Registos de auditoria para ações de admin que resolvem disputas rapidamente
Registos de auditoria para ações de admin ajudam a ver quem mudou o quê, quando e porquê. Saiba o que capturar, como adicionar diffs e como pesquisar logs para resolver disputas.
Por que os registos de auditoria de admin e suporte importam
Quando algo muda numa app e ninguém sabe explicar porquê, o suporte transforma-se em adivinhação. Clientes sentem-se culpados, colegas sentem-se acusados, e pequenos problemas viram longos fios de conversa e respostas lentas a incidentes.
Ações de admin e suporte são os movimentos nos bastidores que podem alterar a experiência do utilizador sem que ele faça nada. Um agente de suporte reinicia uma password. Um admin muda um plano. Alguém remove conteúdo. Essas ações são muitas vezes necessárias, mas geram mais argumentos porque acontecem fora da vista.
As disputas normalmente soam assim:
- “Eu nunca pedi esse reembolso, por que foi emitido?”
- “A minha conta foi desativada, quem o fez e que regra foi acionada?”
- “A nossa subscrição foi rebaixada e funcionalidades desapareceram da noite para o dia.”
- “Uma publicação foi removida, mas precisamos provar o motivo e o tempo.”
- “O suporte alterou o meu email e agora não consigo entrar.”
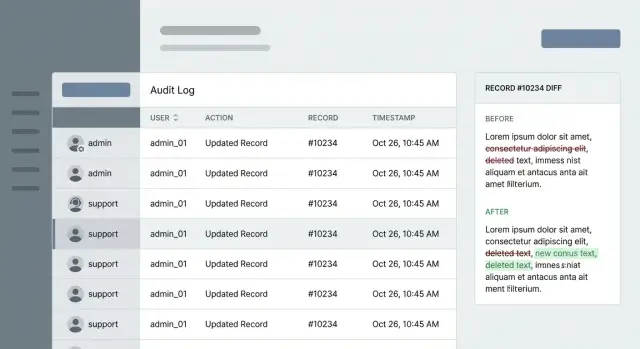
Nesses momentos, o objetivo de um registo de auditoria não é “mais dados”. É uma resposta clara. Uma entrada boa mostra quem fez o quê, em que registo, e quando. Uma entrada ótima também mostra o que mudou (um diff) e contexto suficiente para explicar porquê aconteceu (ID do ticket, código de motivo, nota interna).
Isto importa ainda mais para equipas que lançam rapidamente ou que herdam código gerado por IA. Quando a lógica é confusa, a app pode comportar-se de forma diferente do esperado, e ainda assim precisa-se de uma trilha fiável. Na FixMyMess, vemos frequentemente protótipos construídos com ferramentas como Cursor ou Replit onde painéis de administração estão meia-feitos e ações críticas não são registadas — é exatamente aí que as disputas se tornam dolorosas.
Bons logs resolvem discussões rápido, encurtam investigações e protegem tanto os clientes quanto a equipa com factos em vez de opiniões.
O que uma entrada de registo de auditoria deve conter
Um registo de auditoria só é útil numa disputa se cada entrada responder claramente a cinco perguntas: quem fez, o que aconteceu, o que foi afetado, quando aconteceu e de onde veio. Se faltar qualquer uma dessas, volta-se a adivinhar.
Comece pelo ator. Guarde um identificador estável (user ID, admin ID ou service account ID) e as permissões que tinha na altura (papel). Se o suporte puder impersonar utilizadores, registe isso explicitamente: realizado pelo admin X enquanto impersonava o utilizador Y. Sem isto, não dá para distinguir se a mudança foi feita pelo cliente ou pela equipa em nome dele.
Capture a ação e o alvo juntos. “Updated customer email” é melhor que “update”, mas não confie apenas em texto livre. Mantenha um nome de ação estruturado (create, update, delete, export, password reset, login override) e o registo exato que foi tocado. Inclua o tenant/workspace para poder separar contas.
Para o tempo, guarde um timestamp preciso em UTC e só o formate para hora local na apresentação. Disputas muitas vezes dependem de minutos, e UTC evita confusão com horário de verão.
Adicione contexto suficiente para traçar o evento de ponta a ponta. Uma base sólida é: ponto de entrada (nome da tela UI ou endpoint da API), request ID (e session ID se tiver), IP de origem e user agent (quando apropriado), resultado (sucesso/falha com código de erro) e um motivo de suporte ou referência de ticket.
Exemplo: um cliente diz, “O suporte mudou o meu plano sem pedir.” Uma entrada forte mostra o admin ID, se foi usada impersonação, uma ação como plan_update, o workspace alvo, um timestamp em UTC e um request ID que você pode seguir até à tela ou chamada API exata. Essa é a diferença entre uma história vaga e um registo que resolve o problema em minutos.
Rastrear diffs sem vazar dados sensíveis
Um diff é a forma mais simples de encerrar argumentos porque mostra os valores antes e depois para cada campo que mudou. O objetivo é clareza sem transformar os logs numa segunda base de dados cheia de dados privados.
Registe apenas o que mudou. Se um admin edita um registo de cliente, registe um payload pequeno como role: user -\u003e admin e status: trial -\u003e active, não o perfil completo. Isto mantém as entradas legíveis, torna as pesquisas mais rápidas e reduz a exposição acidental.
Campos sensíveis precisam de tratamento especial. Normalmente não quer valores brutos nos logs para passwords, access tokens, números completos de cartão ou notas privadas. Uma regra útil: se não iria colar isso numa conversa de suporte, não coloque num registo de auditoria.
Abordagens comuns incluem mascaramento (por exemplo, ****@gmail.com), hashing (uma impressão unidirecional), uma simples flag “changed” (como password: changed), redacção total, ou separar detalhes sensíveis num armazenamento distinto com acesso mais restrito e retenção mais curta.
Diffs são ainda mais úteis com intenção. Adicione um reason code (como customer_request, fraud_review, bug_fix, policy_exception) e uma nota curta. Quando uma disputa acontece mais tarde, o “porquê” importa tanto quanto o “o quê”.
Também capture IDs relacionados para poder reconstruir a história: ticket ID, conversation ID, order ID, refund ID e a chave primária do registo.
Exemplo: um cliente alega que o suporte atualizou o plano sem permissão. A sua entrada deve mostrar plan: basic -\u003e pro, a identidade do agente, o timestamp, reason code customer_request e um ticket ID que corresponda à conversa onde pediram a mudança. Se herdou código gerado por IA que regista demais (ou nada), a FixMyMess costuma começar por adicionar diffs seguros e regras estritas de redacção para que os logs resolvam disputas em vez de criar novos riscos.
Como desenhar logs em que possa confiar mais tarde
Logs confiáveis são menos sobre dashboards sofisticados e mais sobre regras aborrecidas que nunca mudam. Se quer que os registos de admin e suporte resolvam disputas, precisa de entradas que sejam difíceis de falsificar, fáceis de ler e consistentes em todos os caminhos de código.
Trate cada entrada como append-only. Não edite eventos antigos quando algo muda ou quando um agente comete um erro. Escreva um novo evento que corrija o anterior, assim a história permanece completa.
Use uma forma de evento única em todo lado, mesmo entre equipas e serviços diferentes. Quando suporte, admins, jobs em background e chamadas API produzem campos diferentes, o log deixa de responder a perguntas básicas sob pressão.
Um esquema prático de base:
- who: user ID, papel, e qualquer info de acting-as
- what: nome da ação (por exemplo,
user.password_reset) - where: tipo de registo e record ID
- when: timestamp do servidor (UTC)
- context: request correlation ID, origem (UI/admin panel/API key/background job), e IP/dispositivo quando apropriado
Correlation IDs são o que transforma “achamos que aconteceu por volta das 15h” em prova. Gere uma por pedido, passe-a por chamadas internas e anexe-a ao evento de auditoria. Se uma ação tocar três tabelas, o mesmo correlation ID permite ligar esses eventos a um único ticket de suporte ou clique.
Registe a origem sempre. “Admin changed plan” não basta quando a questão real é se veio da UI do admin, de uma API key usada por uma agência, ou de um job noturno.
Planeie retenção cedo. Decida por quanto tempo precisa dos eventos para disputas, quão grandes os logs podem ficar e onde vivem. Equipas que recorrem à FixMyMess frequentemente descobrem que a sua app gerada por IA nunca registou ações críticas ou eliminou histórico cedo demais, o que torna a verificação impossível quando um cliente contesta um débito.
Tornar os logs pesquisáveis para o trabalho real de suporte
A pesquisa é a diferença entre “achamos que isto aconteceu” e “aqui está o momento exacto em que mudou”. Desenhe a pesquisa do modo como o suporte trabalha: encontrar um cliente, estreitar para o registo e depois confirmar a mudança exacta.
Mantenha nomes de ação curtos e consistentes. Uma taxonomia apertada (pense em dezenas, não centenas) torna os filtros utilizáveis e evita o problema “tudo é custom” em que apps construídas rápido muitas vezes acabam. Se precisar de mais detalhe, coloque-o em campos estruturados, não num novo nome de ação.
Normalize o básico para que cada evento possa ser filtrado da mesma forma em toda a app.
Os campos que tornam a pesquisa realmente útil
Pelo menos, assegure que cada evento inclua:
- action (por exemplo,
user.password_reset,billing.refund_issued) - actor_id e actor_role (admin, support, system)
- record_type e record_id (sempre presentes, sempre com o mesmo formato)
- created_at (hora do servidor)
- request_id (para agrupar eventos relacionados)
Depois adicione um pequeno conjunto de campos de “contexto de suporte” seguros que ajudam na pesquisa: email do cliente (ou uma versão hasheada/normalizada), número de encomenda, nome do workspace/org e ticket ou conversation ID. Mantenha estes como campos separados, não enterrados numa frase.
Evite eventos ruidosos. Page views, aberturas de ecrã e logs “list loaded” enterram o sinal. Os registos de auditoria devem focar-se em ações que mudam estado, concedem acesso ou expõem dados sensíveis.
Faça cada entrada legível sem perder estrutura: uma frase clara para humanos mais campos estruturados para filtros. “Support agent updated billing email” ajuda, mas ainda deve incluir record_type=workspace, record_id=... e um resumo do diff que prove o que mudou.
Passo a passo: adicionar logging de ações de admin a uma app
Um workflow prático
Liste o que admins e suporte conseguem realmente fazer hoje, não o que espera que façam. Transforme cada capacidade num nome de evento claro para que o log leia como uma linha do tempo em vez de uma gaveta de tralha.
Um workflow simples:
- Inventarie ações de admin/suporte (refund, password reset, plan change, profile edit, role grant) e mapeie cada uma para um evento.
- Marque registos de alto risco que devem sempre registar (auth, billing, permissões, propriedade da conta).
- Defina o contexto obrigatório: ator, registo alvo, timestamp, motivo e um diff seguro.
- Implemente o logging na camada de serviço (onde correm as regras de negócio), não espalhado por botões da UI.
- Execute um “teste de disputa” que reconstrua quem mudou o quê e porquê usando apenas os logs.
Depois de mapear eventos, decida o que “target” significa na sua app. Um bom padrão é target_type (Subscription), target_id (sub_123) e IDs relacionados opcionais (como user_id). Isso facilita muito pesquisas posteriores.
Onde as equipas normalmente empacam
Alto risco não significa raro. Significa que uma mudança aqui pode custar dinheiro, bloquear alguém ou criar um argumento de suporte. Se estiver inseguro, comece com um conjunto curto: definições de autenticação, billing/invoices, papéis/permissões, mudanças de email/telefone e tudo o que afete acesso.
Exija um motivo humano para ações sensíveis, mesmo que curto. “Customer confirmed new email over phone” é muito mais útil que “updated”.
Faça uma disputa falsa antes de lançar. Finja que um cliente diz “O suporte rebaixou o meu plano sem pedir.” Pode puxar um evento que mostre: que admin, que registo, o diff antes/depois (Plan: Pro -\u003e Basic), a nota de motivo e o timestamp? Se não, corrija os campos agora.
Se está a reparar uma app gerada por IA, o logging na camada de serviço também reduz “eventos em falta” quando o código da UI muda. É muitas vezes uma das primeiras correções que equipas como a FixMyMess aplicam quando protótipos viram produtos reais.
Ações de alto risco para registar sempre
Se só vai registar poucas coisas, registe as ações que podem mudar dinheiro, acesso ou confiança. São os momentos que viram disputas: “Eu não mudei isso”, “O suporte acedeu aos meus dados”, ou “Alguém elevou as próprias permissões”.
As ações que merecem logging sempre ativo
Foque-se em eventos poderosos, difíceis de reverter ou que toquem dados sensíveis. Um teste simples: se um utilizador ficasse chocado ao ver isto numa fatura, screenshot ou relatório de conformidade, pertence ao log.
Priorize:
- Leituras de dados sensíveis (exports, downloads, “view full card”, abrir perfis completos com detalhes privados).
- Mudanças de papéis e permissões (atualizações de papel, pertença a grupos, API keys, definições SSO, flags de admin).
- Impersonação (início, fim e cada ação feita enquanto se impersona, registando tanto o membro da equipa quanto a conta do cliente).
- Ações em massa (reembolsos em lote, eliminações em massa, migrações, edições em batch), incluindo contagens e referências aos IDs afetados.
- Tentativas falhadas restritas (checagens de permissão negadas, tokens admin inválidos, exports bloqueados), com rate limits para evitar ruído.
Exemplo rápido de como isto resolve disputas
Um cliente diz, “O suporte descarregou a minha lista de faturas e mudou o meu plano.” Se os seus logs capturam tanto “Export invoices” (leitura) quanto “Plan changed” (escrita), pode mostrar rapidamente quem fez, quando, de que sessão e se ocorreu durante impersonação.
É aqui que muitos protótipos gerados por IA falham em produção: registam apenas writes bem-sucedidos e saltam leituras sensíveis. Plataformas como a FixMyMess costumam começar por adicionar esses eventos de alto risco porque entregam o maior retorno em confiança e suporte com uma pequena mudança de código.
Mantenha cada evento fácil de entender: um nome de ação claro, o(s) registo(s) tocado(s) e contexto suficiente para explicar por que aconteceu sem expor segredos.
Erros comuns que tornam os registos de auditoria pouco fiáveis
A maioria das disputas não acontece porque não há logs. Acontece porque os logs são vagos, incompletos ou impossíveis de confiar mais tarde. Uma trilha de auditoria deve ler como evidência: clara, específica e difícil de adulterar.
Uma falha frequente é registar um evento genérico como “updated user” sem detalhe a nível de campo. Quando um cliente diz “O suporte mudou o meu plano”, precisa ver exatamente o que mudou (valor antigo, valor novo), não apenas que “algo” aconteceu. Sem diffs também perde padrões como alternâncias repetidas ou sobrescritas acidentais.
Outro erro é despejar segredos e dados pessoais na trilha. Tokens completos, passwords, cookies de sessão, API keys ou dados de pagamento brutos nunca devem ficar nos logs. Guarde valores redigidos ou referências em vez disso, e registe que um campo sensível mudou sem registar o valor.
Atribuição de ator falha mais frequentemente do que as equipas esperam. Jobs em background, webhooks e scripts muitas vezes correm como “system”, mesmo quando acionados por um humano. Isso torna a trilha muito menos útil no trabalho real de suporte.
Matadores de fiabilidade a vigiar:
- Eventos podem ser editados ou apagados após o facto.
- O ator está em falta (ou é sempre “system”) para fluxos automatizados.
- Identificadores de registo não são estáveis, por isso as pesquisas trazem ruído.
- Nomes de ação não são consistentes, fazendo com que filtros percam metade da história.
- Diffs são parciais ou ambíguos (faltam before/after).
Exemplo: um fundador questiona uma alteração de reembolso. O seu log deve mostrar o diff do estado do reembolso, a conta admin que clicou, o ticket/motivo e o ID do registo. Quando a FixMyMess audita apps geradas por IA quebradas, esta é uma das primeiras lacunas que vemos: “foi atualizado” sem a prova necessária.
Checklist rápido para resolver uma disputa usando logs
Quando um cliente diz, “Eu não mudei isso” ou “A vossa equipa estragou a minha conta”, o objetivo é simples: construir uma linha do tempo clara que ambas as partes entendam. Bons logs permitem responder três perguntas rápido: quem fez, o que mudou e quando.
Comece amplo e depois estreite até estar a olhar para um evento específico e o seu diff exacto.
Uma forma rápida de chegar à verdade
- Encontre o cliente usando um identificador estável (customer ID, account ID, ticket ID) e confirme que está a olhar para o registo certo.
- Filtre por tipo de ação (password reset, refund, plan change) e por ator (admin específico, agente de suporte, job automatizado).
- Abra os detalhes da mudança e leia o diff, não apenas o resumo.
- Use o correlation/request ID para ver o que mais aconteceu no mesmo fluxo. Disputas frequentemente vêm de efeitos colaterais, não do clique original.
- Registe o resultado em palavras simples e, se necessário, adicione um evento de follow-up que registe a resolução.
Pequeno exemplo
Um cliente reporta que foi rebaixado sem consentimento. O log mostra um agente que mudou o plano, mas o mesmo correlation ID inclui uma tentativa de pagamento falhada segundos antes. O diff mostra que uma regra de downgrade correu automaticamente após a tentativa falhar. Isso normalmente resolve a disputa e aponta o que corrigir: clarificar a UI, apertar permissões ou melhorar a regra.
Se herdou uma app gerada por IA, isto é uma das primeiras coisas a adicionar durante o cleanup. Equipas como a FixMyMess frequentemente veem ações “powerful admin” a ocorrer sem rasto, o que transforma cada reclamação em adivinhação.
Exemplo: traçar uma mudança de suporte desde a queixa até à prova
Um cliente escreve: “A minha subscrição foi cancelada e eu não o fiz.” Aqui é onde os registos de admin e suporte acabam com a adivinhação. Quer uma trilha limpa que mostre quem tocou na conta, o que mudou e porquê.
Comece pelo registo do cliente e filtre eventos à volta do momento em que notou o problema. Numa boa trilha, encontra rapidamente uma impersonation (ou “login as user”) seguida de uma atualização de subscrição.
Aqui está como essa trilha pode parecer quando está a funcionar bem:
2026-01-16 09:41:03Z actor=support:maya action=impersonate_user target=user:1842
context: ticket=SUP-10488 reason="Asked to check billing page error"
2026-01-16 09:43:19Z actor=support:maya action=subscription_update target=sub:7711
source=ui request_id=8f3c... ip=203.0.113.24
diff:
status: active -\u003e canceled
cancel_at_period_end: false -\u003e true
context: ticket=SUP-10488 note="Customer requested cancel at renewal"
Dois detalhes resolvem disputas rapidamente: o diff (o que mudou) e o contexto (ticket ID, motivo e uma nota curta). O timestamp e o ator clarificam se foi uma ação de suporte ou do cliente.
Confirme a origem para não culpar o sistema errado:
- Ação UI: há um actor interno de utilizador mais um session/request ID.
- API key: o ator é uma key ou integração, muitas vezes com um key ID.
- Job automatizado: o ator é o nome do job, com um schedule/run ID.
Se a mudança estiver errada, reverta-a imediatamente (por exemplo, defina a subscrição de volta para active) e depois registe a ação corretiva como um evento próprio com uma nota de motivo como “Reverted cancel, customer did not consent.” Essa entrada final impede que a mesma discussão volte mais tarde.
Próximos passos: comece pequeno e depois fortaleça a trilha
Comece com um escopo mínimo que possa entregar no próximo sprint. Escolha as ações de admin e suporte que mais frequentemente causam discussões e chargebacks, e registe essas primeiro. Se só fizer uma coisa, assegure-se de que pode responder: quem fez, o que mudou, qual o registo e quando.
Uma forma prática de encontrar lacunas é um breve exercício de disputa. Pegue num ticket real passado (ou crie um falso) e tente provar o que aconteceu usando apenas os seus logs. Por exemplo: “Um cliente diz que o seu plano foi rebaixado sem permissão.” Consegue ver o utilizador exacto afectado, o ator (admin ou system), os valores antes/depois, e o contexto do ticket? Se não conseguir, escreva o que falta e adicione.
Depois que o básico funcione, adicione guardrails para que a trilha se mantenha segura e útil: mascarar ou omitir campos sensíveis (passwords, tokens, dados completos de cartão) enquanto ainda regista o facto da mudança, definir retenção que corresponda às necessidades de suporte e requisitos legais, restringir o acesso aos logs (e registar o acesso aos próprios logs), e adicionar alertas para ações de alto risco como mudanças de papel, reembolsos e resets de autenticação.
Se a sua base de código foi gerada por IA, o logging inconsistente é comum: ações acontecem em múltiplos locais, checagens de autenticação diferem por rota e mudanças “system” são difíceis de separar das humanas. Uma auditoria focada pode ser a correção mais rápida.
A FixMyMess (fixmymess.ai) oferece uma auditoria de código gratuita para identificar falta de logging de auditoria, trilhas de autenticação quebradas e lacunas de segurança, especialmente para protótipos gerados por IA que precisam de comportamento pronto para produção.
Perguntas Frequentes
Que problema os registos de auditoria de admin e suporte resolvem, na prática?
Um registo de auditoria transforma uma disputa numa linha do tempo verificável. Em vez de debater o que “deve ter acontecido”, você aponta para uma entrada que mostra quem agiu, o que fez, qual registo foi afetado e quando aconteceu.
Que ações de admin/suporte devo registar primeiro?
Registe qualquer ação que mude dinheiro, acesso ou confiança. Comece por reinicializações de password, mudanças de email, alterações de papéis/permissões, upgrades/downgrades de planos, reembolsos, cancelamentos, impersonação e exportações de dados sensíveis.
Que campos deve incluir cada entrada de registo de auditoria?
Uma entrada útil responde a cinco coisas: ator, ação, registo-alvo, timestamp e contexto de origem. Na prática isso significa um ID de ator estável e papel, um nome de ação estruturado, tipo de registo e ID, hora em UTC, além de detalhes de pedido/sessão e uma referência de ticket/motivo.
Como devo nomear ações para que os registos sejam pesquisáveis?
Use uma taxonomia pequena e consistente, por exemplo billing.refund_issued ou user.password_reset. Mantenha a explicação detalhada em campos estruturados (diff, reason code, ticket ID) para que os filtros continuem fiáveis e você não crie dezenas de nomes de ação quase idênticos.
Devo armazenar diffs (valores antes/depois) nos registos de auditoria?
Registe antes/depois a nível de campo apenas para os campos que mudaram. Os diffs devem ser pequenos e específicos (por exemplo, plan: basic -\u003e pro) para provar o que mudou sem despejar registos inteiros nos logs.
Como registo mudanças sem vazar dados sensíveis?
Não guarde valores brutos de segredos ou dados muito sensíveis como passwords, tokens, detalhes completos de pagamento ou notas privadas. Prefira redacção, mascaramento, hashing ou um marcador simples como “changed”, mantendo a entrada focada no facto da mudança e em quem/quando/onde aconteceu.
Porque devo guardar timestamps dos registos em UTC?
UTC evita confusão com horário de verão e fusos horários, algo comum em disputas onde minutos contam. Guarde timestamps em UTC e só converta para o horário local na UI quando alguém estiver a ler o registo.
Como devo registar a impersonação de suporte (“entrar como utilizador”)?
A impersonação deve ser explícita e rastreável. Registe o início e o fim da impersonação e, para cada ação executada enquanto se faz impersonação, registre ambas as identidades: o membro da equipa que a realizou e o utilizador/conta em cujo nome atuou.
Como tornar os registos de auditoria confiáveis e difíceis de manipular?
Torne os registos append-only e trate-os como evidência. Se algo estiver errado, escreva um novo evento corretivo que referencie o original e restrinja quem tem acesso ou pode apagar logs; também deve registar acessos aos próprios logs.
A minha app foi construída com ferramentas de IA e o logging está uma confusão — isto pode ser corrigido rapidamente?
Sim — é comum que protótipos gerados por IA percam registos críticos ou registem de forma inconsistente. Uma correção prática é implementar logging na camada de serviço (onde correm as regras de negócio), padronizar o formato do evento e os nomes de ação, e adicionar diffs seguros com redacção; a FixMyMess pode fazer uma auditoria rápida para identificar as faltas e corrigi-las rápido.