Uploads diretos para armazenamento de objetos que evitam timeouts
Uploads diretos para armazenamento de objetos evitam timeouts ao enviar arquivos grandes direto para o storage, usando URLs assinadas e etapas retomáveis que mantêm o app responsivo.
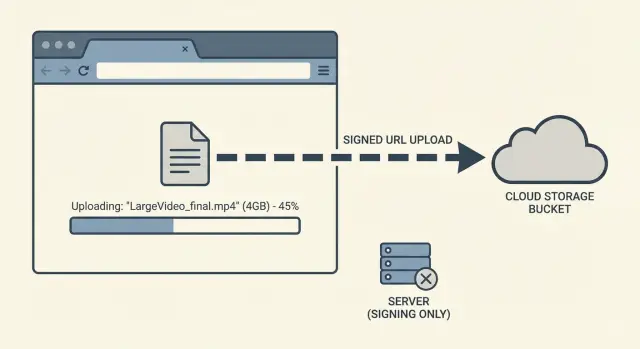
Por que uploads grandes continuam falhando em apps reais
Os usuários percebem rápido: a barra de progresso chega a 90% e congela. Eles atualizam a página, tentam de novo, e falha em outro ponto. No celular ou em Wi‑Fi instável, vira uma loteria, mesmo quando o arquivo está OK.
Quando uploads falham, as pessoas não perdem só tempo. Perdem confiança. Um criador que passou 20 minutos exportando um vídeo não vai re-enviar com prazer três vezes. Um recrutador anexando um grande portfólio abandona o formulário. Aí sua equipe lida com o fallout: "Está preso", "Diz que falhou", "Cadê meu arquivo?"
Retentativas frequentemente pioram a situação. Muitos sistemas recomeçam do zero, queimam banda e deixam para trás arquivos duplicados "quase enviados" ou registros de banco parcialmente preenchidos. Se seu app salva metadados antes do upload realmente terminar, você acaba com entradas que parecem reais mas apontam para nada.
Uploads grandes estressam as partes mais fracas de uma stack típica. Conexões longas estouram timeout. Proxies e load balancers cortam requisições. Servidores disparam CPU e memória se ficarem armazenando grandes payloads. Um upload lento pode travar recursos que deviam atender todo mundo.
O objetivo é simples: fazer arquivos grandes enviarem-se de forma confiável sem transformar seu servidor de aplicação num intermediário frágil. Uploads diretos para armazenamento de objetos fazem isso. Em vez de empurrar gigabytes pelo backend, o dispositivo do usuário envia direto para o storage. Seu app fica com permissões, rastreio e confirmação do resultado final.
É aqui que protótipos costumam quebrar: "funciona com arquivos pequenos" e desaba em produção.
O que geralmente causa timeouts em uploads
A maioria dos timeouts acontece porque seu servidor está atuando como retransmissor. O navegador envia um arquivo enorme para seu servidor, seu servidor mantém a conexão aberta e depois repassa os mesmos bytes para o storage. Se o usuário estiver lento, seu servidor fica esperando. Enquanto isso, memória e CPU sobem e outras requisições começam a atrasar.
Timeouts também podem vir de qualquer ponto no caminho. Um único limite basta para matar um upload mesmo que o resto esteja saudável: a aba do navegador (suspensão em background, troca de rede), um proxy ou load balancer com limite rígido de requisição, timeouts de workers do servidor, limites do framework para tamanho de corpo ou parsing, ou a própria chamada do cliente de storage.
A reação comum é "só aumenta o timeout." Isso pode ganhar um dia, mas raramente corrige o problema de raiz. Timeouts maiores significam mais conexões de longa duração, e o overload fica mais provável. Uma pessoa enviando um vídeo de 2 GB em Wi‑Fi ruim pode ocupar um worker por minutos e, de repente, usuários normais veem páginas lentas ou logins falhando.
Imagine um cenário comum: um usuário faz upload do café. No meio, a conexão cai por 10 segundos. O navegador tenta de novo, seu servidor ainda segura uma requisição pela metade, um proxy mata a requisição aos 60 segundos e o usuário vê "Upload falhou" sem motivo claro.
Uploads diretos para storage ajudam porque removem seu servidor de aplicação do caminho pesado de dados.
O que significa upload direto para armazenamento de objetos (em linguagem simples)
Upload direto para armazenamento significa que o arquivo vai direto do dispositivo do usuário (navegador ou app móvel) para o bucket de storage, em vez de passar primeiro pelo seu servidor de aplicação. Seu app ainda coordena, mas não carrega os bytes do arquivo.
Pense assim: seu servidor entrega ao usuário um passe de permissão único e de curta duração. O usuário usa esse passe para enviar direto ao storage. Essa permissão pode ser limitada a um único arquivo, um único destino e um intervalo curto de tempo.
Na prática, seu backend faz três pequenas coisas:
- confirmar que o usuário tem permissão para enviar
- criar a permissão de upload de curta duração (frequentemente uma URL assinada)
- registrar metadados e depois verificar que o upload terminou
A vantagem é imediata: menos timeouts, menos pressão de banda no servidor e uma experiência mais suave. Serviços de storage foram feitos para aceitar muitos uploads grandes ao mesmo tempo.
Um exemplo simples: um fundador testa fazendo upload de um vídeo grande. Com "upload via meu servidor", a requisição pode morrer aos 60 segundos, 120 segundos, ou quando um proxy decidir que já esperou demais. Com a abordagem direta, o navegador envia para o storage, e seu app só faz uma requisição "iniciar" rápida e uma "confirmar" rápida.
Uploads assinados: a forma segura de deixar usuários enviarem direto
Uma URL assinada é esse passe de permissão de curta duração que seu backend cria para que um usuário envie um arquivo ao storage sem seu servidor ficar no meio do caminho.
O "assinado" importa porque a URL (ou campos de formulário) inclui prova de que seu backend aprovou o upload sob regras específicas. Se alguém copiar a URL depois, ela deve ser inútil porque expira rápido e só permite uma ação restrita.
Que limites uma URL assinada deve incluir?
Uploads assinados devem ser rígidos por padrão. Bons limites incluem tempo de expiração (minutos, não horas), limite máximo de tamanho, tipos de conteúdo permitidos (por exemplo, video/mp4 ou image/png) e uma chave/destino travado ou padrão de caminho para que usuários não sobrescrevam outros arquivos. Se você depende de metadados (como owner ID), valide isso também.
Um fluxo típico: o usuário seleciona um vídeo de 1 GB. Seu backend checa a conta, tipo esperado e tamanho. Então retorna uma URL assinada válida por, digamos, 10 minutos. O navegador envia direto para o storage e seu backend recebe uma pequena mensagem de "upload concluído" depois.
Single shot vs multipart uploads
Use uma URL single-shot quando os arquivos são pequenos o bastante para que uma única requisição conclua sem precisar de resume.
Para arquivos maiores, prefira multipart. Multipart divide o arquivo em pedaços para que você possa re-tentar apenas a parte que falhou em vez de reiniciar do zero. Isso frequentemente é a diferença entre "funciona na rede do escritório" e confiabilidade real.
Estratégias retomáveis que sobrevivem conexões instáveis
Uploads grandes falham por motivos entediantes: Wi‑Fi cai, laptop dorme, telefone troca de rede. Se seu upload depende de uma única requisição longa, qualquer solavanco pode forçar o usuário a recomeçar.
Uploads retomáveis consertam isso transformando uma transferência frágil em muitas transferências pequenas e re-tentáveis. Isso combina naturalmente com uploads diretos para storage porque seu servidor não está vigiando um arquivo enorme por minutos.
Como uploads retomáveis funcionam
Em vez de enviar o arquivo inteiro de uma vez, o cliente o divide em partes (chunks). Cada parte é enviada separadamente, e o sistema registra o que chegou.
Uma abordagem simples:
- dividir o arquivo em chunks de tamanho fixo (por exemplo, 5–25 MB cada)
- enviar os chunks em ordem (ou alguns em paralelo) e registrar números de partes concluídas
- re-tentar apenas os chunks que falham, com backoff (esperar um pouco mais a cada tentativa)
- retomar depois perguntando "Quais chunks vocês já têm?" e continuar
- finalizar dizendo ao storage para montar as partes em um único objeto
Se o navegador travar ou o dispositivo dormir, a próxima sessão pode retomar a partir do último chunk confirmado.
O que os usuários devem experimentar
Retomável não é só escolha de backend. Muda a sensação do upload. Usuários devem ver progresso baseado em chunks confirmados e receber controles que combinem com a vida real: pausar, retomar e um estado claro de "reconectando" quando a rede oscilar.
Exemplo: alguém envia um vídeo de 3 GB no trem. A conexão cai duas vezes. Com uploads retomáveis, eles só reenviam dois chunks faltantes, o progresso continua honesto e o upload termina sem a frustração de "começar do 0%".
Passo a passo: um fluxo de upload confiável que você pode implementar
Um fluxo confiável mantém seu servidor fora do caminho de dados. Seu servidor define regras e confirma resultados. O navegador envia o arquivo direto para o storage.
Uma sequência prática:
- Cliente pede para enviar (só metadados). Envie nome do arquivo, tamanho, tipo e contexto (projeto, usuário), mas não o arquivo.
- Servidor valida e retorna info de upload assinada. Faça valer os limites, crie um registro rascunho no banco e retorne a info assinada de upload mais um ID/chave de upload.
- Navegador envia direto e mostra progresso. Envie do cliente para o storage e atualize progresso. Se suportar chunking, mantenha estado de chunks localmente para que um refresh possa continuar.
- Cliente confirma conclusão. Depois que o storage reportar sucesso, o cliente chama seu servidor com o ID/chave e o tamanho esperado.
- Servidor verifica e finaliza. Confirme que o objeto existe, bate tamanho/tipo e pertence ao usuário certo. Então marque o registro como pronto.
Um detalhe pequeno que previne muita dor: trate o upload como uma máquina de estados. "Rascunho" não é "pronto." Só mude para "pronto" após verificação server-side.
Mantenha trabalho pós-upload fora da requisição de upload. Enfileire tarefas como thumbnails, escaneamento de vírus ou transcodificação para que usuários não fiquem esperando e timeouts não se acumulem.
Fazer os uploads parecerem confiáveis para os usuários
As pessoas perdoam um upload lento. Não perdoam um upload confuso. Mesmo com uploads diretos para storage, a conexão geralmente é o elo fraco, então sua UI precisa definir expectativas e cumprir promessas.
Faça o progresso parecer honesto. Uma porcentagem sozinha é enganosa para arquivos grandes porque a velocidade muda. Mostre MB enviados do total e trate "tempo restante" como estimativa. Se o upload estiver parado, diga isso. "Pausado, tentando reconectar" é melhor que 72% congelado.
Um padrão simples:
- mostrar MB enviados do total e velocidade atual
- mostrar ETA só depois de alguns segundos de transferência estável
- detectar ausência de progresso por N segundos e então mudar para "reconectando"
- oferecer ações claras de "Pausar" ou "Tentar novamente"
Uploads também passam mais segurança quando sobrevivem a comportamentos normais. Se alguém atualizar, fechar a aba ou o laptop dormir, mantenha estado local suficiente (nome do arquivo, tamanho, ID da sessão de upload, partes concluídas) para retomar em vez de reiniciar.
Quando erros ocorrerem, seja específico e dê o próximo passo. "Upload falhou" é inútil. "Sua conexão caiu. Salvamos seu progresso. Clique em Retomar." tranquiliza. Se o usuário escolheu o tipo de arquivo errado ou excedeu um limite, diga o que é permitido.
Acessibilidade importa porque o status de upload é baseado em tempo. Use texto de status legível (não só cor), mantenha foco na ação clicada e anuncie mudanças chave (iniciado, pausado, retomado, concluído) para que usuários de teclado e leitores de tela não fiquem no escuro.
Erros comuns e armadilhas a evitar
A maior armadilha com uploads diretos é assumir "o navegador cuidou, então acabou." O storage é confiável, mas seu app ainda precisa controlar acesso, confirmar conclusão e manter o banco honesto.
Confiar demais no navegador
Uma URL assinada prova que o usuário tinha permissão no início. Não prova o que foi enviado, nem que o upload terminou.
Após o upload, verifique no servidor que o objeto existe e corresponde ao tamanho e tipo esperados, que caiu no caminho/prefixo correto para aquele usuário ou projeto, e que quaisquer metadados que você dependa batem. Só então marque o upload como "pronto."
URLs assinadas permissivas demais
Alguns sistemas "consertam" timeouts deixando URLs assinadas válidas por horas e aceitando qualquer arquivo. Isso é arriscado. Mantenha a URL curta e com escopo estreito: limite de tamanho, tipos MIME e destino travado.
Registros de uploads que nunca terminaram
Se você cria um registro no banco como "enviado" antes da confirmação, vai acumular entradas quebradas e arquivos faltando. Crie como "pendente" e só mude para "enviado" depois de confirmar que o objeto existe (ou após um evento de callback do storage, se usar um).
Processamento pesado inline
Não faça o usuário esperar enquanto você transcodifica vídeo, escaneia arquivos ou gera thumbnails. Aceite o upload, confirme e então queue o processamento em background, mostrando um status claro. Isso mantém o caminho de upload rápido e previsível.
Enviar arquivos acidentalmente pela sua API
Se o frontend voltar a postar o arquivo para sua API quando o upload direto falha, você está de volta aos timeouts. Mantenha autenticação e tráfego de controle na API, mas mantenha os bytes do arquivo indo direto para o storage.
Checklist rápido antes de liberar
Antes de chamar o recurso de upload de "pronto", passe rápido por confiabilidade e segurança. A maioria dos bugs aparece quando usuários reais tentam arquivos grandes em Wi‑Fi instável ou quando trabalho em background demora mais que o timeout HTTP.
- Retomar funciona sem recomeçar. Se a conexão cair a 80%, o usuário deve continuar de onde parou.
- Limites são aplicados antes da permissão. Verifique tipo e tamanho cedo e recuse emitir permissão para arquivos que você não aceitará.
- Permissões assinadas são de curta duração e com escopo restrito. Um arquivo, um caminho, um método.
- Conclusão é verificada no storage. Não marque como "feito" só porque o cliente disse.
- Trabalho pesado é movido para fora da requisição de upload. Converter, escanear, OCR e thumbnails depois do upload.
Se o processamento demora, mostre dois estados separados: "Enviado" e "Processando." Usuários confiam em sistemas que explicam o que está acontecendo.
Um exemplo realista: um upload grande que não falha
Um criador está num café tentando enviar um vídeo de 3 GB. O Wi‑Fi cai por alguns segundos de vez em quando, e o laptop entra em sleep uma vez. Eles ainda esperam que o upload termine sem recomeçar.
No método antigo, o navegador envia tudo para seu servidor, que depois encaminha para o storage. Em 30–120 segundos (dependendo do setup), algo estoura: load balancer, reverse proxy, limite serverless ou uma requisição lenta. O usuário vê erro, atualiza, e o upload reinicia do 0%. Suporte recebe "Tentei três vezes e nunca funciona."
Compare com uploads diretos usando uma URL assinada e uploads retomáveis. Seu servidor só entrega permissão de curta duração e um plano de upload. O navegador envia o arquivo direto ao storage em partes (por exemplo, chunks de 10–50 MB). Quando o Wi‑Fi do café oscila, só a parte atual falha.
Em vez de perder tudo, o cliente re-tenta o chunk que faltou, continua do último pedaço confirmado, mantém o progresso crível e termina mesmo com conexão imperfeita.
Seu time de produto pode medir a diferença rápido: taxa de conclusão de upload, média de re-tentativas por upload e tempo até o ativo estar reproduzível ou processável. O melhor sinal é menos chamados de suporte sobre "uploads presos" ou "uploads reiniciam", porque o sistema se recupera silenciosamente e seu servidor fica responsivo.
Próximos passos se seu fluxo de upload atual já é bagunçado
Se uploads já são instáveis, não reconstrua tudo de uma vez. Os ganhos mais rápidos vêm de estreitar escopo, tornar falhas visíveis e remover a parte mais arriscada (seu servidor proxyando arquivos grandes).
Comece com um tipo de upload, como vídeos ou PDFs. Escolha o que causa mais chamados de suporte ou os arquivos maiores. Mantenha o caminho antigo para outros tipos até o novo provar sua eficácia.
Antes de mudar comportamento, adicione rastreamento básico para ver o que está quebrando. Timeouts frequentemente escondem múltiplos problemas: redes lentas, tempestades de retry, CORS mal configurado, tokens expirados e usuários deixando a aba.
Um plano de limpeza que costuma funcionar:
- migrar uma tela e um tipo de arquivo para uploads diretos verificados
- instrumentar início do upload, bytes enviados, conclusão e motivo claro de falha
- confirmar fronteiras de autenticação: emitir permissões assinadas de curta duração, nunca enviar chaves longas ao navegador
- remover segredos expostos e lógica embolada (chaves hardcoded, endpoints duplicados, responsabilidades misturadas, loops de retry intermináveis)
- centralizar o fluxo de upload (um módulo cliente, um endpoint da API que emite assinaturas)
Se você herdou um app gerado por IA, gaste tempo extra em autenticação e tratamento de segredos. "Funciona na minha máquina" protótipos frequentemente pulam checagens server-side ou acoplam uploads ao servidor de formas que desabam sob tráfego real.
Se quiser uma segunda opinião, FixMyMess (fixmymess.ai) pode rodar uma auditoria de código gratuita para encontrar problemas de upload e segurança, e ajudar a reparar o fluxo para que fique pronto para produção.
Perguntas Frequentes
Por que uploads grandes falham mesmo quando meu servidor parece estar bem?
A maioria das falhas acontece porque o upload passa primeiro pelo seu servidor de aplicação. Isso cria uma requisição de longa duração que pode ser cortada pelo navegador, proxy, load balancer, limite de serverless ou pelo timeout do próprio worker do servidor. Tirar os bytes do arquivo do caminho do backend (upload direto para armazenamento de objetos) remove a parte mais frágil do trajeto.
O que exatamente meu backend deve fazer em um fluxo de upload direto para armazenamento?
Seu servidor só deve cuidar de permissão, rastreamento e verificação. Ele pode validar o usuário, criar uma permissão de upload assinada e curta, criar um registro rascunho no banco de dados e finalizar o registro depois de verificar que o objeto existe no armazenamento. O servidor não deve fazer streaming nem armazenar o arquivo em buffer.
O que é um upload assinado e por que é mais seguro?
Um upload assinado é uma permissão de curta duração que seu backend cria para permitir que o cliente envie diretamente para o armazenamento sob regras estritas. É mais seguro do que expor credenciais de longa duração porque expira rápido e pode ser limitado a um único arquivo, um destino específico e restrições concretas.
Quais limites devo impor nas permissões de upload assinadas?
Comece restrito e afrouxe só se for necessário. Use expiração curta (minutos), limite máximo de tamanho, tipos MIME permitidos e uma chave/prefixo de destino que impeça sobrescrever arquivos de outros usuários. Esses limites reduzem abuso e evitam arquivos “enviados, mas inutilizáveis.”
Quando devo usar uploads multipart em vez de uma URL assinada única?
Use uploads single-shot para arquivos pequenos onde uma única requisição costuma completar. Use multipart (chunked) para arquivos grandes ou quando precisar de resume, porque um único problema de rede não forçará recomeçar do zero. Multipart é a escolha prática para usuários reais em dados móveis ou Wi‑Fi instável.
Como uploads retomáveis funcionam na prática?
Divida o arquivo em partes, faça upload das partes independentemente e registre quais partes foram concluídas. Se a conexão cair, reenvie apenas as partes faltantes e continue. O essencial é armazenar estado suficiente (como um ID de sessão de upload e números de partes concluídas) para que uma atualização ou reinício retome de onde parou.
Como evito que meu banco de dados encha com registros “enviados” sem arquivo?
Não marque um upload como concluído só porque o cliente disse que sim. Depois que o cliente reporta sucesso, seu servidor deve checar o armazenamento para confirmar que o objeto existe e corresponde ao tamanho e tipo esperados, então mudar o registro do banco de dados de “pendente” para “pronto”. Isso evita registros quebrados que apontam para arquivos ausentes.
Quais mudanças na UI deixam uploads mais confiáveis para os usuários?
Mostre progresso com base em bytes confirmados, não só uma porcentagem que pode congelar. Diga ao usuário o que está acontecendo quando o progresso para, por exemplo “Reconectando”, e ofereça uma ação clara de retomar ou tentar novamente. Se possível, preserve estado para que um refresh não reinicie tudo do zero — isso é a forma mais rápida de perder confiança.
Por que não devo transcodificar ou escanear vírus durante a requisição de upload?
Processamento inline aumenta as chances de timeouts e faz o usuário esperar por trabalho que não precisa bloquear o upload. Aceite o upload, verifique-o e então execute scanning, thumbnailing ou transcodificação em background com um status separado de “Processando”. Isso mantém o caminho de upload rápido e previsível.
Meu código de upload está bagunçado (e parcialmente gerado por IA). Qual é a forma mais rápida de consertar?
Comece migrando uma tela e um tipo de arquivo para um fluxo direto para armazenamento e verificado em forma de máquina de estados, e então meça taxa de conclusão e motivos de falha. Se o código é gerado por IA, priorize checar fronteiras de autenticação, remover segredos expostos e eliminar fallbacks que enviem bytes do arquivo pela sua API. Se quiser, FixMyMess (fixmymess.ai) pode fazer uma auditoria de código gratuita e consertar o fluxo de upload para produção.