Корректное завершение работы Node‑серверов: как остановить случайные 502
Научитесь корректно завершать работу Node‑серверов: дренировать keep‑alive соединения, завершать in‑flight запросы, закрывать пул подключений к БД и предотвращать случайные 502 во время деплоев.
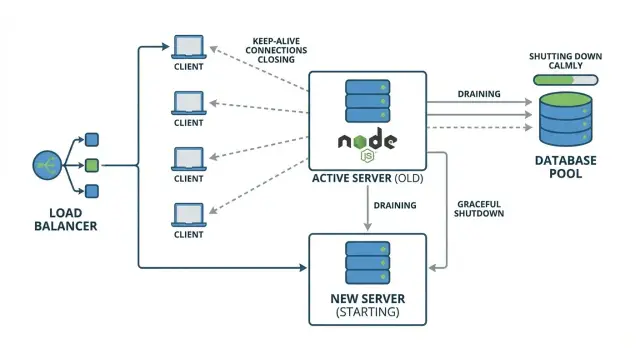
Почему деплои могут вызывать случайные 502
«Случайная 502» во время деплоя обычно означает, что ваш реверс‑прокси или балансировщик нагрузки отправил запрос на экземпляр приложения, который уже умирает. На короткий момент прокси может всё ещё считать этот экземпляр доступным, или он может переиспользовать существующее соединение, на другом конце которого уже нет здорового сервера.
Это кажется случайным, потому что зависит от тайминга. Большинство пользователей попадают на экземпляры, которые ещё работают, и получают нормальный ответ. Небольшая группа попадает в неудачное окно: их запрос приходит прямо в момент завершения процесса, когда сервер перестаёт слушать, или сразу после обрыва соединения.
Keep‑alive может усугублять ситуацию. Клиенты и прокси переиспользуют существующие TCP‑соединения для нескольких запросов, так что во время деплоя у вас могут быть долгоживущие соединения, которые всё ещё шлют запросы на экземпляр, который вы пытаетесь заменить. Если приложение моментально закрывает сервер, эти переиспользованные соединения падают непредсказуемо, и прокси часто отмечает это как 502.
Ключевая идея — корректное завершение (graceful shutdown): перестать принимать новую работу, закончить то, что уже в прогрессе, и только потом выйти.
Простой сценарий: вы выкатываете новую версию, оркестратор шлёт сигнал остановки, и Node сразу выходит. Один пользователь в процессе оформления заказа (in‑flight запрос). Другой использует браузер и переиспользует keep‑alive‑соединение для следующей страницы. Оба запроса обрываются. Остальные, которые были направлены на другие экземпляры, ничего не замечают.
Шатдаун, который дренирует соединения и ждёт завершения in‑flight запросов с небольшим запасом времени, предотвращает эти «случайные» ошибки и делает деплои предсказуемыми.
Что именно вы останавливаете
Node‑сервер — это не просто «процесс, который останавливается». Это процесс, пребывающий в середине диалога с клиентами, держащий открытые ресурсы: сокеты, таймеры, подключения к базе. Graceful shutdown в основном про корректное завершение этих диалогов в нужном порядке.
Типичный жизненный цикл запроса: клиент подключается, шлёт запрос, ваше приложение выполняет код (часто обращаясь к базе или чужому API), затем сервер отправляет ответ и запрос завершён. Если вы убьёте процесс посередине, клиент получит битый ответ, а балансировщик нагрузок может пометить это как 502.
«In‑flight запросы» — это запросы, которые начали выполняться, но ещё не завершились. Именно их с наибольшей вероятностью обрежут во время деплоя. Даже короткие запросы становятся in‑flight, если база медлит, стороннее API тормозит или цикл событий занят.
Keep‑alive добавляет ещё слой. Одно TCP‑соединение может передавать множество запросов. Во время shutdown вы хотите перестать принимать новые запросы, но у вас всё ещё могут быть открытые keep‑alive‑сокеты, простаивающие или ожидающие следующего запроса.
Некоторая работа остаётся «в полёте» дольше и требует особого подхода: загрузки (большие файлы, медленные клиенты), экспорт/генерация отчётов, потоковые ответы и Server‑Sent Events (SSE), а также WebSockets (не «запросы» в привычном смысле, но всё ещё активные соединения).
Итак, вы завершаете три вещи: новый входящий трафик, текущие in‑flight запросы и любые долгоживущие соединения, которые держат процесс занятым даже когда он выглядит простым.
Сигналы и тайминги: как запускается shutdown
Большинство проблем с деплоем начинаются одинаково: процесс Node получает команду остановиться, но никто толком не уверен, когда и сколько у него времени на завершение.
В Linux наиболее важны два сигнала:
- SIGTERM: «Пожалуйста, выйди сейчас, но сначала подчисти за собой.» Это то, что платформы шлют при обычной остановке или деплое.
- SIGINT: «Стоп, потому что нажали Ctrl+C.» Это то, что вы получаете в терминале при прерывании вручную.
Менеджеры процессов и контейнеры обычно следуют простой последовательности: деплой начинается, старому экземпляру шлётся SIGTERM, и запускается отсчёт (часто называемый grace period). Если приложение выходит вовремя — отлично. Если нет, платформа отправляет жёсткий kill (SIGKILL) и процесс мгновенно умирает.
Если вы ничего не делаете, Node будет работать пока его не убьют. Это значит, что keep‑alive‑сокеты могут быть разорваны посреди запроса, in‑flight работа может никогда не завершиться, а подключения к базе останутся висящими. Результат проявляется в виде «случайных» 502, даже если логи приложения выглядят нормально.
Сделайте поведение при shutdown предсказуемым, а не хаотичным. Решите заранее, какой сигнал вы обрабатываете (обычно SIGTERM), сколько будете ждать до принудительного завершения, и что останавливается первым (новый трафик) по сравнению с тем, что вы пытаетесь доконать (in‑flight запросы).
Когда shutdown предсказуем, деплои перестают быть делом удачи.
Пошагово: безопасно перестать принимать новый трафик
Деплой не должен ощущаться как выдергивание вилки питания. Цель проста: сначала остановить новый трафик, затем завершить то, что уже идёт.
Начните с простого флага «draining» в приложении. Когда он становится true, сервер ещё жив, но готовится к завершению работы.
Безопасный порядок для большинства HTTP API:
- Установите
draining = trueкак только получите сигнал на shutdown. - Сделайте readiness‑чек неготовым, чтобы балансировщик перестал шлёть новый трафик на этот экземпляр.
- На любой новый запрос, который всё же придёт, возвращайте понятный
503 Service Unavailableс коротким сообщением. - Попросите HTTP‑сервер перестать принимать новые соединения.
- Держите процесс работающим, пока существующие запросы не завершатся (с таймаутом, описанным ниже).
Миниатюрный пример (в стиле Express):
let draining = false;
app.get('/ready', (req, res) =\u003e {
if (draining) return res.sendStatus(503);
res.sendStatus(200);
});
app.use((req, res, next) =\u003e {
if (draining) return res.status(503).send('Server is restarting, try again');
next();
});
process.on('SIGTERM', () =\u003e {
draining = true;
server.close(); // stop accepting new connections
});
Держите health‑чеки честными. Во время shutdown вы хотите, чтобы «ready» быстро стал красным, но при этом базовая проверка «alive» оставалась зелёной до самого выхода. Это помогает избежать преждевременного убийства процесса платформой и возникновения тех самых 502, которые вы пытаетесь предотвратить.
Дренируем keep‑alive соединения, не роняя пользователей
Keep‑alive позволяет браузеру (или балансировщику) переиспользовать один TCP‑сокет для нескольких HTTP‑запросов. Это хорошо для скорости, но неожиданно при деплое: вы перестаёте принимать новые соединения, но старые keep‑alive сокеты остаются открытыми и могут прислать следующий запрос на процесс, который умирает.
server.close() в Node прекращает приём новых соединений, но не закрывает автоматически уже существующие keep‑alive‑сокеты. Чтобы безопасно их дренировать, отслеживайте сокеты при подключении и аккуратно закрывайте простые (idle), позволяя активным запросам завершиться.
Простой шаблон:
- Держите
Setсокетов, добавляя их вconnectionсобытии сервера. - Отмечайте сокеты как «занятые», пока у них есть активный запрос.
- При shutdown вызовите
server.close(), затемsocket.end()для простых сокетов. - Через дедлайн вызывайте
socket.destroy()для всего, что ещё открыто.
Вот компактный пример:
const sockets = new Set();
const busy = new Set();
server.on('connection', (socket) =\u003e {
sockets.add(socket);
socket.on('close', () =\u003e { sockets.delete(socket); busy.delete(socket); });
});
server.on('request', (req, res) =\u003e {
busy.add(req.socket);
res.on('finish', () =\u003e busy.delete(req.socket));
});
async function shutdown() {
server.close();
for (const s of sockets) if (!busy.has(s)) s.end();
setTimeout(() =\u003e { for (const s of sockets) s.destroy(); }, 10_000);
}
Этот дедлайн принудительного закрытия важен. Без него один зависший клиент может удерживать старый экземпляр живым и превращать rollout в череду таймаутов и промежуточных ошибок прокси.
Доведите in‑flight запросы до конца с понятным таймаутом
Когда начинается деплой, вы хотите, чтобы существующие запросы завершились нормально, но вам также нужен жёсткий стоп, чтобы старый процесс не висел бесконечно. Проще всего — отслеживать активные запросы и использовать флаг draining.
Небольшой шаблон, работающий с большинством Node HTTP фреймворков:
let draining = false;
let active = 0;
app.use((req, res, next) =\u003e {
if (draining) return res.status(503).set('Connection', 'close').send('Server restarting');
active += 1;
res.on('finish', () =\u003e { active -= 1; });
res.on('close', () =\u003e { active -= 1; });
next();
});
function beginShutdown() {
draining = true;
}
Во время дренажа избегайте создания новой работы, которая переживёт сам запрос. Частая ошибка — позволить запросу поставить в очередь фоновые задачи (отправку писем, генерацию отчётов, очистку) после того, как вы уже начали завершение. Если вам нужно ставить задания, оградите это тем же флагом draining и пропускайте такие операции при shutdown.
Установите таймаут shutdown, соответствующий вашему трафику. Многие команды начинают с 10–30 секунд, а затем настраивают по медленным конечным точкам.
Поток прост: начните дренировать и перестаньте принимать новые запросы, ждите, пока active === 0, и если таймер сработал — принудительно закройте оставшиеся соединения и выходите.
Если запрос приходит после начала дренажа, возвращайте 503 Service Unavailable и добавляйте Connection: close. Это говорит клиентам и балансировщикам не держать сокет открытым, что уменьшает редкие полузакрытые keep‑alive ошибки, которые часто проявляются как 502.
Чисто закройте DB‑пулы и другие ресурсы
Закрытие HTTP‑сервера — это не то же самое, что позволить Node‑процессу выйти. Пул подключений к базе держит открытые TCP‑сокеты (и иногда таймеры), так что цикл событий всё ещё занят. Поэтому деплой может выглядеть «завершённым», в то время как старый процесс висит, потом его убивают и возникают ошибки.
«Закрыть пул» обычно значит: перестать выдавать новые соединения, закрыть простые, и подождать, пока активные запросы не завершатся. Типичные примеры:
- PostgreSQL (
pg):await pool.end() - MySQL (
mysql2):await pool.end() - Mongoose:
await mongoose.connection.close()(и прекратите новые операции)
Порядок важен. Сначала перестаньте принимать трафик (чтобы не начать новые DB‑операции), затем дайте завершиться in‑flight запросам, потом закрывайте пул БД. После этого завершайте остальное.
Ожидающие запросы и транзакции требуют ясных правил. Во время shutdown блокируйте новые запросы на запись, дайте текущим запросам завершиться в пределах таймаута, затем завершайте быстро. Если у вас длинные транзакции — старайтесь завершить их быстро и откатить, если вы попали в дедлайн.
async function shutdown() {
server.close(); // stop new HTTP connections
await Promise.race([
waitForInFlightToFinish(),
sleep(10_000),
]);
await dbPool.end();
await redis?.quit();
await queue?.close();
}
Другие ресурсы, которые могут держать процесс живым: клиенты Redis, очереди задач, подключения к Kafka/Rabbit, cron‑таймеры и открытые дескрипторы файлов. Явное их закрытие превращает shutdown в то, на что можно положиться.
Фоновые задачи: не забывайте о скрытой работе
HTTP‑трафик — это только половина истории. Многие Node‑сервера запускают фоновые задачи в том же процессе: потребители очередей, cron‑задачи, периодические обновления и воркер‑лупы. Во время деплоя они могут держать процесс живее, чем вы ожидаете, или продолжать трогать БД после начала shutdown.
Первое правило: как только начался shutdown, прекращайте запуск новой фоновой работы. Пауза потребления очередей, остановка опроса и предотвращение срабатывания cron. Если вы пользуетесь библиотекой, ищите реальный pause/stop метод (а не просто disconnect), потому что отключение может триггерить повторные попытки и дополнительный шум.
После остановки нового запуска пусть текущие задания завершаются, но только до понятного лимита. Иначе одна застрявшая задача может задержать shutdown до тех пор, пока платформа не убьёт процесс, а тогда и ошибки резко увеличатся.
Безопасная отмена vs ожидание
Выбирайте в зависимости от природы задания:
- Ждать работу с известным верхним пределом (отправка письма, обработка одного изображения).
- Отменять длинные задачи с неопределённым концом (большие импорты, сторонние вызовы, которые подвисают).
- Отменять всё, что держит открытую DB‑транзакцию.
- Ждать задачи, которые умеют сохранять прогресс и возобновляться.
- Отменять задачи, которые при повторном запуске могут повредить (двойное списание, двойной возврат денег).
Если вы отменяете, делайте это осознанно: установите флаг isShuttingDown, перестаньте забирать новые сообщения и дайте задачам проверять флаг в безопасных точках, чтобы они могли корректно завершиться.
Что логировать, чтобы понять, что мешало выходу
Логируйте достаточно, чтобы ответить на вопрос «что ещё работало?». Фиксируйте время старта shutdown и сигнал, счётчики активных задач (по имени очереди), возраст и ID самой старой выполняющейся задачи, какие подсистемы ещё открыты (клиент очереди, cron, таймеры), и было ли достигнуто время дедлайна с принудительным прекращением чего‑либо.
Особые случаи: WebSockets, стриминг и загрузки
Shutdown проще, когда запросы короткие. Проблемы начинаются, когда соединения держатся минуты.
WebSockets: закрываем без сюрпризов для пользователей
WebSockets — по своей природе долгоживущие, поэтому не убивайте процесс просто так. Во время shutdown перестаньте принимать новые вебсокеты, уведомите активных клиентов и дайте им короткое окно для переподключения.
Практичный паттерн: отправьте событие «server restarting», перестаньте обрабатывать новые сообщения и закройте соединение с нормальным кодом закрытия (не ошибочным). Если у вас есть балансировщик, убедитесь, что он перестал направлять новые подключения на экземпляр, прежде чем закрывать сокеты.
Стриминг, SSE и долгие опросы
SSE и другие стриминговые эндпоинты могут выглядеть «простыми» для прокси, даже когда они работают. Во время shutdown аккуратно завершайте потоки, чтобы клиент мог переподключиться, и задавайте максимальное время дренажа, чтобы не ждать вечность.
В случае долгого опроса клиенты быстро ретраят. Вернуть понятный ответ «попробуйте снова» лучше, чем позволить соединению умереть и возникнуть 502.
Практический подход: сначала прекратите принимать новые соединения, пометьте экземпляр как draining в health‑чеке, отправьте финальное сообщение и аккуратно закройте потоки/сокеты, дайте загрузкам короткую грацию, затем прервите, и используйте один жёсткий таймаут для всего, чтобы деплой завершался.
Загрузки файлов в процессе
Если клиент загружает файл, разрыв соединения может испортить файл и отнять минуты. По возможности используйте возобновляемые загрузки. Если это невозможно, записывайте во временный файл и «подтверждайте» его только после полного завершения загрузки.
Также проверьте таймауты реверс‑прокси (Nginx, ALB и т.д.). Таймаут прокси, меньший, чем ваш поток или загрузка, может выглядеть как 502, связанная с деплоем, даже если код приложения в порядке.
Распространённые ошибки, которые всё ещё приводят к 502
Большинство «случайных» 502 при деплое на самом деле не случайны. Они происходят, когда shutdown идёт в неправильном порядке или когда балансировщик продолжает направлять трафик на процесс, который уже умирает.
Одна типичная ошибка тайминга — слишком долго не останавливать приём трафика. Если вы начинаете дренаж только после того, как начали закрывать ресурсы, вы создаёте окно, в котором приходят новые запросы, но важные ресурсы (например, DB‑подключения) уже недоступны. Результат выглядит как нестабильное сетевое поведение.
Ещё классическая ошибка — закрыть пул базы данных раньше времени. Запросы, которые уже прошли маршрутизацию, всё ещё нуждаются в запросах, сессиях или транзакциях. Если пула нет — эти запросы падают в середине.
Окружения деплоя обычно шлют SIGTERM, а не SIGINT. Если вы тестировали только Ctrl+C локально, ваш обработчик shutdown может никогда не сработать в проде. Это часто проявляется в AI‑сгенерированном Node‑коде: локально всё ок, а при первом настоящем деплое платформа жёстко убивает процесс, потому что он не реагирует на ожидаемый сигнал.
Частые причины провалов shutdown просты: не перейти в режим дренажа рано, отсутствие дедлайна на shutdown (или слишком короткий дедлайн), оставлять readiness зелёным во время дренажа, агрессивно закрывать keep‑alive вместо их дренажа и забывать, что фоновые задачи могут держать процесс живым после закрытия HTTP‑сервера.
Если исправите одну вещь — исправьте health‑чеки. Как только начинается дренаж, экземпляр должен быстро перестать выглядеть готовым, чтобы трафик ушёл на другие инстансы прежде, чем вы начнёте что‑то разбирать.
Быстрый чек‑лист перед деплоем
Сделайте dry‑run в стейджинге прямо перед релизом. Когда процесс получает команду остановиться, он должен перестать брать новую работу, завершить начатую и не оставить висящих хвостов.
Короткий чек‑лист:
- Пришлите реальный сигнал shutdown (SIGTERM) и убедитесь, что приложение реагирует сразу: лог‑строка о старте shutdown, readiness меняется, и сервер перестаёт принимать новые соединения.
- Во время дренажа проверьте, что новые запросы получают контролируемый ответ (например, 503 с коротким сообщением), а не висят до таймаута балансировщика.
- Создайте медленный запрос (sleep, тяжёлый запрос в базе или большой рендер) и убедитесь, что он может завершиться. Также подтвердите, что у вас есть жёсткий таймаут, чтобы процесс вышел вовремя, даже если что‑то зависнет.
- Проверьте очистку: пул БД закрывается, клиенты очередей дисконнектятся, таймеры останавливаются. После выхода процесс не должен оставаться живым из‑за открытых дескрипторов.
- Просмотрите логи shutdown сквозь весь процесс: время начала, когда начался дренаж, количество активных запросов и финальная строка «shutdown complete».
Простой способ поймать проблемы — запустить два curl одновременно: один долгий запрос, потом другой сразу после отправки SIGTERM. Если долгий завершился, а новый получил быстрый предсказуемый ответ — вы близки к цели.
Если ваш сервер сгенерирован AI‑инструментом (Lovable, Bolt, v0, Cursor, Replit), эти хуки часто отсутствуют или наполовину подключены. Исправьте их заранее, чтобы избежать ощущения «случайной 502» во время деплоев.
Пример: rolling‑деплой без обрыва запросов
Представьте небольшую продовую схему: два Node API‑инстанса (A и B) за балансировщиком нагрузки. Клиенты используют keep‑alive, поэтому одна вкладка браузера может переиспользовать один TCP‑сокет к инстансу A минуты подряд.
Во время rolling‑деплоя балансировщик начинает отправлять новые запросы на B, пока A заменяется. Но есть catch — keep‑alive: даже если балансировщик перестаёт брать A для новых соединений, некоторые клиенты всё ещё имеют открытое соединение к A и будут продолжать отсылать запросы по нему.
Отсюда и идут прерывистые 502. Если A получает SIGTERM и быстро выходит, эти переиспользованные соединения внезапно указывают на процесс, которого уже нет. Следующий запрос по этому сокету падает, и прокси сообщает 502.
Graceful shutdown избегает этого, делая три вещи в нужном порядке:
- перестать принимать новые соединения на A
- дренировать существующие keep‑alive соединения
- ждать in‑flight запросы в пределах понятного таймаута, затем закрыть DB‑пулы и выйти
Для теста локально или в стейджинге: сделайте один медленный эндпоинт (например, задержка 10 секунд), шлите повторяющиеся запросы с включённым keep‑alive, затем перезапускайте только один инстанс. Если дренаж работает — медленный запрос завершится и вы не увидите прерывистых 502.
Следующие шаги: сделайте деплои скучными снова
Graceful shutdown помогает только если вы видите его в деле под реальным трафиком. Добавьте логи shutdown, показывающие порядок событий: сигнал получен, readiness сменился, перестали принимать новые запросы, счётчик активных запросов, дренаж keep‑alive, пул БД закрыт, выход процесса.
Перед следующим релизом запустите тест с медленным запросом в стейджинге: сделайте один эндпоинт намеренно медленным (10–20 секунд), затем задеплойте, пока этот запрос в процессе. Вам нужны два результата: медленный запрос доходит до конца, и новые запросы переходят на новый инстанс без ошибок.
Если кодовая база грязная или сгенерирована ИИ и деплои всё ещё непредсказуемы, целенаправленный аудит часто быстрее, чем хаотичные правки. FixMyMess (fixmymess.ai) помогает командам диагностировать пути shutdown, дренаж соединений и проблемы с очисткой в унаследованных AI‑сгенерированных Node‑приложениях, чтобы rollout‑ы перестали давать сюрпризные 502.