Кеширование и пагинация для медленных страниц‑списков: практические паттерны
Узнайте про кеширование и пагинацию для медленных страниц списков: курсорная пагинация, дизайн ключей кэша и безопасные альтернативы API, которые «загружают всё».
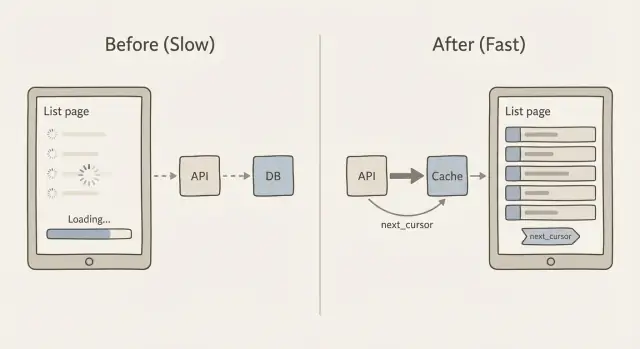
Почему страницы‑списки тормозят по мере роста данных
Страница‑список часто выглядит нормально при 200 строках, но затем внезапно начинает «ломаться» при 20 000. Пользователи видят медленную прокрутку, вечные индикаторы загрузки и фильтры, которые отвечают секунды. Иногда страница мерцает пустым состоянием, потому что запрос таймаутится или клиент отказывается ждать и рендерит ничего.
Корень проблемы прост: каждая дополнительная запись заставляет систему делать больше работы. База данных должна найти строки, отсортировать их и применить фильтры. API должна превратить их в JSON. Сеть должна передать эти данные. Затем браузер (или мобильное приложение) должен разобрать их, выделить память и отрисовать.
Куда уходит время
По мере роста набора данных замедления обычно приходят из смеси следующих причин:
- Работа базы данных: большие сканирования, тяжёлые джойны и сортировка больших результатов.
- Размер полезной нагрузки: возврат сотен или тысяч строк за один запрос.
- Стоимость рендеринга: UI пытается отрисовать слишком много элементов сразу.
- Повторяющиеся запросы: тот же список запрашивается снова и снова без кэша.
Сортировка и фильтрация имеют скрытую стоимость, потому что часто заставляют базу задействовать намного больше данных, чем вы ожидаете. Например, фильтр “status = open” дешев при правильном индексе, но «поиск по подстроке в имени» или «сортировка по последней активности» быстро становятся дорогими. Ещё хуже — пагинация через OFFSET (страница 2000) заставляет базу пройти тысячи строк, лишь чтобы достать следующую страницу.
Цель — не «сделать быстро один раз». Цель — предсказуемое время ответа по мере роста данных. Это обычно означает возвращать меньше записей за запрос, использовать пагинацию, которая не замедляется на глубоких страницах, и кэшировать ответы списков, чтобы повторные посещения не платили полную цену каждый раз.
Избегайте эндпойнтов «вернуть всё»
Одна из причин, почему страницы‑списки тормозят — это API, которое возвращает всю таблицу, потому что так было проще на этапе прототипа. Обычно это выглядит так:
GET /api/orders
200 OK
[
{ "id": 1, "customer": "...", "notes": "...", "internalFlags": "...", ... },
{ "id": 2, ... }
]
Это терпит крах в масштабе, потому что умножает работу сразу в трёх местах: базе нужно сканировать и сортировать больше строк, серверу нужно сформировать и отправить огромный JSON, а браузеру — распарсить и отрисовать длинный список. Даже если позже вы добавите кэш и пагинацию, эндпойнт «дай мне всё» остаётся дорогим для генерации и передачи.
Мобильные устройства и ненадёжные сети ощущают это первыми. JSON‑ответ в 5–10 МБ может быть нормален в офисном Wi‑Fi, но может таймаутиться в 4G, садить батарею и делать приложение «ломаным». Это также усложняет восстановление после ошибок: при неудаче пользователь теряет всю страницу, а не только следующий фрагмент.
Вот простое правило, которое держит вас в рамках: отсылайте только то, что пользователь видит сейчас. Обычно это небольшая страница (например, 25–100 строк) и только поля, нужные для представления списка.
Когда команды приносят FixMyMess с AI‑сгенерированной админкой, мы часто видим list‑эндпойнты, возвращающие полные записи (включая большие текстовые поля) без лимита. Быстрое улучшение — вернуть компактную форму «элемента списка» и грузить детали только при открытии строки. Это изменение само по себе может сократить время запроса, размер ответа и время рендера на клиенте без правок дизайна UI.
Курсорная пагинация простыми словами
Многие list‑эндпойнты стартуют с OFFSET‑пагинации: «дайте страницу 3» значит «пропустите первые 40 строк и верните следующие 20». Это кажется простым, но с ростом таблицы становится медленнее, потому что база всё равно пробегает пропущенные строки.
OFFSET‑пагинация также ведёт себя странно, когда данные меняются во время навигации. Если добавляются новые строки или удаляются старые, следующая страница может показывать дубли или пропускать элементы. Вы попросили «страницу 3», но «страница 3» нестабильна.
Курсорная пагинация решает это, используя закладку вместо номера страницы. Клиент говорит: «дайте мне следующие 20 элементов после последнего элемента, который я видел». Это значение «после» и есть курсор. Это основная идея при работе с кешированием и пагинацией для медленных страниц: держать каждый запрос маленьким, предсказуемым и быстрым.
Что такое курсор на самом деле
Курсор обычно — небольшой набор значений из последней строки текущего ответа. Чтобы он был стабильным, ваш список должен иметь последовательный порядок сортировки без равенств. Частая схема — сортировка по created_at с id как tie‑breaker (например: сначала новые, а если у двух строк одинаковая метка времени — по id).
Эта стабильная сортировка важна, потому что гарантирует, что «после этого элемента» всегда указывает в одно конкретное место списка.
Как работает next_cursor
Концептуально сервер возвращает:
- Элементы для этого запроса (скажем, 20)
next_cursor, который представляет последний элемент в этом наборе
Если дальше элементов нет, next_cursor пуст или отсутствует. Клиент сохраняет его и шлёт назад, чтобы получить следующий срез. Никакого подсчёта страниц, никаких огромных пропусков и гораздо меньше сюрпризов при изменяющемся списке.
Шаг за шагом: реализуем API с курсорной пагинацией
Курсорная пагинация — рабочая лошадка при кешировании и пагинации медленных списков. Она держит страницы стабильными и быстрыми, даже когда добавляются новые строки.
1) Выберите стабильный порядок сортировки
Выберите порядок, который не меняется для данной строки. Частый выбор — created_at desc, id desc. id как tie‑breaker важен, когда много строк имеют одинаковую метку времени.
2) Определите форму запроса и ответа
Держите запрос маленьким и предсказуемым: limit, опциональный cursor и любые фильтры, которые вы уже поддерживаете (status, owner, search).
Простая форма ответа выглядит так:
{
"items": [/* results */],
"next_cursor": "opaque-token",
"has_more": true
}
3) Безопасно кодируйте и декодируйте курсор
Не кладите в курсор сырые SQL‑фрагменты или смещение базы. Сделайте его непрозрачным токеном, который содержит только то, что нужно для продолжения, например created_at и id последней строки.
Практичный формат — base64‑закодированный JSON, опционально подписанный (чтобы клиенты не могли его подделать). Пример полезной нагрузки внутри токена: { "created_at": "2026-01-10T12:34:56Z", "id": 123 }.
4) Запрос с использованием курсора (и обработка вставок)
С created_at desc, id desc ваш следующий запрос должен брать строки «до» курсора:
created_at < cursor_created_atOR (created_at = cursor_created_atANDid < cursor_id)
Это удерживает пагинацию стабильной, даже если новые элементы вставляются в начало, пока пользователь листает.
5) Добавьте ограничители
Установите значение по умолчанию (например, 25) и жесткий максимум (например, 100). Валидируйте cursor, limit и фильтры. Если курсор недействителен, возвращайте понятную ошибку 400. В FixMyMess такие защитные ограждения часто отсутствуют в AI‑сгенерированных эндпойнтах, и именно поэтому листы падают под реальной нагрузкой.
Проектирование ключей кэша для ответов списков
Кеширование списков кажется простым, пока вы не вспомните, сколько «разных списков» может порождать приложение. Один эндпойнт может поддерживать поиск, фильтры, опции сортировки, разные размеры страниц и курсорную пагинацию. Если ваш ключ кэша игнорирует даже один из этих входов, вы рискуете показать неправильные результаты не тому пользователю.
Хороший ключ кэша — уникальный отпечаток точного ответа списка. Включайте всё, что меняет набор или порядок строк. Обычно это значит:
- Область: публичный vs пользовательский vs по организации (и соответствующий id)
- Входы запроса: фильтры, текст поиска и сортировка
- Пагинация: курсор (или маркер «первая страница») и limit
- Версия: опциональный тег схемы или «list‑v2», чтобы безопасно менять формат
Держите ключ читаемым. Простая схема, которая хорошо работает:
resource:scope:filters:sort:cursor:limit
Например: tickets:org_42:status=open|q=refund:created_desc:cursor=abc123:limit=25. Нормализуйте входы, чтобы разные написания не создавали лишних промахов (обрезайте пробелы, сортируйте параметры фильтра и используйте единый разделитель).
Решите, что именно кэшируете. Многие команды кэшируют только первую страницу — она чаще всего запрашивается и получает большую выгоду от короткого TTL. Кэширование каждой страницы тоже поможет, но взрывает число ключей и усложняет инвалидaцию при изменениях данных.
Не кэшируйте, когда это скорее вредит, чем помогает: сильно персонализированные списки (например, «рекомендации для вас»), списки, которые меняются каждые несколько секунд, или списки с проверками прав доступа, которые сложно корректно закодировать в ключе.
Если вы работаете над кешированием и пагинацией медленных списков в AI‑сгенерированном приложении, следите за эндпойнтами, которые случайно делают cursor опциональным и падают в режим «вернуть всё». Это частая проблема, которую FixMyMess исправляет, ужесточая дефолты пагинации и включая полный контекст запроса в ключи кэша.
Как держать кэш свежим, не усложняя систему
Большинству страниц‑списков не нужна идеальная, моментальная свежесть. Им важно быть быстрыми и «достаточно свежими» для цели пользователя. Это ключ к тому, чтобы кеширование и пагинация работали без превращения инвалидации кэша в отдельный продукт.
TTL против ивентной инвалидации (по‑простому)
TTL (time to live) — самый простой вариант: кэшируйте список на 30–120 секунд, затем обновляйте. Это просто и надёжно, но может показывать слегка устаревшие данные.
Ивентная инвалидация пытается быть точной: когда запись меняется, вы немедленно удаляете затронутые закэшированные списки. Это может дать очень свежие данные, но усложняется тем, что одно изменение может затронуть множество фильтров и сортировок.
Практичный компромисс — "stale while revalidate": отдать кэшированный ответ, даже если он немного стар, а затем обновить его в фоне. Пользователи получают быстрый интерфейс, а кэш самовосстанавливается после изменений.
Целенаправленная инвалидация, которая остаётся управляемой
Вместо «удалить всё» инвалидируйте только то, что можно чётко описать:
- По пользователю или арендатору (только их списки)
- По типу ресурса (orders vs customers)
- По группе фильтров (status=open, tag=vip)
- По «версии коллекции» (счётчик, который вы увеличиваете при записи)
Последний вариант часто самый простой: включите collection_version в ключ кэша. Когда что‑то меняется — инкрементируйте версию, и старые записи больше не используются.
Кеш‑штампы возникают, когда много запросов одновременно промахиваются и все пересобирают кэш. Две простые защиты:
- Добавьте джиттер к TTL (случайно +/- 10–20%)
- Коалесценция запросов (один строит, остальные ждут)
- Отдавайте устаревший ответ на короткое время, пока строится новый
Наконец, решите, какая согласованность вам действительно нужна. Для большинства админских и лентовых страниц «обновления появляются в пределах 1–2 минут» — нормально. Для операций с деньгами или правами доступа лучше не кэшировать список вовсе или держать очень короткий TTL и проверять детали на странице элемента.
Клиентские паттерны пагинации, которые остаются быстрыми
У большинства экранов со списком есть понятный трафиковый паттерн: пользователи чаще всего попадают на страницу 1. Кэшируйте первую страницу на клиенте (в памяти или localStorage) с коротким TTL и показывайте её сразу, обновляя в фоне. Это решает ощущение «пустого экрана», из‑за которого список кажется медленным.
При курсорной пагинации считайте курсор частью идентичности страницы. Держите небольшой словарь cursor -> rows, чтобы возврат назад не триггерил новые запросы и UI оставался отзывчивым даже при плохой сети.
Предзагрузка следующей страницы помогает, но только аккуратно. Безопасный подход — предзагружать, когда пользователь близок к низу или после паузы в прокрутке, и отменять запрос, если изменились фильтры или сортировка.
- Предзагружайте только одну страницу вперёд
- Дебаунс триггера (например, 200–400 мс)
- Блокируйте предзагрузку, если есть активный запрос
- Не предзагружайте для дорогих фильтров (например, полнотекстовый поиск)
- Останавливайте предзагрузку, когда вкладка скрыта
Состояния загрузки важнее, чем кажется. Используйте «мягкий» индикатор загрузки (сохраняйте видимыми уже загруженные строки) и очевидную кнопку повтора при ошибках. При повторной попытке добавляйте результаты только после подтверждения, что они относятся к тому же запросу (те же фильтры, сортировка и курсор), иначе получите дубли или смешанные строки.
Клиентская дедупликация — ваша страховка. Всегда сливайте строки по стабильному id, а не по индексу массива или метке времени. Если вы получаете одну и ту же строку дважды, заменяйте её на месте, чтобы список не «прыгал».
Infinite scroll не всегда лучше. Для админских экранов, где люди часто прыгают между страницами, сравнивают и сортируют, он может быть хуже. Если пользователи часто говорят «я был на странице 7», используйте постраничную навигацию с понятным размером страницы, а infinite scroll оставляйте для фидов, где точная позиция не важна. Это частая правка, которую мы делаем, когда чинитcя AI‑сгенерированные UI, которые случайно перегружают API и кажутся тормознутыми.
База данных и базовые вещи с полезной нагрузкой, которые улучшают кэширование
Кеширование помогает, но не убирает медленные запросы. Кешированный ответ всё равно должен быть сгенерирован хотя бы раз, а промахи кэша происходят чаще, чем думают (новые фильтры, новые пользователи, истёкшие ключи, деплои). Если запрос к базе не в порядке, вся система будет казаться ненадёжной.
Индексы — первое, куда смотреть. Для страниц‑списков выигрышный шаблон прост: индекс должен соответствовать тому, как вы фильтруете и как вы сортируете. Если эндпойнт делает WHERE status = 'open' и ORDER BY created_at DESC, у базы должен быть путь, поддерживающий оба.
Практическое правило для list‑запросов:
- Индексируйте колонки, которые чаще всего используются в
WHERE. - Включайте колонку сортировки (
ORDER BY) в тот же индекс, когда возможно. - Если вы всегда фильтруете по арендатора/пользователю, эта колонка обычно должна быть первой.
- Предпочитайте стабильные ключи сортировки (
created_at,id), чтобы пагинация и кэширование были предсказуемы. - Перепроверяйте индексы после добавления новых фильтров, а не через месяцы.
Далее: перестаньте отправлять лишние данные. Многие медленные списки медленные потому, что они передают слишком большой JSON, а не потому что база умирает. Избегайте SELECT *. Выбирайте поля, которые действительно показываете в таблице. Если UI требует только id, name, status и updated_at, возвращайте только их. Вы получите более быстрые запросы, меньшие полезные нагрузки и выше вероятность попадания в кэш, потому что ответы дешевле хранить и отдавать.
Будьте осторожны с сортировкой по вычисляемым полям, таким как «full_name» (first + last), «last_activity» из подзапроса или «relevance» из формулы. Такие поля часто заставляют делать сканирования, тяжёлые планы с джойнами или сортировку в памяти. Когда возможно, предварительно вычисляйте значение в реальном столбце или сортируйте по более простому полю и формируйте красивое значение в UI.
Прежде чем углубляться, измерьте два числа:
- Время выполнения запроса (p50 и p95, не только один запуск).
- Размер полезной нагрузки для одной страницы.
- Количество просмотренных строк vs возвращённых.
- Процент попаданий в кэш для list‑эндпойнта.
- Самая медленная комбинация фильтра + сортировки, которой действительно пользуются.
Это особенно часто встречается в AI‑сгенерированных приложениях: эндпойнты «работают» на демо, но когда приходят реальные данные, отсутствие индексов и большие полезные нагрузки делают кэши бесполезными. Исправьте базу сначала, и кэширование станет множителем, а не пластырём.
Пример: починка медленной админской страницы в растущем приложении
Обычная история: админ‑дашборд начинался как AI‑сгенерированный прототип. На 200 строк он работал. Через полгода — 200 000, и список «Пользователи» таймаутится или грузится 10–20 секунд. Люди обновляют страницу, фильтры кажутся случайными, и CPU базы взлетает.
Плохая версия обычно выглядит так: клиент вызывает эндпойнт, который возвращает всё (или использует OFFSET‑пагинацию с большими смещениями), ответ включает тяжёлые поля (профили, настройки, историю аудита), и каждая прокрутка триггерит новый дорогой запрос. Кэша нет, так что одна и та же первая страница пересчитывается для каждого администратора.
Вот практическое исправление кеширования и пагинации для медленных списков, сохраняющее поведение предсказуемым.
Что мы изменили
Мы оставили UI без изменений, но поменяли контракт API:
- Используем курсорную пагинацию: возвращаем
items,nextCursorи всегда запрашиваем сlimit. - Сортируем по стабильному ключу (например,
created_atплюсid), чтобы курсоры не пропускали и не дублировали элементы. - Кэшируем только первую страницу для типичных представлений (например, «Все пользователи, сначала новые»), потому что она чаще всего запрашивается.
- Ограничили фильтры безопасными индексированными полями (status, role, created date). Отклоняем «contains»‑поиск по большим текстовым колонкам, если нет поддержки поиска.
- Обрезали полезную нагрузку: список возвращает только то, что нужно таблице. Детали загружаются на странице пользователя.
Простая форма ответа:
{ "items": [{"id": "u_1", "email": "[email protected]", "createdAt": "..."}], "nextCursor": "createdAt:id" }
Что заметили админы
Первый экран стал появляться быстро, а прокрутка осталась плавной, потому что каждый запрос ограничен. Обновления списка перестали бить по базе, потому что первая страница приходит из кэша. Фильтры стали вести себя консистентно, потому что порядок сортировки и правила курсора ясны.
Чтобы внедрить безопасно, запустите новый эндпойнт за feature‑флагом для внутренних админов, сравните результаты бок о бок и логируйте ошибки курсоров (дубли, пропущенные строки). Если вы наследуете сломанный прототип из Bolt или Replit, команды вроде FixMyMess обычно начинают с быстрого аудита, чтобы найти эндпойнты «вернуть всё» и запросы, которые надо исправить в первую очередь.
Частые ошибки и ловушки
Большинство исправлений медленных списков рушатся по простым причинам: пагинация ненадёжна, кэш небезопасен или эндпойнт можно использовать во вред. Если вы работаете над кешированием и пагинацией медленных списков, вот самые неприятные ловушки.
OFFSET‑пагинация — классическая ловушка. На маленьких данных кажется нормальной, но если вы сортируете по полю без уникальности (например, created_at), новые строки могут врываться посередину, пока пользователь листает. Это создаёт дубли, пропуски или «прыгающую» страницу. Курсорная пагинация избегает этого, но только если порядок сортировки стабилен (например: created_at плюс уникальный id).
Сами курсоры могут быть проблемой безопасности и корректности. Если вы кладёте в курсор сырые id, SQL‑фрагменты или выражения фильтров, пользователи могут угадывать значения, ломать декодирование или форсировать дорогие запросы. Более безопасный паттерн: кодируйте только последние значения сортировки и валидируйте их сервер‑стороне перед выполнением запроса.
Кэширование приносит другой класс ошибок. Самая большая — забыть про область действия. Если ключ кэша не включает пользователя, арендатора, роль и фильтры, вы можете «пролить» данные между аккаунтами. Также следите за историей свежести: смены статуса и удаления — первые вещи, которые замечают пользователи, когда кэш отстаёт.
Пример: админская страница «Orders» показывает paid и pending. Если ключ кэша игнорирует фильтр status=pending, админ может увидеть смешанный список, и кэш даже может шариться с непубличными представлениями.
Пять защит, которые предотвращают большинство инцидентов:
- Всегда устанавливайте max
limitи принудительно применяйте его на сервере. - Используйте стабильную сортировку с уникальным tie‑breaker.
- Делайте курсоры непрозрачными и валидируйте декодированные значения.
- Стройте ключи кэша из области пользователя + фильтров + сортировки + размера страницы.
- Решите, насколько долго допустимы устаревшие данные, и инвалидируйте или сокращайте TTL для быстро меняющихся списков.
Если вы унаследовали AI‑сгенерированное приложение с нестабильной пагинацией, небезопасными ключами кэша или неограниченными эндпойнтами, FixMyMess может провести аудит и указать точные места отказа до релиза.
Быстрый чек‑лист и следующие шаги
Используйте это как финальную проверку при улучшении кеширования и пагинации медленных списков. Маленькие детали решают, останется ли список быстрым при 1 000 строк и при 10 миллионах.
Постройте безопасно (API и кэш)
- Установите жёсткий cap на limit (и здравый default), чтобы никто случайно не попросил 50 000 строк.
- Используйте стабильную сортировку (например, created_at + id), чтобы страницы не пересортировывались между запросами.
- Держите курсор непрозрачным. Относитесь к нему как к токену, а не к полю, которое клиент редактирует.
- Убедитесь, что запрос использует индексы, соответствующие вашим фильтрам и сортировке.
- Сузьте ключи кэша до того, что меняет ответ: пользователь/арендатор, фильтры, сортировка, размер страницы и курсор.
Кеширование работает лучше, когда первую страницу легко переиспользовать, так что начните с неё. Выберите TTL, соответсвующий частоте изменений списка, и добавьте базовую защиту от штампов (лок, коалесценция запросов или отдача устаревшего ответа при ревалидации), чтобы всплески трафика не «расплавили» базу.
Доведите до проверки (тесты и эксплуатация)
- Создавайте новые элементы во время пагинации и подтверждайте, что вы не видите дубликатов или пропусков.
- Меняйте фильтры во время прокрутки и подтверждайте, что клиент сбрасывает состояние, а не смешивает старые и новые страницы.
- Симулируйте медленную сеть и проверьте, что клиент дедупит результаты и игнорирует ответы, пришедшие не по порядку.
- Мониторьте время запросов, процент попаданий в кэш, количество ошибок и размер полезной нагрузки после релиза.
- Логируйте самые медленные list‑эндпойнты с их фильтрами, чтобы нацелить реальные нарушители.
Дальше: если ваш AI‑сгенерированный прототип имеет медленные или сломанные list‑эндпойнты, FixMyMess может провести бесплатный аудит кода, чтобы выявить проблемы пагинации, кэширования и безопасности до релиза.