Исчерпание пула подключений к базе данных: настройка для безсерверных сред
Узнайте, почему исчерпание пула подключений к базе данных может происходить даже при небольшом трафике и как настроить пул для безсерверных сред и долгоживущих серверов, чтобы избежать сбоев.
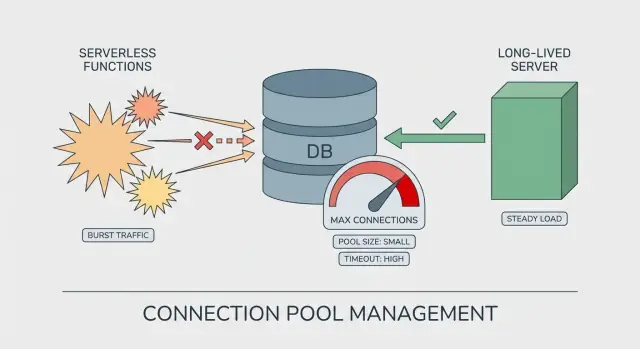
Как выглядит исчерпание пула в продакшене
Исчерпание пула подключений значит, что вашему приложению не удаётся получить соединение с базой, когда оно нужно. Запросы накапливаются, приложение ждёт, затем падает по таймауту. Для пользователей это выглядит как случайные падения сайта.
Большинство команд сначала замечают «всё работает медленно», хотя CPU и трафик выглядят нормально. Страницы, которые обычно грузятся за секунду, висят 10–30 секунд, а потом падают. Чаще всего страдают чувствительные сценарии: вход, оформление заказа, сохранение формы.
Пользовательские симптомы обычно такие:
- Страницы медленные и иногда восстанавливаются после обновления
- Случайные 500 ошибки, которые то пропадают, то возвращаются
- Сбои при входе или обрывы сессий
- Фоновые задачи перестают продвигаться
- Мобильные приложения таймаутят на простых действиях
У инженеров картина конкретнее: очереди запросов растут, больше времени уходит на ожидание базы, в логах видны ошибки вроде «timeout acquiring connection». На стороне БД активные подключения могут сидеть у лимита или кратковременно всплескивать.
Самое сбивающее с толку — несоответствие: трафик может выглядеть «лёгким», а система стоит в ожидании.
Частая причина — несколько запросов держат соединения дольше, чем ожидается. Один медленный запрос, оставленная открытой транзакция или код, забывший вернуть клиент, могут заблокировать пул. После этого даже пара пользователей способна вызвать пробку.
Почему это случается даже при небольшом трафике
«Пользователи онлайн» — не то же самое, что «активные подключения к БД». Большинство БД позволяют меньшее число одновременных подключений, чем думают, и каждое соединение потребляет память и CPU.
В Postgres max_connections часто выставлен консервативно. Даже лимит, например, в 100 может быть на практике недостаточен, если каждое соединение тяжёлое. Добавьте админские инструменты, фоновые воркеры, миграции и одноразовые скрипты — и вы закончите раньше, чем ожидали.
Кроме того, один запрос пользователя может трогать БД несколько раз: главный запрос, запись аналитики, обновление сессии и, возможно, добавление в очередь. Если это не контролировать, «лёгкий трафик» всё равно делает много параллельной работы.
Исчерпание пула обычно вызвано одним (или несколькими) из следующих:
- Утечки подключений после ошибок или таймаутов, из‑за чего они не возвращаются в пул
- Медленные запросы, которые держат соединения дольше и заставляют другие запросы ждать
- Ретрайи, которые умножают трафик (ретраи на клиенте, на сервере, в ORM)
- Фоновый шум: боты, cron, health checks, опрос очередей
- Задачи на старте или миграции, открывающие лишние подключения в неудачный момент
Конкретный пример: у вас 10 пользователей, но один эндпоинт иногда делает запрос на 4 секунды. С пулом 10 небольшая вспышка (обновления, ретраи или бот) может занять все соединения. Новые запросы ждут, попадают на таймаут пула, падают, ретраятся и усугубляют пик.
Аварии при «лёгком трафике» чаще связаны с временем жизни соединений и параллелизмом, а не с общим числом запросов.
Serverless vs долгоживущие серверы: в чём разница в пулах
На долгоживущем сервере (VM, контейнер, классический app‑сервер) процесс живёт часами или днями. Пул БД переиспользуется между множеством запросов. Он «прогревается», стабилизируется, и можно предсказать, сколько соединений будет активно в любой момент.
Serverless иной. Ваш код может запускаться во множестве короткоживущих экземпляров. Каждый экземпляр может создать свой пул, даже если обслуживает всего несколько запросов. Так исчерпание пула проявляется при кажущемся лёгком трафике: трафик распределён по большему числу экземпляров, чем вы ожидали.
Почему serverless умножает подключения
Резкий рост обычно происходит из‑за cold starts и событий масштабирования. Когда платформа хочет больше параллелизма, она запускает дополнительные экземпляры, и каждый экземпляр может открыть свой набор соединений.
Размер пула, который кажется безопасным на сервере, может быть рискованным в serverless:
- Долгоживущий сервер: 1 экземпляр × пул 20 = ~20 подключений
- Serverless‑всплеск: 30 экземпляров × пул 20 = ~600 подключений
Даже если всплеск кратковременный, этого достаточно, чтобы достичь лимитов Postgres, замедлить запросы и вызвать таймауты.
Простая модель для мыслей
На долгоживущих серверах вы настраиваете пул для повторного использования и пропускной способности. В serverless вы настраиваете пул под «радиус взрыва»: предполагайте, что может быть много копий вашего приложения одновременно.
Показатели, которые нужно собрать перед изменением настроек
Догадки при настройке пула превращают мелкие проблемы в инциденты. Прежде чем менять что‑то, соберите несколько метрик, чтобы понять, не хватает ли вам подключений, не удерживаются ли они слишком долго или и то, и другое.
Начните с лимита базы. Найдите max_connections Postgres, затем посчитайте, кто их использует: ваше приложение, админы, фоновые воркеры, миграции, BI‑инструменты, реплики для чтения. Многие команды думают, что у них «100 подключений», когда 30 уже заняты.
Далее фокусируйтесь на параллелизме, а не на ежедневном трафике. Сайт с 200 пользователями в день всё ещё может иметь 20 одновременных запросов, если одна страница делает много API‑вызовов или несколько человек обновляют её одновременно. Посмотрите на пиковые параллельные запросы за самые загруженные 5–15 минут и разбейте по экземплярам (или по функциям в serverless).
Скорость запросов важна не меньше, чем число подключений. Соберите медленные запросы по суммарному времени и по p95/p99. Несколько запросов на 2–5 секунд могут закрепить соединения достаточно долго, чтобы заблокировать всё остальное.
Сигналы, которые обычно объясняют «внезапные» аварии:
- Открытые подключения против лимита Postgres и скорость их роста
- Время ожидания подключения (время в очереди за свободным соединением)
- Таймауты пула и всплески ошибок (частота и временные метки)
- Параллелизм запросов в момент начала ошибок
- Делят ли фоновая обработка и пользователи одну базу и один пул
Простая проверка реальности: если ваш таймаут получения соединения 10 секунд, а вы видите end‑to‑end задержки API 12 секунд, пользователи обвиняют «сервер», в то время как реальная задержка — ожидание соединения.
Пошагово: настройка пула для долгоживущих серверов
На долгоживущих серверах (VM, контейнеры, всегда‑он поды) самая большая ловушка — забыть, что каждый процесс может иметь свой пул. Десять веб‑воркеров с пулом 20 — это не 20 подключений, а до 200.
Начните с бюджета подключений, который оставляет запас под ваш лимит БД. Если Postgres позволяет 100 подключений, редко стоит давать приложению все 100. Оставьте место для миграций, админских сессий, фоновых инструментов и деплоев.
1) Установите размер пула под реальный параллелизм
Думайте в терминах «сколько запросов выполняются одновременно», а не «сколько пользователей». Медленные запросы увеличивают время удержания каждого соединения, что повышает необходимый пул.
Практический подход: установите общий бюджет подключений для всего приложения (обычно 60–80% от лимита БД), затем разделите его между процессами. Начинайте с малого и увеличивайте только если видите очереди и база всё ещё имеет запас. Бюджетируйте воркеров задач отдельно.
2) Добавьте таймауты, которые быстро провалятся (и восстанавливаются)
Две настройки предотвращают тихие нарастания: acquisition timeout (сколько запрос ждёт свободного соединения) и idle timeout (как долго неиспользуемое соединение остаётся открытым). Короткие acquisition timeouts превращают медленное деградирование в видимую, ограниченную ошибку, на которую можно настроить оповещение.
Если выбирать, меньший пул с чёткими таймаутами безопаснее, чем большой пул, который доводит базу до перегрузки.
3) Ограничьте параллелизм выше уровня пула
Если ваш сервер принимает 500 одновременных запросов, а общий бюджет БД — 60 соединений, нужен лимит: количество воркеров, конкуренция запросов или параллелизм обработчиков задач.
Проверьте, что соединения всегда возвращаются, включая пути ошибок. Ищите отсутствующие блоки finally, заброшенные транзакции или долгие ORM‑сессии.
Пошагово: настройка пула для serverless
Serverless меняет математику. Код может выглядеть так же, но платформа может создать много коротких экземпляров одновременно.
1) Установите жёсткие лимиты на экземпляр
Сделайте каждый экземпляр «маленьким» с точки зрения БД. Во многих serverless‑сетапах вам не нужен большой пул внутри каждой функции.
Простые правила:
- Ограничьте размер пула небольшим числом (часто 1–4 на экземпляр)
- Используйте короткий таймаут получения соединения, чтобы запросы падали быстро, а не накапливались
- Установите idle timeout, чтобы неиспользуемые соединения быстро закрывались
- Переиспользуйте пул между вызовами (создайте его один раз вне обработчика запроса)
- Убедитесь, что каждый запрос освобождает соединение, даже при ошибках
Проверка здравого смысла: если Postgres позволяет 100 подключений, а платформа может поднять 50 экземпляров, пул по 5 попытается создать 250 подключений — явно опасно.
2) Контролируйте параллелизм до обращения к БД
Ваш лучший «пул» часто — это ограничение параллелизма. Ограничьте, сколько запросов одна версия сервиса может выполнять одновременно. Это остановит волну соединений при новом релизе, шторме ретраев или всплеске фоновых задач.
Следите за скрытым параллелизмом: Promise.all, webhook‑хендлеры с фан‑аутом, потребители очередей, обрабатывающие несколько сообщений. Всё это умножает количество попыток подключиться, даже при малом пользовательском трафике.
3) Используйте внешний пулер или управляемый прокси, когда можно
Если у платформы есть прокси к базе или вы можете запустить внешний пулер, он сгладит масштабирование serverless и удержит подключения к БД стабильными. Но знайте лимиты: прокси сам может исчерпать ресурсы или начать очередить запросы дольше, чем таймаут функции.
Реальный режим отказа — «новый пул на запрос» плюс ретраи. Десять одновременных инвокаций могут превратиться в 30 попыток подключения за секунды.
Защитные механизмы, которые не дадут мелким проблемам стать аварией
Большинство инцидентов с пулом начинаются как небольшое замедление. Несколько запросов ждут чуть дольше, потом всё сыпется. Защитные механизмы — это быстрое падение, экспоненциальное снижение нагрузки и сохранение работоспособности, пока база восстанавливается.
Определите понятное поведение при ошибке. Если запрос не может быстро получить соединение, он должен завершиться с понятной ошибкой, а не висеть до таймаута выше. Короткие таймауты пула также защищают воркеры, освобождая потоки, чтобы сервис продолжал отвечать.
Ретраи должны иметь жёсткие лимиты. Ретрай каждой упавшей операции может превратить краткий сбой в лавину. Оставляйте ретраи для безопасных операций (например, идемпотентных чтений), добавляйте джиттер и ограничивайте общее время ретраев.
Цепные предохранители (circuit breakers) — следующий уровень. При повторяющихся сбоях БД открывайте предохранитель на короткое окно и сразу возвращайте ошибки для новых запросов, зависящих от БД. Лучше быстро упасть, чем всю систему загнать в медленную коллапсацию.
Грациозная деградация помогает пользователям двигаться дальше. В зависимости от продукта это может быть режим только для чтения при сбоях записи, отдача кэшированных результатов для популярных чтений, временное отключение тяжёлых функций вроде отчётов или дружелюбное сообщение «повторите через 30 секунд» для эндпоинтов, зависящих только от БД.
Оповещайте по ранним сигналам, а не только по жёстким ошибкам. Растущее время ожидания подключения, увеличивающаяся глубина очереди и рост p95 часто появляются за минуты до «слишком многих подключений».
Частые ошибки, которые провоцируют внезапное исчерпание пула
Большинство инцидентов не из‑за огромного пика трафика. Они происходят, когда несколько мелких решений суммируются и съедают ваш запас.
Одна ловушка — выставить размер пула приложения равным лимиту БД. Если Postgres позволяет 100 подключений и вы ставите пул 100, вы не оставляете места для миграций, воркеров, админов или второй копии приложения при деплое.
Масштабирование serverless — ещё одна частая причина. Если каждый экземпляр функции создаёт свой пул, у вас нет «одного пула из 20», у вас «20×N экземпляров», что может превратить лёгкий трафик в шторм подключений за секунды.
Ошибки, чаще всего запускающие внезапный фейл:
- Использование max БД как размера пула приложения вместо резервирования запаса
- Создание отдельного пула на экземпляр serverless (или на каждый запрос)
- Утечки подключений на путях ошибок (ранние return, исключения, отменённые запросы)
- Держание соединений слишком долго (медленные запросы, отсутствующие индексы, длинные транзакции)
- Фоновый шум, конкурирующий с реальными пользователями (health checks, cron, опрос очередей)
Реалистичный сценарий: «пассивное» приложение, health check каждые несколько секунд, cron раз в минуту и один медленный запрос на 10 секунд. При небольшом пуле пара совпадений способна его заполнить.
Быстрая контрольная вилка перед релизом
Многие инциденты под маркой исчерпания пула — на самом деле упущенные проверки: лимиты неизвестны, таймауты непоследовательны, параллелизм оставлен на волю случая.
Сначала зафиксируйте жёсткий потолок. У Postgres есть max_connections, а провайдеры часто резервируют подключения для админских задач. Если вы не знаете реальный доступный максимум, вы не сможете безопасно считать пула.
Перед релизом подтвердите:
- Ваш бюджет подключений:
max_connections, зарезервированные подключения и целевой лимит для приложения - Размер пула и таймауты с запасом, включая явный acquisition timeout
- Настройки параллелизма (особенно в serverless), чтобы один деплой не породил волну подключений
- Самые медленные запросы и основные исправления (индексы и случайные N+1 — частые причины)
- Видимость: дашборды и оповещения по числу подключений, времени ожидания подключения и таймаутам пула (не только по общим 500)
Практический тест: прогоните небольшой нагрузочный тест, моделирующий «лёгкий трафик» (несколько пользователей, кликающие по сайту), и смотрите время ожидания пула и активные подключения. Если что‑то растёт стабильно, вы уже близки к инциденту.
Реалистичный пример: outage при нескольких пользователях онлайн
Малый SaaS работал в тихий вторник: онлайн было шесть человек, пара просмотров дашборда в минуту. Потом пользователи пожаловались, что вход висит, а дашборд выдаёт случайные 500.
Логи не показывали «обычную» недоступность: CPU нормальный, память нормальная. Ключевой признак — повторяющиеся сообщения «timeout acquiring a client» и «remaining connection slots are reserved». Классическое исчерпание пула, хоть трафик и казался лёгким.
Причины — два небольших изменения, вышедшие вместе.
Во‑первых, новая фоновая задача запускалась каждую минуту и обновляла таблицу статистики. Во‑вторых, один запрос дашборда стал медленнее из‑за пропавшего индекса. Этот запрос стал занимать 8–12 секунд, а задача держала соединение всё это время.
Затем деплой перевёл приложение с одного долгоживущего сервера на serverless. Код не стал рискованнее, но параллелизм вырос. Несколько одновременных загрузок страниц плюс пара фоновых задач означали гораздо больше попыток подключения одновременно. Каждый экземпляр имел свой пул, так что общее число подключений быстро росло.
Фикс не был одной волшебной настройкой. Это был набор мелких защит:
- Уменьшили пул на экземпляр, чтобы один экземпляр не мог схватить слишком много соединений
- Ограничили параллелизм, чтобы платформа не порождала бесконтрольную конкуренцию
- Уменьшили таймауты пула, чтобы запросы падали быстро и восстанавливались
- Оптимизировали медленный запрос (добавили индекс и убрали лишние join)
После этого система стала стабильной. Оповещения по «времени ожидания пула» и «активным подключениям» давали предупреждение за минуты до того, как пользователи это почувствовали.
Следующие шаги: стабилизировать пул и получить второе мнение
Если вы только что боролись с исчерпанием пула, не начинайте с угадывания чисел. Сначала назовите свой операционный режим: serverless (много короткоживущих экземпляров), долгоживущие серверы (несколько стабильных процессов) или гибрид. У пулинга разные задачи в каждом случае.
Задокументируйте простой бюджет пула, который делает невозможным запрос от вашего апп‑типа большего числа подключений, чем Postgres может безопасно отдать. Зафиксируйте три вещи: ваш доступный потолок подключений Postgres, пиковое число экземпляров (или число в всплеске) и лимит на экземпляр, а также таймауты «стоп‑знак», чтобы запросы падали быстро, а не накапливались.
Затем прогоните целевой нагрузочный тест, соответствующий реальности. Многие команды тестируют высокую пропускную способность, но пропускают паттерн, который вызывает исчерпание: краткие всплески, медленные запросы и ретраи одновременно. Включите сценарии входа/регистрации, вашу самую медленную страницу и фоновые задачи, работающие одновременно.
Если кодовая база — наследие AI‑генерации, проверьте типичные проблемы: «подключение на запрос», отсутствие очистки на путях ошибок и скрытые ретраи, умножающие параллелизм. Для быстрой проверки FixMyMess (fixmymess.ai) предлагает бесплатный аудит кода, который показывает, где создаются, утекают или удерживаются соединения слишком долго, чтобы вы исправляли причину, а не гадали с числами пула.
Часто задаваемые вопросы
Что на самом деле означает «исчерпание пула подключений»?
Это означает, что приложению не хватает свободных соединений с базой данных. Запросы накапливаются в ожидании, затем доходят до таймаута получения соединения, а пользователи видят медленные страницы, а потом периодические ошибки.
Почему исчерпание пула происходит даже при небольшом трафике?
CPU и общий трафик могут выглядеть нормально, потому что приложение в основном ждёт. Несколько запросов, которые удерживают соединения дольше ожиданий, могут заблокировать весь пул, поэтому даже «маленький» трафик приводит к застою.
Какие самые частые пользовательские симптомы в продакшене?
Ищите длительные зависания (обычно 10–30 секунд), за которыми следуют 500‑ ошибки, сбои при входе или фоновая обработка, которая перестаёт продвигаться. Обновление страницы иногда временно «исправляет» ситуацию, потому что освобождается соединение, но затем проблема возвращается.
Как в реальном коде обычно происходят утечки подключений?
Утечки возникают, когда код получает соединение и не возвращает его по всем путям, особенно на ошибках. Необработанные исключения, ранние return, отменённые запросы и отсутствующая логика очистки — частые причины.
Это проблема «слишком большого числа пользователей» или что‑то другое?
Думайте не о «слишком многих пользователях», а о параллелизме и времени удержания соединений. Пул рассчитан на ограниченное число одновременных запросов; если запросы медленные или транзакции остаются открытыми, каждое соединение дольше занято и пул быстрее исчерпывается.
Чем пуллинг отличается в serverless по сравнению с долгоживущими серверами?
На долгоживущих серверах пул переиспользуется внутри стабильного процесса, поэтому общее число соединений легче предсказать. В serverless платформа может поднять много короткоживущих экземпляров, и каждый экземпляр может открыть свой пул, что быстро множит суммарные подключения.
Какие показатели собрать до изменения настроек пула?
Начните с лимита базы (например, max_connections) и вычтите подключения, зарезервированные для админов, миграций и фоновых воркеров. Затем измерьте пиковые параллельные запросы, время ожидания соединения и медленные запросы по p95/p99 — эти числа объясняют большинство «внезапных» инцидентов.
Какие таймауты и защитные меры предотвращают плавный крах?
Поставьте таймаут получения соединения (acquire timeout), чтобы запросы быстро падали, а не накапливались, и таймаут простоя (idle timeout), чтобы неиспользуемые соединения закрывались. Ограничьте параллелизм запросов и задач так, чтобы приложение не могло принять значительно больше работы, чем позволяет бюджет соединений.
Какие самые большие ошибки, приводящие к исчерпанию пула?
Не ставьте размер пула равным максимуму БД — вам нужно оставить место для деплоев, миграций и админских сессий. Не создавайте пул на каждый запрос, контролируйте ретраи и избегайте медленных запросов внутри долгих транзакций, которые удерживают соединения.
Как быстро стабилизировать AI‑сгенерированное приложение, которое постоянно исчерпывает пул?
Проверьте, нет ли паттернов «подключение на запрос», отсутствующей очистки в ошибках, скрытых ретраев и медленных запросов. AI‑генерированные прототипы часто содержат такие ошибки. Если нужен быстрый второй взгляд, FixMyMess (fixmymess.ai) может провести аудит кода и указать, где создаются, утекают или слишком длительно удерживаются соединения, чтобы вы исправляли причину, а не угадывали настройки пула.