Quando adicionar uma réplica de leitura: sinais, roteamento e armadilhas
Quando adicionar uma réplica de leitura: sinais claros, roteamento seguro de leituras e como evitar surpresas causadas por atraso de replicação e suposições erradas.
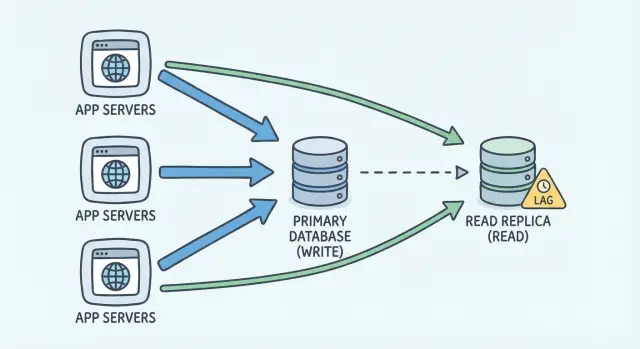
Qual problema uma réplica de leitura realmente resolve
Uma réplica de leitura ajuda quando seu banco de dados passa tanto tempo respondendo leituras que as gravações começam a sofrer. Isso não é só sobre deixar páginas mais rápidas — é sobre proteger o banco primário para que ele possa continuar aceitando atualizações em vez de ficar preso atrás de consultas SELECT pesadas.
Normalmente isso aparece num padrão familiar: uma ou duas telas populares (ou endpoints de API) geram a maior parte do trabalho do banco. Um dashboard que atualiza com frequência, uma página de busca ou uma visão administrativa “listar tudo” podem consumir CPU e I/O. Então as partes do app que criam pedidos, atualizam perfis ou gravam logs começam a estourar timeout ou a ficar imprevisíveis.
Uma réplica faz uma coisa principal: dá outra cópia dos dados para ler. Seu app pode enviar alguns SELECTs para a réplica para que o primário tenha mais espaço para INSERT/UPDATE/DELETE.
O que ela não corrige:
- Queries lentas por conta de escrita ruim ou índices faltando
- Problemas de locking causados por transações longas no primário
- Excesso de gravações (uma réplica não aumenta capacidade de escrita)
- Lógica de app que assume que toda leitura está imediatamente atualizada
Esse último ponto é o motivo pelo qual a decisão é sobre correção, não só velocidade. Uma réplica costuma ficar um pouco atrás do primário. Se você ler dela no momento errado, um usuário pode não ver suas configurações recém-atualizadas, uma página de “pagamento efetuado” pode ainda parecer não paga, ou um agente de suporte pode pensar que uma ação não ocorreu.
Uma boa regra prática: adicione uma réplica de leitura quando você tiver tráfego claramente dominado por leituras que prejudica a responsividade das gravações, e você conseguir apontar quais endpoints são seguros para servir com dados levemente desatualizados.
Noções básicas sobre réplica de leitura (sem jargão)
Uma réplica de leitura é um segundo servidor de banco que mantém uma cópia do seu banco principal. Você mantém um banco “primário” como fonte da verdade. Todas as gravações vão para lá, porque é o único lugar garantido a ter os dados mais recentes.
A réplica é usada principalmente para leituras. Em vez de cada carregamento de página, relatório ou gráfico atingir o primário, algumas queries somente leitura podem ir para a réplica para que o primário fique responsivo para gravações e requisições críticas.
Como a cópia se mantém atualizada
A maioria das configurações usa replicação assíncrona. Em termos simples: o primário grava as mudanças primeiro, depois a réplica recebe e aplica essas mudanças um pouco depois. Esse atraso é o replication lag. Às vezes é ínfimo (milissegundos). Sob carga, ou durante picos, pode crescer para segundos ou mais.
Esse único fato explica a maioria das surpresas que as pessoas enfrentam.
O tradeoff que você está escolhendo
Uma réplica pode fazer seu app parecer mais rápido, mas você paga com frescor. Leituras da réplica podem estar um pouco atrás do primário.
Um modelo mental simples:
- Primário: correto agora, lida com gravações
- Réplica: escala leituras, pode ficar atrás
- Lag: a lacuna entre o que você acabou de gravar e o que a réplica consegue ver
Exemplo: um usuário atualiza o email e atualiza a página de perfil imediatamente. Se essa página ler da réplica, pode ainda mostrar o email antigo por um momento. Isso não está permanentemente errado, mas é confuso a menos que você roteie essas leituras com cuidado.
Sinais de que você está pronto para considerar uma réplica
Uma réplica de leitura ajuda quando seu banco passa a maior parte do tempo em leituras (SELECTs), não em gravações. Se a CPU do banco está alta e suas queries de topo são principalmente SELECTs, isso é um forte sinal.
Outro sinal comum é “tráfego de leitura prejudica gravações”. Você vê latência nas gravações crescer exatamente quando o tráfego de leituras atinge pico, embora o volume de gravações não tenha mudado. Leituras e gravações competem pela mesma CPU, memória e disco, então páginas de relatórios pesadas podem desacelerar checkout, cadastros ou qualquer atualização.
Analise com cuidado o que está lento. Páginas de listagem, dashboards, tabelas administrativas, resultados de busca e exports costumam ser bons candidatos. Esses endpoints tendem a escanear muitas linhas e são chamados muitas vezes por usuários reais (ou jobs em background).
Pressão no pool de conexões é outro gatilho prático. Se você está batendo no máximo de conexões principalmente por causa de endpoints pesados de leitura, uma réplica pode reduzir a contenção. Isso não corrige queries ineficientes, mas pode dar folga.
Cache pode adiar a necessidade de réplica, mas nem sempre basta. Costuma ser hora de réplica quando:
- Taxa de hit no cache continua baixa porque dados mudam com frequência ou chaves são difíceis de projetar
- Cache causa problemas de “números errados” visíveis ao usuário
- Você precisa de dados razoavelmente frescos, mas não perfeitamente instantâneos
- Exports e filtros ad-hoc não podem ser cacheados com segurança
- Sua camada de cache já é uma fonte majoritária de bugs
Um processo de decisão que você pode seguir
Trate adicionar uma réplica como um pequeno experimento com métrica de sucesso clara. O objetivo não é “adicionar mais bancos”. É “reduzir dor sem quebrar correção”.
Comece sendo específico. “O app parece lento” não é suficiente. Você quer uma lista curta de endpoints e queries que possa medir antes e depois.
Um processo que funciona para a maioria dos times:
- Identifique seus principais endpoints de leitura por contagem de queries e tempo total (dashboard, busca, feed, relatórios).
- Confirme que o banco é o gargalo (não CPU do app server, código lento, cache ausente ou chamadas API chatas).
- Separe leituras em dois grupos: precisa ser fresco (saldos, permissões, checkout) vs pode ser levemente desatualizado (analytics, listas de atividade, páginas públicas).
- Defina uma meta verificável, como “reduzir a carga de leitura no primário em 40%” ou “cortar p95 do dashboard de 3s para 1s”.
- Defina um plano de rollback: como você trocará as leituras de volta para o primário rapidamente se algo der errado.
Então decida onde roteará leituras. Um bom primeiro passo é rotear apenas endpoints “que podem ser levemente desatualizados” para a réplica e manter todas as gravações no primário. Evite misturar leituras e gravações na mesma requisição no começo. É aí que o lag faz estrago.
Antes de ativar qualquer coisa em produção, faça uma checagem rápida de segurança:
- Você consegue dizer qual DB serviu uma requisição (logs, tags ou tracing)?
- Você consegue detectar lag e voltar temporariamente para o primário?
- Tem um plano de teste curto para correção visível ao usuário (login, pagamentos, permissões)?
Se não consegue medir melhoria e não consegue reverter rápido, pause. Uma réplica adiciona complexidade, então você quer que o benefício seja óbvio.
Quais endpoints se beneficiam (e quais devem ficar no primário)
Uma réplica ajuda mais quando você tem muitas leituras que não precisam estar perfeitamente atualizadas. O objetivo não é mover tudo. É tirar pressão do primário mantendo o app correto.
Bons candidatos para réplica
Normalmente são seguros porque são pesados em leitura e não ligados a dinheiro ou acesso:
- Páginas públicas (marketing, blog, páginas públicas de produto)
- Busca e navegação (filtros, listagens de categoria)
- Analytics e relatórios (gráficos, tendências, exports)
- Listas administrativas (tabelas de usuários, pedidos, logs) onde cliques abrem detalhes no primário
- APIs somente leitura usadas por parceiros ou ferramentas internas
Visualizações de perfil e catálogos de produto costumam ser OK com cuidado. A maioria dos usuários não nota se um avatar ou bio demora alguns segundos para atualizar.
Endpoints que devem ficar no primário
Se afeta dinheiro ou acesso, mantenha no primário. Isso inclui checkout, pagamentos, status de assinatura e qualquer coisa que decida o que um usuário pode ver ou fazer.
Também fique atento a endpoints que parecem somente leitura mas escrevem silenciosamente. Times frequentemente adicionam writes pequenos como atualizar last_seen, incrementar contadores de visualização, atualizar sessões ou registrar “recentemente visto”. Se você rotear esse endpoint para uma réplica, ele pode falhar (réplicas costumam ser somente leitura) ou se comportar de forma inconsistente.
Uma regra simples: envie para réplicas apenas queries idempotentes e somente leitura. Mantenha qualquer coisa que mude estado, ou decida acesso, no primário. Se você não tem 100% de certeza, trate como primário até verificar as queries.
Como rotear leituras sem tornar o app frágil
Roteamento de leituras soa simples: envie SELECTs para a réplica e mantenha gravações no primário. Na prática, a parte frágil é tudo ao redor: gerenciamento de conexões, momentos de “ler sua própria escrita” e o que acontece quando a réplica fica para trás.
Duas abordagens práticas de roteamento
Normalmente você roteia em um de dois lugares.
Se você rotea no código da aplicação, escolhe o banco por endpoint (ou por query). É direto porque é explícito: “navegar produtos” pode usar a réplica enquanto “atualizar perfil” fica no primário. A desvantagem é que regras de roteamento podem se espalhar pelo código e ficar difíceis de entender.
Se você rotea via proxy ou roteador de banco, as políticas ficam centralizadas, o que pode tornar rollbacks mais rápidos. O risco é que isso esconda surpresas: uma query que você assumiu segura pode ir para a réplica e começar a mostrar resultados desatualizados.
Torne resiliente (e fácil de desfazer)
Trate primário e réplica como recursos diferentes, não hosts intercambiáveis. Use conexões separadas e pools separados para que uma réplica lenta não bloqueie o pool usado para gravações.
Um conjunto pequeno de regras de segurança evita a maioria dos incidentes:
- Após um usuário gravar, mantenha-o “sticky” ao primário por uma janela curta (frequentemente segundos).
- Por padrão, use primário para qualquer coisa envolvendo dinheiro, auth, permissões ou conteúdo gerado pelo usuário logo após criação.
- Adicione um kill switch que envie todas as leituras de volta ao primário instantaneamente (flag de configuração, var de ambiente, feature flag) e teste-o.
- Configure timeouts agressivos para leituras na réplica e caia para o primário em vez de falhar a requisição.
Exemplo: um dashboard carrega 12 widgets. Roteie widgets lentos e não críticos (gráficos semanais, páginas top) para a réplica, mas mantenha “plano atual” e “última fatura” no primário. Se a réplica atrasar, a página continua funcionando; apenas os gráficos ficam um pouco defasados.
Como lidar com lag de replicação com segurança
Replication lag é o tempo que leva para novos dados gravados no primário aparecerem na réplica. Se seu app ler da réplica cedo demais, usuários podem ver informações antigas e assumir que algo quebrou.
Comece definindo o que “stale seguro” significa para seu produto. Para um dashboard, ficar 5 a 30 segundos atrás pode ser aceitável. Para billing, senhas ou permissões, até 1 segundo pode ser demais.
Regras práticas que evitam surpresas
Algumas regras cobrem a maioria dos casos reais:
- Use read-after-write: depois que um usuário atualizar algo, roteie as próximas requisições para o primário para aquele usuário (ou registro).
- Mantenha telas críticas no primário: pagamentos, login, controle de acesso e qualquer coisa que possa bloquear alguém.
- Se precisar mostrar dados da réplica numa tela crítica, mostre um estado “atualizando” e evite afirmar que algo é definitivo.
- Detecte lag e pare de usar a réplica quando subir demais.
- Evite misturar resultados do primário e da réplica na mesma resposta (cria combinações impossíveis).
Exemplo concreto: um usuário muda o email e cai na página de perfil. Se essa página ler da réplica, pode ainda mostrar o email antigo. Com read-after-write, você roteia essa página para o primário por 30 a 60 segundos após o update. Após essa janela, leituras normais na réplica voltam a ser usadas.
Roteamento sensível ao lag também importa durante picos e deploys. Réplicas frequentemente ficam para trás quando o primário está ocupado ou surge uma query de longa duração. Se seu app consegue medir o lag da réplica (ou usa uma checagem por threshold simples), você pode trocar leituras de volta ao primário até a réplica recuperar.
O que quebra primeiro quando você adiciona uma réplica
As primeiras quebras são geralmente as que os usuários notam imediatamente: “Eu salvei, mas não mudou.” Um pequeno atraso pode virar um grande problema de confiança.
Tickets de suporte costumam subir quando pessoas editam um perfil, mudam configurações ou postam um comentário e, ao atualizar, veem o dado antigo. Planeje para momentos de “ler sua própria escrita”, não apenas para ganhar capacidade.
Auth e checagens de permissão também falham cedo. Se um usuário acabou de atualizar um plano, foi adicionado a um time ou teve acesso revogado, uma leitura na réplica pode retornar o estado anterior. Isso leva a “por que ainda estou bloqueado?” ou, pior, “por que ainda consigo ver isso?”.
Jobs em background podem se comportar mal também. Muitos sistemas de jobs leem uma linha para decidir se há trabalho necessário. Com leituras desatualizadas, dois workers podem achar que a tarefa está pendente e executá-la em duplicidade, ou podem pular porque a réplica ainda não atualizou.
Mesmo quando nada está realmente errado, a UI pode parecer inconsistente. Paginação e ordenação podem saltar se uma requisição bate no primário e a próxima na réplica atrasada. Você verá duplicatas, itens faltando ou contagens de páginas que mudam entre cliques.
Contadores derivam mais rápido do que se espera: limites de taxa, contadores de visualização, badges de não lidos, totais de notificações. Se uma requisição incrementa no primário mas a próxima lê de uma réplica atrasada, números podem regredir.
Como padrão simples, mantenha no primário até testar cuidadosamente:
- Telas logo após um write (salvar, checkout, configurações)
- Login, checagens de permissão e leituras relacionadas à sessão
- Tabelas do tipo work-queue usadas por jobs em background
- Qualquer coisa que dependa de ordenação exata ou contagens
- Limites de taxa, quotas e contadores/badges
Erros comuns e armadilhas
A maior armadilha é enviar todo SELECT para a réplica porque “são só leituras”. Muitas leituras fazem parte de um fluxo que espera o último write: “criar conta” então “carregar perfil”, ou “adicionar ao carrinho” então “mostrar carrinho”.
Outro problema comum são dependências de read-after-write escondidas. Uma página de configurações pode salvar preferências e refazer um fetch em seguida. Um endpoint de login pode ler um registro de sessão logo após ele ter sido escrito. Se essas leituras baterem na réplica durante o lag, o app parece quebrado mesmo com a gravação tendo acontecido.
Gerenciamento de conexões é uma fonte silenciosa de dor. Se você compartilhar um único pool entre primário e réplica, o app pode acidentalmente enviar gravações para a réplica (ou aplicar configurações de réplica no primário). Mesmo quando “funciona”, depurar fica mais difícil porque logs e métricas não mostram claramente qual DB atendeu a query.
Monitoramento costuma ser adicionado tarde demais. Monitore lag, erros de query na réplica e queries lentas separadamente, e alerte sobre mudanças súbitas após deploys.
Algumas armadilhas a destacar:
- Roteamento por nome de endpoint em vez de por necessidade de frescor
- Esquecer que admin tools e jobs em background também executam queries
- Não testar comportamento de falha (réplica caída, picos de lag)
- Cachear leituras defasadas e torná-las stale por mais tempo do que pretendido
- Não ter um toggle rápido para enviar todo o tráfego de volta ao primário
Planeje um rollback antes de liberar. Uma feature flag que força todas as leituras ao primário pode economizar horas.
Lista rápida de verificação antes de ativar
Não comece pela infraestrutura. Comece com uma checagem de segurança para não trocar páginas lentas por bugs confusos de “por que minha mudança não salvou?”.
- Liste suas telas mais pesadas em leitura e marque quão frescas elas precisam ser.
- Defina uma regra de read-after-write (quem fica sticky ao primário, por quanto tempo e quais telas estão cobertas).
- Meça replication lag e decida um threshold onde você para de usar a réplica.
- Comprove que tem um kill switch e que ele funciona.
- Faça rollout gradual e observe timeouts, taxas de erro e inconsistências visíveis aos usuários.
Um exemplo simples: acelerar um dashboard sem quebrar a UX
Imagine um pequeno app SaaS. O dashboard tem gráficos, “top customers” e filtros por intervalo de datas que disparam queries pesadas de reporting. Enquanto isso, a área de configurações trata dados de cobrança, membros do time e permissões. O tráfego cresce, o dashboard começa a ficar lento e as gravações passam a ficar mais lentas em horários de pico.
Esse é um bom momento para considerar uma réplica de leitura: não porque você quer um novo banco, mas porque quer que leituras custosas parem de competir com gravações importantes.
Uma separação limpa normalmente fica assim:
- Relatórios do dashboard, exports e widgets de analytics leem da réplica.
- Configurações, permissões, convites e qualquer coisa que precise refletir uma mudança imediatamente ficam no primário.
- Endpoints mistos (por exemplo, cards do dashboard que também mostram o plano atual do usuário) ou leem o plano do primário ou aceitam um pequeno atraso.
Depois adicione stickiness de curta duração após writes. Se um usuário muda um papel de “Viewer” para “Admin” e é redirecionado ao dashboard, ler da réplica pode mostrar o papel antigo por alguns segundos. Marque a sessão com “ler do primário até o tempo X” (geralmente 30 a 60 segundos) após um save bem-sucedido. Durante essa janela, roteie leituras para o primário. Depois que a janela expira, volte a usar a réplica.
Se você está lidando com um codebase herdado gerado por IA onde o roteamento leitura/escrita já está espalhado ou frágil, FixMyMess (fixmymess.ai) foca em diagnosticar e reparar problemas como split inseguro de leitura/escrita e falta de fallbacks sensíveis ao lag para que réplicas melhorem performance sem criar bugs de correção.
Perguntas Frequentes
Que problema uma réplica de leitura resolve na prática?
Uma réplica de leitura ajuda quando o tráfego de leitura é tão pesado que atrasa as gravações no banco de dados primário. O objetivo é manter o primário responsivo para atualizações, descarregando queries somente de leitura seguras para outra cópia dos dados.
Se seu app parece lento mas o banco de dados não é realmente o gargalo, uma réplica não vai resolver o problema real.
Quando devo adicionar uma réplica em vez de apenas otimizar queries?
Use uma réplica quando suas queries mais ativas forem principalmente SELECTs e você notar latência nas gravações durante picos de leitura. Um sinal comum é que poucas telas (dashboards, busca, listas administrativas) consomem a maior parte do tempo do banco.
Se a dor vem de queries mal projetadas ou índices faltando, corrija isso antes de adicionar mais complexidade.
Quais endpoints costumam ser seguros para enviar a uma réplica?
Comece roteando endpoints que toleram dados um pouco desatualizados, como widgets de analytics, feeds de atividade, resultados de busca e tabelas administrativas grandes. Eles normalmente geram muito tráfego de leitura sem exigir frescor perfeito.
Mantenha o rollout inicial estreito para que você possa medir o impacto e desfazer rápido se os usuários reportarem resultados confusos.
O que sempre deve ficar no banco de dados primário?
Mantenha no primário tudo que envolve dinheiro, acesso ou confirmação imediata do usuário. Isso inclui checkout, pagamentos, status de assinatura, login, checagens de permissão e páginas visitadas logo após salvamentos.
Esses fluxos geralmente exigem “ler sua própria escrita” e o lag da réplica pode fazer o app parecer quebrado ou inconsistente.
O que é replication lag e por que importa?
Atraso de replicação é o intervalo entre escrever no primário e ver essa mudança na réplica. Com replicação assíncrona, a réplica normalmente fica um pouco atrás, e sob carga pode ficar segundos atrás.
Esse é o motivo pelo qual adotar réplica é uma decisão de correção, não só de velocidade.
Como evitar o problema de “acabei de atualizar, mas ainda vejo o dado antigo”?
Um padrão simples: depois que um usuário grava algo, roteie as próximas requisições dele para o primário por uma janela curta (frequentemente alguns segundos). Isso evita a sensação de “salvei, mas ainda está velho”.
Você pode implementar isso como stickiness por sessão ou regras de roteamento para endpoints específicos que seguem writes.
O que costuma quebrar primeiro depois de adicionar uma réplica?
A falha mais comum é inconsistência visível ao usuário: alguém atualiza configurações, atualiza a página e vê o valor antigo porque a leitura atingiu a réplica. Outra falha típica é controle de acesso: uma mudança de papel pode não ter chegado à réplica ainda.
Jobs em background também podem se comportar mal se tomarem decisões com leituras desatualizadas e executarem trabalho duplicado ou perderem trabalho.
Quais são os maiores erros que equipes cometem com réplicas de leitura?
Evite enviar mixes de primário e réplica na mesma resposta no começo, porque isso produz resultados contraditórios. Evite também rotear “qualquer SELECT” para a réplica — muitas leituras fazem parte de um fluxo que espera o último write.
Mantenha regras de roteamento simples e um rollback fácil para não ficar preso durante incidentes.
Como tornar o roteamento para réplicas seguro e reversível?
Tenha um kill switch que envie todas as leituras de volta ao primário instantaneamente e teste-o antes de precisar. Também defina timeouts agressivos para leituras na réplica e caia para o primário em vez de falhar a requisição.
Monitore lag da réplica e pare de usá-la quando o lag ultrapassar o limite que você considera seguro para o seu produto.
E se meu código for bagunçado (ou gerado por IA) e roteamento de leituras parecer arriscado?
Se a base de código tem acesso ao banco espalhado, writes ocultos dentro de endpoints “de leitura” ou não há como aplicar regras de read-after-write, adicionar uma réplica pode causar bugs confusos. Nesse caso costuma valer a pena arrumar roteamento, pooling de conexões e comportamento de fallback antes.
FixMyMess ajuda times a reparar código gerado por IA ou herdado onde a separação leitura/escrita é frágil, para que réplicas melhorem performance sem quebrar correção.