteceu?”
Você não precisa de um dashboard extenso para depurar webhooks. A menor view útil é uma tela com uma tabela de eventos recentes e um painel de detalhe. Quando alguém perguntar por que um pagamento, cadastro ou envio não foi atualizado, você deve ser capaz de responder em dois minutos.
Uma boa tabela de eventos recentes mostra o suficiente para identificar padrões como retries repetidos, um provedor com outage ou seu handler retornando 500s. Mantenha-a consistente para fácil escaneamento.
Inclua:
- Event ID (ID do provedor, mais seu ID interno se tiver)
- Provider e tipo de evento, hora de recebimento
- Status (received, verified, processed, failed, ignored)
- Tentativas e hora da última tentativa
- Última mensagem de erro (curta, aparada)
No painel de detalhe, foque no que alguém precisa a seguir: a verificação de assinatura passou, qual versão do handler rodou, que resposta foi enviada, timestamps chave (received/verified/processed) e o correlation ID que liga aos seus logs.
Ações podem ajudar, mas só se forem seguras: reprocessar (apenas se o handler for idempotente), marcar como ignorado (para eventos ruins conhecidos ou ruído de teste), adicionar uma nota interna e copiar um resumo para suporte (event ID, status, última mensagem de erro).
Bloqueie essa view para admins e registre toda ação administrativa (quem fez, quando, por quê).
Erros comuns que tornam o debug de webhooks mais difícil
Um webhook pode estar “funcionando” e ainda assim ser impossível de entender quando algo dá errado. A maior parte da dor vem de escolhas pequenas que escondem a falha real ou criam efeitos colaterais barulhentos.
Um grande erro é logar payloads completos. Muitos corpos de webhook incluem e-mails, endereços, tokens ou segredos por acidente. Em vez disso, registre um resumo seguro: tipo de evento, provider, event ID, timestamp da requisição e um hash curto do body. Se precisar de mais detalhe, armazene uma cópia criptografada com retenção curta e acesso restrito.
Retries também podem se tornar auto-infligidos. Se um evento já foi processado, retornar um status não 2xx frequentemente desencadeia retries intermináveis e ações duplicadas downstream. Faça de “já processado” um resultado explícito e retorne 2xx com uma entrada de log clara dizendo que foi deduped.
Outra armadilha comum é misturar falhas de verificação com falhas de processamento. Se a verificação da assinatura falha, isso é um sinal de segurança. Se a lógica de negócio falha depois da verificação, é um bug do app ou problema de dados. Se ambos aparecerem como “500 error”, você perde a capacidade de agir rápido.
Problemas operacionais frequentes:
- Sem timeout em chamadas a banco ou APIs, então o handler fica pendurado até o provedor desistir
- Erros logados sem nome do provedor, tipo de evento, event ID e request ID interno
- Só logar exceções, não a decisão tomada (ignored, queued, processed, deduped)
- Formatos de log diferentes entre ambientes, dificultando comparações
Exemplo: um provedor de pagamentos reenvia um evento 12 vezes. Seus logs mostram 12 linhas “500” mas nenhuma pista se a assinatura falhou, o banco deu timeout ou o evento já havia sido processado. Com observabilidade, a primeira entrada mostraria “verified ok”, a próxima mostraria “DB timeout after 3s” e retries posteriores seriam deduped assim que o event ID fosse armazenado.
Verificações rápidas antes de considerar pronto
Teste a observabilidade de webhooks como uma pessoa estressada, com sono e com pressa. Se você não consegue responder perguntas básicas rápido, o futuro você irá sofrer quando o provedor reenviar o mesmo evento por horas.
Comece com um benchmark simples: escolha um event ID real do provedor e cronometre-se. Você deve conseguir encontrar aquele evento único (e seu histórico de entrega) em menos de 30 segundos, sem adivinhar qual servidor o processou.
Uma checklist pré-voo curta resolve a maioria das lacunas:
- Busca funciona: colar o event ID do provedor mostra um registro claro, não cinco quase-duplicados
- Status da assinatura é óbvio: logs mostram verified yes/no, e a razão quando falha
- Retries são visíveis: contador de tentativas e hora da última tentativa fáceis de achar
- Tipo de falha é claro: você pode distinguir exceção vs timeout vs validação
- Dados são seguros: segredos e dados pessoais estão excluídos ou redigidos em logs e armazenamento
Faça um drill realista. Dispare um evento que você sabe que vai falhar (por exemplo, payload sem um campo obrigatório). Confirme que você pode responder: chegou até você, a verificação passou, o que retornou, foi lento e houve retry?
Por fim, verifique vazamentos acidentais. Webhooks frequentemente contêm e-mails, endereços, tokens ou metadados completos de cartão. Logs devem armazenar apenas o que você precisa para debug: event ID, nome do provedor, timestamps, resultado da assinatura, status e uma mensagem de erro curta.
Exemplo: um webhook de pagamento falhou e como você o rastreia
Um ticket de suporte comum: seu provedor de pagamento envia um webhook invoice.paid, o cartão do cliente é cobrado, mas ele ainda não tem acesso ao plano pago.
Com observabilidade em vigor, você para de adivinhar. Abre a view administrativa e busca pela janela de tempo. Encontra a chamada exata do webhook.
As primeiras perguntas são respondidas imediatamente: verificação da assinatura “pass”, o event ID do provedor está salvo (por exemplo, evt_01H...) e o timestamp da requisição bate com o que o provedor mostra. Você sabe que é real e chegou ao seu servidor.
Nos detalhes do evento, o ciclo de vida mostra:
- Received: 2026-01-20 14:03:12
- Verified: pass
- Processing: failed
- Responded: 500
O campo de erro aponta a causa, por exemplo “Cannot insert subscription row: missing user_id.” Isso indica que o bug está no seu código, não no provedor.
Agora os retries começam a chegar. Aqui a idempotência importa. Como você armazenou o event ID e o tratou como único, o handler não concede acesso duas vezes. Entregas posteriores são registradas como duplicadas e puladas, ou reexecutadas com segurança dependendo do seu design.
Depois de consertar o bug, você pode reprocessar o evento falhado a partir da view administrativa. O estado vira para processed, a resposta passa a 200 e o cliente recebe acesso.
Para suporte, você agora tem fatos limpos para compartilhar: o timestamp do evento original, o event ID e o estado atual (received, verified, processed, failed).
Próximos passos se seu código de webhook ainda parecer frágil
Se seu handler ainda parece uma caixa-preta, comece com a menor mudança que te dá sinal: registre o resultado da verificação de assinatura (pass/ fail) e armazene o event ID do provedor. Isso normalmente transforma “não funcionou” em um caminho claro para a correção, sem mudar a lógica de negócio.
Mantenha esses primeiros logs entediantes e seguros. Registre outcomes e tempos, não segredos. Log que a verificação falhou, qual provedor era e qual event ID veio, mas nunca registre headers crus ou valores de assinatura.
Quando você capturar IDs de evento e status de forma confiável, adicione uma view administrativa pequena. Não construa um dashboard completo ainda. Uma tabela simples que responde “recebemos, verificamos, processamos, que erro ocorreu e o que retornamos?” já é suficiente.
Se o código do webhook foi gerado por uma ferramenta de IA e parece não confiável, planeje uma limpeza. Sinais comuns são suposições de auth quebradas, comportamento de retry confuso (cobranças duplas, e-mails duplicados) e segredos espalhados em configs ou logs.
Uma ordem prática de trabalho:
- Adicione logs estruturados para resultado da assinatura e request ID
- Armazene event IDs dos webhooks e dedupe neles
- Registre um ciclo de vida claro (received, verified, processed, failed)
- Adicione uma view administrativa pequena para eventos e erros recentes
- Faça um refactor direcionado para retries, idempotência e tratamento de segredos
Se você está lidando com um protótipo gerado por IA e precisa deixá-lo pronto para produção, FixMyMess (fixmymess.ai) foca em diagnosticar e reparar código gerado por IA, incluindo handlers de webhook com auth instável, bugs de retry e logs inseguros.
Perguntas Frequentes
What’s the simplest way to make my webhook handler observable?
Comece registrando três coisas em cada requisição: se a verificação da assinatura passou, o ID do evento do provedor e um resultado claro como processed, failed ou deduped. Adicione tempos (recebido e finalizado) para detectar timeouts. Essa base pequena geralmente transforma um 500 misterioso em algo que você pode agir rapidamente.
Why do webhook bugs feel so hard to debug compared to normal API calls?
Webhooks falham de forma silenciosa porque você não controla quando são enviados nem de onde vêm, e os provedores frequentemente reenviam em segundo plano. Sem IDs de evento armazenados e logs estruturados, cada retry parece uma requisição nova, e você não consegue saber se é um duplicado, um problema de assinatura ou um bug real de processamento.
What should I log for signature verification without leaking secrets?
Registre o resultado e a razão, não o material secreto. Um bom registro é verified=true/false com uma razão curta como missing_signature ou timestamp_out_of_window, junto com qual cabeçalho você checou e o nome do algoritmo. Não registre a chave de assinatura, a assinatura bruta ou cabeçalhos não redigidos.
How do I stop retries from causing duplicate charges or duplicate records?
Salve o ID do evento do provedor o mais cedo possível e aplique uma restrição única em (provider, event_id). Se já o tiver visto, retorne 2xx e pule a ação de negócio, registrando que foi deduped. Isso previne cobranças duplas, provisionamento duplicado e e-mails repetidos durante retries.
What if my webhook provider doesn’t include a reliable event ID?
Derive um ID estável a partir de partes que não mudam entre retries, por exemplo um hash de provider + request path + raw body bytes, ou um cabeçalho estável mais o corpo. Evite timestamps ou qualquer coisa que difira a cada tentativa. Depois de derivá-lo, trate-o como um ID de evento normal para dedupe e rastreamento.
What lifecycle fields should I record so I can trace where it failed?
Separe “recebimento da entrega” de “processamento de negócio”. Registre quando a requisição chegou, quando a verificação terminou, quando o processamento começou e terminou, e qual código de resposta você retornou. Assim fica óbvio quando você respondeu 200 mas o trabalho real falhou depois, ou quando um processamento lento causou timeout no provedor.
How do I log webhook data without creating a privacy or compliance problem?
Mantenha apenas resumos seguros por padrão: provider, event ID, tipo de evento, timestamps, status e uma mensagem/ classe de erro curta que não contenha segredos ou dados pessoais. Se armazenar corpos brutos, criptografe-os, restrinja acesso e mantenha por um período curto. Trate logs de webhooks como dados de usuário porque frequentemente contêm e-mails, endereços ou metadados financeiros.
What should a minimal admin view for webhooks include?
Uma tabela de eventos recentes mais uma view de detalhe é suficiente. Mostre event ID, provider, tipo, hora de recebimento, status, tentativas/última tentativa, resultado da assinatura, código de resposta, duração e a última classe de erro. Se adicionar um botão de reprocessar, garanta que o handler seja idempotente para não aplicar efeitos duas vezes.
What are the most common mistakes that make webhook debugging worse?
Não despeje payloads brutos nem registre cabeçalhos, tokens ou assinaturas crus. Separe falhas de verificação de assinatura de falhas de processamento. Não esqueça timeouts em chamadas a DB e APIs externas, e não deixe de armazenar IDs de evento, ou você perderá a capacidade de ver duplicatas e retries claramente.
My webhook code was generated by an AI tool and keeps breaking—what should I do?
Se o handler foi gerado por IA e é instável, comece com uma auditoria rápida da verificação de assinatura, idempotência, tratamento de segredos e segurança dos logs. Se precisar consertar rápido, FixMyMess (fixmymess.ai) pode diagnosticar e reparar handlers gerados por IA, reforçar segurança e tornar retries seguros, tipicamente em 48–72 horas após uma auditoria de código gratuita.