Аудит затрат для прототипов на ИИ: сократите расходы на API и БД
Аудит затрат для прототипов на базе ИИ помогает выявить эндпоинты, запросы и фоновые задачи, которые раздувают счёт, и быстро устранить основные проблемы.
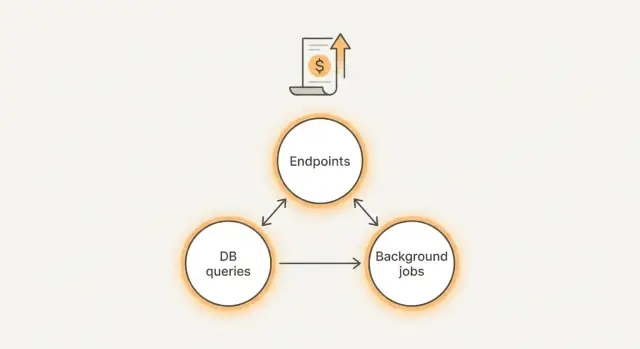
Что на самом деле формирует ваш счёт?
Многие прототипы, созданные с помощью ИИ, становятся дорогими по простой причине: они хорошо выглядят на демо, но в фоне тратят деньги впустую. Генераторы кода часто дублируют вызовы, пропускают кеширование и добавляют «полезный» опрос, который никогда не останавливается. Вы не замечаете этого, пока не придут реальные пользователи или несколько тестировщиков не оставят приложение открытым на весь день.
Большая часть неожиданных трат происходит в трёх местах:
- Эндпоинты: один экран запускает слишком много API-вызовов, ретраев или возвращает излишне большие ответы.
- Запросы: медленные или неограниченные запросы к базе, которые сканируют куда больше данных, чем нужно.
- Фоновые задачи: cron, воркеры очередей и вебхуки, которые запускаются слишком часто или никогда не останавливаются.
«Хорошие» траты — скучные. Они прогнозируемы и растут вместе с реальной активностью продукта. Если у вас в 10 раз больше активных пользователей, расходы могут вырасти, но это логично. «Плохие» траты растут, когда никто ничего не делает, или когда одна фича тихо запускает сотни вызовов.
Если у вас есть только 30 минут, измерьте несколько вещей, которые быстро покажут проблему:
- Топ эндпоинтов по количеству запросов и среднему размеру ответа
- Самые медленные и самые частые запросы к БД
- Фоновые задачи по частоте запусков и среднему времени выполнения
- Вызовы сторонних API по эндпоинту и по частоте ошибок или ретраев
- Базовый уровень расходов в часы «никто не использует"
Быстрая проверка реальности помогает: откройте приложение, выполните одно обычное действие (например, загрузите дашборд) и посмотрите, что срабатывает. Если одно действие запускает 20 запросов, три длинных запроса и всплеск в очереди задач, вы нашли отправную точку.
Привяжите расходы к реальным фичам (а не к расплывчатому «использованию")
Дашборды, показывающие «API вызовы» или «чтения БД», не говорят, что именно исправлять. Это становится проще, когда вы переводите траты в реальные действия пользователя.
Сделайте простой «карту затрат"
Запишите несколько действий, которые могут легитимно стоить денег, и относитесь ко всему остальному как к подозрительному, пока не докажут необходимость. Для многих прототипов это:
- Регистрация и вход (email, SMS, OAuth)
- Поиск и фильтры
- Чат или генерация контента
- Отчёты и экспорт
- Загрузка файлов и обработка
Прикрепите грубые ожидания к каждому действию: «Отправка чат-сообщения должна стоить меньше чем X», или «Запуск отчёта должен занимать меньше Y секунд». Вам не нужны идеальные числа — нужны цели, которые делают очевидной расточительность.
Далее разделите пользовательские траты и всегда-работающие траты.
Пользовательские траты происходят только при действии человека. Всегда-работающие траты идут, даже когда никто не пользуется приложением: cron, воркеры, фоновый опрос, автоповторы и «health checks», которые попадают на дорогие эндпоинты. Всегда-работающие траты часто дают самый быстрый выигрыш, потому что сжигают деньги 24/7.
Также проверьте, в каком окружении тратятся деньги. Приложения на ИИ часто указывают dev или staging на те же платные сервисы, что и production, или оставляют тестовые воркеры работать ночью. Если вы не можете чётко сказать «это прод», предполагайте, что часть расходов не продовая.
Установите цель перед тем, как лезть в код:
- Сократить 20% на этой неделе (выключить самое большое расточительство)
- Сократить 80% за месяц (переработать архитектуру, кеширование и доступ к данным)
Типичный пример: фича «отчёт» используется раз в день, а фоновая задача генерирует её каждые 5 минут для каждого аккаунта. Дашборд показывает «высокое использование БД», но реальная проблема — фича, которой никто не просил, работает постоянно.
Шаг за шагом: инвентаризация эндпоинтов, запросов и задач
Цель — перестать догадываться. Вам нужна карта всех мест, где приложение тратит деньги, привязанная к реальным запросам и реальной работе.
Выберите один обычный день трафика и используйте его как базу. Если трафика немного, возьмите день внутреннего тестирования, где вы прогоняете основные сценарии (регистрация, оплата, поиск, чат, загрузки). Сохраните эту базу, чтобы сравнивать после изменений.
Сделайте одностраничную инвентаризацию
Пройдитесь по приложению в трёх группах: эндпоинты, запросы к БД и фоновая работа.
- Эндпоинты
- Перечислите все API-маршруты (включая внутренние) и отметьте, кто их вызывает: браузер, мобильное приложение, cron, вебхук или другой сервис.
- Добавьте грубый объём и задержку. Точные числа — отлично, но «высокий/средний/низкий» и «быстро/медленно» достаточно, чтобы найти первые проблемы.
- Запросы
- Для каждого эндпоинта зафиксируйте топ запросов к БД, которые он триггерит.
- Выберите образцы из логов, трассировки или представления медленных запросов в БД и опишите форму запроса (какие таблицы затронуты, фильтры, join-ы).
- Фоновая работа
- Запишите каждую запланированную задачу, обработчик вебхука и воркер очереди.
- Укажите, как часто она запускается и что делает (синхронизация, отправка писем, embeddings, очистка).
Держите всё привязанным к дню-базе, чтобы оценить стоимость на 1,000 запросов или на активного пользователя.
Когда список готов, шаблоны выпрыгивают: один эндпоинт вызывается при каждой загрузке страницы, «маленький» запрос сканирует большую таблицу, или фоновая задача выполняется каждую минуту, даже когда ничего не меняется.
Эндпоинты, которые тихо дорожают
Некоторые из крупнейших утечек скрываются в «нормальных» эндпоинтах, которые вызывают много раз в день. Часто бэкенд не дорогой на запрос, он дорог потому, что один и тот же запрос повторяется сотни или тысячи раз.
Распространённый виновник — опрос: фронтенд проверяет обновления каждые несколько секунд, даже когда ничего не меняется. Петли обновления могут происходить случайно, например, когда страница ререндерится и триггерит новый fetch, или когда два компонента вызывают один и тот же эндпоинт, не зная друг о друге. Если пользователи держат вкладку открытой, этот тихий цикл становится постоянным счётчиком.
Другой паттерн — эндпоинт, который делает слишком много работы за один запрос. ИИ-сгенерированный код может упаковать несколько lookups, лишние join-ы или обработку файлов в один маршрут «для удобства». В демо это работает, но каждый вызов запускает цепочку запросов к БД и сторонним API.
Чтение-интенсивные маршруты становятся дорогими при отсутствии кеширования. Если эндпоинт возвращает одинаковые данные для многих пользователей (цены, настройки, список шаблонов), вы платите повторно за идентичные чтения.
Ретраи умножают расходы быстро. Если тайм-ауты слишком короткие или нет лимитов, клиенты могут ретраить агрессивно. В итоге вы платите дважды (или больше) за одно и то же действие.
Несколько признаков, что эндпоинт стоит проверить в первую очередь:
- Он вызывается по таймеру (polling) или на каждое нажатие клавиши
- Триггерит несколько downstream-вызовов (БД плюс внешние API)
- Часто возвращает одинаковый ответ, но без кеша
- Иногда тайм-аутится, и клиенты автоматически повторяют попытки
- Нет rate limit, поэтому всплески превращаются в дорогие пики
Пример: эндпоинт /messages в прототипе чат-бота вызывается каждые 2 секунды, чтобы проверить новые ответы. Кроме того, он пересчитывает контекст беседы и делает несколько обращений к БД. Исправление частоты вызовов и перенос тяжёлой работы из запроса сразу сокращают расходы.
Запросы, которые взрывают расходы базы данных
Траты на БД часто идут от небольшого числа запросов, которые выполняются намного чаще, чем вы думаете. ИИ-сгенерированный код может скрывать неэффективность за ORM, поэтому приложение выглядит нормально в тестах, но дорожает при реальном трафике.
Один из крупнейших виновников — паттерн N+1: вы получаете список элементов, а затем код тихо запрашивает связанные данные по одной строке внутри цикла. Страница с 50 заказами может превратиться в 51 запрос (или 201, если каждый заказ подтягивает customer и items), и каждое обновление повторяет работу.
Отсутствие индексов — ещё один множитель. Если вы фильтруете по полям вроде user_id, created_at или status, или делаете join по внешним ключам, база не должна сканировать всю таблицу каждый раз. При отсутствии индекса затраты растут с увеличением данных, поэтому ситуация ухудшается каждую неделю.
Также следите за запросами, которые тянут слишком много. Выбор всех колонок, загрузка больших JSON-блобов или возврат тысяч строк, когда UI показывает первые 20, тратит CPU, память и сеть впустую. Поиск, ленты активности и админ-таблицы — частые нарушители, особенно когда забывают пагинацию.
Пять проверок, которые обычно выявляют худшие всплески:
- Ищите повторные чтения внутри циклов (N+1) в логах или трассировках
- Проверьте наличие индексов для часто используемых фильтров и ключей join
- Выбирайте только нужные колонки, а не
SELECT * - Добавьте пагинацию и жёсткие лимиты для скролла и поиска
- Убедитесь, что подключено пуление соединений, чтобы не открывать новое соединение к БД на каждый запрос
Пример: прототип чат-бота хранит сообщения и «подгружает последние 5,000» при каждом просмотре страницы, чтобы собрать контекст. Изменение на выборку последних 30 сообщений, индексация conversation_id и батчинг связанных выборок быстро снизят нагрузку на БД.
Фоновые задачи, которые запускаются чаще, чем вы думаете
Фоновые задачи — частая причина, по которой прототип на ИИ выглядит дешёвым в тестах, а в проде становится дорогим. Они запускаются, когда никто не использует приложение, и часто касаются самых дорогих частей стека: внешних API, базы данных и файлового хранилища.
Начните с перечисления каждой задачи по расписанию и запишите её частоту простым языком. «Каждую минуту» и «каждые 5 минут» — обычные убийцы бюджета, особенно если задача вызывает платные API или сканирует большие таблицы.
Далее ищите задачи, которые выполняются, даже когда нет работы. Типичный пример — задача синхронизации, которая проверяет новые данные, но всё равно вытаскивает тысячи строк или вызывает API, даже если ничего не изменилось. Простые проверки перед дорогой частью часто достаточно, чтобы остановить утечку.
Поведение fan-out — ещё один тихий множитель. Одна запланированная задача может поставить в очередь работу на каждого пользователя, рабочее пространство или запись. Если она выполняется почасово и у вас 2,000 пользователей, вы вдруг запускаете 48,000 задач в день.
Несколько исправлений, которые обычно быстро режут расходы:
- Добавьте проверку «нет работы» (длина очереди, время последнего обновления или дешёвый count) перед любой тяжёлой операцией или вызовом API
- Ограничьте fan-out батчами (обрабатывать по 100 записей за раз) и делайте backoff при загруженности
- Сделайте задачи идемпотентными, чтобы повторные попытки не повторяли дорогую работу (уникальный ключ задачи или маркер обработанного)
- Логируйте количества и длительности: элементов обработано, API вызовов сделано, строк просканировано, общее время выполнения
Как выбрать несколько правок, которые быстро режут расходы
Аудит имеет смысл только если превращается в короткий, сфокусированный план. Цель не в том, чтобы всё сделать идеально, а убрать пару горячих точек, которые формируют большую часть счёта.
Для каждой потенциальной правки запишите две вещи: насколько она сложна и сколько может сэкономить. Держите подход лёгким, чтобы быстро принимать решения.
- Добавить лимиты запросов к дорогим эндпоинтам (малые усилия, большие экономия)
- Кешировать ответы для чтение-интенсивных эндпоинтов на 60 секунд (малые усилия, средняя–высокая экономия)
- Добавить индекс в БД для топового запроса (средние усилия, высокая экономия)
- Уменьшить частоту опроса в воркере или UI (малые усилия, средняя–высокая экономия)
- Переработать целый модуль (большие усилия, неоднозначная экономия)
Приоритизируйте исправления, которые уменьшают один из драйверов:
- Количество API-вызовов (меньше запросов, меньше ретраев, меньшие ответы)
- Количество просканированных строк (быстрее запросы, меньше полных сканов)
- Частоту задач (меньше опросов, реже запланированные запуски)
Быстрые ограничения обычно побеждают первыми. Поставьте пределы на абузные паттерны (rate limits, тайм-ауты, max page size). Добавьте кеш там, где данные не меняются каждую секунду. Для фоновой работы переключитесь с «проверять каждую минуту» на «запускать при необходимости» или увеличьте интервал.
Используйте правило остановки: выпустите 2–3 изменения, затем померьте снова в течение дня (или обычного бизнес-цикла). Если вы не видите значительного падения, вернитесь к инвентаризации. Большие переписывания соблазнительны, но часто пропускают реальный драйвер затрат.
Пример: если прототип чат-бота повторно отправляет всю переписку при каждом сообщении, небольшое изменение, например суммаризация старых сообщений или ограничение истории, сократит расход токенов быстрее, чем перестройка всей фичи чата.
Пример: прототип чат-бота с неконтролируемыми расходами
Типичный случай: прототип Lovable или Bolt с простым экраном чата и дашбордом для «использования» и «истории». В демо всё работает, но счёт растёт быстрее, чем количество пользователей.
Вот паттерн. Каждая загрузка страницы запускает несколько AI-вызовов «на всякий случай» (суммаризация, предложенные подсказки, сентимент, генерация заголовка). Одновременно дашборд выполняет полные сканы таблиц, чтобы пересобрать статистику с нуля. Несколько активных тестировщиков создают сотни вызовов в час, и база начинает делать тяжёлые чтения, выглядящие как случайные всплески.
Часто главный виновник — один эндпоинт чата, который повторяет работу по созданию embeddings при каждом сообщении, иногда больше одного раза за запрос. Он может встраивать текст пользователя, повторно встраивать последние N сообщений и повторно встраивать те же фрагменты базы знаний, потому что ничего не кешируется. Если эндпоинт также сохраняет всё и затем немедленно запрашивает «все сообщения для этого пользователя» без ограничений, стоимость запросов растёт с каждой беседой.
Исправления, которые обычно режут расходы, скучные, но эффективные:
- Дебаунс триггеров UI, чтобы одно действие пользователя делало один запрос, а не пять
- Кешировать embeddings и переиспользовать их, если текст не изменился
- Добавить пагинацию и лимиты к истории сообщений и таблицам дашборда
- Перенести «приятные дополнения» AI (заголовки, суммаризации) в запланированные задачи, которые выполняются реже
- Добавить защитные меры: тайм-ауты, max tokens и rate limits на пользователя
Результат, на который стоит смотреть — меньше вызовов на одно действие пользователя и более плоская кривая расходов. После этих изменений вы должны предсказывать расходы по активным пользователям, а не быть удивлёнными из-за одного занятого послеобеденного периода.
Распространённые ошибки при аудите затрат
Аудит может пойти не туда, если вы воспринимаете его как упражнение в таблицах, а не как охоту за несколькими вещами, которые генерируют большую часть счёта. Цель — не идеальные измерения, а быстрые безопасные экономии.
Одна ловушка — собирать кучу метрик и при этом пропускать очевидное. Команды отслеживают каждый маршрут, каждую таблицу, каждый дашборд, а потом не делают ничего с самыми большими нарушителями. На практике ваши топ-5 эндпоинтов и топ-5 запросов часто объясняют большую часть расходов.
Ещё одна ошибка — исправлять неправильный слой. Можно оптимизировать медленный запрос, но если фоновая задача вызывает его каждую минуту (или запускается дважды из-за ретраев), счёт не сдвинется. Всегда подтверждайте, что триггерит работу: действия пользователя, расписания cron, вебхуки, ретраи или воркеры очередей.
Следите за этими паттернами провала:
- Вы отключаете фичу, чтобы сэкономить, но реальная проблема — циклические вызовы или клиент, который опрашивает слишком часто
- Вы оптимизируете один запрос, а экспорт или sync-job выполняет тот же запрос тысячи раз
- Вы гонитесь за экономией и случайно ломаете корректность (частичные данные, пропущенные записи, устаревший кэш)
- Вы пропускаете базовые проверки безопасности и выпускаете открытые секреты, слабую авторизацию или уязвимости к инъекциям
- Вы «решаете» проблему снижением лимитов, не разбираясь, почему приложение достигает этих лимитов
Пример: фича «уведомления» в прототипе кажется дорогой, поэтому её отключают. Позже выясняется, что настоящий виновник — воркер, который отправляет одну и ту же пачку повторно, потому что задача никогда не сохраняла своё контрольное состояние.
Быстрый чеклист: до и после изменений
Относитесь к этому как к небольшому эксперименту: сначала измерьте, потом поменяйте одну вещь, потом измерьте снова. Иначе вы рискуете «сэкономить деньги» на бумаге, но сломать вход, замедлить страницы или вызвать ретраи, которые будут стоить ещё дороже.
Выберите день-базу (или типичные 24 часа) и запишите числа в одном месте: общие расходы на API, расходы на БД и фоновые воркеры, плюс пару топовых нарушителей.
Перед изменениями убедитесь, что можете ответить на вопросы:
- Какие топ-3 эндпоинта по затратам и по объёму (запросы)?
- Какие топ-3 запроса по общему времени или просканированным строкам?
- Есть ли полный список запланированных задач, очередей и cron-ов, и как часто они запускаются?
- Записали ли вы «до» числа для базового окна (расходы, задержки, ошибки, ретраи)?
- Знаете ли вы, как выглядит «хорошо» для пользователей (время загрузки страницы, время до первого ответа, успешный вход или оплата)?
После изменений перепроверьте то же окно и добавьте две проверки: ретраи и пользовательский опыт. Частая ловушка — уменьшить вычисления на запрос, но ввести 500 ошибки, тайм-ауты или сбои авторизации, которые вызывают автоматические ретраи. Один сломанный эндпоинт может удвоить трафик и затраты без новых пользователей.
Также убедитесь, что вы не просто переместили расходы в другое место (например: меньше API-вызовов, но более тяжёлые запросы к БД, или меньше чтений БД, но больше фоновых задач).
Следующие шаги, если ваш прототип на ИИ сложно распутать
Если аудит показывает «всё дорого», проблема обычно в коде, а не в облаке. ИИ-сгенерированные проекты часто выходят с запутанной маршрутизацией, дублированной логикой и скрытыми ретраями. Прежде чем оптимизировать строка за строкой, сделайте короткую диагностику, чтобы картировать, что реально работает в проде и как текут запросы.
Начните с поиска горячих точек. Если есть 1–3 явных нарушителя (один шумный эндпоинт, один медленный запрос, одна избыточная задача), патч обычно даёт самый быстрый выигрыш. Если вы обнаружили десяток средних проблем по многим файлам, вы потратите больше времени на погоню за симптомами, и небольшая переработка зачастую дешевле.
Простое правило:
- Патчьте, когда исправление изолировано и тестируемо (rate limit для одного эндпоинта, кеш, исправление одного N+1)
- Рефакторьте, когда тот же паттерн повторяется (копипаст загрузки данных, несколько эндпоинтов делают одно и то же, задачи вызывают друг друга)
- Перестраивайте, когда фундаментальные вещи сломаны (auth ненадёжна, секреты открыты, архитектура мешает безопасным изменениям)
Если привлекаете стороннюю помощь, важнее передача дел, чем длинные объяснения. Принесите один базовый день (нормальные 24 часа трафика) и короткий пакет фактов:
- Список эндпоинтов с количеством запросов и худшими нарушителями
- Топ запросов с средним временем и частотой
- Список фоновых задач с расписанием и реальными числами запусков
- Недавние заметки по деплойам (что поменялось, когда расходы выросли)
Если код пришёл из инструментов вроде Lovable, Bolt, v0, Cursor или Replit и трудно проследить, что что вызывает, FixMyMess (fixmymess.ai) может сделать бесплатный аудит кода, чтобы замапить эндпоинты, запросы и задачи перед любыми правками. Дальше фокус — прямое устранение: исправление логики, усиление безопасности, рефакторинг и подготовка к деплою, чтобы прототип вёл себя как продакшен, а не как демо.
Часто задаваемые вопросы
Мой счёт за прототип на ИИ большой — что проверять в первую очередь?
Начните с того, что проверьте, что продолжает тратить деньги, когда никто активно не пользуется приложением. Сравните тихий ночной период с загруженным часом, затем найдите небольшое число горячих точек: несколько эндпоинтов с очень большим числом запросов, пара запросов к БД, которые занимают большую часть времени, и фоновые задачи с частым расписанием. Если расходы не падают во время «никто не использует» часов, самый быстрый выигрыш обычно даёт отключение всегда-работающей работы, а не пользовательских фич.
Как установить базовую линию перед тем, как менять код?
Выберите обычный 24-часовой период и зафиксируйте числа, которые можно легко перепроверить позже: общие затраты на API, затраты на базу данных и затраты фоновых воркеров, плюс главные нарушители по объёму и задержкам. Цель не в идеальном учёте, а в наличии снимка «до», чтобы понять, действительно ли изменения снизили расходы, а не просто переместили их.
Как привязать облачные расходы к реальной фиче, а не к расплывчатым метрикам?
Переведите «использование» в реальные действия пользователя: загрузка дашборда, отправка сообщения в чате, запуск отчёта или загрузка файла. Затем проследите, что вызывает каждое действие в проде: какие запросы отправляются, какие запросы к БД выполняются, всплески задач и обращения к сторонним сервисам. Когда одно простое действие запускает неожиданную цепочку работы, вы нашли, что нужно исправить дальше.
Почему опросы взрывают расходы даже при небольшом числе пользователей?
Опрос выглядит безобидно, потому что каждый запрос маленький, но он выполняется постоянно и умножается по открытым вкладкам и пользователям. Если UI проверяет данные каждые несколько секунд, хотя ничего редко меняется, расходы растут, даже когда продукт «бездействует». Обычное решение — сократить или убрать опрос и получать данные только при изменениях или по явному запросу пользователя.
Как повторные попытки и тайм-ауты тихо увеличивают мои расходы?
Повторы могут удвоить или утроить счёт, потому что вы платите за одну и ту же работу несколько раз. Это происходит, когда тайм-ауты слишком агрессивные, ошибки не обрабатываются корректно или клиенты автоматически повторяют запросы без ограничений. Обычно помогают здравые тайм-ауты, лимиты запросов, идемпотентность запросов и предотвращение повторных дорогостоящих действий при ошибках.
Что такое проблема N+1 и как её заметить?
Паттерн N+1 — это когда вы получаете список, а затем внутри цикла запрашиваете связанные данные по одной строке. На малых данных это не заметно, но это масштабируется плохо и быстро становится дорогим. Практическое решение — батчить такие выборки, чтобы одна загрузка страницы не порождала десятки или сотни отдельных запросов.
Когда добавление индекса в БД — лучшее решение для экономии?
Если вы фильтруете или делаете join по полям вроде user_id, created_at или status, а база каждый раз сканирует всю таблицу, вы увидите медленные запросы, которые с ростом данных становятся хуже. Добавление правильного индекса обычно даёт прямое и заметное снижение времени запросов и загрузки CPU. Важно индексировать те поля, по которым действительно фильтруют ваши топовые эндпоинты, а не то, что кажется важным.
Почему фоновые задачи создают расходы в «бездействие» ночью?
Потому что они выполняются, даже когда никто не использует приложение, и часто затрагивают самые дорогие части стека: базу, платные API и хранилище. Задача, которая запускается каждую минуту, может превратиться в постоянную утечку затрат, особенно если она сканирует много строк или делает fan-out по пользователям. Простая проверка «нет работы — не делать дорогую часть» и ограничение fanning обычно быстро сокращают расходы без вмешательства в пользовательский опыт.
Как решить: патчить, рефакторить или пересобирать?
Начните с изменений, которые легко протестировать и которые уменьшают явный драйвер — число запросов, просканированных строк или частоту задач. Патчьте, когда проблема изолированная и тестируема (лимитировать один эндпоинт, добавить кеш, исправить один N+1). Рефакторьте, когда паттерн повторяется во многих файлах. Перестраивайте, когда фундаментальные вещи сломаны (auth ненадёжен, секреты открыты, архитектура мешает безопасным правкам).
Что нужно подготовить, если я привлечу кого-то, чтобы починил дорогую кодовую базу, сгенерированную ИИ?
Принесите один базовый день данных и короткое резюме самых дорогих мест: какие эндпоинты шумят, какие запросы медленные и частые, какие фоновые задачи запускаются слишком часто. Если код сгенерирован инструментами вроде Lovable, Bolt, v0, Cursor или Replit и его трудно трассировать, FixMyMess может начать с бесплатного аудита кода и затем устранить горячие точки с человеческой проверкой. Большинство проектов решается за 48–72 часа с высокой долей успеха, цель — превратить демо-код в поведение, приемлемое для продакшена.