Исправление проблем «работает на моей машине»: конфигурация для dev, staging, prod
Исправьте проблемы «работает на моей машине» с явным разделением dev, staging, prod, валидацией env‑переменных и простыми проверками, которые предотвращают сюрпризы в рантайме.
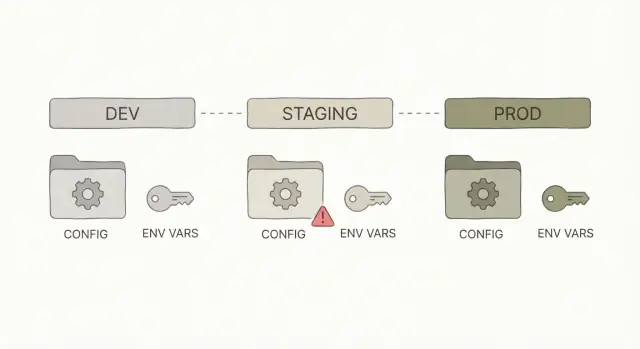
Что обычно означает «работает на моей машине"
Когда кто‑то говорит «работает на моей машине», это значит, что приложение нормально запускается на его ноутбуке, но ломается после деплоя. Код может быть тот же, но окружение вокруг него другое.
Чаще всего это не «ошибка логики». Это конфигурация: приложение получает разные входные данные в зависимости от места запуска. Локально ваш компьютер тихо подставляет нужные вещи (сохранённые логины, локальные файлы, заполненные базы данных, закешированные токены). В staging или production этих «костылей» нет.
Распространённые причины:
- Отсутствующие или неверные переменные окружения (ключи API, URL базы данных, callback URL для аутентификации)
- Разные внешние сервисы (локальный SQLite vs размещённый Postgres, тестовый Stripe vs боевой Stripe)
- Разные URL и редиректы (localhost vs реальный домен)
- Разные настройки билда и рантайма (версия Node, порт, feature‑флаги)
- Секреты, захардкоженные в коде или
.envи никогда не установленые в проде
Проблемы с конфигом часто проявляются как запутанные симптомы: вход работает локально, но падает после деплоя; платежи таймаутятся; изображения не загружаются; фоновые задания не запускаются. Путь в коде тот же, но приложение смотрит не туда или ему не хватает обязательного значения.
Цель — повторяемость запусков в каждом окружении. Dev, staging и prod могут использовать разные значения, но они должны следовать одним и тем же правилам. Если переменная обязательна в проде, считайте её обязательной везде. Если в staging используется другая база, она всё равно должна иметь ту же схему и тот же тип подключения.
Пример: приложение на базе AI развернули и оно сразу падает с ошибкой «DATABASE_URL is undefined». Локально у разработчика он был в приватном .env файле. В проде — не установлен. Починка — не поиск в коде, а объявление обязательной конфигурации, её проверка при старте и установка в каждом окружении.
Dev vs staging vs prod: что меняется и что не должно
Dev, staging и prod — это одно и то же приложение в трёх разных местах.
- Dev — место для быстрой сборки и экспериментов на локальной машине.
- Staging — репетиция, которая должна вести себя как прод, но без реальных пользователей.
- Prod — живая система, от которой зависят люди.
Некоторые вещи в окружениях должны меняться, потому что они указывают на разные сервисы или данные. Другие вещи должны оставаться идентичными, чтобы вы действительно тестировали то, что собираетесь выпустить.
Что должно меняться
Держите код приложения тем же, но меняйте значения вокруг него:
- URL сервисов (базовый API, OAuth callback, webhook URL)
- Ключи и секреты (разные учётные данные для каждого окружения)
- Источники данных (отдельные базы и бакеты, или хотя бы отдельные схемы)
- Feature‑флаги (в проде безопасные дефолты, в dev — больше переключателей)
- Уровень логирования (подробнее в dev, тише в prod)
Окружение должно задавать эти значения, а не локальная машина разработчика.
Что не должно меняться
Билд и рантайм должны совпадать между staging и prod: одинаковые зависимости, одинаковый шаг билда, одинаковая команда старта и та же версия рантайма. Если в staging используется node 20, а в prod — node 16, вы тестируете разное приложение.
Избегайте «быстрой правки в проде», например редактирования конфигурации на сервере или добавления пропавшей переменной вручную без записи. Такие одноразовые фиксы приводят к ошибкам, которые потом не воспроизвести. Частый пример: кто‑то по‑горячему правит callback URL в проде, staging остаётся старым, и следующий деплой ломает вход.
Переменные окружения 101 (без жаргона)
Переменная окружения (env var) — это настройка, которую приложение читает при старте. Она живёт вне кода, обычно задаётся в терминале, в панели хостинга или инструменте деплоя.
Думайте об env vars как об входных данных для приложения. Обращайтесь с ними как с требованиями, а не рекомендациями. Если значение отсутствует, приложение должно быстро падать с понятным сообщением, а не ползти дальше и ломаться позже.
Простой способ решить, что куда помещать:
- Env vars: значения, которые меняются по окружениям или являются чувствительными. Примеры:
DATABASE_URL,JWT_SECRET,STRIPE_API_KEY,S3_BUCKET,APP_ENV. - Код: дефолты и логика, которые одинаковы везде. Пример: «сессии истекают через 7 дней».
- Конфиг‑файлы (под контролем версии): не‑секретные настройки, которые нужно ревьюить. Пример: feature‑флаги, метки интерфейса, allowed CORS origins (только если они не секретны).
Именование — где команды чаще всего путаются. Выберите соглашение и придерживайтесь его: заглавные буквы, слова через подчёркивание, и один префикс для нескольких сервисов. Избегайте почти‑дубликатов вроде DB_URL, DATABASE и DATABASE_URL в разных частях приложения.
Распространённая ловушка — «необязательные» переменные, которые тихо отключают фичи. Например, приложение может отправлять почту в блоке if (process.env.SMTP_PASSWORD) и не предупреждать при отсутствии. В результате: локально регистрация работает, но в проде письма по сбросу пароля не приходят.
Лучшее правило: если фича включена в окружении, её обязательные переменные должны быть установлены, иначе приложение должно остановиться и сообщить, чего не хватает.
Пошагово: настройте простую и согласованную структуру конфигурации
Большинство багов «работает на моей машине» возникают потому, что конфигурация разбросана. Один человек ставит значения в локальный файл, другой — в панель хостинга, и приложение тихо берёт то, что увидит первым. Решите, где «истина», и придерживайтесь этого.
1) Выберите единый источник правды
Для большинства веб‑приложений самое чистое правило: переменные окружения — источник правды. Локальный .env может быть удобен для разработки, но код должен читать конфиг одинаково везде.
Если нужно поддерживать и файл, и env vars, задайте явный приоритет (например: env vars переопределяют значения из файла) и задокументируйте это, чтобы не было сюрпризов.
2) Добавьте один явный флаг окружения
Пусть приложение объявляет, в каком оно окружении. Используйте одну переменную, например APP_ENV с тремя допустимыми значениями: development, staging, production. Не делайте догадок по доменам или флагу debug.
Когда окружение явно, можно безопасно выбирать дефолты: более подробные логи в dev и тише в prod.
Практическая настройка для большинства команд:
- Держите в репозитории файл-шаблон
.env.example, в котором перечислены все требуемые переменные (без реальных секретов). - Используйте локальный
.envтолько для удобства разработки и исключайте его из VCS. - Значения для staging и production храните в настройках провайдера хостинга.
- Загружайте конфиг в одном месте (один модуль конфигурации) и импортируйте его везде.
3) Делайте дефолты безопасными
Дефолты допустимы для разработки (например, локальный URL базы), но в проде избегайте дефолтов для чувствительных вещей. Отсутствие DATABASE_URL в проде должно приводить к быстрому падению, а не к тихому переходу на неверный ресурс.
4) Документируйте, что нужно коллегам для запуска
Соберите список обязательных переменных в одном месте (обычно .env.example + короткая заметка в README). Это особенно важно для AI‑сгенерированных приложений, где конфиг имеет тенденцию расти хаотично и шастать между кодом, файлами и панелями хостинга.
Валидируйте env vars при старте, чтобы избежать сюрпризов
Многие проблемы появляются потому, что приложение стартует с пропущенными или неверными настройками, а ломается позже при обращении к определённой странице. Простое решение — валидировать переменные окружения на старте и не запускать приложение, если что‑то не так.
Быстро падать с понятными проверками
Обращайтесь с конфигом как с входными данными. Если обязательные значения отсутствуют, останавливайте приложение и выводите ошибку с указанием того, что нужно установить (не раскрывая секретов).
Что стоит валидировать заранее:
- Наличие: обязательные значения, например
DATABASE_URL,AUTH_SECRET,PORT - Тип:
PORT— число,DEBUG— boolean, timeouts — целые числа - Формат: URL выглядят как URL, email выглядят как email
- Кросс‑проверки полей: если
FEATURE_X=true, требуйтеFEATURE_X_KEY - Допустимые значения:
APP_ENV— одно изdevelopment,staging,production
После валидации логируйте короткое резюме старта: имя окружения, версия приложения и какие опциональные фичи включены. Не выводите секреты, полные строки подключения или токены. При необходимости логируйте только факт, что значение установлено, или безопасный отпечаток (например, последние 4 символа).
Добавьте команду самопроверки конфига
Лёгкая команда‑тест конфигурации делает деплои безопаснее, потому что её можно запустить до старта сервера.
Например:
config:testзагружает env vars, валидирует их и выходит с кодом 0/1- Печатает понятные ошибки (какие ключи пропущены, неверные типы, недопустимые URL)
- Может проверять доступность сервисов там, где это безопасно (например, достижимость хоста БД) без дампа учётных данных
Держите секреты вне кода (и вне логов)
«Секрет» — это всё, что даёт доступ: API‑ключи, OAuth‑секреты, ключи подписи сессий, пароли БД, приватные ключи шифрования, секреты вебхуков и даже внутренние токены. Если кто‑то их получит, он может притвориться вами или вашим приложением.
AI‑сгенерированные приложения часто «сливают» секреты в двух местах: в коде и в логах. Ключ захардкожен «на скорую руку», строка подключения попадает в коммит, или кто‑то печатает process.env для отладки и забывает убрать это перед релизом.
Правила, предотвращающие большинство инцидентов:
- Никогда не коммитьте секреты в репозиторий, даже «временные».
- Никогда не отправляйте секреты в браузер или мобильный клиент. Если пользователь видит — это не секрет.
- Никогда не логируйте секреты или заголовки целиком. Редактируйте токены и пароли.
- По возможности предпочитайте короткоживущие токены.
Если подозреваете утечку, считайте ключ скомпрометированным. Проводите ротацию, затем убедитесь, что старое значение действительно недействительно (многие платформы держат старые ключи активными до явного отключения). Проверьте историю деплоев, логи и любые скриншоты или отчёты об ошибках.
Используйте отдельные учётные данные для каждого окружения. Dev, staging и prod не должны разделять одного и того же пользователя БД, API‑ключ или секрет подписи. Тогда утечка в staging не даст доступа в prod.
Сделайте staging достаточно похожим на production
Staging — место, где вы ловите проблемы, проявляющиеся только после деплоя, но это работает только если staging похож на prod по критичным аспектам.
Начните с повторяемых сборок. Если в staging используется Node 20, а в prod — Node 18, или в одном окружении устанавливаются другие версии зависимостей, вы тестируете не то же самое приложение. Зафиксируйте версию рантайма и зависимости (pin‑ьте версии, коммитьте lockfile и используйте одинаковую команду билда везде). Избегайте шагов установки, зависящих от окружения, которые меняют поведение или пропускают проверки.
Держите staging близким к prod по критическим путям: тот же тип базы, тот же кеш или очередь, если вы их используете, и та же последовательность старта (миграции, сиды, фоновые процессы). Не обязательно полно‑масштабные данные, но те же сервисы и порядок операций.
Проверки состояния — ваша ранняя система оповещений. Хороший staging‑деплой должен падать сразу, если не может подключиться к БД, если миграции ожидают применения или если отсутствуют обязательные переменные окружения.
Простые стандарты:
- Одинаковый рантайм и lockfile зависимостей в dev, staging и prod
- Тот же артефакт сборки, который продвигается из staging в prod (не пересобирайте по‑другому)
- Те же шаги старта (мигрировать, затем запускать веб‑процесс, затем воркеры)
- Базовый health check, который проверяет подключение к БД и пару ключевых эндпоинтов
- Запись «отпечатка» конфига на каждый деплой (какие имена env vars были установлены, какие feature‑флаги включены) без значений
Частые ошибки, приводящие к runtime‑сбоям
Большинство багов «вчера работало» — не случайны. Они обычно идут от конфигурационного дрейфа: кто‑то поменял настройку, сделал хотфикс или подправил секрет в одном месте и забыл задокументировать. Через неделю деплой откатывает код, но не настройки, и приложение ломается непонятно как.
Другой классический провал — опора на локальные файлы, которых не будет в проде. На ноутбуке может быть папка uploads/ с нужными правами, локальная SQLite‑база или .env, который не попадёт на сервер. В проде файловая система может быть только для чтения, контейнеры перезапускаются, и «этого файла» просто нет.
Ошибки, которые часто превращаются в аутейджи:
- Восприятие предупреждений как нормальных: пропущенные env vars, дефолтные падения или «опциональные» настройки, которые потом становятся обязательными
- Смешение клиентских и серверных переменных в веб‑приложениях, утечка секретов или сломанные сборки, когда браузер не может читать серверные значения
- Забвение зарегистрировать OAuth или callback URL платежей для конкретного окружения
- Предположение, что локальные пути существуют везде (uploads, temp, локальные файлы БД, сертификаты)
- Нефиксирование экстренных изменений в панели хостинга в общей документации
Небольшой пример: основатель имеет AI‑сгенерированный прототип, который работает в хостинге для разработки, но в проде вход падает. Корень оказался прост: приложение падало к dev callback URL, потому что продовая переменная отсутствовала. Никаких ясных ошибок, просто цикл редиректов.
Быстрый чек‑лист перед релизом
Короткая процедура перед релизом ловит большинство конфигурационных проблем. Прогоняйте её в том же окружении, в которое выпускаете (staging для репетиции, production для реального релиза).
- Убедитесь, что все обязательные env vars установлены (и не пусты). Перепроверьте значения, которые различаются по окружениям: базовые URL, ключи API, настройки почты.
- Проверьте, что приложение смотрит на правильную базу и хранилище (хост/имя БД, бакет хранения, очередь, кеш). Одна неверная переменная может направить трафик продакшна в staging.
- Проверьте настройки аутентификации end‑to‑end: callback URL, домен cookie, настройки сессий, allowed CORS origins.
- Запустите валидацию конфига перед релизом. Приложение должно отказываться стартовать, если что‑то критическое отсутствует или явно неверно.
- Прогоните один реалистичный сценарий end‑to‑end в staging: регистрация, вход, сброс пароля, оплата, загрузка, экспорт, приглашение коллеги.
Если staging проходит тесты, а в проде вход падает, обычно причина банальна: redirect URL указывает не на тот домен, домен cookie неверен или не установлен нужный auth‑секрет.
Пример: реальная чистка конфига в AI‑сгенерированном приложении
У основателя был AI‑сгенерированный проект, который локально выглядел нормально, но падал сразу после деплоя. Проблема не была сложной. В проде использовались другие имена переменных, один секрет отсутствовал, а один URL всё ещё указывал на localhost.
Что сломалось после деплоя
Пользователи могли открыть сайт, но вход не работал. Симптомы разные: иногда белый экран, иногда общий 500.
Корневые причины:
- OAuth callback URL всё ещё был
http://localhost:3000/... - В проде не установлен обязательный секрет для подписи сессий/токенов
- В production по ошибке использовался URL базы от staging
Как мы исправляли (без догадок)
Сначала мы провели аудит переменных окружения: все значения, которые приложение читает, откуда они берутся и в каком окружении нужны.
Дальше стандартизировали имена и чётко разделили значения для dev, staging и prod.
Добавили защитные механизмы, чтобы ошибки проявлялись сразу:
- Валидировать обязательные переменные при старте и показывать, чего не хватает
- Проверять форматы (в проде URL обязаны быть HTTPS, секреты — минимальной длины)
- Блокировать небезопасные дефолты в проде (никаких localhost‑callback, никаких заглушек)
- Логировать только безопасные подсказки (никогда не печатать секреты)
После этих изменений деплои стали предсказуемыми. Staging стал вести себя как prod там, где это важно, и проблемы появлялись при старте, а не в момент входа пользователя.
Следующие шаги: укрепляйте конфиг без зацикливания
Не пытайтесь всё сразу идеализировать. Выберите одно небольшое изменение, которое сразу уменьшит число сюрпризов, проверьте его локально и после деплоя, затем сделайте короткий цикл до следующего релиза.
Хорошие «победы на сегодня":
- Добавьте
.env.example, где перечислены все обязательные переменные (с безопасными плейсхолдерами) - Добавьте валидацию при старте, чтобы приложение падало при пропуске или неверном формате переменных
- Уберите захардкоженные ключи, URL и debug‑флаги из кода и перенесите их в окружение
- Перестаньте печатать секреты в логах (даже «временные» отладочные логи)
- Переименуйте запутанные переменные, чтобы их назначение стало очевидным
Затем выполните ограниченный план усиления:
- Сравните имена переменных в dev, staging и prod и убедитесь, что различаются только значения
- Перепроверьте настройки аутентификации для каждого окружения (callback URL, cookie‑домен, OAuth настройки)
- Убедитесь, что секреты хранятся в хранилище секретов платформы деплоя, а не в репозитории
- Сделайте чистый деплой с нуля, чтобы выявить отсутствующие переменные и неверные предположения
Если вы унаследовали запутанный AI‑сгенерированный репозиторий, начните с аудита конфигурации и секретов — обычно именно там прячутся скрытые дефолты, утечки и ошибки, проявляющиеся только при деплое.
Если вы застряли, FixMyMess (fixmymess.ai) специализируется на диагностике и ремонте таких проблем: конфиг‑дрейф, ошибки аутентификации, утёкшие секреты и готовность к деплою.
Часто задаваемые вопросы
Что на самом деле означает «работает на моей машине»?
Обычно это значит, что с кодом всё в порядке, но окружение отличается после деплоя. Что‑то, что на ноутбуке подставлялось автоматически (env‑переменные, локальные файлы, кешированные токены, заполненные данные, другая база), отсутствует в staging или production, и приложение ломается хотя в репозитории ничего не менялось.
С чего начать, если приложение ломается только после деплоя?
Начните с проверки конфигурации, а не бизнес‑логики. Сравните переменные окружения, версии времени выполнения (например, Node), и конечные точки сервисов между локальной машиной и продом, затем попытайтесь воспроизвести проблему с теми же входными данными, которые видит сервер.
Какая самая распространённая конфигурационная ошибка при падении деплоя?
Самая частая ошибка — отсутствующие или неверные переменные окружения. Типичный признак: ошибка вроде DATABASE_URL is undefined или фичи молча не работают, потому что в проде не установлен ключ.
Что должно отличаться между dev, staging и production?
Оставляйте один и тот же код, но три набора значений. Dev для быстрой разработки, staging — репетиция, похожая на прод, а prod — живая система. Меняйте URL сервисов, секреты и источники данных по окружениям, но держите одинаковыми билд, версию рантайма и шаги старта.
Что должно быть в env vars, а что — в коде или конфиг‑файлах?
Env‑переменные — это то, что меняется по окружениям или должно быть секретным. В код помещайте бизнес‑правила и дефолты, которые не должны меняться. Файлы конфигурации, попадающие в git, используйте только для не‑секретных настроек, которые можно ревьюить.
Как избежать путаницы с «в каком я окружении»?
Добавьте одну явную переменную вроде APP_ENV и разрешайте только известные значения: development, staging, production. Не угадывайте по домену или флагу debug — это создаёт скрытые различия поведения, которые трудно воспроизвести.
Как сделать так, чтобы проблемы с env vars не проявлялись поздно?
Валидация при старте: отбрасывайте запуск, если обязательные значения отсутствуют или имеют неправильный формат. Так проблемы ловятся до того, как реальные пользователи столкнутся с падениями страниц.
Стоит ли добавлять команду config:test в приложение?
Да. Небольшая команда config:test, которая загружает переменные, проверяет типы и форматы и возвращает код выхода 0/1, — очень полезна как шаг перед деплоем. Она выводит понятные ошибки и позволяет остановить выпуск плохой конфигурации.
Как не допустить утечки секретов в AI‑сгенерированных приложениях?
Храните секреты вне репозитория и клиентского кода, не логируйте их в явном виде. При подозрении на утечку — ротируйте ключи немедленно и убедитесь, что старые значения действительно деактивированы. Используйте разные учётные данные для dev, staging и prod.
Как быстрее всего стабилизировать запутанное AI‑сгенерированное приложение, которое не запускается в проде?
Сначала исправьте структуру конфигурации: централизуйте загрузку конфигурации, упростите имена переменных и добавьте валидацию при старте. Если репозиторий в плохом состоянии, аудит конфигурации и секретов обычно даёт самые быстрые результаты.
Кому обратиться, если нужно срочно починить AI‑сгенерированный проект?
FixMyMess (fixmymess.ai) специализируется на диагностике и починке AI‑сгенерированных приложений: конфигурационный дрейф, проблемы с аутентом, утечки секретов и готовность к деплою. Их бесплатный аудит может показать, что именно отсутствует и с чего начать.
Какие простые вещи чаще всего ломают вход в продакшне?
Проверьте, не оставлено ли в проде локальное значение callback URL, не использованы ли неправильные имена переменных или не смешались ли staging‑учётные данные с продовыми. Часто причина — одна пропущенная переменная, из‑за которой происходят редирект‑циклы или 500‑ые ошибки.