Verificações de readiness e liveness que detectam falhas reais
Aprenda a projetar verificações de readiness e liveness que validam seu banco, fila e APIs críticas para que quedas apareçam antes dos usuários notarem.
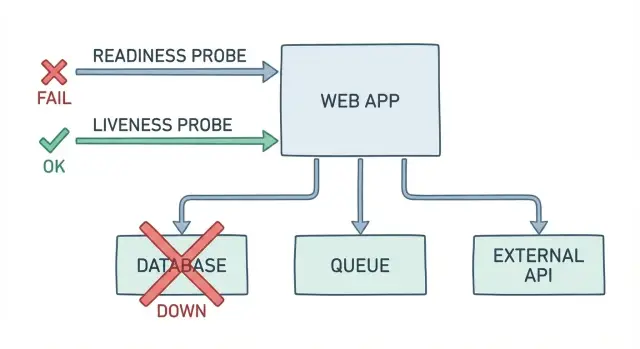
Por que verificações “OK” ainda deixam usuários quebrados
Um endpoint básico /health normalmente responde a uma pergunta: o processo está rodando? Isso não é o mesmo que: um usuário consegue entrar, pagar ou terminar sua tarefa agora. Quando a sua checagem retorna “OK” enquanto o app falha na sua função real, você tem alertas falso-verdes e um incidente mais lento e bagunçado.
É assim que aparece na vida real. O pod está ativo, CPU parece normal e o endpoint de saúde diz “OK”. Mas o login falha porque o banco está bloqueado durante uma migração. Pagamentos falham porque um segredo rotacionou e credenciais expiraram. Jobs em background se acumulam porque a conexão com a fila está travada, então confirmações de pedido nunca são enviadas.
Checagens falso-verdes custam tempo e confiança. O on-call corre atrás de sinais “parece tudo ok”. O suporte recebe reclamações antes do monitoramento. Usuários tentam de novo, desistem e lembram do dia ruim.
Readiness e liveness devem refletir o que os usuários precisam para ter sucesso. Uma boa sonda não é um “OK” de vaidade. É um teste pequeno e rápido do caminho crítico.
Uma sonda consciente de dependências deveria responder perguntas como:
- Conseguimos conectar ao banco e executar uma pequena query?
- Conseguimos autenticar na fila e publicar uma mensagem (ou pelo menos verificar que a conexão está viva)?
- As credenciais obrigatórias são válidas e não expiraram?
- Os poucos serviços externos dos quais realmente dependemos estão alcançáveis?
Se você herdou um app gerado por IA que “roda” mas quebra em produção (frequente em auth, segredos e filas), probes melhores impedem que deploys ruins prejudiquem usuários silenciosamente.
Readiness vs liveness em linguagem simples
Readiness responde: esta instância pode receber tráfego com segurança agora? Se a resposta for não, ela deve permanecer em execução, mas ser removida da rotação para que usuários não sejam encaminhados para uma cópia quebrada.
Liveness responde: o processo está vivo e progredindo, ou está travado de uma forma que um restart resolveria? Se a resposta for não, a plataforma deve reiniciá-lo.
Um exemplo simples de readiness: seu app sobe, mas o banco está offline ou credenciais estão erradas. O processo está em execução, ainda assim todo login e carregamento de página falham. Uma boa probe de readiness falharia aqui para que requisições parem de atingir essa instância até o banco voltar a funcionar.
Um exemplo simples de liveness: um bug causa um deadlock e o app para de responder embora o container ainda esteja rodando. A readiness pode também falhar, mas não resolve o problema raiz. Uma liveness detecta que o app não está progredindo e aciona um restart para recuperar.
Uma forma simples de lembrar:
- Readiness protege usuários de instâncias ruins.
- Liveness ajuda o sistema a recuperar instâncias travadas.
Essas checagens não são testes end-to-end completos. Não devem reproduzir fluxos inteiros ou chamar todas as dependências a cada probe. Mantenha-as pequenas e focadas nas poucas coisas que têm de ser verdade para o app servir tráfego com segurança.
Comece com o que precisa funcionar para os usuários
Uma checagem de saúde só é útil se corresponder ao que os usuários realmente fazem. Antes de escrever readiness e liveness, anote as poucas ações que definem “o app funciona” para seu produto. Se essas ações falham, usuários estão quebrados mesmo se seu endpoint retornar 200.
Mantenha a lista pequena e real: entrar e carregar o dashboard, criar um projeto ou pedido, fazer upload de arquivo e vê-lo aparecer, disparar um job ou enviar uma mensagem, concluir o checkout (se houver pagamentos).
Agora mapeie cada ação para o que ela precisa. “Criar um projeto” geralmente significa que o banco é gravável e migrations foram aplicadas. “Enviar um arquivo” pode precisar de object storage mais um worker de background para processá-lo. “Enviar uma mensagem” pode depender de a fila ser alcançável e consumidores estarem rodando.
A partir desse mapa, escolha as verificações mínimas que melhor representam “os usuários conseguem completar o caminho”. Um ping no banco não basta se gravações estão bloqueadas. Uma conexão com a fila não basta se publicar falha. Mire em uma ou duas checagens por caminho crítico, usando as dependências que mais frequentemente quebram a experiência.
Por fim, decida o que significa “degradado mas utilizável”. Usuários podem navegar mas não criar? Podem entrar mas uploads estão temporariamente desativados? Faça essa escolha de propósito, porque ela controla o comportamento de readiness (o app deve receber tráfego ou não).
Um cenário simples: seu app carrega bem, mas projetos novos nunca aparecem porque o worker não consegue enfileirar jobs. Seu endpoint de saúde da UI ainda diz “OK”. Uma readiness que inclua um enqueue leve (ou uma verificação de publish) pega a falha que os usuários sentem.
O que verificar: BD, fila e suas dependências críticas
Um endpoint de saúde útil deve responder a uma pergunta: se você mandar uma requisição real de usuário agora, ela vai funcionar? Isso significa que readiness (e qualquer endpoint de integridade de dependência que você adicione) precisa tocar as mesmas dependências que seu app precisa para fazer seu trabalho, não apenas retornar “OK” porque o servidor web está rodando.
Banco de dados
Comece simples e seguro. Verifique que você consegue conectar com as mesmas credenciais que o app usa e execute uma pequena query apenas de leitura como SELECT 1. Isso pega rede quebrada, senhas expiradas e strings de conexão mal configuradas. Mantenha rápido e não bloqueie tabelas ou rode migrations a partir de uma probe.
Fila e trabalho em background
Se seu app depende de jobs em background, checar apenas a API não é suficiente. Sua probe deve confirmar que você pode publicar uma mensagem de teste (ou pelo menos autenticar no broker) e que workers estão realmente consumindo. Também monitore backlog que só cresce, porque uma fila pode estar “up” enquanto o trabalho está efetivamente travado.
Um conjunto prático inicial é:
- Conexão com BD + uma query leve
- Publicação na fila (e idealmente um sinal de consumo de um worker)
- Uma chamada interna crítica que você não consegue operar sem
- Uma chamada de API externa que seu fluxo principal depende
- Sanidade de configuração: env vars obrigatórias presentes e segredos corretamente apontados
APIs externas merecem cuidado extra. Você não está testando a internet inteira, mas deve saber se credenciais são inválidas, DNS está quebrado ou respostas desaceleraram demais.
Um exemplo concreto: um cadastro escreve uma linha de usuário e depois enfileira um job “enviar e-mail de boas-vindas”. Se o check do banco passa mas a fila não aceita mensagens, usuários podem “se cadastrar” e nunca receber e-mails de verificação. Uma readiness que inclua a fila bloqueia tráfego até que esse caminho funcione, em vez de permitir falhas silenciosas.
Passo a passo: construir uma readiness que bloqueia tráfego
Uma readiness deve responder: esta instância pode tratar requisições reais de usuário agora? Se não, deve falhar para segurar novo tráfego.
1) Prove o mínimo que importa
Comece com a menor operação de banco que ainda prova que o app pode funcionar. Uma conexão TCP não é suficiente. Prefira uma query pequena que use as mesmas credenciais, esquema e caminho de rede que seu app usa.
Um padrão comum é um endpoint /ready que roda uma query rápida e verifica uma ou duas dependências críticas.
- Rode uma query leve no BD (por exemplo,
SELECT 1) usando a conexão normal do app. - Configure timeouts rígidos (centenas de milissegundos, não segundos) para que falhas apareçam rápido.
- Se o BD estiver inacessível ou estourar o timeout, retorne “not ready” para que o load balancer mantenha o tráfego distante.
- Inclua uma razão legível no corpo da resposta, mas nunca exponha segredos, strings de conexão ou dumps de erro completos.
- Adicione um período de graça na inicialização para que cold starts não causem flapping enquanto o app aquece.
2) Torne falhas óbvias (mas seguras)
Retorne um código de status claro (como 503) e um payload pequeno e seguro:
{ "ready": false, "reason": "db_timeout" }
Esse campo reason economiza tempo em incidentes porque aponta a dependência com problema sem expor dados privados.
3) Conecte de fato para bloquear tráfego
No Kubernetes, readiness controla se um pod recebe tráfego. Garanta que seu app só reporte ready depois de conseguir completar aquela operação real.
Passo a passo: construir uma liveness que aciona restarts
Uma liveness responde: este processo ainda está progredindo ou está travado? Se estiver travado, um restart costuma ser o caminho mais rápido de volta para os usuários.
- Escolha um “sinal de progresso” que prove que o app não está wedged. Bons sinais são locais e simples: um timestamp de watchdog atualizado pelo loop principal, ou “tempo desde a última requisição finalizada”.
- Mantenha leve e local. Uma liveness não deve chamar banco, fila ou serviços externos. Falhas de rede causariam restarts desnecessários.
- Adicione thresholds para evitar loops de restart. Prove regularmente, mas exija múltiplas falhas antes de declarar o container morto. Também adicione um período de graça na inicialização.
- Logue a razão antes de falhar. Escreva uma linha clara com o sinal de travamento e alguns contadores chave (tarefas pendentes, threads ocupadas, memória).
- Teste sob estresse real, não só em dev. Simule alta carga, chamadas downstream lentas e payloads grandes. Muitos apps parecem bem até pools de threads encherem e o processo parar de responder.
Exemplo: um serviço aceita HTTP mas todas as threads de worker estão bloqueadas em um lock em deadlock. Requisições pendem, usuários veem roda-gigante, e readiness pode continuar verde. Uma liveness que monitora “tempo desde a última requisição concluída” detecta o travamento e aciona um restart.
Feitas corretamente, readiness e liveness trabalham juntas: readiness protege usuários de dependências quebradas, e liveness resgata você de código travado.
Timeouts, retries e thresholds que se comportam em produção
Probes de saúde devem ser rápidas e entediantes. Se uma probe demora demais, requisições se acumulam, seu app faz trabalho extra e a própria probe pode virar a causa do outage. Para a maioria dos apps, mire um timeout curto (frequentemente 1–2s) e uma quantidade pequena e fixa de trabalho por probe.
Evite retries pesados dentro da probe. Retries podem esconder falhas reais e adicionar carga quando sistemas já estão sofrendo. Se o banco está expirando, uma probe que tenta três vezes pode ainda retornar sucesso às vezes, mas também bate mais no banco no pior momento.
Thresholds simples que separam blips de outages
Em vez de retry dentro da probe, use thresholds simples no orquestrador. No Kubernetes isso geralmente significa permitir algumas falhas antes de agir.
Um ponto de partida prático:
- Readiness timeout: 1–2s, failureThreshold: 2–3
- Liveness timeout: 1–2s, failureThreshold: 3–5
- periodSeconds: 5–10 (não probe a cada segundo a menos que precise)
- successThreshold: 1
Pense nisso como um pequeno orçamento de falhas: uma resposta lenta não deve causar caos, mas falhas repetidas devem.
Unready vs morto: escolha a ação menos disruptiva
Readiness e liveness não são a mesma alavanca. Se uma dependência está down, o movimento mais seguro geralmente é marcar o app como unready para que pare de receber tráfego. Reiniciar raramente corrige um banco ou fila quebrada e pode atrasar a recuperação.
Use readiness para dizer: “não consigo servir usuários corretamente agora.” Use liveness para dizer: “estou travado e preciso reiniciar.”
Erros comuns que criam falso-verdes (ou flapping constante)
A maioria das checagens falha por uma de duas razões: são rasas demais (tudo “OK” enquanto usuários não conseguem logar) ou profundas demais (falham com oscilações normais e disparam restarts).
Um falso-verde clássico é uma probe que só prova que o servidor web está up. Se o app aceita HTTP mas não consegue ler do BD, publicar na fila ou carregar config essencial, usuários continuam quebrados.
Os erros que mais aparecem:
- Usar um fluxo end-to-end como liveness (login + BD + fila + API externa). Quando qualquer dependência tisca, o orquestrador mata um processo saudável e causa downtime auto-infligido.
- Fazer readiness depender de terceiros instáveis. Se uma API de pagamento ou e-mail estiver lenta por 30s, você pode flutuar entre ready e not-ready e perder tráfego. Prefira sinais mais suaves (último-sucesso em cache, estado do circuit breaker) em vez de falhar duro sempre.
- Logar ou retornar dumps de erro crus. Endpoints de saúde são lugares tentadores para imprimir stack traces, connection strings e tokens. Mantenha respostas mínimas e higienizadas.
- Dizer “ready” antes do app ser utilizável. Causas comuns: migrations ainda rodando, caches não aquecidos, workers não conectados, ou consumidor de fila parado.
- Ignorar timeouts e thresholds. Uma probe sem timeouts apertados pode acumular requisições. Uma probe sem threshold de falha pode oscilar constantemente.
Mantenha liveness rasa (o processo está travado?) e readiness honesta (pode servir usuários com segurança?).
Torne falhas fáceis de ver e agir
Uma probe que falha silenciosamente é quase tão ruim quanto uma que sempre retorna OK. Quando readiness e liveness falham, você quer que um operador saiba o que quebrou, quão espalhado está e o que o sistema está fazendo a respeito.
Logue falhas de probe com um código de erro curto e estável. Mantenha o conjunto de códigos pequeno e consistente para que possa ser buscado e graficado. Inclua uma frase de contexto e evite despejar stack traces em toda falha.
Saídas úteis de probe costumam incluir um código estável (como DB_CONN_TIMEOUT ou QUEUE_AUTH_FAILED), o nome da dependência e a operação que falhou (connect, query, publish, consume) e um status básico como ready ou not-ready. Se usar degraded, seja claro sobre o que isso significa e qual tráfego ainda é seguro.
Teste que “not-ready” tem efeito. Force uma falha real em dependência (por exemplo, revogue credenciais da fila em staging). Confirme que a instância é removida do tráfego e para de receber requisições. Se usuários ainda a atingirem, seu sinal de readiness não está conectado ao roteamento como você pensa.
Seja igualmente rigoroso com restarts. Uma falha de liveness deve disparar reinícios apenas quando o processo estiver realmente travado. Se um blip de banco causa reinícios repetidos, você transformou um problema de dependência em um outage.
Um exemplo concreto: logins falham porque o banco está alcançável mas migrations não rodaram. O app retorna HTTP 200 em /health, ainda assim todo login lança erro. Uma readiness melhor reportaria not-ready com MIGRATION_PENDING, mantendo instâncias quebradas fora do tráfego.
Checklist rápido antes de colocar probes em produção
Antes de confiar em readiness e liveness em produção, confirme que suas probes falham pelas mesmas razões que usuários reais falham. Se uma dependência está down, a probe deve reportar isso rápido e claramente.
Readiness deve bloquear tráfego quando dependências centrais quebrarem: BD inacessível, credenciais erradas, ou uma query simples expirando. Verificações de fila devem refletir fluxo real de mensagens, não apenas “consigo alcançar o servidor”. Toda probe precisa de timeout rígido. Respostas de falha devem ser seguras para expor (códigos e razões curtas, sem stack traces ou segredos). E deploys não devem flapar, então adicione um período de graça na inicialização para trabalhos de aquecimento.
Um teste em staging que vale a pena
Simule uma queda real: bloqueie acesso ao banco por alguns minutos, ou pare seus workers de fila. Confirme que a readiness fica vermelha rapidamente, o tráfego para e o app recupera limpo quando a dependência retorna.
Exemplo: o app parece ok, mas a fila está quebrada
Uma falha comum é assim: usuários fazem pedidos, o checkout retorna 200 e seu endpoint “health” responde “OK”. Mas clientes nunca recebem confirmações de pedido e tickets de suporte se acumulam.
O que aconteceu? O web app ainda atende requisições, mas o caminho da fila está quebrado. Talvez o app não consiga publicar por credenciais ruins. Talvez a fila esteja up mas com backlog enorme, então mensagens não serão processadas por horas. Por fora, o app parece ok.
É aí que readiness e liveness importam. A probe antiga só prova uma coisa: o servidor web responde. Uma readiness melhor age como uma sonda de integridade de dependência e verifica o que precisa funcionar para usuários reais.
Uma readiness simples para esse caso:
- Tente uma publicação leve na fila (ou uma chamada de permissão) com timeout curto.
- Opcionalmente cheque lag da fila (como idade da mensagem mais antiga) e falhe readiness se cruzar um limiar.
- Retorne “not ready” para que o tráfego pare de ir para essa instância até o caminho da fila estar saudável novamente.
Liveness é diferente. Se o worker da fila está travado (deadlock, leak de memória, loop de mensagem envenenada), você normalmente quer que o processo worker seja reiniciado enquanto o processo web pode continuar vivo. Isso costuma significar probes separadas: mantenha o container web vivo e deixe o container worker falhar liveness quando parar de progredir.
Trate o follow-up como investigação, não achismo. Logue a falha exata (publish timeout, erro de autenticação, pico de backlog), então isole a causa: serviço de fila, credenciais, policy de rede ou código do consumidor.
Próximos passos: melhore probes, depois corrija as causas raízes
Se seus endpoints de saúde existem, o próximo passo é torná-los úteis. Boas readiness e liveness não só reportam que o processo está rodando. Elas pegam quebras reais cedo e impedem que pods quebrados sirvam usuários.
Anote o que precisa funcionar para que o usuário complete a ação principal no seu app (entrar, pagar, enviar, mandar mensagem). Escolha as três principais dependências que devem estar saudáveis para essa ação ter sucesso. Para cada uma, adicione uma checagem única que prove que o app realmente consegue usá-la, não só alcançar um hostname.
Depois disso, corrija o que as probes revelarem. Se a readiness falha porque conexões DB vazam, a probe está fazendo seu trabalho. O trabalho é fechar conexões, definir limites de pool, lidar com timeouts e falhar com erros claros. Se checagens de fila falham porque mensagens se acumulam, investigue consumidores, lógica de retry e dead-letter handling.
Se você herdou um protótipo gerado por IA que parece “verde” em checagens básicas mas quebra sob tráfego real, uma auditoria focada ajuda. FixMyMess (fixmymess.ai) se especializa em pegar apps gerados por IA e consertar problemas como auth quebrado, segredos expostos e jobs em background não confiáveis, muitas vezes começando por uma auditoria de código gratuita para revelar o que realmente falha em produção.
Perguntas Frequentes
Por que meu endpoint /health diz OK quando usuários não conseguem entrar ou pagar?
Um endpoint básico /health normalmente só prova que o processo web consegue responder. Os usuários podem continuar bloqueados se o banco de dados estiver travado, credenciais expiradas, migrations pendentes ou a fila travada. Uma verificação útil deve refletir se o app consegue completar o trabalho mínimo do qual os usuários dependem.
Qual é a maneira mais simples de explicar readiness vs liveness?
Readiness significa “esta instância deve receber tráfego agora?” e deve falhar quando dependências chave necessárias para requisições reais não estão utilizáveis. Liveness significa “o processo está travado de uma forma que um restart resolveria?” e só deve falhar quando o app parou de progredir, não quando uma dependência está brevemente indisponível.
O que uma verificação de readiness deve fazer para o banco de dados?
Comece com uma operação mínima que use o mesmo caminho que seu app, por exemplo rodar SELECT 1 com a conexão normal e um timeout rígido. Isso detecta rede quebrada, credenciais erradas e muitas quedas de BD. Se seu fluxo principal exige gravações, considere um sinal seguro ligado a escrita (como checar se migrations foram aplicadas) em vez de apenas uma leitura.
Como incluir a fila na readiness sem tornar as probes pesadas?
Se o app depende de jobs em background, sua probe de readiness deve verificar que o app consegue publicar na fila (ou pelo menos realizar uma checagem de permissão/handshake) com timeout curto. É aí que “tudo está up” mas confirmações, e-mails ou processamento assíncrono falham silenciosamente. Mantenha leve para não gerar carga extra durante incidentes.
Minha liveness deve chamar o banco de dados ou APIs externas?
Evite chamar serviços externos na liveness porque pequenos problemas de terceiros podem disparar loops de reinício e piorar a indisponibilidade. Liveness deve ser local: um timestamp de watchdog, batida de coração do loop de eventos ou “tempo desde a última requisição concluída” costuma ser suficiente. Use readiness para refletir saúde de dependências externas.
Como devo configurar timeouts e retries para probes de readiness e liveness?
Use timeouts apertados para probes falharem rápido e deixe o orquestrador lidar com pequenos picos via thresholds de falha. Isso reduz tráfego de probes durante quedas parciais e evita mascarar problemas reais com retries internos. Se uma dependência está lenta, geralmente é melhor ficar unready rapidamente do que manter pods parcialmente funcionais em rotação.
Como evito que readiness flape quando uma API terceirizada é instável?
Um erro comum é fazer readiness depender de um terceiro instável, o que causa ready/unready constantes e perda de tráfego. Outra é ter probes que fazem trabalho demais, transformando checagens em mini testes de carga. Mantenha readiness focado no que precisa ser verdadeiro para servir usuários com segurança e trate integrações opcionais como “degradadas” em vez de forçar not-ready a cada instabilidade.
O que meus endpoints de saúde devem retornar quando algo está errado?
Retorne um código de status claro (frequentemente 503) e uma string de razão curta e estável como db_timeout ou queue_auth_failed. Faça o mesmo código aparecer nos logs uma vez por janela de falha para ser pesquisável sem encher os logs. Nunca inclua stack traces, tokens, connection strings ou dumps brutos de exceção nas respostas das probes.
Meu app pode ficar “degradado mas utilizável”, e como a readiness deve lidar com isso?
Sim — se for um trade-off intencional para seu produto. Você pode permanecer ready para navegação somente leitura enquanto desabilita ações de criação, mas isso exige que o app imponha as mesmas regras para que usuários não encontrem caminhos quebrados. Se não conseguir separar com segurança “seguro” de “inseguro”, falhe na readiness e pare de receber tráfego até o caminho principal voltar a funcionar.
Meu app foi gerado por uma ferramenta de IA e quebra em produção — vocês podem ajudar?
Apps gerados por ferramentas de IA frequentemente “rodam” mas quebram em produção devido a auth, segredos, migrations e jobs em background — coisas que checagens básicas não pegam. FixMyMess (fixmymess.ai) foca em diagnosticar e reparar essas falhas de produção, incluindo endurecer probes para que deploys ruins não prejudiquem usuários silenciosamente. Se não souber por onde começar, uma auditoria de código gratuita pode rapidamente mostrar os pontos reais de falha.