Timeouts e tentativas (retries) de API: limites sensatos para chamadas a serviços de terceiros
Timeouts e retries de API evitam que lentidões de serviços terceiros congelem sua aplicação. Defina timeouts sensatos, backoff exponencial, limites de retry e valores padrão seguros.
Por que APIs lentas de terceiros podem congelar sua aplicação
Uma chamada a uma API de terceiros parece pequena até que cada requisição dependa dela. Quando esse provedor desacelera, seu app começa a esperar — e esperar. Os usuários veem spinners infinitos. Jobs em background param de concluir. Nada “cai”, mas tudo parece preso.
A maioria das apps roda com capacidade limitada: um número fixo de threads web, slots de concorrência serverless ou workers de fila. Quando uma requisição fica bloqueada por um provedor lento, ela mantém essa capacidade refém. Poucas chamadas lentas podem virar um acúmulo onde novo trabalho nem sequer começa.
Requisições presas geralmente aparecem com um padrão:
- Requisições web ficam penduradas até o navegador expirar, embora seus servidores pareçam “up”.
- Workers ficam ocupados sem concluir jobs, então a fila continua crescendo.
- Um endpoint começa a consumir a maior parte das suas threads (ou conexões de banco) porque está esperando uma chamada externa.
- Retries disparam sem critério, repetindo a mesma chamada lenta e acelerando o acúmulo.
Timeouts e retries existem para uma coisa: falhar rápido, tentar de forma segura e recuperar com elegância. Um timeout claro impede que um provedor lento congele o sistema inteiro. Retries conservadores ajudam a recuperar de falhas breves sem criar uma indisponibilidade auto-infligida.
Isto surpreende porque defaults de clientes HTTP costumam ser permissivos demais. Alguns estão com timeouts muito altos, e outros esperam efetivamente para sempre a menos que você defina tanto connect quanto read timeout. Muitos protótipos gerados por IA saem com esses defaults, então o sistema faz exatamente o que foi mandado: continuar esperando.
Quando você trata cada chamada a um terceiro como um possível gargalo, pode projetar a app para degradar de forma limpa: mostrar uma mensagem útil, enfileirar a tarefa para depois ou trocar para um fallback em vez de deixar tudo travar.
Termos-chave: timeouts, retries, backoff e limites
Se você quer integrações confiáveis com terceiros, seja claro sobre quatro coisas básicas: quanto tempo você espera, se tenta de novo, como espaça as tentativas e quando desiste.
Timeouts (os diferentes “relógios”)
Um timeout é uma regra rígida: “Se não fizermos progresso em X segundos, pare e devolva o controle ao app.” Tipos comuns incluem:
- Connect timeout: quanto tempo esperar para abrir a conexão (DNS, handshake, caminho de rede). Captura redes mortas rapidamente.
- Read timeout: quanto tempo esperar por dados depois que a conexão está aberta. É aqui que provedores lentos costumam te prejudicar.
- Total/request timeout: tempo máximo para a chamada inteira, do início ao fim. É sua rede de segurança final.
Sem timeouts, um único provedor lento pode amarrar threads do servidor ou workers da fila até que tudo se encha.
Retries (tentar de novo) vs. timeouts (parar)
Um retry é outra tentativa depois de uma falha. Retries não substituem timeouts. Retries sem timeouts podem ser piores que nenhum retry, porque você pode empilhar várias requisições presas em vez de uma só.
Retries ajudam com problemas temporários: timeouts breves, erros 502/503 e falhas de rede. Eles são arriscados para falhas “reais” como credenciais inválidas ou requisições erradas, onde repetir não ajuda.
Backoff e jitter (esperar de forma inteligente)
Backoff significa esperar mais entre cada retry (por exemplo: 1s, depois 2s, depois 4s). Jitter significa adicionar um pequeno atraso aleatório para que muitos clientes não tentem ao mesmo tempo e sobrecarreguem o provedor novamente.
Limites de retry (quando desistir)
Um limite de retry limita tentativas. “Desistir” deve ser um resultado limpo: mostrar uma mensagem como “Esse serviço está lento no momento, tente novamente”, manter o estado do usuário seguro (carrinho, rascunho, dados do formulário) e registrar a falha para acompanhamento em vez de ficar girando para sempre.
Escolhendo valores de timeout sensatos
Timeouts não são um número único para copiar em todo lugar. Escolha por provedor e tipo de chamada, baseado no que é aceitável para os usuários e no que seu sistema pode tolerar quando um provedor está lento.
Um ponto de partida prático é separar “consigo conectar?” de “consigo obter resposta?”. Muitos clientes HTTP permitem configurar ambos.
Faixas típicas iniciais:
- Connect timeout: 0,2 a 1s para a maioria das APIs públicas, até 2s se você espera instabilidades ocasionais.
- Read/response timeout: 2 a 10s para requisições típicas; 15 a 30s somente para endpoints conhecidos por serem longos (relatórios, exports).
- Chamadas de escrita (criar cobrança, criar pedido): mantenha timeouts modestos (frequentemente 5 a 10s) e confie em regras seguras de retry em vez de esperar para sempre.
- Polling/verificações de status: timeouts curtos (2 a 5s) e menos retries.
Requisições que afetam o usuário devem ser mais estritas que jobs em background. Se uma página de checkout está esperando, limite a chamada a terceiros em 3 a 5 segundos e mostre um fallback claro. Se uma sincronização noturna roda em background, ela pode esperar mais, mas ainda precisa de limites para não acumular workers presos.
Também defina um prazo total para toda a operação, incluindo retries. Por exemplo: “Tentar por até 20 segundos no total, então falhar.” Sem isso, retries podem estender silenciosamente uma chamada de 5 segundos para um problema de 2 minutos.
Anote suas suposições para que a próxima pessoa não tenha que adivinhar:
- Latência típica que você observa do provedor (p50 e p95)
- Tolerância do UX (quanto tempo um usuário espera antes de abandonar)
- Tempo máximo total que você gastará incluindo retries
- Quais endpoints podem ser mais lentos, e por quê
Quando tentar novamente (e quando não tentar)
Retries são para problemas que provavelmente se resolvem sozinhos em um instante. Se a requisição está errada, retry só desperdiça tempo e pode piorar a indisponibilidade.
Retries geralmente fazem sentido para falhas transitórias: conexão caída, DNS instável ou timeout. Elas também fazem sentido para rate limiting (HTTP 429) e alguns erros de servidor (5xx), porque o provedor pode estar sobrecarregado.
Uma regra prática:
- Repetir em erros de rede, timeouts, 429 e 5xx selecionados (ex.: 502/503/504).
- Não repetir a maioria dos 4xx (400, 401/403, 404) até que algo mude.
- Respeitar
Retry-Afterquando a API o enviar. - Parar cedo se receber uma mensagem de erro claramente permanente.
Tenha cuidado com requisições de “resultado desconhecido”. Se der timeout depois de enviar uma cobrança, retry pode criar duplicatas a menos que você use chaves de idempotência ou um token de pedido.
Uma abordagem prática separa dois padrões:
- Um retry rápido para falhas minúsculas (uma tentativa rápida após ~100–200 ms).
- Uma sequência de backoff curta para throttling ou outages parciais (algumas tentativas com atrasos crescentes).
Isso mantém o app responsivo enquanto ainda recupera quando o provedor precisa de um tempo.
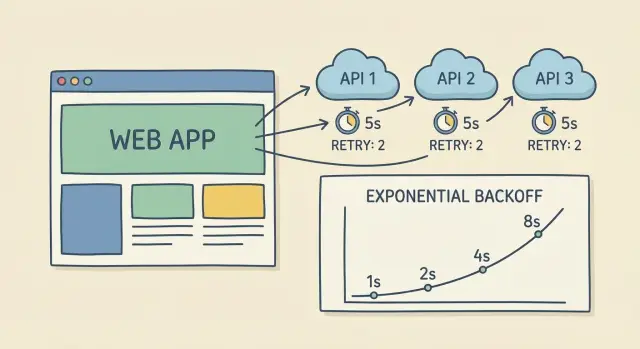
Backoff exponencial com jitter, explicado de forma simples
Quando uma chamada falha ou dá timeout, retry imediato costuma piorar as coisas. Backoff exponencial significa esperar um pouco, depois um pouco mais a cada tentativa. Isso reduz pressão sobre o provedor e dá tempo para o serviço se recuperar.
Uma progressão simples (com um limite para não arrastar demais):
- Tentativa 1: esperar 0,25s
- Tentativa 2: esperar 0,5s
- Tentativa 3: esperar 1s
- Tentativa 4: esperar 2s (cap aqui)
Jitter adiciona um pequeno deslocamento aleatório. Sem ele, milhares de clientes podem retryar nos mesmos instantes (exatamente 1s depois), criando outro pico e mais falhas. Com jitter, um cliente pode esperar 0,8s e outro 1,3s, espalhando as tentativas.
Duas salvaguardas importam mais:
- Limitar o atraso máximo (frequentemente 2 a 5 segundos).
- Manter as tentativas pequenas e previsíveis, geralmente 2 a 4 retries.
Isso torna o pior caso fácil de raciocinar e evita filas escondidas de trabalho preso.
Torne retries seguros: idempotência e prevenção de duplicatas
Retries podem salvar você durante falhas de rede, mas também podem criar uma bagunça. Se você retryar uma ação não idempotente (como “cobrar cartão” ou “criar pedido”), o mesmo clique pode rodar duas vezes. É assim que surgem cobranças em dobro, contas duplicadas ou dois envios.
Uma regra simples: só retryar chamadas que são seguras de repetir. Leitura (GET) normalmente é segura. Escritas (POST que cria ou cobra) precisam de proteção antes de ativar retries.
Use chaves de idempotência quando o provedor suportar
Muitas APIs de pagamento, mensagens e pedidos permitem enviar uma chave de idempotência. Gere uma chave única para a ação do usuário (por exemplo, uma tentativa de checkout) e reutilize-a em cada retry. O provedor então retorna o mesmo resultado em vez de executar a ação novamente.
Armazene essa chave com a resposta e mantenha-a estável mesmo se o usuário atualizar a página.
Adicione sua própria dedupe quando o provedor não oferecer
Se não há suporte a idempotência, você ainda pode evitar duplicatas no seu lado. Mantenha simples:
- Crie um “registro de requisição” com um
request_idúnico antes de chamar o provedor. - Aplique uma restrição única (por exemplo:
user_id + cart_id + action_type). - Armazene a resposta do provedor (sucesso ou falha) e reutilize-a em retries.
- Adicione uma janela TTL curta para não bloquear compras legítimas futuras.
- Registre um ID de requisição estável para que o suporte consiga rastrear o que aconteceu fim a fim.
Exemplo: durante o checkout, a primeira tentativa de cobrança dá timeout, mas o provedor a processa depois. Se você retryar sem idempotência ou dedupe, pode cobrar duas vezes. Com um request_id estável, você consegue retryar com segurança e ainda mostrar um único resultado final.
Pare falhas descontroladas: limites, circuit breakers e fallbacks
Retries ajudam quando um provedor tem um pequeno problema. Se o provedor está fora do ar ou muito lento, retries podem transformar um problema pequeno em uma enxurrada de requisições presas. O objetivo não é “nunca falhar”. É “falhar de forma controlada” para que sua app continue utilizável.
Coloque limites rígidos em cada chamada
Toda chamada externa precisa de limites que terminem o sofrimento rapidamente. Mantenha a lista de limites curta e aplique-os consistentemente:
- Máximo de tentativas (por exemplo, 3 tentativas no total)
- Tempo máximo decorrido (por exemplo, parar após 10 segundos no total)
- Máximo de chamadas concorrentes (evite 500 requisições empilhadas de uma vez)
- Uma definição estrita do que é retryável (apenas erros que você espera recuperar)
Esses limites impedem que um provedor lento congele seu servidor web, entupa filas ou queime seus limites de taxa.
Use um circuit breaker quando um provedor estiver falhando
Um circuit breaker é uma regra simples: se muitas chamadas falham em uma janela curta, pause chamadas por um tempo. Durante a pausa, retorne uma resposta controlada imediatamente em vez de esperar timeouts. Após um período de arrefecimento, permita um pequeno número de chamadas de teste para ver se o provedor se recuperou.
Isso ajuda a isolar uma indisponibilidade do provedor do núcleo do seu app. Usuários ainda podem fazer login, navegar e salvar progresso mesmo se uma integração estiver saudável.
Adicione fallbacks que mantêm os usuários em movimento
Fallbacks podem ser tão simples quanto dados em cache, uma mensagem “tente novamente em um minuto” ou um modo degradado que pula uma funcionalidade não crítica.
Exemplo: se as tarifas de envio derem timeout durante o checkout, mostre uma tarifa padrão ou permita que o usuário finalize o pedido e confirme o envio depois.
Passo a passo: adicionar timeouts e retries a um app existente
Comece tornando o comportamento consistente. Se cada engenheiro define timeouts diferente (ou esquece deles), um provedor lento ainda pode amarrar toda a app.
1) Centralize seus defaults HTTP
Crie um cliente HTTP compartilhado (ou um wrapper) e force todas as chamadas externas a passarem por ele. Dê defaults seguros: um connect timeout, um response timeout e um limite rígido no tempo total gasto (incluindo retries). Registre cada requisição com o nome do provedor para identificar padrões.
Depois adicione uma camada de políticas por provedor. Pagamentos, email, mapas e modelos de IA se comportam diferente, então as mesmas regras de retry raramente servem para todos.
2) Adicione overrides por provedor que reflitam a realidade
Para cada provedor, defina:
- Timeouts (curtos para endpoints rápidos, mais longos só onde necessário)
- Regras de retry (quais códigos e erros de rede qualificam)
- Limites de retry (máx. de tentativas e tempo total)
- Tratamento de rate-limit (respeite 429 e
Retry-Aftercom número limitado de retries)
Mantenha retries conservadores. Um provedor quebrado deve falhar rápido e liberar sua app para continuar funcionando.
3) Meça o que os usuários sentem
Monitore algumas métricas e revise regularmente: taxa de timeout, retries por requisição, sucesso após retry e latência total (incluindo esperas). Se retries “funcionam” mas adicionam 8 segundos ao checkout, os usuários ainda percebem isso.
4) Comprove com lentidão forçada
Teste em staging simulando respostas lentas e conexões falhas. Faça uma chamada de provedor “sleep” por 10 segundos e confirme que seu app dá timeout em 2 segundos, retrya com backoff e para no limite. Teste também outages parciais onde toda terceira requisição falha.
Erros comuns que causam requisições presas
Requisições presas geralmente vêm de um problema raiz: não há um limite claro de quanto tempo a app vai continuar tentando. Quando um provedor fica lento, workers ficam esperando e o backlog cresce até que tudo pareça congelado.
Padrões que criam acúmulos silenciosos:
- Contagem de retries tão alta que é efetivamente infinita.
- Retries imediatos sem pausa, especialmente sob carga.
- Sem prazo total, então o usuário espera mais enquanto seus servidores permanecem ocupados.
- Retry de erros permanentes (chave API inválida, permissões faltando, payload inválido) em vez de corrigir a requisição.
- Ignorar limites de taxa (429), o que frequentemente leva a throttling mais severo.
Um modelo mental útil: retries são para problemas temporários, não permanentes. Quando um provedor está fora ou lento, você quer menos tentativas mais inteligentes, não mais.
O que “seguro” costuma parecer: 2 a 3 tentativas extras, backoff exponencial com jitter e um limite rígido para toda a operação (por exemplo, “pare após 10 segundos no total, não importa o que aconteça”). Para respostas 429, trate o tempo de espera do provedor como parte do contrato.
Um exemplo realista: um provedor fica lento durante o checkout
Imagine um fluxo de checkout com três chamadas a terceiros: uma API de pagamentos para cobrar o cartão, uma API de envio para buscar tarifas ao vivo e um provedor de email para enviar o recibo.
Numa tarde, o provedor de envio fica lento. Seu app pede tarifas, mas a requisição fica pendurada por 25–30 segundos. O cliente fica olhando para o spinner. Se seu servidor mantiver essa requisição aberta, você prende threads e enfileira mais checkouts atrás dela. Um provedor lento pode fazer o site inteiro parecer fora do ar.
Um fluxo mais seguro:
- Pagamentos: timeout curto; não retry automaticamente após uma tentativa de cobrança a menos que você possa provar que é seguro.
- Tarifas de envio: timeout rápido (ex.: 2–3s), retry um pequeno número de vezes com backoff e então pare.
- Fallback: se o envio ainda estiver lento, mostre uma tarifa padrão ou permita que o usuário conclua e confirme o envio depois.
- Mensagem ao usuário: “Não foi possível carregar tarifas ao vivo. Você ainda pode fazer o pedido; confirmaremos o envio por email.”
Onde os retries acontecem importa. Na página de checkout, mantenha timeouts apertados para que o cliente tenha uma resposta rápida. Depois que o pedido é criado, você pode fazer retries mais longos em background (ainda com limites rígidos) para obter a tarifa final e atualizar o pedido sem manter o usuário refém.
Checklist rápido antes de enviar para produção
Antes de liberar, revise cada chamada a terceiros (pagamentos, email, mapas, auth, envio, provedores de IA). O objetivo é simples: um provedor lento não deve congelar sua app, e uma indisponibilidade breve não deve gerar uma pilha de requisições presas.
Assegure que toda chamada tem:
- Connect timeout curto
- Read/response timeout razoável
- Um prazo total para a operação inteira (incluindo retries)
Para retries:
- Retry apenas falhas transitórias (timeouts, erros de rede temporários, 429/5xx claros)
- Use backoff exponencial com jitter
- Aplique máx. de tentativas e tempo máximo decorrido em todos os lugares (cliente HTTP, fila de jobs, workers de background)
Por fim, torne retries seguros. Se uma operação pode criar duplicatas (cobranças, pedidos, criação de conta), adicione chaves de idempotência ou dedupe antes de ativar retries.
O monitoramento deve mostrar por provedor: taxa de timeout, taxa de retry e latência média. Assim você pega problemas cedo, antes que se tornem um congelamento visível ao usuário.
Próximos passos: estabilize suas integrações sem sobrecomplicar
Comece encontrando as chamadas que podem esperar para sempre. Procure requisições sem timeout explícito, jobs de background que retryam “até sucesso” e workers que nunca desistem. Esses são os que silenciosamente se acumulam e transformam um pequeno atraso de provedor em uma indisponibilidade.
Escolha um ou dois APIs de terceiros críticos e finalize o padrão end-to-end antes de tocar no resto. Crítico normalmente significa fluxo de dinheiro, login, mensagens ou qualquer coisa que bloqueie uma ação do usuário. Implemente um timeout claro, uma política de retry com backoff e um limite rígido de retries. Adicione logs básicos para responder: com que frequência tentamos de novo, quanto tempo esperamos e se eventualmente conseguimos sucesso?
Quando algo dá errado, velocidade importa mais que ferramentas perfeitas. Escreva um pequeno playbook de incidente: como desabilitar temporariamente um provedor (feature flag ou toggle de config), o que mostrar aos usuários, o que checar primeiro (status do provedor, taxas de erro, profundidade das filas) e quando reativar.
Se você herdou uma base de código gerada por IA com defaults inseguros, FixMyMess (fixmymess.ai) pode rodar uma auditoria de código gratuita para apontar timeouts faltando, retries descontrolados e integrações frágil, e depois ajudar a transformar o protótipo em software pronto para produção com correções verificadas por humanos.
Perguntas Frequentes
Por que uma única API lenta de terceiros pode fazer meu app parecer congelado?
Sua aplicação tem uma capacidade limitada (threads web, slots serverless ou workers). Se uma requisição estiver esperando por uma API lenta sem um timeout rígido, ela mantém essa capacidade ocupada e o trabalho novo não consegue começar — tudo parece travado mesmo sem haver um “crash”.
Quais timeouts devo definir para a maioria das chamadas a APIs de terceiros?
Defina um connect timeout curto, um read/response timeout separado e um prazo total para a requisição. Um ponto de partida comum é 0,2–1s para conectar e 2–10s para obter resposta, ajustando por provedor conforme a tolerância dos usuários.
Qual é a diferença entre timeout e retry?
Um timeout para de esperar e devolve o controle ao app. Um retry é uma nova tentativa após uma falha. Normalmente você precisa dos dois: timeouts para evitar trabalhos presos e um pequeno número de retries para se recuperar de falhas momentâneas.
Quais erros devo tentar novamente e quais devo evitar?
Retry apenas erros que provavelmente são temporários, como timeouts, instabilidades de rede, 429 (rate limit) e certos 5xx. Não repita a maioria dos 4xx (requisição inválida, credenciais ruins), porque repetir não resolve o erro.
Como faço backoff e jitter sem piorar a situação?
Use backoff exponencial para aumentar o tempo entre tentativas e adicione jitter para que muitos clientes não reenviem exatamente no mesmo instante. Mantenha o esquema pequeno e previsível (ex.: 2–4 retries com atraso limitado) para não criar esperas longas ou filas ocultas.
Por que retries podem causar cobranças duplas ou pedidos duplicados?
Retries podem repetir uma escrita quando a primeira tentativa foi processada pelo provedor mas sua aplicação não recebeu a resposta, levando a cobranças ou pedidos duplicados. Use chaves de idempotência ou deduplicação para evitar isso.
Os timeouts devem ser diferentes para requisições web e jobs em background?
Para requisições voltadas ao usuário, como checkout, mantenha timeouts mais apertados e mostre um fallback claro se o provedor estiver lento. Para jobs em background, você pode aguardar mais tempo, mas ainda precisa de limites rígidos para não deixar workers presos e encher a fila.
Quando devo adicionar um circuit breaker?
Use um circuit breaker quando um provedor apresentar muitas falhas em curto período. O circuito pausa chamadas por um tempo curto e retorna respostas controladas imediatamente, permitindo que o resto do app continue funcionando.
Por que protótipos gerados por IA costumam vir com defaults HTTP inseguros?
Muitos clients HTTP têm padrões permissivos que esperam muito tempo por respostas. Protótipos gerados por IA frequentemente mantêm esses padrões, então a aplicação acaba esperando indefinidamente, exatamente como configurada.
Qual é a forma mais rápida de adicionar timeouts e retries sensatos a um app existente?
Centralize as chamadas HTTP em um cliente compartilhado com defaults seguros e regras por provedor. Se você herdou um código gerado por IA e não sabe onde faltam timeouts ou retries, FixMyMess (fixmymess.ai) pode rodar uma auditoria gratuita e corrigir o comportamento de integração rapidamente com mudanças verificadas por humanos.