Blue‑green развёртывание для небольших приложений: безопасные переключения и откаты
Изучите blue‑green развёртывание для небольших приложений с двумя окружениями: безопасные переключения, быстрые откаты и практические советы по базе данных и сессиям.
Почему небольшие приложения всё ещё страдают от рискованных релизов
Небольшие приложения обычно падают по тривиальным причинам. Делаете маленькое изменение — и вдруг у всех не работает вход. Или фоновая задача запускается дважды и записывает дублированные строки. Или значение конфигурации указывает не на ту базу, и пользователи час получают ошибки.
Такие простые отказы кажутся несправедливыми, потому что приложение «небольшое». Но риск часто выше как раз в маленьких командах: меньше людей проверяет изменения, меньше времени на тесты, и нет никого на связи, кто мог бы срочно бросить всё и починить продакшен.
Худшие релизы ломают то, что трудно заметить локально. Авторизация и сессии могут сломаться из‑за недействительных cookie, неправильно настроенных callback или отклонённых токенов. Данные становятся уязвимыми, когда миграции блокируют таблицы или когда код начинает писать новые поля до их появления. Runtime‑настройки бьют, если секреты отсутствуют, переменные окружения неверны или сетевые правила отличаются от dev. И даже если всё ок в тихом тесте, реальный трафик может «свалить» endpoint, который в разработке выглядел нормально.
Blue‑green развёртывание снижает этот риск, не превращая релизы в громоздкую церемонию.
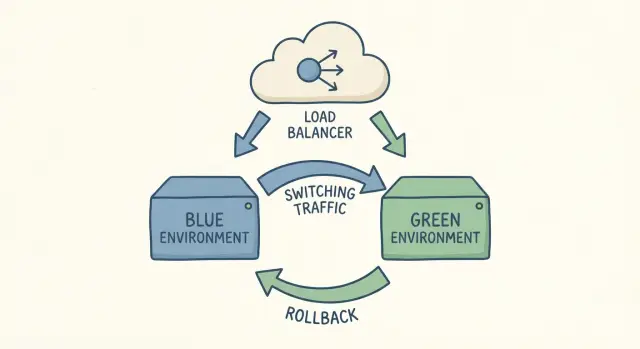
Под «двумя окружениями» обычно понимают две полные копии вашей продакшн‑настройки, запущенные одновременно: одна живёт с пользователями (blue), другая — версия, которую вы собираетесь выпустить (green). Обе должны использовать одинаковые типы серверов, одинаковые зависимости и продакшн‑похожие настройки. Главное — только одно из них принимает реальный трафик.
Переключение — это просто смена трафика с blue на green. Если что‑то пошло не так, вы возвращаете обратно. В этом и суть.
Речь не о тяжёлых процессах. Речь о том, чтобы иметь безопасное место, где можно проверить практические вещи перед тем, как пользователи заплатят ценой: работает ли вход, загружаются ли ключевые страницы, ведут ли себя фоновые задания и можно ли быстро откатиться, если что‑то упущено?
Типичный сценарий для маленького приложения — «быстрое» изменение, сделанное в спешке. На вашей машине всё работает, а в проде ломается из‑за других cookie, доменов или секретов. Когда green уже настроен в стороне, вы можете сначала проверить эти продакшн‑только детали, а затем переключить трафик, когда будете уверены.
Если кодовая база сгенерирована AI и уже хрупка, риск растёт. Команды часто наследуют сломанную авторизацию, открытые секреты и запутанную логику, которая ведёт себя иначе под реальным трафиком. Blue‑green не исправит плохой код сам по себе, но может не дать плохому деплою перерасти в длительный простой.
Blue‑green простыми словами
Blue‑green развёртывание — простая идея: держать две готовые к запуску копии приложения.
Blue — это та версия, на которой сейчас пользователи. Она обрабатывает реальный трафик. Green — новая версия, которую вы хотите выпустить. Вы собираете её, настраиваете и тестируете, пока blue продолжает обслуживать пользователей.
Когда вы уверены в green, выполняете контролируемое переключение трафика, чтобы пользователи начали попадать на green вместо blue. Обычно переключение делается в одном месте: правило балансировщика нагрузки или reverse proxy, swap окружений у хоста, настройка роутинга в контейнерном шлюзе или (менее идеально) DNS. DNS работает, но кеширование делает время переключения менее предсказуемым.
Главный выигрыш — скорость и уверенность. Если после переключения что‑то пошло не так, откат часто сводится к простому возврату трафика на blue. Не нужно срочно перестраивать старую версию — она уже там и уже работает.
Представьте простое SaaS‑приложение с логином, биллингом и дашбордом. Вы деплойте green с новой версткой дашборда, выполняете smoke‑тест на реальной инфраструктуре, затем переключаете трафик. Если клиенты жалуются на сломанные графики, вы возвращаетесь на blue за считанные минуты, пока чините green.
Blue‑green не решает всё волшебным образом. Наиболее частые проблемы — две области:
Миграции базы данных: если green требует новую таблицу или изменённые колонки, нужно планировать так, чтобы и blue, и green могли работать безопасно в переходный период.
Сессии и логины: если сессии хранятся в памяти каждого инстанса, пользователи могут быть выкинуты при переключении трафика. Общая сессия (или безсессионная авторизация) это предотвращает.
Когда blue‑green подходит (и когда — нет)
Blue‑green хорошо работает, когда вы хотите более безопасные релизы, но без сложного инструментария. Держите два продакшн‑похожие окружения, тестируете новое в реальных настройках, затем переключаете трафик.
Это особенно подходит, если приложение в основном stateless и изменения легко тестировать end‑to‑end. Часто это простые веб‑приложения, API с короткими независимыми запросами, внутренние инструменты с известным набором пользователей и ранние SaaS‑продукты, которые выпускают маленькие изменения часто. Также подходит, если вы можете позволить себе запускать две копии в окно релиза.
Простой пример: маленький SaaS с Next.js и API. Вы деплойте новую версию в green, быстро проверяете (вход, создание элемента, экспорт), затем переключаете трафик. Если что‑то идёт не так — возвращаетесь за минуты.
Это не лучший вариант, когда самая сложная часть релиза — база данных или когда работу нельзя безопасно дублировать между окружениями. Предупреждающие сигналы: частые переписывания схемы, блокирующие таблицы; длительные фоновые задачи, которые нельзя приостановить или дублировать; большое in‑memory состояние (WebSocket, кастомное хранение сессий) и побочные эффекты третьих сторон (платежи, письма), которые нельзя аккуратно повторить. Плохо идёт, если у команды нет письменного чеклиста cutover/rollback.
Есть стоимость: вы платите за две копии во время релиза. Для маленьких приложений это может быть дешево, но учитывайте удвоенную вычислительную нагрузку и дублирование сервисов (очереди, кеши), если они нужны.
Инструменты важны меньше, чем привычки команды. Короткий чеклист (кто переключает трафик, что проверять, что считаете триггером отката) предотвращает панику.
Что нужно перед попыткой
Blue‑green лучше работает, когда вы рассматриваете blue и green как два отдельных, полных копии продакшена. Если базовые вещи не налажены, вы всё ещё сможете переключить трафик, но не будете понимать, какая сторона на самом деле здоровая, и откат станет грязным.
Начните с конфигурации. Blue и green должны запускать один и тот же код, но нельзя по ошибке шарить не те секреты. Разделяйте переменные окружения, секреты и делайте просто проверить, какое окружение используется сервисом. Частая ошибка — направить green на неправильную базу, неверный OAuth callback или тестовый ключ платежей.
Минимальный чеклист подготовки
Перед первым cutover вы должны уметь ответить «да» на эти пункты:
- Раздельные конфиги для blue и green (env vars, секреты, ключи сторонних сервисов) с понятными именами и простым способом проверить, что загружено.
- Один воспроизводимый артефакт сборки, который продвигается дальше (build once, deploy many). Не пересобирайте для green.
- Health‑check, который доказывает больше, чем «сервер поднялся» (включите критические зависимости: базу данных и кеш).
- Базовый мониторинг того, что чувствуют пользователи (rate ошибок и latency) плюс одна‑две ключевые операции (регистрация, оплата, загрузка файла).
- Логи, которые можно читать в стрессовой ситуации (request IDs, полезные ошибки и способ сравнить blue vs green).
Health‑checks стоят отдельного внимания. «200 OK» для балансировщика — нормально, но перед переключением хочется более глубокого сигнала. Например: может ли приложение достучаться до базы, прочитать строку и записать лёгкую запись? Если нельзя безопасно тестировать записи, по крайней мере проверьте соединение и выполнение простого запроса.
Держите релизы скучными. Главный плюс blue‑green — уверенность, что вы переключаетесь на то же, что уже тестировали. Если сборка меняется между окружениями, вы тестируете одно, а выпускаете другое.
Пошагово: простой runbook релиза blue‑green
Blue‑green лучше работает как короткий повторяемый чеклист. Не нужно усложнять — нужно быть скучным и безопасным.
1) Выберите метод переключения трафика
Выберите один метод и придерживайтесь его:
- Переключение на балансировщике нагрузки или reverse proxy
- Swap окружений у платформы (если хост это поддерживает)
- Изменение DNS (работает, но кеширование делает тайминг непредсказуемым)
Решите заранее, кто имеет доступ, сколько это занимает и как это отменить.
2) Деплойте green, чтобы он соответствовал blue
Разверните новую версию в green с тем же «профилем», что и blue: те же сервисы (очередь, кеш, хранилище), тот же подход к управлению секретами, те же фоновые воркеры и эквивалентные runtime‑настройки. Значения могут отличаться, но структура должна быть согласованной.
Большинство провалов blue‑green происходят потому, что green не похож на прод: green указывает на другую базу, где отсутствует секрет и авторизация ломается только после переключения, или раннер задач не подключён как нужно.
3) Проверьте green до того, как пользователи начнут его трогать
Запустите быстрые smoke‑тесты против green под реальным аккаунтом (или staging‑безопасным). Держите тест простым и сфокусированным на том, что ломает доход и доверие:
- Вход и выход из системы
- Загрузка нескольких ключевых страниц
- Создание и обновление одной реальной записи
- Триггер одной фоновой задачи (письмо, webhook, отчёт)
- Просмотр логов на предмет новых всплесков ошибок
Если приложение использует кеши или воркеры — запустите их заранее и дайте им прогреться. Частая ситуация: «в тестах всё работало», а в проде падает, когда кеши холодные и воркеры начинают обрабатывать реальные очереди.
4) Переключение и зоркий мониторинг
Переключайте трафик контролируемо. Если ваша платформа позволяет градуированный трафик (даже 10% сначала), сделайте это. Если переключение всё‑или‑ничто — делайте в тихое окно.
В ближайшие 10–30 минут наблюдайте короткий набор сигналов: rate ошибок, latency, успешность логина, ваш ключевой сценарий (чек‑аут, оплата) и нагрузку на базу. Решите заранее, какие метрики означают «стоп и откат».
Миграции базы без потери записей
Сложнее всего в blue‑green обычно не переключение, а база данных.
Главный риск прост: некоторое время могут быть живы обе версии приложения. Если обе пишут в одну базу, но ожидают разные таблицы или колонки, одна версия начнёт выдавать ошибки. Ещё хуже — она запишет данные, которые другая версия не прочитает или перезапишет поля неожиданно.
Безопасный паттерн — делать изменения схемы обратно‑совместимыми сначала. Добавляйте, прежде чем удалять. Держите старый код работающим, пока новый раскатывается.
Используйте подход «расширить, затем сократить»
Большинство малых приложений избегают даунтайма, разбивая изменения схемы на шаги:
- Расширение: добавьте новые колонки или таблицы, оставьте старые.
- Запись с перекрытием: обновите новый код, чтобы писать в новое место, одновременно сохраняя совместимость чтения.
- Сужение: после cutover и безопасного окна удалите старые колонки, таблицы или кодовые ветки.
Пример: хотите переименовать users.fullname в users.display_name. Не удаляйте fullname во время переключения. Добавьте display_name, выпустите код, который пишет оба поля (или пишет одно и делает бэфилл), затем почистите позже.
Отделяйте деплой от разрушительных миграций
Старайтесь не объединять «drop column», «переписать таблицу» или «бэфилл 50M строк» с моментом flip. Выполняйте долгие или рискованные операции заранее, пока текущая версия ещё обслуживает пользователей. Если миграция займёт минуты или будет блокировать строки — рассматривайте её как pre‑migration и сделайте так, чтобы её можно было запустить безопасно при работе старой версии.
Во время окна переключения проверяйте совместимость в обе стороны: старое приложение читает строки, записанные новым, и новое — строки, записанные старым. Именно тут выплывают скрытые допущения: жестко закодированные списки колонок, отсутствие обработки NULL или небезопасные значения по умолчанию.
Сессии и auth: держите пользователей в системе при переключении
Самый быстрый путь превратить безопасный cutover в поддержку‑кошмар — нечаянно выбросить всех из системы. Сессии чаще всего ломаются из‑за различий между blue и green: имя cookie, ключ подписи, формат токена или даже домен/поддомен.
Держите правила идентификации идентичными с обеих сторон
Во время окна переключения считайте контрактами и не меняйте:
- Ключи подписи и шифрования сессий (cookie secrets, JWT‑ключи, CSRF‑секреты)
- Настройки cookie (имя, домен, путь, Secure, HttpOnly, SameSite)
- Формат токенов и сессий (claims, срок действия, сериализация)
- OAuth‑callback и redirect URL
Если нужно вращать ключи — делайте с перекрытием. Green должен принимать и старые, и новые ключи для верификации, а выдавать новые только при новых логинах. Существующие пользователи останутся в сессии, новые логины будут под новым ключом.
Предпочитайте stateless авторизацию (и держите совместимость)
Если приложение может использовать короткоживущие access‑токены и flow refresh, cutover упрощается, потому что сервер не хранит сессии. Важно совместимость: green должен принимать токены, выпущенные blue, до их естественного истечения. Не меняйте имена claim или правила audience в одном релизе.
Если вы используете серверные сессии — общий стор сессий обязателен. И blue, и green должны читать и писать в одно и то же хранилище сессий (обычно Redis или таблица в БД). Если окружения имеют свои сторы, пользователь переключится на green и окажется «неизвестен», хотя cookie в порядке.
Чек‑ауты и длинные формы — частая боль. Кто‑то в середине оплаты, происходит cutover, следующий запрос попадает на green. Храните корзину и состояние заказа в базе (не только в памяти), используйте идемпотентность для платежей и делайте отправку форм терпимой к повторным попыткам. По возможности переключайте трафик постепенно и дайте blue завершить входящие запросы до полного flip.
Быстрый откат без усугубления ситуации
В blue‑green откат обычно не означает откат кода. Это переключение трафика обратно на предыдущее окружение (green→blue). Если роутинг чистый, это может быть быстро.
Цель — скорость и уверенность. Выберите одного владельца решения и держите очевидное действие для flip (одна кнопка, одна команда, один шаг runbook). Когда у всех есть свой «быстрый фикс», откаты затягиваются и становятся грязными.
Согласуйте триггеры отката заранее. Частые: резкий всплеск 5xx/таймаутов, ошибки логина/регистрации, сбои платежей, явные проблемы с целостностью данных (пропавшие заказы, дубли, странные итоги) или скачок latency, делающий приложение нефункциональным.
Сложная часть — база данных. Как только green начал писать, возвращаться назад безопасно только если blue может прочитать новый формат. Если релиз включал миграцию, удалившую колонку, переименовавшую поля или изменившую constraints, blue может упасть или вести себя некорректно. Так откат превращается в большую аварию.
Практическое правило — держать изменения базы обратно‑совместимыми в течение короткого окна. Добавляйте новые колонки сначала, держите старые, запускайте код, работающий с обеими версиями, и удаляйте старое поле только после стабилизации.
Задайте окно принятия решения. Например: «Если в первые 10–20 минут мы видим критические ошибки — возвращаемся. После этого фиксируем вперёд, если нет потери данных.» Это предотвращает бесконечные дебаты, пока пользователи страдают.
Простой сценарий отката:
- Назначить владельца инцидента и заморозить другие изменения
- Переключить трафик обратно на предыдущее окружение
- Проверить логин, платежи и основные пользовательские пути
Частые ошибки, приводящие к простоям
Blue‑green звучит просто, но большинство инцидентов происходят в скучных пробелах между «двумя окружениями» и «переключением трафика».
Одна большая ошибка — считать blue и green разными приложениями. Это начинается с мелочей: отсутствующая переменная окружения, секрет, повернутый только в одном месте, или фича‑флаг, включённый по‑разному. Затем cutover — и платежи не проходят или письма перестают отправляться. Blue и green должны быть одной сборки и одной формы конфигурации, с минимумом различий (цвет развёртывания и hostnames).
Ещё часто забывают про фоновые задачи. Веб‑трафик может переключиться чисто, но раннер задач всё ещё смотрит на старое окружение или оба окружения запускают один и тот же scheduled job. Это приводит к дублирующимся счетам, двойным уведомлениям и конфликтам очистки.
Базы данных — где люди чаще всего получают травмы. Команды делают разрушительную миграцию в момент переключения. Если green использует новую схему, а blue всё ещё пишет старую (или наоборот), вы быстро потеряете записи или получите порчу данных. Безопасный паттерн: сначала совместимые изменения, затем деплой, переключение, потом удаление старого.
Локальное тестирование недостаточно. Blue‑green проваливается на продакшн‑деталях: реальные провайдеры авторизации, настоящие cookie, реальные кеши, реальные таймауты и реальная нагрузка. Если вы тестировали green только на ноутбуке — вы не тестировали то, что собираетесь отдать пользователям.
Наконец, команды тянут время во время инцидента, потому что не определили правило «стоп‑линии». Решите заранее, что вызывает немедленный откат: резкий скачок ошибок, превышение порога логина, сломанный ключевой сценарий (регистрация, оплата, сброс пароля), рост ошибок БД (deadlocks, timeouts), дублирование фоновой работы или просто невозможность объяснить проблему за несколько минут.
Быстрый чеклист и следующие шаги
Blue‑green работает лучше, когда каждый релиз — короткая рутина, ловящая те немногие вещи, которые сильнее всего бьют по пользователям: сломанный вход, потерянные записи и замедления сразу после переключения.
До переключения выполните быструю пред‑деплой проверку. Подтвердите health‑checks нового окружения (включая критические зависимости), проверьте загрузку правильных env vars и секретов, просмотрите миграции на предмет безопасности (сначала добавление, без неожиданных удалений) и убедитесь, что логи и мониторинг работают.
Сразу после cutover протестируйте как реальный пользователь. Для многих малых приложений это значит: зарегистрироваться или войти, создать или обновить запись и выполнить одну ключевую денежную или коммуникационную операцию (чек‑аут, оплата, отправка приглашения, сохранение черновика).
После первых нескольких минут прекратите кликать и наблюдайте сигналы. Ищите изменения, а не идеальные цифры: резкий рост ошибок, всплеск latency или накопление в очередях.
Определите правила отката заранее. Откат — это не только переключение, это ещё и решение по данным: кто имеет право откатывать, точное действие переключения и его длительность, что происходит с записями после cutover, как работать с сессиями и когда прекращать откаты и начинать фиксить вперёд.
Если вы унаследовали AI‑сгенерированное приложение и деплои постоянно падают, считайте это проблемой здоровья кода, а не только процесса. Команды в FixMyMess (fixmymess.ai) делают диагностику кодовой базы, правку логики, укрепление безопасности и подготовку к деплою для AI‑сгенерированных прототипов, чтобы blue‑green cutover и rollback стали предсказуемыми, а не стрессовыми.
Часто задаваемые вопросы
Что такое blue‑green развёртывание простыми словами?
Blue‑green означает, что у вас есть два полных готовых окружения. Одно (blue) обслуживает реальных пользователей, в другое (green) вы разворачиваете и тестируете новую версию. Когда всё устраивает — переключаете трафик на green; если что-то ломается — возвращаете на blue.
Почему у небольших приложений так много простоев из‑за «малых» релизов?
Малые команды часто выполняют меньше проверок перед релизом: меньше времени на тесты, меньше рецензентов и медленнее реакция на инциденты. Небольшая ошибка в конфигурации или авторизации может вывести всё приложение. Blue‑green даёт безопасный шаг «попробовать на реальной инфраструктуре» без громоздкой процедуры.
Как лучше всего переключать трафик между blue и green?
Чаще всего переключение делают на уровне балансировщика нагрузки или reverse proxy — быстро и удобно вернуть назад. Если платформа поддерживает swap окружений, это ещё проще. DNS работает, но из‑за кэширования тайминги предсказать сложнее.
Что мне проверить на green перед переключением?
Быстрый smoke‑тест, который отражает то, что важно пользователям: вход в систему, несколько ключевых страниц, создание/обновление записи и одна фоновая задача или побочный эффект. Убедитесь, что в продакшн‑настройках загружены правильные секреты и переменные окружения. Сразу после переключения наблюдайте за ошибками и задержками, чтобы быстро откатиться при необходимости.
Как не дать green посмотреть в неправильную базу или взять не те секреты?
Конфигурация — это первичный риск. Сделайте очевидным, в каком вы окружении, держите конфиги blue и green раздельными и перепроверяйте «подводные камни»: endpoint базы, OAuth callback URL, домен cookie и ключи платежей. Большинство болезненных cutover — не баги кода, а неправильные настройки.
Как не допустить, чтобы пользователи вышли из системы при переключении?
Сделайте правила идентификации одинаковыми в обоих окружениях во время окна переключения: ключи подписи и шифрования сессий (cookie secrets, JWT‑ключи), настройки cookie (имя, домен, путь, Secure, HttpOnly, SameSite), формат токенов и правила истечения, а также OAuth‑callback‑URL. Если нужно менять ключи — делайте это с перекрытием: green должен принимать старый и новый ключи, отдавая пользователям новые с новым ключом.
Как выполнять миграции базы, не теряя записи?
Предположите, что blue и green некоторое время будут писать в одну базу, поэтому схема должна быть обратно‑совместимой. Сначала добавляйте новые столбцы или таблицы, затем деплойте код, который умеет работать со старой и новой формой, а удаляйте старые поля только позже. Избегайте разрушительных миграций в момент переключения.
Когда откатываться, а когда фиксить вперёд?
Откат в blue‑green — это, как правило, не попытка «раскатать» код, а переключение трафика обратно на прошлое окружение. Решение об откате должен принимать один ответственный, а само действие — быть очевидным (одна команда, одна кнопка, шаг в runbook). Решите триггеры отката заранее: резкий рост 5xx/таймаутов, ошибки входа, отказ оплат или явные проблемы с целостностью данных. Будьте осторожны, если green уже записал данные в новом формате — тогда откат может быть небезопасен.
Как не запускать фоновые задачи по два раза в blue и green?
Одноразовые или периодические задачи, запущенные в обоих окружениях, приводят к дублирующим эффектам: двойные счета, повторные уведомления и т. п. Перед переключением убедитесь, что во время перехода выполняется только одна копия «разового» задания — назначьте, где работают воркеры и cron‑задачи. После переключения проверьте очереди, планировщики и обработчики webhook.
Помогает ли blue‑green, если приложение сгенерировано AI и уже нестабильно?
AI‑сгенерированный код часто имеет хрупкую авторизацию, запутанную логику и неконсистентную работу с конфигурацией — это делает поведение продакшена непредсказуемым. Blue‑green ограничит радиус бедствия, но не исправит фундаментальные проблемы: небезопасные миграции, захардкоженные ключи или ненадёжную логику сессий. Если деплои постоянно падают, стоит провести диагностику и очистку кодовой базы.