Transações de banco de dados para escritas atômicas: pare dados parcialmente salvos
Aprenda como transações de banco de dados para escritas atômicas evitam registros parcialmente salvos, com passos simples, tratamento de rollback e checagens rápidas para apps mais seguros.
O que são registros “parcialmente salvos” e por que acontecem
Um registro “parcialmente salvo” aparece quando uma ação do usuário exige várias alterações no banco de dados, mas apenas algumas delas têm sucesso. O usuário pensa que concluiu a tarefa, mas o banco de dados agora guarda uma versão só parcialmente completa.
Exemplo: um checkout deveria (1) criar um pedido, (2) reservar estoque e (3) registrar uma tentativa de pagamento. Se a linha do pedido é criada, mas a atualização do estoque falha, você fica com um pedido que não pode ser enviado. Se o estoque é reservado mas a linha de pagamento está faltando, o suporte vê estoque sumir sem receita correspondente.
Esse tipo de inconsistência gera bugs que parecem aleatórios:
- linhas ausentes (um pedido existe, mas sem itens do pedido)
- totais divergentes (o total da fatura não bate com os itens)
- registros órfãos (um pagamento referencia um pedido que nunca foi criado)
- registros duplicados (um retry cria um segundo pedido)
- estados “travados” (status diz “pago” mas nada mais confirma)
Usuários experimentam isso como confusão de alto impacto: um cadastro que mostra “Bem-vindo” mas não permite login depois, um e-mail de confirmação de pedido com pedido vazio, ou um pagamento que parece ter dado certo mas nenhuma assinatura aparece.
Dados parcialmente salvos geralmente acontecem quando o código executa múltiplos inserts e updates separadamente, sem tratá-los como uma única unidade. Uma instabilidade de rede, uma queda de servidor, um erro de validação ou um timeout no meio já são suficientes para deixar etapas iniciais commitadas e etapas posteriores puladas.
Isso é especialmente comum em protótipos gerados por IA porque eles focam no caminho feliz. Casos de borda como falhas parciais, retries e limpeza frequentemente faltam, então ações que deveriam ser atômicas viram uma cadeia de queries independentes sem um plano de rollback claro.
Quando você deve usar uma transação (e quando não deve)
Use uma transação quando uma ação do usuário cria ou altera dados em mais de um lugar, e ficar “meio pronto” é inaceitável. O objetivo é simples: ou todas as alterações relacionadas são salvas, ou nenhuma delas é.
Transações são adequadas quando os registros dependem uns dos outros, como criar um cabeçalho de pedido e seus itens. Se o pedido salva mas os itens não, sua aplicação tem um registro que parece real, mas não pode ser atendido.
Também são a ferramenta certa quando mudanças devem falhar em conjunto porque há dinheiro ou limites envolvidos: contagens de estoque, saldos de conta, créditos e uso de cota. Se uma atualização acontece sem a outra, você pode vender em excesso, cobrar em duplicidade ou permitir que usuários extrapolem limites.
Uma regra prática: se você está mexendo em várias tabelas como parte de um único resultado, comece assumindo que precisa de uma transação.
Se um fluxo cruza serviços (escrita no banco + envio de e-mail ou cobrança), mantenha efeitos colaterais externos fora da transação. Salve o estado primeiro, commite, e então dispare o e-mail ou a cobrança de forma que possa ser re-tentada com segurança.
Sinais de que você provavelmente precisa de transações (ou de transações mais rígidas) incluem scripts de limpeza recorrentes após falhas, tickets de suporte como “vejo em uma tela mas não em outra”, dashboards que discordam porque linhas estão faltando, e código onde saves estão espalhados por helpers.
Quando não usar uma transação: para trabalho longo e lento (processamento de arquivos, jobs em lote grandes, esperar por APIs de terceiros). Manter uma transação aberta por muito tempo pode bloquear outros usuários e aumentar a chance de timeouts.
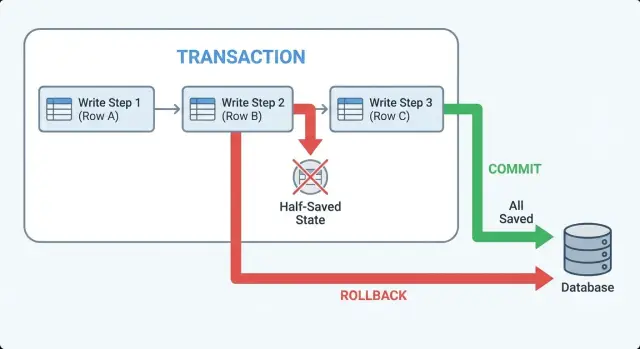
Transações em termos simples: commit, rollback, atomic
Uma transação é um invólucro de segurança em torno de um conjunto de escritas no banco. Ela transforma “salvar essas 3 coisas” em uma ação tudo-ou-nada.
“Atômico” significa que ou toda alteração do grupo é salva, ou nenhuma é. Não existe um estado intermediário onde algumas linhas existem e outras não.
Pense num checkout onde você (1) cria um pedido, (2) reserva estoque e (3) registra uma tentativa de pagamento. Sem uma transação, uma queda entre passos pode deixar você com um pedido que parece real mas sem itens reservados, ou itens reservados sem pedido. Com uma transação, o banco trata esses passos como uma única unidade.
These are the terms you’ll see in code and logs:
- Begin: start the transaction. Changes are temporary until the end.
- Commit: make it permanent. All changes land at once.
- Rollback: undo it. The database discards everything since the begin.
Commit e rollback são os dois finais limpos. Se sua app pode sair cedo (erro, timeout, falha de validação), você quer que o código deixe óbvio qual final aconteceu.
Uma frase sobre isolamento
Isolamento significa que sua transação é protegida de surpresas causadas por outras pessoas escrevendo ao mesmo tempo, então você não lê ou escreve com base em dados que mudam por baixo de você.
Se lembrar de uma regra: agrupe inserts e updates relacionados que devem dar certo juntos, e não permita efeitos colaterais (e-mails, webhooks, jobs) até depois do commit.
Passo a passo: envolver uma escrita multi-etapa em uma transação
Dados parcialmente salvos acontecem quando uma etapa inicial tem sucesso (como criar uma linha) e uma etapa posterior falha (como atualizar um saldo). A correção é tratar todo o conjunto de mudanças como uma única unidade de trabalho.
Comece escolhendo o limite: tudo que deve ser verdadeiro junto vai dentro da transação. Por exemplo, “criar pedido + reservar estoque + registrar intent de pagamento” deve ou acontecer tudo, ou nada.
Um fluxo confiável se parece com isto:
- Inicie uma transação antes do primeiro insert/update na unidade de trabalho.
- Execute as instruções em uma ordem segura (linha pai primeiro, depois filhos, depois atualizações derivadas).
- Após cada instrução crítica, verifique se obteve o esperado (contagem de linhas, id retornado, constraints).
- Se qualquer etapa falhar, pare imediatamente e faça rollback.
- Faça commit somente quando cada passo tiver sucedido, então retorne uma resposta de sucesso clara.
Aqui está o formato em pseudocódigo:
BEGIN;
-- 1) Create parent
INSERT INTO orders(...) VALUES(...) RETURNING id;
-- 2) Create children
INSERT INTO order_items(order_id, ...) VALUES (...);
-- 3) Update derived state
UPDATE inventory SET reserved = reserved + 1 WHERE sku = ? AND available \u003e 0;
COMMIT;
Dois detalhes fazem ou quebram esse padrão.
Primeiro, não engula erros. Se o passo 3 atualizar 0 linhas, trate isso como falha, lance um erro e faça rollback.
Segundo, não envie uma resposta de sucesso antes do commit completar. “OK” antes do commit é como trabalho parcial vaza como “sucesso”.
Se você herdou código gerado por IA, fique atento a transações falsas onde cada query abre sua própria conexão. O código pode parecer transacional enquanto as queries rodam em sessões diferentes.
Tratando falhas: caminhos explícitos de rollback e erros claros
Dados parcialmente salvos frequentemente vêm de tratar erros como “problema de outra pessoa”. Decida desde o início o que conta como falha e torne todos os caminhos de falha óbvios no código.
Faça rollback por mais que crashes. Faça rollback em exceções (timeouts, erros de constraint, deadlocks), checagens falhas (uma atualização afeta 0 linhas quando deve afetar 1), validação dependente do estado atual (“usuário já tem uma assinatura ativa”), ou escritas dependentes que retornam valores inesperados.
Então torne o rollback explícito. Evite padrões como “catch e ignorar” ou retornar false sem limpeza. Uma estrutura simples mantém você honesto:
begin transaction
try:
write A
write B
verify row counts
commit
return success
except error:
rollback
log safe context
return clear failure
finally:
close connection
Erros claros importam. O chamador deve saber o que fazer a seguir (“por favor tente novamente” vs “entrada inválida”), mas a mensagem não deve vazar segredos como texto SQL, tokens ou variáveis de ambiente. Uma abordagem prática é uma razão curta mais um id de erro interno que você pode encontrar nos logs.
Nunca deixe uma transação aberta. Transações abertas podem travar linhas, bloquear outros usuários e fazer requisições posteriores falharem de forma estranha. Sempre commit ou rollback, e sempre feche a conexão (ou a devolva ao pool) em um bloco finally.
Logue o suficiente para reproduzir o problema sem despejar dados privados: nome da operação (signup, checkout), ids relevantes, contagens de linhas e o tipo de erro. Uma falha comum em código gerado por IA é capturar erros, retornar “sucesso” e deixar o banco dividido entre duas versões da realidade.
Retries e idempotência: manter-se seguro sob timeouts
Timeouts criam uma situação delicada: o cliente desiste, mas o servidor pode ainda terminar o trabalho e commitar. Se o cliente re-tentar, você pode criar o mesmo pedido duas vezes, conceder acesso em duplicidade ou cobrar em duplicidade.
Transações mantêm cada tentativa tudo-ou-nada, mas não impedem a mesma tentativa de ocorrer de novo. É aí que entra idempotência.
Idempotência significa que a mesma requisição, repetida, produz o mesmo resultado. Um padrão comum é exigir uma chave de idempotência (um ID aleatório do cliente) e armazená-la com o resultado final. No retry, você busca essa chave e retorna o resultado original em vez de rodar todo o fluxo de novo.
Maneiras práticas de tornar retries seguros:
- Adicione constraints únicos que reflitam regras de negócio reais (um perfil por usuário, uma assinatura por usuário por workspace).
- Armazene a chave de idempotência com um índice único e salve o ID do registro criado junto com ela.
- Use upsert quando isso fizer sentido para a regra de negócio (criar se faltar, caso contrário reutilizar a linha existente).
- Trate “violação de constraint única” como um resultado normal de retry: busque a linha existente e retorne-a.
- Mantenha efeitos colaterais externos (pagamentos, e-mails) idempotentes também.
Exemplo: uma requisição de checkout dá timeout logo após o commit do banco, mas antes da resposta chegar ao navegador. O retry chega. Com uma constraint única em (user_id, cart_id) e uma chave de idempotência armazenada com o payment_intent_id, a segunda requisição retorna o mesmo pedido e não cria uma segunda cobrança.
Dicas de design: mantenha transações pequenas e efeitos separados
Transações funcionam melhor quando cobrem uma ação de negócio clara. Coloque as regras de negócio chave no limite: valide o que deve ser verdade, escreva as linhas relacionadas e então commite.
Transações longas fazem mal porque mantêm locks abertos. Outras requisições se acumulam atrás delas e timeouts tornam-se mais prováveis. Faça o mínimo trabalho necessário para deixar o banco consistente e saia rápido.
Mantenha a transação focada
Um erro comum é tratar uma transação como um “try/catch” geral para qualquer coisa que possa falhar. Mantenha trabalho não relacionado fora dela.
Regras práticas:
- Coloque apenas reads e writes que devem ter sucesso juntos dentro da transação.
- Evite chamar serviços externos enquanto a transação estiver aberta.
- Evite queries lentas ou atualizações em lote grandes na mesma transação que escritas visíveis ao usuário.
- Mantenha o caminho de código fácil de raciocinar (um ponto de entrada, um commit).
Separe efeitos colaterais das mudanças de dados
Efeitos colaterais como enviar e-mails, cobrar cartões, criar arquivos ou enviar imagens não são trabalho do banco. Se você os fizer dentro da transação, corre o risco de enviar uma confirmação e depois dar rollback nos dados.
Um padrão mais seguro é: escreva os dados, commit, então dispare os efeitos colaterais.
Se você precisa de alta confiabilidade, escreva um registro de “outbox” como parte da mesma transação (por exemplo, “enviar e-mail de boas-vindas para o usuário 123”). Após o commit, um worker lê o outbox e executa o efeito colateral. Se falhar, você re-tenta sem corromper seus registros principais.
Erros comuns que ainda causam dados parcialmente salvos
Muitos bugs de dados parcialmente salvos não são causados por falta de transações. Acontecem quando uma transação é usada de forma que quebra silenciosamente a garantia tudo-ou-nada.
Um erro clássico é salvar o registro “principal”, commitar, e só então criar linhas relacionadas necessárias (log de auditoria, profile, entrada em tabela de join). Se o segundo passo falhar, você fica com um registro que parece válido em uma tabela mas está faltando companheiros obrigatórios.
Outro problema comum é tratamento de erro que pula a limpeza. Uma transação pode ser aberta corretamente, mas um ramo retorna cedo (ou lança dentro de um callback) sem um rollback. Dependendo da stack, isso pode deixar a conexão em estado ruim ou levar a commits inesperados.
Padrões de falha que aparecem com frequência em código gerado por IA:
- Capturar um erro, logá-lo e ainda assim retornar “sucesso”.
- Fazer uma chamada a API de terceiro (e-mail, pagamentos, upload) enquanto a transação está aberta, fazendo uma rede lenta manter locks.
- Misturar clientes de banco, de modo que uma escrita roda em uma conexão diferente e não faz parte da mesma transação.
- Repetir a requisição sem idempotência, criando duplicatas após um timeout.
Exemplo: um fluxo de signup insere em users, depois user_profiles, depois org_members. Se o insert no profile falhar mas o insert em users já commitou, a próxima tentativa de signup pode falhar em “email já existe” e o usuário fica preso em limbo.
Duas regras práticas previnem muito disso: mantenha a transação limitada ao trabalho do banco, e torne cada caminho de saída explícito. Se precisar de uma chamada externa, commite primeiro e então faça a chamada; se ela falhar, registre um status “precisa de retry”.
Verificações rápidas antes de liberar
Antes de liberar uma feature que faz inserções e atualizações multi-etapa, escreva a “unidade de trabalho” em uma frase. Exemplo: “Criar um pedido, reservar estoque e registrar um intent de pagamento.” Se você não consegue dizer isso claramente, seus limites de transação provavelmente estão confusos.
Um teste rápido de sanidade é seguir a conexão. Cada query que deve ter sucesso ou falhar junto precisa rodar na mesma sessão/conexão do banco. Esse é um modo frequente de falha em código gerado por IA: um helper usa uma conexão do pool enquanto outro abre uma nova, então a transação cobre apenas parte do trabalho.
Uma checklist curta antes do envio:
- Defina a unidade de trabalho em uma frase e envolva apenas isso em uma única transação.
- Verifique que cada escrita relacionada usa o mesmo objeto de conexão/sessão do begin ao commit.
- Faça os caminhos de falha enfadonhos: em qualquer erro, rollback uma vez, retorne um erro claro e pare.
- Adicione constraints que tornam retries seguros (chaves únicas para registros “um por usuário”, chaves de idempotência para requisições).
- Mantenha efeitos colaterais fora da transação: envie e-mails, webhooks e uploads somente após o commit (ou enfileire-os).
Depois, faça uma execução “quebre isso”: force um erro no passo 2 de 3 (por exemplo, viole uma constraint na terceira tabela). Após a requisição falhar, verifique o banco. Você deveria ver zero novas linhas, não “algumas linhas com peças faltando”.
Exemplo: fluxo de cadastro que escreve em 3 tabelas
Imagine um cadastro que precisa escrever três linhas:
users(email, hash de senha)profiles(user_id, display_name)subscriptions(user_id, plan)
Se você rodar esses como três escritas separadas, pode obter dados parcialmente salvos. Por exemplo, a linha users é criada, mas criar profiles falha porque display_name é muito longo ou um campo obrigatório está faltando. Agora você tem uma conta real que não pode finalizar onboarding, e tentativas futuras podem falhar porque o email já está tomado.
Como fica sem transação
Um padrão comum gerado por IA é: inserir usuário, depois inserir profile, depois inserir subscription, cada um com sua própria chamada. Quando o passo 2 falha, o passo 1 já commitou. Agora você precisa de código de limpeza (deletar o usuário) e precisa decidir o que acontece se essa limpeza também falhar.
O mesmo fluxo com transação e rollback explícito
Com escritas atômicas, você trata as três inserções como uma unidade: ou as três dão certo, ou nenhuma existe.
BEGIN;
INSERT INTO users (email, password_hash)
VALUES (:email, :hash)
RETURNING id INTO :user_id;
INSERT INTO profiles (user_id, display_name)
VALUES (:user_id, :display_name);
INSERT INTO subscriptions (user_id, plan)
VALUES (:user_id, :plan);
COMMIT;
-- If any statement fails, ROLLBACK;
Duas regras tornam isso confiável:
- Só envie “sucesso” ao usuário após o
COMMITter sucesso. - Se algo lançar, capture,
ROLLBACKe retorne uma mensagem de erro clara.
Ações pós-commit como e-mails de boas-vindas devem acontecer depois do commit (ou serem enfileiradas), assim você não envia e-mail para alguém cuja conta nunca foi realmente salva.
Para testar, adicione uma falha intencional no meio (por exemplo, force um display_name inválido) e confirme que o banco tem zero linhas para aquele email após a requisição falhar.
Próximos passos: corrigindo bugs de transação em apps gerados por IA
Se você herdou um app gerado por ferramentas como Lovable, Bolt, v0, Cursor ou Replit, registros parcialmente salvos geralmente apontam para limites de transação faltantes ou incompletos. Frequentemente parece ok em testes do caminho feliz, mas quebra sob tráfego real, timeouts ou um valor nulo inesperado.
Sinais comuns de que o código está sem uma transação adequada (ou a usa só pela metade):
- Uma chamada de API escreve em várias tabelas, mas cada escrita acontece em funções separadas com suas próprias chamadas ao banco.
- Erros são capturados e logados, mas o código continua e retorna sucesso.
- Jobs em background, e-mails ou chamadas de pagamento acontecem no meio das escritas no banco.
- Um retry cria linhas duplicadas porque nada aplica idempotência.
- Você vê linhas órfãs (um profile sem usuário, ou um pedido sem itens).
Quando pedir uma auditoria de código, não pergunte só “usamos transações?”. Pergunte onde elas começam e terminam, e o que acontece em falha. Uma auditoria sólida deve marcar riscos de integridade de dados (foreign keys, constraints, writes parciais), além de issues relacionadas que costumam vir com código gerado por IA, como fluxos de autenticação quebrados, segredos expostos e riscos de SQL injection.
Se você está decidindo refatorar ou reconstruir: refatore quando o modelo de dados estiver bom e o fluxo estiver principalmente sem um limite claro de transação mais tratamento de erro limpo. Reconstrua quando o workflow estiver embaraçado, tabelas não baterem com o produto, ou cada correção criar um novo caso de borda.
Se você está vendo dados parcialmente salvos ativamente em uma base gerada por IA, FixMyMess (fixmymess.ai) foca em diagnosticar o código, reparar a lógica, endurecer a segurança, refatorar áreas arriscadas e deixar o app pronto para deploy. A auditoria de código gratuita deles é uma forma prática de apontar o endpoint exato onde a atomicidade quebra e qual deve ser o comportamento de rollback mais seguro.