SSRF em apps gerados por IA: encontre endpoints e endureça os fetches
SSRF em apps gerados por IA pode expor serviços internos. Aprenda a encontrar endpoints de fetch arriscados e aplicar allowlists, proteção DNS e endurecimento de requisições.
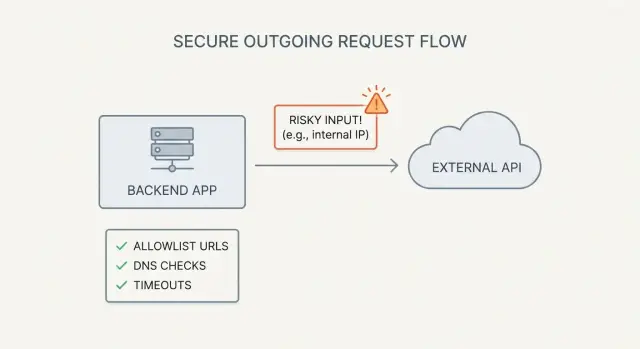
O que é SSRF (e por que apps gerados por IA o provocam)
SSRF (server-side request forgery) acontece quando sua aplicação pode ser enganada a fazer uma requisição de rede para um atacante.
O atacante não precisa ter acesso aos seus servidores. Ele só precisa de qualquer funcionalidade que aceite uma URL (ou hostname) e então faça um fetch no backend.
Um exemplo simples: você adiciona um botão “Importar de URL”. O navegador envia url=https://example.com/data.json para sua API, e seu servidor baixa o arquivo. Se esse mesmo endpoint também aceitar http://localhost:3000/admin ou http://169.254.169.254/ (metadados da nuvem), seu servidor pode acabar expondo dados internos.
Isso aparece constantemente em protótipos gerados por IA. Eles frequentemente incluem endpoints “buscar qualquer coisa” (proxies de imagem, previews de link, testadores de webhook, geradores de PDF/screenshot) porque deixam a demo completa. Mas são lançados sem as proteções necessárias para tornar fetches server-side seguros.
SSRF é perigoso porque servidores normalmente têm acesso que usuários não têm. Um SSRF bem-sucedido pode:
- Acessar painéis administrativos e serviços internos em
localhostou IPs privados - Ler endpoints de metadados da nuvem e roubar credenciais
- Escanear sua rede interna e encontrar portas e serviços abertos
- Contornar regras baseadas em IP (porque a requisição sai do seu servidor)
SSRF não é o mesmo que um navegador fazendo requisições. Se o navegador de um usuário carrega uma URL diretamente, isso é client-side. SSRF é especificamente seu backend (ou uma função serverless) fazendo o fetch, com o acesso de rede e segredos dele.
Onde o SSRF geralmente se esconde: endpoints para procurar
SSRF tende a se esconder em qualquer lugar onde o servidor vá buscar uma URL que o usuário pode influenciar. Esses endpoints parecem inofensivos porque estão “apenas puxando conteúdo”, mas podem ser usados para alcançar serviços internos, metadados da nuvem ou outros alvos privados.
Comece listando recursos do produto que aceitam uma URL, direta ou indiretamente. Lugares comuns incluem previews de link, ferramentas de importar por URL (CSV/JSON/modelos), testadores de webhook, downloads por proxy de arquivos/imagens e leitores de RSS/feed.
Verifique também ferramentas apenas de admin. Apps gerados por IA frequentemente incluem páginas rápidas de “teste de conexão”, checks de saúde que fazem ping nas dependências ou telas de configuração de integração que verificam uma URL. Essas têm alto risco porque podem rodar com acesso de rede elevado e pular validações normais.
Não esqueça fetches retardados. Jobs em background, filas e tarefas cron podem armazenar uma URL agora e buscá-la depois. Essa lacuna pode tornar o bug mais difícil de notar.
Ao buscar no código (e nos logs de requisição), preste atenção a nomes de parâmetro que costumam carregar URLs, mesmo quando soam inofensivos: url, callback, avatarUrl, webhookUrl, redirect.
Um exemplo concreto: uma configuração “foto de perfil de URL” pode buscar a imagem no servidor para redimensionar. Se o endpoint aceita avatarUrl sem checagens rígidas, um atacante pode apontá-lo para um endereço interno e usar o fetch da imagem como um túnel.
Um rápido modelo de ameaça para abuso de fetch server-side
Antes de consertar qualquer coisa, deixe claro o que um atacante está tentando alcançar.
Primeiro, mapeie o que seu servidor consegue alcançar a partir de sua rede. Normalmente inclui serviços localhost (painéis de admin, portas de debug), faixas de IP privadas dentro do seu VPC e endpoints de metadados do provedor de nuvem que podem fornecer credenciais. Se o app roda em um container, inclua nomes de serviços internos e sidecars.
Em seguida, decida o que você precisa proteger. Os maiores alvos são segredos e tokens (chaves de API, segredos de sessão), credenciais de banco de dados, dashboards internos e qualquer serviço que confie em requisições vindas da sua rede interna.
Finalmente, escreva o limite para cada recurso de fetch server-side:
- Quem pode acioná-lo (público, usuário, admin)
- O que é permitido buscar (domínios exatos ou uma pequena lista de parceiros)
- O que nunca deve ser alcançado (localhost, IPs privados, metadados)
- Para que a resposta é usada (arquivo armazenado, dados parseados, HTML renderizado)
Se você herdou um protótipo de ferramentas como Bolt ou Replit, esse modelo de ameaça rápido é um bom primeiro passo antes de uma auditoria mais profunda.
Passo a passo: encontre todo fetch server-side no seu código
SSRF geralmente começa com um recurso simples: “busque esta URL”, “importe de link”, “preview de webhook” ou “verifique se este site está no ar”. Antes de adicionar defesas, você precisa de um inventário completo de todos os lugares onde seu servidor faz requisições de saída.
1) Caçar requisições de saída (incluindo wrappers)
Comece com uma busca em texto no repositório. Procure por clientes HTTP comuns e helpers, não apenas fetch.
- JavaScript/Node:
fetch,axios,got,superagent,node-fetch - Python:
requests,httpx,urllib,aiohttp - Ruby:
Net::HTTP,Faraday - Wrappers shell:
curl,wget,exec(,spawn(
Também pesquise por palavras que costumam cercar esses recursos: “webhook”, “callback”, “import”, “download”, “proxy”, “scrape”.
Se o app foi gerado por ferramentas como Lovable, Bolt, v0, Cursor ou Replit, procure módulos helper que escondem chamadas de rede atrás de nomes como getUrlContent() ou scrapePage().
2) Trace de onde a URL vem
Para cada ponto de chamada, siga a variável para trás até chegar na origem. Fontes comuns incluem campos no corpo da requisição, parâmetros de query, cabeçalhos, linhas no banco de dados, variáveis de ambiente e strings de template que combinam input do usuário com uma base URL.
Preste atenção a controle indireto, como um subdomínio controlado pelo usuário, um baseUrl por tenant ou um ID que mapeia para uma URL no banco.
3) Verifique caminhos de fetch ocultos
Confirme se o cliente segue redirects, resolve short links ou tenta novamente com URLs alternativas. Uma requisição que parece segura pode tornar-se insegura após um 302 para um host interno.
4) Confirme o comportamento e documente
Provque falhas de propósito (domínio inválido, timeout, resposta grande) e veja o que acontece: o que é logado, qual texto de erro é retornado e se algum dado de resposta é refletido ao usuário.
Documente cada endpoint com seus inputs, outputs, requisitos de autenticação e domínios de destino pretendidos. Esse inventário se torna seu plano de correção de SSRF.
Allowlists que funcionam: valide host, esquema e porta
Blocklists falham porque regras de URL são complicadas e atacantes são persistentes. Uma allowlist estrita de destinos conhecidos é o padrão mais seguro, especialmente quando um recurso permite que usuários busquem ou importem conteúdo por URL.
Faça o parse e normalize a URL antes de compará-la a qualquer coisa. Não cheque a string bruta. Parseie em esquema, hostname, porta e path. Compare o hostname normalizado e a porta efetiva (incluindo padrões como 443 para https).
Um fluxo prático de allowlist:
- Parseie a URL com um parser real (não regex)
- Exija o esquema
https(ouhttpapenas se realmente precisar) - Exija um hostname (evite IPs simples a menos que explicitamente permitidos)
- Permita apenas portas aprovadas (normalmente 443, às vezes 80)
- Compare o hostname com suas regras de allowlist
Esquemas e portas são brechas comuns. Se você validar apenas o domínio e esquecer o esquema, um atacante pode tentar handlers inesperados em alguns ambientes. Se permitir qualquer porta, o atacante pode sondar serviços internos em portas estranhas mesmo que o host pareça aceitável.
Subdomínios também precisam de regras claras. Igual exato é o mais simples (somente api.example.com). Se precisar usar curingas, imponha um limite real para que example.com.evil.com não passe.
Trate a allowlist como configuração centralizada, não como código espalhado. Mantenha-a em um só lugar e registre qual regra foi correspondida para facilitar revisões e evitar exceções esquecidas.
Proteções DNS: pare rebinding e truques de IP interno
DNS rebinding é um truque simples com resultado perigoso. Sua app valida uma URL como https://example.com/image.png. Parece inofensiva. Mas o atacante controla example.com e pode mudar o que ela resolve depois da sua checagem. Quando seu servidor conecta, esse hostname pode apontar para 127.0.0.1 ou um IP de metadados da nuvem.
Por isso checagens básicas de hostname não são suficientes.
Um padrão mais seguro é resolver o hostname você mesmo, checar cada IP retornado e só conectar se todos forem seguros.
O que bloquear (IPv4 e IPv6)
Ao resolver o hostname, rejeite qualquer endereço em faixas privadas ou especiais, incluindo redes privadas (RFC1918) e ULA IPv6, loopback (127.0.0.1, ::1), link-local (169.254.0.0/16, fe80::/10), ranges reservados/indefinidos (como 0.0.0.0, ::) e formas IPv4-mapeadas em IPv6.
Cheque todos os registros retornados, não apenas o primeiro. Atacantes costumam usar múltiplos registros A/AAAA onde um parece público (passa na validação) e outro é interno.
Re-cheque perto da conexão
Se seu cliente HTTP permitir, resolva e valide logo antes de abrir o socket, e evite que ocorram novas resoluções de DNS durante redirects. Se não puder controlar isso, mantenha o tempo entre validação e fetch o menor possível.
Endurecimento da requisição: timeouts, redirects e padrões seguros
Mesmo com uma allowlist boa, clientes HTTP server-side costumam ser permissivos por padrão. O objetivo é simples: falhar rápido, buscar menos e nunca seguir redirects para locais que você não pretendia.
Comece definindo limites estritos em todo fetch server-side. Se uma requisição for lenta, grande ou incerta, trate-a como suspeita e pare.
Defaults mais seguros para fetch server-side
Um baseline que funciona bem na prática:
- Defina timeouts apertados (conexão e leitura separados) e limite o tamanho da resposta.
- Desabilite redirects para URLs fornecidas por usuários, ou permita apenas um redirect se o destino final for revalidado.
- Restrinja métodos a GET (e talvez HEAD).
- Remova cabeçalhos sensíveis. Não anexe cookies, chaves de API ou tokens internos a requisições externas.
- Registre um resumo curto (host, path, status, tempo). Evite logar URLs completas se elas puderem conter segredos.
Um padrão de falha comum: um recurso “preview desta URL” permite redirects. Um atacante submete uma URL que faz 302 para um painel interno ou um endereço de metadados da nuvem. Sua app segue e acaba repassando um cabeçalho Authorization reutilizado para chamadas internas.
Erros: mantenha usuários seguros, mantenha engenheiros informados
Quando um fetch é bloqueado ou falha, mostre uma mensagem genérica ao usuário (por exemplo, “Não foi possível buscar essa URL”). Coloque a razão detalhada (timeout vs redirect vs host bloqueado) apenas em logs internos. Erros detalhados na UI muitas vezes ensinam atacantes sobre suas regras.
Erros comuns que ainda deixam SSRF aberto
Bugs de SSRF muitas vezes sobrevivem a correções “básicas”. O resultado parece protegido, mas um atacante ainda consegue fazer seu servidor falar com serviços internos ou endpoints de metadados.
Muitas equipes começam com checagens de string como startsWith('https://'). Isso quebra com URLs estranhas, codificações incomuns ou URLs que parecem seguras mas resolvem para lugares perigosos.
Outras falhas comuns:
- Permitir redirects sem re-checar cada salto
- Validar o host e depois conectar usando um valor diferente mais tarde
- Bloquear apenas
127.0.0.1e esquecer loopback IPv6 (::1),0.0.0.0e ranges privados como10.*,172.16.*,192.168.* - Pular defesas de DNS rebinding (validar uma vez e buscar depois)
Se você retorna conteúdo buscado diretamente para o navegador, pode criar um segundo problema: seu servidor vira um proxy. Sem limites rígidos, atacantes podem baixar arquivos enormes para gerar custos ou enviar tipos de conteúdo inesperados que seu frontend trate mal.
Checklist rápido pré-lançamento para defesas SSRF
Antes do lançamento, parta do pressuposto de que alguém tentará transformar qualquer fetch server-side em um túnel.
Faça o inventário de todo lugar em que um usuário (ou outro sistema) pode influenciar uma URL, host ou referência a arquivo remoto. Inclua campos óbvios como “importar por URL”, além de testadores de webhook, previewers de imagem, geradores de PDF, leitores de feed, recursos “verifique meu site” e integrações que aceitam callback URLs.
Em staging, valide alguns essenciais:
- Cada endpoint e job em background que aceita uma URL/hostname está listado.
- A allowlist é aplicada no servidor para cada fetch (não só na UI).
- Esquema, host e porta são validados antes da requisição.
- Checagens de DNS/IP bloqueiam ranges internos para IPv4 e IPv6, e a checagem acontece próxima à conexão.
- Timeouts, limites de tamanho de resposta e regras de redirect estão em vigor.
Para testes simples de “alvo ruim conhecido”, tente localhost, um IP privado, um hostname interno usado no seu ambiente e o endereço de metadados comum da nuvem. Você não está tentando explorar nada, apenas confirmando que sua app recusa a requisição e não vaza detalhes úteis de erro.
Exemplo: corrigindo um recurso “importar de URL” com segurança
Um padrão comum é um recurso de conveniência como “Importar avatar de URL.” Um gerador adiciona um endpoint backend que recebe uma URL, baixa a imagem no servidor e armazena.
O caminho de exploração é previsível. Um atacante submete uma URL que não é um host de imagens, mas um endereço interno como um serviço de metadados, um painel administrativo privado ou uma porta HTTP de banco de dados exposta apenas na rede interna. Se seu servidor a busca, o atacante pode descobrir segredos, hostnames internos ou até obter HTML se você armazenar ou pré-visualizar a resposta.
Torne o fetch entediante e rígido:
- Allowlist apenas hosts de imagem específicos que você controla ou confia.
- Exija
httpse bloqueie portas não padronizadas. - Resolva o DNS você mesmo e bloqueie IPs privados, loopback e link-local antes de conectar.
- Desabilite redirects, ou permita um único redirect que ainda passe pela validação.
- Defina timeouts apertados e um tamanho máximo de download pequeno, e verifique o content-type e os magic bytes.
Adicione monitoramento para perceber sondagens. Frequentemente aparece como muitas requisições falhas em vários hosts, tentativas repetidas de atingir 169.254.169.254 ou localhost, ou picos em resultados DNS bloqueados e redirects barrados.
Próximos passos: simplifique recursos de fetch e faça uma revisão focada
Se você encontrou mesmo um fetch server-side que pode atingir uma URL fornecida pelo usuário, assuma que há mais. A redução de risco mais rápida é diminuir a superfície de ataque.
Decida quais recursos de fetch você realmente precisa. Muitos apps vêm com extras como “importar por URL”, “preview de link”, “buscar Open Graph”, “testador de webhook”, “proxy de imagem” ou “conectar a qualquer API.” Cada um é um ponto de entrada potencial para SSRF. Se um recurso não é essencial, removê-lo costuma ser mais seguro do que endurecê-lo para sempre.
Depois, defina algumas regras que devem ser verdadeiras para todo fetch server-side:
- Só esquemas, portas e hosts aprovados são permitidos (nada de “qualquer URL”).
- Checagens DNS e IP acontecem no momento da requisição, não apenas uma vez na validação.
- Timeouts, limites de redirect e caps de tamanho de resposta estão sempre ativos.
- Fetching é centralizado em um helper para que novos endpoints não escapem das proteções.
Se quiser uma verificação rápida externa para uma base de código gerada por IA, FixMyMess (fixmymess.ai) faz diagnóstico e endurecimento de segurança para protótipos construídos com ferramentas como Lovable, Bolt, v0, Cursor e Replit. Eles também oferecem uma auditoria de código gratuita para identificar rapidamente riscos de fetch/SSRF e outros problemas de alto impacto antes de você enviar para produção.
Perguntas Frequentes
What is SSRF in plain English?
SSRF é quando seu backend (ou uma função serverless) pode ser enganado para buscar uma URL controlada por um atacante. Como a requisição sai do seu servidor, ela pode alcançar serviços internos, IPs privados ou metadados de nuvem que um usuário normal não consegue acessar.
Why do AI-built apps get SSRF bugs so often?
Protótipos gerados por IA costumam adicionar recursos “convenientes” que fazem fetch de URLs no servidor — previews de links, proxies de imagem, importação por URL, testadores de webhook, geradores de screenshot/PDF. Funcionam bem para demos, mas frequentemente são lançados sem allowlists rígidas, verificações de DNS/IP e controle de redirects.
What endpoints should I check first for SSRF?
Procure qualquer endpoint ou job que aceite algo como url, webhookUrl, callback, avatarUrl, redirect, ou um endereço de “teste de integração”. Não esqueça trabalhadores em background e tarefas cron que gravam uma URL agora e a buscam depois — SSRF pode esconder-se fora do fluxo normal de requisições.
How do I find every server-side fetch in my codebase?
Faça um inventário de todas as requisições de saída que seu servidor pode fazer procurando clientes HTTP (como fetch/axios/requests) e quaisquer helpers internos que os encapsulem. Para cada chamada, trace de onde vem a URL e verifique se a entrada do usuário pode influenciar qualquer parte dela, mesmo indiretamente por campos no banco de dados ou configuração por tenant.
Should I use an allowlist or a blocklist to prevent SSRF?
Padrão: use uma allowlist de domínios exatos que você espera e rejeite o resto. Faça parse e normalize a URL com um parser real, exija https e permita apenas portas seguras (normalmente 443, às vezes 80) para impedir que atacantes usem portas estranhas para sondar serviços internos.
How do I protect against DNS rebinding and “it resolves to localhost” tricks?
Como o DNS pode mudar após você validar o hostname, resolva o nome você mesmo, inspecione todos os IPs retornados e rejeite intervalos privados, loopback, link-local e outras faixas especiais tanto para IPv4 quanto para IPv6. Faça essa checagem o mais próximo possível da conexão real, não apenas uma vez no início.
What are the safest defaults for server-side HTTP requests?
Aperte timeouts, limite o tamanho da resposta e trate redirects como perigosos para URLs fornecidas por usuários. O padrão mais seguro é não seguir redirects; se precisar permitir, revalide o destino após cada salto antes de conectar e nunca reencaminhe cabeçalhos de autenticação internos ou cookies ao host remoto.
What are the most common SSRF “fixes” that still leave me vulnerable?
Checagens simples de string como startsWith('https://') e regras que só bloqueiam localhost deixam buracos: não cobrem loopback IPv6, ranges privados, redirects e alterações de DNS entre validação e conexão. Outro erro comum é validar um valor de host e depois conectar usando um valor diferente derivado depois.
How can I quickly test whether my SSRF defenses actually work?
Tente alvos conhecidos-bons para testes: localhost, intervalos de IP privados e o endereço de metadados comum da nuvem. Confirme que sua app os bloqueia sem vazar razões detalhadas aos usuários. Teste também o comportamento de redirect e garanta que o destino final seja revalidado, não apenas a URL inicial.
Can FixMyMess help harden an AI-generated codebase against SSRF?
Se sua app foi gerada por ferramentas como Lovable, Bolt, v0, Cursor, ou Replit, é comum que falte um caminho de fetch escondido ou um job em background. FixMyMess (fixmymess.ai) pode executar uma auditoria de código gratuita para inventariar fetches server-side e então endurecer o código (allowlists, checagens de DNS/IP, regras de redirect, timeouts) para deixá-lo pronto para produção rapidamente.