Registos estruturados para depuração de 5 minutos em produção
Registos estruturados tornam bugs em produção mais fáceis de reproduzir rapidamente. Adicione request IDs, limites de erro e padrões de log prontos a copiar para depuração em 5 minutos.
Por que bugs em produção parecem impossíveis de reproduzir
Um relatório de bug em produção costuma parecer isto: “Deu erro quando cliquei no botão.” Sem captura de ecrã, sem hora exata, sem ID do utilizador e sem pista sobre dispositivo ou browser. Quando tenta reproduzir, funciona normalmente.
Produção é caótica porque as condições exatas são difíceis de recriar. Utilizadores reais têm contas diferentes, dados diferentes, redes instáveis, várias abas abertas e sessões obsoletas. Um problema raro de temporização pode causar um crash que nunca aparece em staging.
Mensagens no console e erros vagos não sobrevivem a esse ambiente. O console do utilizador não é o seu console, e mesmo que recolha logs, “algo falhou” não indica qual pedido, qual flag de funcionalidade ou qual serviço upstream disparou o erro. Pior ainda, um erro não tratado pode parar a app antes de registar o detalhe que precisava.
O objetivo é simples: quando chega um relatório, você deve ser capaz de responder a três perguntas em minutos:
- O que aconteceu (o evento e a ação do utilizador)
- Onde aconteceu (o pedido exato, a página e o componente)
- Por que aconteceu (o erro, mais o contexto importante)
É por isso que registos estruturados importam. Em vez de despejar frases aleatórias, regista-se eventos consistentes com os mesmos campos sempre, para que possa filtrar e seguir a história entre serviços e ecrãs.
Não precisa de uma grande reescrita para chegar lá. Pequenas mudanças somam-se rápido: adicione um request ID a cada pedido, inclua-o em cada linha de log e capture crashes com limites de erro (error boundaries) para ainda assim recolher contexto quando a UI falha.
Aqui vai um exemplo realista. Um fundador diz: “O checkout por vezes fica a girar para sempre.” Sem logs melhores, adivinha: provedor de pagamento? base de dados? autenticação? Com request IDs e eventos consistentes, pode pesquisar um ID e ver: checkout_started, payment_intent_created, seguido por um timeout em inventory_reserve, e depois um erro na UI. Agora tem um único caminho falhado para reproduzir.
Se herdou uma app gerada por IA onde os logs são aleatórios ou estão em falta, isto normalmente é uma das correções com maior retorno. Equipes como a FixMyMess costumam começar com uma auditoria rápida do que se pode ou não traçar hoje, depois adicionam o mínimo de logging para que o próximo bug seja uma investigação de 5 minutos em vez de uma semana de suposições.
O que são registos estruturados, em linguagem simples
Registos em texto simples são do tipo que provavelmente já viu antes: uma frase impressa no console como “Login do utilizador falhou”. São fáceis de escrever, mas difíceis de usar quando algo quebra em produção. Cada pessoa escreve mensagens de forma diferente, detalhes são omitidos e a pesquisa vira tentativa e erro.
Registos estruturados significam que cada linha de log segue a mesma forma e inclui detalhes chave como campos nomeados (frequentemente em JSON). Em vez de uma frase, regista-se um evento mais o contexto em volta. Assim, pode filtrar, agrupar e comparar logs como dados.
Um bom log deve responder a algumas perguntas básicas:
- Quem foi afetado (qual utilizador ou conta)
- O que aconteceu (a ação ou evento)
- Onde aconteceu (serviço, rota, ecrã, função)
- Quando aconteceu (timestamp normalmente adicionado automaticamente)
- Resultado (sucesso ou falha, e porquê)
Aqui está a diferença na prática.
Texto simples (difícil de pesquisar):
Login failed for user
Estruturado (fácil de filtrar e agrupar):
{
"level": "warn",
"event": "auth.login",
"userId": "u_123",
"requestId": "req_8f31",
"route": "/api/login",
"status": 401,
"error": "INVALID_PASSWORD"
}
Os campos mais úteis são geralmente os mais maçantes que desejará ter mais tarde: event, userId (ou account/team ID), requestId e status. Se só adicionar quatro campos, comece por aí. Eles permitem responder: “Qual o pedido exato que este utilizador fez, e o que a app retornou?”
A estrutura é o que torna a depuração em produção rápida. Pode rapidamente pesquisar todas as falhas event = auth.login, agrupar por status, ou puxar todos os logs com requestId = req_8f31 para ver a história completa de um problema de utilizador. Essa é a diferença entre ficar 30 minutos a percorrer logs e encontrar o problema em 5.
Request IDs: a forma mais rápida de traçar um problema de utilizador
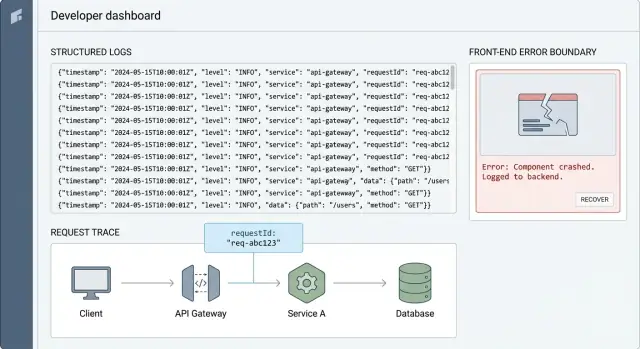
Um request ID é uma string curta e única (como req_7f3a...) que anexamos a uma ação de utilizador. O ponto é simples: ela liga tudo o que aconteceu para essa ação, desde o clique no frontend até à API, à query à base de dados e de volta.
Sem isso, a depuração em produção vira adivinhação. Pesquisa logs por tempo, utilizador ou endpoint e ainda acaba com uma pilha de mensagens não relacionadas. Com um request ID, pode filtrar até uma única história e lê-la em ordem.
Isto é correlação: o mesmo ID aparece em cada linha de log que pertence ao mesmo pedido. É a cola que torna os registos estruturados realmente utilizáveis quando está sob pressão.
Onde o request ID deve ser criado
Crie o ID o mais cedo possível e passe-o por cada camada.
- Na borda (CDN / load balancer) ou API gateway, se tiver um
- Caso contrário, no ponto de entrada do backend (o primeiro middleware que trata do pedido)
- Se nenhum existir (comum em protótipos gerados por IA), gere-o no handler do servidor antes de qualquer outro trabalho
Uma vez criado, devolva-o ao cliente num header de resposta também. Quando um utilizador disser “Deu erro”, pode pedir esse ID ou mostrá-lo numa tela de suporte.
Quando reutilizar vs gerar um novo ID
Reutilize o mesmo request ID durante toda a vida de um pedido, incluindo chamadas internas desencadeadas por ele. Se a sua API chama outro serviço, passe o ID adiante para que a trilha não se quebre.
Gere um novo ID quando já não estiver a lidar com o mesmo pedido:
- Replays/retries: mantenha o ID original como pai, mas dê a cada tentativa o seu próprio attempt ID (para ver falhas repetidas)
- Jobs em background: crie um novo job ID e guarde o request ID original como o “trigger” (para ligar o job de volta à ação do utilizador)
Um exemplo simples: um utilizador clica em “Pagar” e recebe um erro. O frontend regista requestId=abc123, a API regista o mesmo abc123 com a rota e user ID, e a camada de base de dados regista abc123 junto à query e ao tempo. Quando o pagamento falha, pode puxar abc123 e ver exatamente onde partiu, normalmente em minutos.
Como adicionar request IDs de ponta a ponta (passo a passo)
Um request ID é um valor curto e único que segue uma ação de utilizador pelo seu sistema. Quando o suporte diz “o checkout falhou às 14:14”, o request ID permite puxar cada linha de log relacionada em segundos.
Configuração passo a passo
Use o mesmo padrão básico em qualquer stack:
- Crie (ou aceite) um request ID na borda do servidor. Se o cliente já enviar um (frequentemente
X-Request-Id), mantenha-o. Se não, gere-o assim que o pedido entrar na sua API. - Armazene-o no contexto do pedido para que cada log o inclua. Ponha-o num local que o seu código consiga ler sem ter de passar por cada função. Muitos frameworks têm armazenamento local por pedido. Caso não exista, anexe-o ao objeto request.
- Retorne-o ao cliente na resposta. Adicione um header como
X-Request-Id. Isso dá ao suporte e aos utilizadores algo concreto para copiar. - Encaminhe-o para tudo a jusante. Adicione o mesmo header em chamadas HTTP de saída, inclua-o em payloads de filas/jobs e passe-o para wrappers de base de dados para que queries lentas possam ser ligadas ao mesmo pedido.
- Inclua-o em relatórios de erro (opcional). Ao capturar exceções, anexe
requestIdpara que relatórios de crash e logs coincidam. Para erros visíveis ao utilizador, pode mostrar um curto “código de suporte” derivado do request ID.
Aqui está um exemplo simples ao estilo Node/Express. A ideia é a mesma noutras linguagens:
import crypto from "crypto";
app.use((req, res, next) => {
const incoming = req.header("X-Request-Id");
req.requestId = incoming || crypto.randomUUID();
res.setHeader("X-Request-Id", req.requestId);
next();
});
function log(req, level, message, extra = {}) {
console.log(JSON.stringify({
level,
message,
requestId: req.requestId,
...extra
}));
}
Uma vez isto implementado, os seus registos estruturados tornam-se instantaneamente mais úteis: cada evento pode ser pesquisado por requestId, mesmo que o problema salte entre serviços.
Se herdou uma app gerada por IA onde os logs são cadeias aleatórias (ou estão totalmente em falta), adicionar request IDs é uma das reparações mais rápidas porque melhora a depuração sem alterar a lógica de negócio.
Conceber eventos de log que dêem para pesquisar
Bons logs leem-se como uma linha temporal. Quando algo quebra, deve conseguir responder: o que aconteceu, a que pedido, e que decisão o código tomou.
Com registos estruturados, isso significa que cada linha de log é um pequeno registo com os mesmos campos sempre, não uma frase livre. Consistência é o que faz a pesquisa funcionar.
Comece com um pequeno conjunto de nomes de eventos
Escolha alguns tipos de evento centrais e reutilize-os na app. Evite inventar um nome novo para a mesma coisa toda a semana.
Aqui estão tipos de evento comuns que se mantêm úteis ao longo do tempo:
- request_started
- request_finished
- db_query
- auth_failed
- error
Nomeie eventos em minúsculas com underscores e mantenha o significado estável. Por exemplo, se já tem auth_failed, não adicione login_denied e sign_in_rejected mais tarde, a menos que signifiquem coisas diferentes.
Registe uma decisão, não uma linha de código
Uma regra simples: registe quando o programa toma uma decisão que altera o resultado. Esse é o ponto que vai querer encontrar mais tarde.
Ruim: registar cada linha em volta de uma chamada de base de dados.
Melhor: um único evento db_query que diga o que importou: qual modelo/tabela (não SQL bruto), se teve sucesso e quanto demorou.
Inclua sempre campos de resultado
Facilite filtrar por falhas e caminhos lentos. Adicione alguns campos que aparecem na maioria dos eventos:
- ok: true ou false
- errorType: uma categoria curta como ValidationError, AuthError, Timeout
- durationMs: para qualquer coisa cronometrada (requests, bd, API externa)
- statusCode: para respostas HTTP
Um exemplo realista: se um utilizador reporta “o checkout falha”, deve conseguir pesquisar por event=auth_failed ou ok=false, depois estreitar por statusCode=401 ou errorType=AuthError, e finalmente identificar a parte lenta ordenando por durationMs.
Se está a herdar código gerado por IA, isto frequentemente está em falta ou inconsistente. Na FixMyMess, uma das primeiras reparações é normalizar nomes de eventos e campos para que a depuração em produção deixe de ser adivinhação.
Níveis de log e volume sem ser sufocado pelo ruído
Se cada evento for logado como erro, deixa de confiar nos seus logs. Se tudo for debug, afoga-se na informação. Boa depuração em produção começa com uma promessa simples: os logs por defeito devem explicar o que aconteceu sem inundar o sistema.
Para que serve cada nível
Pense nos níveis de log como um sistema de ordenação por urgência e expectativa. Em registos estruturados, o nível é apenas mais um campo que pode filtrar.
- DEBUG: Detalhes que só quer ao investigar. Exemplo: tempo de resposta de uma API externa, ou o ramo exato que o seu código seguiu.
- INFO: Marcos normais. Exemplo: “utilizador autenticou-se”, “payment intent criado”, “job concluído”.
- WARN: Algo correu mal, mas a app recupera. Exemplo: tentar novamente um pedido, usar um valor fallback, um serviço externo retornar 429.
- ERROR: A operação falhou e precisa de atenção. Exemplo: uma exceção não tratada, uma escrita à base de dados falhada, ou uma resposta 5xx.
Uma regra prática: se isso acordaria alguém à noite se aumentasse muito, provavelmente é ERROR. Se ajuda a explicar uma reclamação de utilizador mais tarde, provavelmente é INFO. Se só é útil enquanto tem um ticket específico aberto, é DEBUG.
Mantenha o volume sob controlo
Endpoints de alto tráfego podem gerar ruído rápido, especialmente em apps geradas por IA onde o logging é adicionado por todo o lado sem plano. Em vez de apagar logs, controle o caudal.
Use táticas simples:
- Amostragem (sampling): Log 1% dos pedidos bem-sucedidos, mas 100% dos WARN e ERROR. Sampling é mais útil em health checks, endpoints poluentes e jobs de background muito verbosos.
- Limites de taxa: Se o mesmo warning se repete, registe-o uma vez por minuto com um contador.
- Um evento por resultado: Prefira um único log "request finished" com duração e status em vez de 10 pequenos logs.
Finalmente, vigie performance. Evite construção pesada de strings ou serialização JSON em caminhos críticos. Registe campos estáveis (como route, status, duration_ms) e compute detalhes caros apenas quando o nível está ativado.
Limites de erro: apanhe crashes e mantenha contexto útil
Um limite de erro (error boundary) é uma rede de segurança na UI. Quando um componente crasha durante o render, um lifecycle ou um construtor, o boundary apanha-o, mostra um ecrã de fallback e (mais importante) regista o que aconteceu. É assim que transforma uma página em branco e uma reclamação vaga em algo que pode reproduzir.
O que apanha: erros síncronos de UI que ocorrem enquanto a app constrói a página. O que não apanha: erros em handlers de eventos, timeouts ou a maioria do código assíncrono. Para esses ainda precisa de try/catch normal e tratamento de promessas rejeitadas.
O que registar quando a UI crasha
Quando o boundary dispara, registe um único evento com contexto suficiente para pesquisar e agrupar falhas semelhantes. Se usa registos estruturados, mantenha as chaves consistentes.
Capture:
route(o caminho atual) e qualquer estado de UI importante (tab, modal aberto, passo de um wizard)component(onde crashou) eerrorName+messageuserAction(o que o utilizador acabou de fazer, como “clicou em Guardar”)requestId(se tiver um vindo do servidor ou do cliente HTTP)buildinfo (versão da app, ambiente) para corresponder a um release
Aqui está uma forma simples:
log.error("ui_crash", {
route,
component,
userAction,
requestId,
errorName: error.name,
message: error.message,
stack: error.stack,
appVersion,
});
O que os utilizadores devem ver vs o que os desenvolvedores precisam
A mensagem para o utilizador deve ser calma e segura: “Algo correu mal. Por favor atualize. Se continuar, contacte o suporte.” Evite mostrar texto de erro cru, stacks ou IDs que possam revelar detalhes internos.
Os desenvolvedores, por outro lado, precisam do contexto completo nos logs. Um bom padrão é mostrar um curto “código de erro” na UI (como um timestamp ou token aleatório) e registar o evento detalhado com esse mesmo token.
No servidor, use redes de segurança equivalentes: um handler global de erros para pedidos, mais handlers para unhandled promise rejections e uncaught exceptions. É aqui que muitas apps geradas por IA falham, e por isso equipas como a FixMyMess frequentemente encontram crashes “silenciosos” sem requestId e sem logs úteis.
Se configurar isto uma vez, um crash em produção deixa de ser um mistério e passa a ser um evento pesquisável que consegue corrigir rápido.
Logar com segurança: evite vazar segredos e dados pessoais
Bons logs ajudam a corrigir bugs rápido. Logs maus criam novos problemas: passwords expostas, chaves de API visíveis e dados pessoais que nunca quis armazenar. Uma regra simples funciona bem: registe o que precisa para depurar o comportamento, não o que o utilizador digitou.
Nunca registe isto (nem “só por agora”): passwords, cookies de sessão, tokens de autenticação (JWTs), chaves de API, códigos OAuth, chaves privadas, números de cartão completos, CVVs, dados bancários e cópias integrais de documentos. Trate também dados pessoais como sensíveis: emails, telemóveis, moradas, IPs (em muitos casos) e campos de texto livre que possam conter qualquer coisa.
Alternativas mais seguras que ainda permitem depurar
Em vez de despejar payloads inteiros, registe pequenos pedaços estáveis de contexto que ajudam a reproduzir o problema.
- Redacte: substitua segredos por "[REDACTED]" (faça isto automaticamente).
- Valores parciais: registe apenas os últimos 4 caracteres de um token ou número de cartão.
- Hash: registe um hash unidirecional de um email para correlacionar eventos sem guardar o email.
- Use IDs: userId, orderId, invoiceId e requestId são geralmente suficientes.
- Resuma: registe contagens e tipos ("3 items", "payment_method=card") em vez do objeto completo.
Exemplo: em vez de registar todo um pedido de checkout, registe orderId, userId, cartItemCount e paymentProviderErrorCode.
Porque o código gerado por IA vaza segredos (e como evitar)
Protótipos gerados por IA frequentemente logam corpos de pedido inteiros, headers ou variáveis de ambiente em “debug mode”. Isso é arriscado em produção e fácil de perder porque “funciona”. Procure armadilhas comuns: console.log(req.headers), print(request.json()), logging de process.env ou registar o objeto de erro completo que inclui headers.
Proteja-se com dois hábitos: sanitizar antes de registar, e bloquear chaves perigosas por defeito. Crie um pequeno wrapper “logger seguro” que redija campos como password, token, authorization, cookie, apiKey e secret onde quer que apareçam.
Finalmente, tenha uma mentalidade de retenção. Guarde logs detalhados apenas tempo suficiente para debugging e análises de segurança. Mantenha resumos por mais tempo, elimine detalhes brutos mais cedo e facilite a purga de logs para um utilizador quando exigido.
Um exemplo realista de depuração em 5 minutos
Um utilizador reporta: “Não consigo entrar. Funciona no meu portátil, mas não em produção.” Não consegue reproduzir localmente, e a única pista é um timestamp e o email.
Com registos estruturados e request IDs em vigor, começa pelo relatório do utilizador e trabalha para trás a partir de um único pedido.
Minuto 1: encontrar o pedido
O seu suporte ou UI mostra um curto “Código de Suporte” (que é apenas o requestId). Se ainda não tem essa UI, pode pesquisar logs pelo identificador do utilizador (email hasheado) à volta da hora reportada e depois recolher o requestId a partir do primeiro evento compatível.
Minutos 2–4: seguir o fluxo e identificar a etapa com falha
Filtre logs por requestId=9f3c... e agora tem uma história limpa: uma tentativa de login de ponta a ponta, através de múltiplos serviços.
{"level":"info","event":"auth.login.start","requestId":"9f3c...","userHash":"u_7b1...","ip":"203.0.113.10"}
{"level":"info","event":"auth.oauth.callback","requestId":"9f3c...","provider":"google","elapsedMs":412}
{"level":"error","event":"db.query.failed","requestId":"9f3c...","queryName":"getUserByProviderId","errorCode":"28P01","message":"password authentication failed"}
{"level":"warn","event":"auth.login.denied","requestId":"9f3c...","reason":"dependency_error","status":503}
A terceira linha é a resposta completa: a base de dados rejeitou a ligação em produção. Como o log tem um nome de event estável e campos como queryName e errorCode, não perde tempo a ler paredes de texto ou a adivinhar a que stack trace pertence este utilizador.
Se também tiver um error boundary no cliente, poderá ver um evento correspondente como ui.error_boundary.caught com o mesmo requestId (passado como header) e a tela onde aconteceu. Isso ajuda a confirmar o impacto visível ao utilizador sem depender de capturas de ecrã.
Minuto 5: transformar logs num teste reproduzível
Agora pode escrever uma reprodução precisa que corresponda à realidade:
- Use o mesmo caminho de login (callback do Google)
- Execute contra a configuração semelhante à produção (fonte correta de user/secret da BD)
- Execute a operação única que falhou (
getUserByProviderId) - Afirme o comportamento esperado (retornar um 503 claro com uma mensagem segura)
Em muitas bases de código “geradas por IA” que vemos na FixMyMess, este problema acontece porque os segredos estão hard-coded localmente, mas são obtidos de forma diferente em produção. O objetivo dos logs não é mais dados, é ter os campos certos para ir de uma reclamação de utilizador a um passo falhado, rápido.
Lista rápida, erros comuns e próximos passos
Quando um problema em produção aparece, quer logs que respondam a três perguntas rápidas: o que aconteceu, a quem, e onde falhou. Esta lista mantém os seus registos estruturados úteis quando estiver sob pressão.
Lista rápida
- Cada pedido recebe um
requestId, e ele aparece em cada linha de log desse pedido. - Cada log de erro inclui
errorTypee uma stack trace (ou o equivalente mais próximo na sua linguagem). - Autenticação e pagamentos (ou qualquer caminho de dinheiro) têm eventos claros de “start” e “finish” para perceber onde o fluxo para.
- Segredos e tokens são redigidos por defeito, e nunca despeja payloads completos de pedido/resposta.
- Os mesmos campos centrais aparecem sempre:
service,route,userId(ouanonId),requestIdedurationMs.
Se não fizer mais nada, certifique-se de poder colar um requestId na pesquisa de logs e ver a história completa desde o primeiro handler até à última chamada à base de dados.
Erros comuns que fazem perder tempo
Mesmo boas equipas caem em algumas armadilhas que tornam os logs difíceis de usar quando importa.
- Nomes de campos inconsistentes (por exemplo
req_id,requestIderequest_idusados em locais diferentes). - Contexto em falta (um erro é logado, mas não dá para saber que rota, utilizador ou passo o causou).
- Logar apenas em erros (precisa de alguns eventos “marco” para ver onde o fluxo para).
- Ruído a nível errado (tudo é
info, por isso avisos reais ficam enterrados). - Vazamentos acidentais de dados (tokens, chaves API, cookies de sessão ou payloads de pagamento completos nos logs).
Próximos passos: escolha os 3 fluxos mais críticos para o utilizador (frequentemente signup/login, checkout e recuperação de password). Adicione request IDs de ponta a ponta e depois adicione 3 a 6 eventos pesquisáveis por fluxo (start, passo principal, finish e uma falha clara). Uma vez esses sólidos, expanda ao resto da app.
Se a sua app gerada por IA é difícil de depurar porque os logs são desorganizados ou ausentes, a FixMyMess pode fazer uma auditoria de código gratuita e ajudar a adicionar request IDs, campos de evento consistentes e tratamento de erros mais seguro para que problemas em produção sejam mais fáceis de reproduzir.