Travessia de caminho em endpoints de download: como identificar e corrigir
Travessia de caminho em endpoints de download pode expor arquivos privados. Aprenda a lidar com nomes de arquivo com segurança: listas de permissão, caminhos canônicos e controles de acesso no armazenamento.
Por que endpoints de download são fáceis de errar
Um endpoint de download deve fazer uma coisa simples: quando um usuário autenticado clica em "Download", o servidor encontra o arquivo certo e o envia de volta (com o nome e o tipo de conteúdo corretos).
Na prática, o passo de "encontrar o arquivo" é onde as coisas quebram. O erro mais comum é tratar a entrada do usuário como se fosse um nome de arquivo seguro. Um desenvolvedor pega algo como ?file=invoice.pdf e junta a um caminho de pasta, assumindo que o usuário só pedirá seus próprios arquivos. Atacantes não pensam em nomes de arquivo — eles pensam em caminhos.
Esse é o risco central da travessia de caminho em endpoints de download: um atacante tenta controlar de onde o servidor lê, não apenas qual documento ele obtém. Se seu código constrói um caminho a partir de entrada não confiável, uma requisição pode sair da pasta pretendida e entrar em áreas sensíveis.
Quando isso acontece, o impacto pode ser bem maior que "alguém baixa a fatura errada." Um atacante pode ler arquivos de configuração que revelam credenciais do banco de dados ou chaves de API, código-fonte (útil para encontrar mais bugs), uploads privados e exportações, ou outros arquivos do servidor que o ajudam a mapear seu ambiente.
Endpoints de download também são fáceis de errar porque parecem inofensivos. Muitas vezes são lançados tardiamente, recebem menos revisão e "funcionam bem" em testes básicos. O bug só aparece quando alguém envia entradas estranhas, caminhos codificados ou separadores inesperados.
Como a travessia aparece em requisições reais
Um endpoint de download geralmente pega algo da requisição e transforma em um caminho de arquivo. O bug aparece quando o servidor confia nessa entrada. Se o código faz algo como baseDir + "/" + filename, um atacante pode mudar o que “filename” significa.
Do lado de fora, uma requisição normal pede report.pdf. Um atacante tenta cargas que sobem diretórios ou pulam para outra unidade.
Formas comuns de payload incluem:
../secrets.envou../../../../etc/passwd..\\..\\Windows\\System32\\drivers\\etc\\hosts/etc/passwd(caminho absoluto no Linux)C:\\Windows\\win.ini(caminho absoluto no Windows)- Separadores mistos como
..\\../..\\config.yml
A codificação torna isso mais difícil de identificar nos logs. Muitos apps decodificam parâmetros de URL antes de validá‑los, o que significa que uma string bloqueada pode reaparecer após a decodificação. Atacantes costumam tentar %2e%2e%2f (que vira ../), ou dupla codificação como %252e%252e%252f (decodificada duas vezes por algumas stacks). Eles também misturam maiúsculas e separadores, por exemplo %2E%2E%5C para obter ..\\.
Um cenário realista: seu endpoint é GET /download?file=invoice-123.pdf. Se o handler usar esse valor diretamente, o atacante tenta file=..%2f..%2f.env ou file=..\\..\\appsettings.json. Se o arquivo existe e seu processo pode lê‑lo, o servidor pode retorná‑lo como um "download" sem erro óbvio.
Diferenças de plataforma importam só o suficiente para ser perigoso. Linux tipicamente usa / e é case‑sensitive. Windows aceita \\ e muitas vezes tolera /, suporta letras de unidade e tem nomes de dispositivo como CON e NUL. Se sua validação pensa apenas em um estilo de OS, pode perder o outro quando você fizer o deploy, ou quando um atacante testar bypasses.
Maneiras rápidas de detectar manipulação insegura de nomes de arquivo
A maior parte da travessia em endpoints de download começa com um erro: deixar a requisição decidir o caminho que você lê do disco. Você pode detectar isso traçando de onde a rota de download obtém sua entrada e onde essa entrada é usada.
Sinais de risco costumam parecer com isto:
- Um parâmetro de query como
file,path,nameoudownloadé lido e passado paraopen(),readFile(),sendFile()ou uma junção de caminhos. - O servidor confia em um cabeçalho (como
X-File,Content-Dispositionou atéReferer) para escolher um arquivo a servir. - "Sanitização" é feita com truques de string como
replace("../", "")ou removendo pontos, em vez de impor uma pasta base segura. - O endpoint constrói um caminho a partir da entrada do usuário e de uma pasta base, mas nunca verifica onde ele termina depois da normalização.
- Downloads saem direto do filesystem do servidor da aplicação, mesmo que os arquivos pudessem ficar em outro lugar (object storage, blobs em banco de dados ou um serviço de uploads).
Você pode confirmar a suspeita com alguns testes seguros em um ambiente de dev. Se um endpoint de download aceita um nome de arquivo, tente valores que nunca deveriam funcionar: ../.env, ../../etc/passwd, ..\\..\\windows\\win.ini, ou variantes codificadas como %2e%2e%2f. Mesmo que a resposta seja um erro, observe pistas nos logs (caminhos resolvidos completos, stack traces ou mensagens de erro que mencionem diretórios reais).
Um padrão comum que "parece seguro mas não é": o código verifica que a entrada termina com .pdf e então abre o arquivo. Atacantes podem usar truques de codificação, extensões duplas ou outros casos‑limite para passar por checagens ingênuas. Mesmo que alguns exemplos antigos com null‑byte não se apliquem mais à sua stack, a lição é a mesma: checagens por sufixo não são uma barreira.
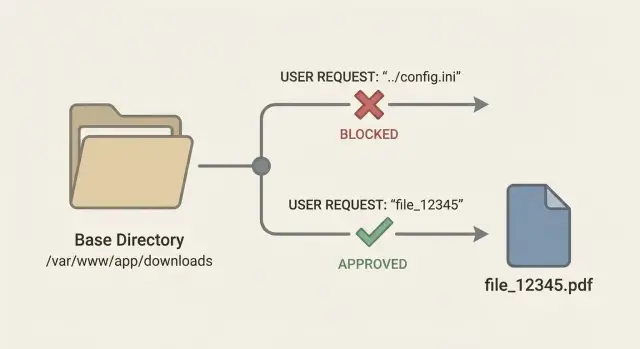
Padrão mais seguro: use IDs de arquivo e lookup no servidor
A maneira mais simples de evitar travessia de caminho em endpoints de download é parar de aceitar nomes de arquivo na URL. Nomes de arquivo são problemáticos. Podem incluir barras, barras invertidas, sequências .. e codificações que mudam o significado quando o servidor junta strings em um caminho.
Um padrão mais seguro é expor um ID estável, como GET /download/7f3a2c, e manter a localização real do armazenamento no lado do servidor. O ID é apenas um ponteiro. Sua aplicação decide qual arquivo ele aponta.
Quando uma requisição chega, faça um lookup do arquivo em uma tabela de banco de dados (ou qualquer repositório confiável) usando esse ID. Armazene metadados que você precisa para tomar uma decisão segura: quem é o dono, qual é a chave de armazenamento, qual o content type que deve retornar e se ainda é válido.
Um fluxo simples:
- Aceitar apenas um ID opaco (UUID, token aleatório, ID do banco).
- Buscar metadados do arquivo por ID (dono, organização, storage key, content type).
- Verificar se o usuário atual tem permissão para acessar esse registro.
- Baixar pelo storage key confiável, não pela entrada do usuário.
- Definir headers de resposta a partir dos metadados armazenados, não da requisição.
Exemplo: um cliente clica em "Download invoice" e sua UI chama /download/inv_12345. Seu servidor confirma que inv_12345 pertence à conta daquele cliente, então lê storage_key=accounts/889/invoices/2025-01.pdf. O usuário nunca envia ../../etc/passwd porque não existe parâmetro de nome de arquivo para atacar.
Isso também facilita auditorias. Você pode revisar uma checagem de autorização no lookup em vez de tentar provar que todo nome de arquivo possível é seguro.
Listas de permissão que realmente ajudam (e o que evitar)
Uma allowlist só ajuda se limitar downloads a coisas que você já sabe que são seguras. Para downloads, isso geralmente significa ou (1) uma lista de chaves de arquivo conhecidas que você gerou e armazenou, ou (2) uma lista curta de tipos de arquivo que você realmente suporta.
A allowlist mais segura é pela chave exata armazenada, não pelo nome de arquivo fornecido pelo usuário. O usuário envia um ID como fileId=8f3c..., seu servidor busca o registro armazenado (dono, caminho no bucket, chave exata do objeto) e serve isso. O usuário nunca influencia o caminho.
Se você precisa aceitar nomes de arquivo, trate allowlists de extensão como um backup, não como controle principal. Valide um conjunto curto (por exemplo: pdf, csv) e rejeite todo o resto. Não tente "limpar" entradas para torná‑las aceitáveis. Rejeitar é mais seguro.
Antes de validar qualquer coisa, normalize para que atacantes não escapem pelas brechas. Mantenha simples e consistente: remova espaços em branco, normalize maiúsculas/minúsculas se isso fizer sentido, e rejeite separadores de caminho (/ e \\) além de sequências como ... Também fique atento a nomes traiçoeiros como invoice.pdf.exe ou report.pdf .
O que evitar: blacklists (elas perdem variantes), checagens endsWith em entrada bruta e allowlists que ainda permitem partes de diretório.
Caminhos canônicos: impor um limite de diretório base
A regra mais segura para downloads é simples: o usuário nunca deve poder escolher um caminho do filesystem. Se você precisa aceitar algo como um nome de arquivo, converta‑o para um caminho canônico e então prove que ele ainda está dentro de uma pasta aprovada (por exemplo, downloads_root). Isso fecha o truque clássico ../.
Canonicalizar significa resolver o caminho real que o SO usará. Deve colapsar . e .., normalizar separadores e (se sua plataforma suportar) resolver symlinks. Symlinks importam porque um caminho aparentemente inofensivo dentro da pasta de downloads pode apontar para fora dela.
Um padrão prático fica assim:
base = realpath(downloads_root)
requested = realpath(join(downloads_root, user_input))
if requested is null -> error
if not requested starts_with base + separator -> error
serve requested
Antes de canonicalizar, rejeite entradas obviamente perigosas. Isso reduz casos‑limite e facilita o logging. Rejeições comuns incluem caminhos absolutos (/etc/passwd, C:\\Windows\\...) e entradas que contenham separadores de caminho quando você esperava um nome simples.
Regras que se mantêm bem:
- Aceite apenas entradas relativas (sem
/inicial, sem letras de unidade). - Construa o caminho com funções de join seguras, nunca concatenação de strings.
- Canonicalize para um caminho real e então verifique se permanece sob
downloads_root. - Se o caminho canônico falhar, trate como bloqueado, não como "tente outro".
Finalmente, retorne o mesmo erro genérico para "não encontrado" e "bloqueado". Se você retornar mensagens diferentes, atacantes podem sondar quais arquivos existem no seu servidor, mesmo que não possam baixá‑los.
Controles de acesso no nível de armazenamento que reduzem o raio de impacto
Mesmo com boas checagens de entrada, trate seu endpoint de download como de alto risco. Se a travessia passar, as escolhas de armazenamento decidem se o atacante obtém um arquivo ou seu servidor inteiro.
Evite servir arquivos de usuários no mesmo disco do container da aplicação. Quando uploads e código da aplicação compartilham um filesystem, um único bug pode expor configs, chaves e código fonte. Mantenha arquivos fora do web root e desative o serviço estático direto para esse diretório, de modo que apenas sua aplicação possa ler e retornar arquivos.
Para muitas equipes, object storage é a maneira mais simples de reduzir risco. Em vez de ler caminhos locais, armazene arquivos como objetos e imponha acesso usando permissões por objeto ou acesso assinado de curta duração. Seu app verifica quem é o usuário, qual ID de arquivo foi pedido e se ele é o dono. Só então gera um token de download com tempo limitado ou faz proxy do arquivo.
Controles que compensam rápido:
- Mantenha buckets privados por padrão.
- Prefira acesso assinado de curta duração a URLs públicas permanentes.
- Se usar disco local, armazene fora do web root.
- Execute o app com permissões mínimas no filesystem (somente leitura onde necessário).
- Separe ambientes e buckets (dev vs prod).
Logging é tão importante quanto bloquear. Para cada requisição de download, registre o ID do usuário, o ID do arquivo e a decisão (permitido ou bloqueado), além de um código de motivo como "não é dono" ou "token expirado". Esse rastro de auditoria ajuda a detectar sondagens e prova o que aconteceu.
Erros comuns e bypasses que atacantes usam
A maioria das correções de travessia falha porque o código assume que o atacante enviará um simples ../. Ataques reais são em camadas e desenhados para escapar de qualquer checagem que você adicionou.
Um erro clássico é confiar em regras no lado do cliente ou campos ocultos de formulário. Se sua UI só deixa o usuário escolher de um dropdown, mas o servidor ainda aceita um parâmetro path, um atacante pode alterar esse valor na requisição. O servidor tem que agir como se a UI não existisse.
Truques de codificação são outro bypass frequente. Equipes decodificam uma vez, validam, e depois algum framework ou proxy decodifica novamente. Isso pode transformar uma string aparentemente segura em ../ depois da validação. A correção é consistência: normalize e valide em um lugar, e assegure que o valor usado para abrir o arquivo é exatamente o valor que você validou.
Checagens por extensão são fáceis de enganar. Bloquear tudo exceto .pdf soa seguro, mas atacantes ainda podem atravessar para pastas sensíveis e buscar arquivos que terminem com .pdf, ou abusar de segmentos extras se seu tratamento de caminho for frouxo. Se o objetivo é servir apenas faturas, o caminho não deveria ser controlado pelo usuário.
Bypasses que aparecem com frequência:
- Caminhos ocultos ou gerados no cliente tratados como entrada confiável
- Decodificação em camadas diferentes (app, framework, proxy)
- Checagens "Allow .pdf only" que ignoram diretórios e segmentos
- Symlinks dentro de uma pasta permitida que apontam para fora
- Zip Slip: extrair um arquivo que contém caminhos com
../e escrever fora da pasta alvo
Symlinks merecem atenção especial. Mesmo que você junte uma pasta base com um nome de arquivo, um symlink dentro dessa pasta pode pular a fronteira. A correção confiável é checagem de caminho canônico (depois de resolver symlinks) mais permissões estritas no filesystem.
Checklist rápido antes de lançar um recurso de download
Endpoints de download parecem simples, mas são uma forma comum de a travessia chegar à produção. Algumas escolhas pequenas (como aceitar um nome de arquivo na URL) podem transformar um download normal de fatura em "ler qualquer arquivo no servidor."
A abordagem padrão mais segura
Decida primeiro o que o usuário tem permissão para solicitar. Usuários devem pedir um arquivo por um ID que você controla, não por um caminho que possam moldar.
- Input: aceite apenas um ID de arquivo (ou número de fatura), nunca um caminho bruto ou nome de arquivo.
- Lookup: mapeie esse ID para um registro armazenado que contenha a chave de armazenamento real ou caminho absoluto no servidor.
- Validação: se precisar tratar nomes, use uma allowlist apertada (extensões esperadas, caracteres permitidos), então canonicalize e confirme que o resultado permanece dentro do diretório base.
- Autorização: verifique propriedade e papel antes de ler o arquivo, não depois.
- Resposta: defina cabeçalhos seguros e evite refletir entrada do usuário em
Content-Dispositionsem limpeza.
Reduza o raio de impacto com armazenamento e testes
Armazenamento privado por padrão te salva quando o código falha. Mantenha arquivos baixáveis fora do web root e evite buckets públicos onde adivinhar um nome basta.
Um teste prático rápido: tente requisitar sequências ../, variantes codificadas e barras extras contra sua rota de download. Tentativas bloqueadas devem ser logadas com detalhes suficientes para depurar (ID do usuário, ID solicitado, motivo do bloqueio), mas sem segredos.
Cenário de exemplo: downloads de faturas que expõem arquivos do servidor
Um fundador implementa rapidamente um recurso de faturas: clientes clicam e o app chama um endpoint como /download?filename=invoice-1042.pdf. O servidor pega filename, monta um caminho, lê o arquivo e o retorna.
Funciona em testes porque todo mundo pede arquivos normais. O problema é que o servidor está confiando na entrada do usuário para escolher um arquivo. Um atacante pode trocar o parâmetro por algo como ../../.env ou ../../../etc/passwd. Se o código junta strings (ou decodifica valores codificados em URL e depois junta), o app pode ler arquivos fora da pasta de faturas.
Um plano de correção que mantém o recurso mas remove o risco:
- Trocar nomes de arquivo por IDs (ex.:
/download?id=inv_1042) e buscar o caminho real no servidor. - Aplicar checagens de auth e de propriedade para que somente o cliente certo baixe sua fatura.
- Armazenar faturas em armazenamento privado (não em pasta pública) e servi‑las por download controlado.
- Adicionar allowlists simples: permitir apenas formatos conhecidos (como PDF) e rejeitar o resto.
- Logar requisições negadas para detectar tentativas de sondagem cedo.
Para confirmar que foi consertado, não confie em "parece bem." Prove:
- Tente payloads
../e variantes codificadas e verifique que sempre retorna um erro genérico. - Cheque logs para confirmar que padrões de travessia foram bloqueados e registrados.
- Adicione um teste automatizado que tenta
../../.enve espera uma negação.
Próximos passos: audite seus endpoints e corrija rapidamente
Comece supondo que você tem mais de uma rota de "download." Em muitos apps, arquivos são servidos por vários lugares: rota de faturas, rota de exportação, preview de anexo e às vezes uma ferramenta de debug que acaba indo para produção.
Uma auditoria prática:
- Liste todos os endpoints que retornam arquivo (download, export, relatório, imagem, anexo, backup).
- Trace de onde cada um obtém seu nome de arquivo ou caminho (query, param de rota, corpo JSON, cabeçalhos, banco de dados).
- Anote cada local de armazenamento em uso (diretórios locais, pastas temporárias, mounts de rede, buckets de object storage).
- Busque por construção de caminhos e leituras de arquivo (
join,resolve,open,readFile,sendFile, criação de zip). - Verifique checagens de acesso: quem pode solicitar qual arquivo e como esse mapeamento é imposto.
Depois de mapear a superfície de ataque, faça uma remediação focada. Prefira IDs de arquivo com lookup no servidor (ID -> caminho armazenado) em vez de deixar a entrada do usuário influenciar um caminho do filesystem. Adicione validação de caminho canônico para impor um único limite de diretório para qualquer acesso remanescente em disco, e use uma allowlist rigorosa apenas para arquivos verdadeiramente estáticos.
Finalize com testes que provem que a correção se mantém:
- Requisições contendo
../e variantes codificadas são rejeitadas. - Caminhos absolutos (Unix e Windows) são rejeitados.
- Casos de symlink não escapam do diretório base.
- Só arquivos pertencentes ao usuário ou à org atual podem ser baixados.
Se você herdou uma base de código gerada por IA, vale a pena uma revisão por outra pessoa nas rotas que servem arquivos. FixMyMess (fixmymess.ai) foca em diagnosticar e reparar apps gerados por IA, e uma auditoria rápida pode revelar problemas como manipuladores de download inseguros, checagens de auth quebradas, exposição de segredos e padrões de armazenamento arriscados antes que cheguem à produção.
Perguntas Frequentes
O que é travessia de caminho em um endpoint de download?
Um endpoint de download fica perigoso quando transforma entrada controlada pelo usuário em um caminho de arquivo no disco. Se seu código faz algo como “pasta base + entrada do usuário”, um atacante pode tentar ../ ou variantes codificadas para escapar do diretório pretendido e ler outros arquivos aos quais o processo do app tem acesso.
O que os atacantes podem obter se a travessia de caminho funcionar?
Se um atacante consegue ler arquivos fora da pasta de downloads, ele pode obter arquivos de configuração com segredos, código-fonte da aplicação, uploads privados, exportações ou outros arquivos do servidor. O dano real costuma ser o acesso subsequente — por exemplo, usar credenciais vazadas para acessar seu banco de dados ou serviços de terceiros.
Como identifico rapidamente manipulação insegura de nomes de arquivo no meu código?
Procure por rotas que leem file, path, name ou parâmetros semelhantes na query, rota, corpo JSON ou cabeçalhos e então passam esse valor para APIs de arquivo como open, readFile ou sendFile. Trate como sinal de alerta qualquer “sanitização” feita por string, como replace("../", ""), porque costuma perder codificações e casos limites.
Por que bloquear apenas "../" em uma checagem de string não resolve?
Porque atacantes raramente enviam ../ em claro. Eles usam codificação URL, dupla codificação, separadores mistos e caminhos específicos de plataforma, de modo que a sequência perigosa pode aparecer apenas depois de decodificação ou normalização dentro da sua stack.
Qual é o desenho mais seguro para um endpoint de download?
O mais seguro é expor um ID opaco no URL e fazer lookup do caminho ou chave de armazenamento no servidor. O usuário pede “arquivo 123” e sua aplicação decide onde esse arquivo está e se o usuário atual tem permissão para acessá‑lo.
Listas de permissão de extensão como “somente .pdf” são suficientes?
Não de forma confiável. Uma checagem como “deve terminar com .pdf” não previne travessia de diretório e não impede que alguém baixe um PDF sensível que exista em outra parte do servidor. Use checagens de extensão apenas como uma guarda adicional depois que você eliminar o controle do usuário sobre caminhos.
O que significa checagem de “caminho canônico” na prática?
Resolva o caminho solicitado para um caminho canônico (real) e então verifique se ele ainda está dentro de um único diretório base aprovado. Se o resultado canônico escapar desse limite, bloqueie e retorne um erro genérico para que atacantes não possam sondar quais arquivos existem.
Por que as diferenças entre Windows e Linux importam na validação?
São formatos de caminho diferentes que podem contornar validações feitas apenas para um estilo. Windows aceita barras invertidas, muitas vezes tolera /, suporta letras de unidade e tem nomes de dispositivo especiais, enquanto Linux usa / e costuma ser case-sensitive. Validar só um estilo pode deixar brechas quando você faz deploy ou quando atacantes testam estilos alternativos.
Como escolhas de armazenamento reduzem o dano se um bug passar?
Não armazene arquivos de download de usuários na mesma área do filesystem que contém código e segredos, se puder evitar. Prefira armazenamento de objetos privado com tokens de acesso de curta duração ou proxy pelo servidor, e execute a aplicação com permissões mínimas de leitura para que um único bug não exponha a máquina inteira.
O que devo registrar e monitorar para endpoints de download?
Registre a identidade do usuário, o ID do arquivo (ou o valor solicitado) e se a ação foi permitida ou bloqueada, com um código de motivo simples, mas não registre caminhos resolvidos completos ou conteúdos que possam conter segredos. Se herdou um código gerado por IA e suspeita de rotas de serviço de arquivos arriscadas, FixMyMess (fixmymess.ai) pode executar uma auditoria rápida e corrigir manipuladores de download inseguros, checagens de auth e exposições de segredos.