Когда добавлять реплику для чтения: признаки, маршрутизация и подводные камни
Когда стоит добавлять реплику для чтения: явные признаки, безопасная маршрутизация чтений и как избежать сюрпризов от задержки репликации и неверных предположений.
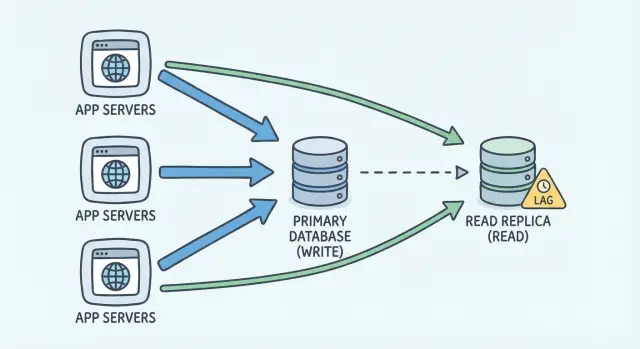
Какую проблему решает реплика для чтения
Реплика для чтения помогает, когда база данных тратит так много времени на обработку чтений, что от этого страдают записи. Речь не только о том, чтобы страницы казались быстрее. Речь о защите первичной базы данных, чтобы она могла продолжать принимать обновления, а не застревать за тяжёлыми SELECT‑запросами.
Обычно это проявляется знакомой схемой: один‑два популярных экрана (или API‑энда) генерируют большую часть работы с БД. Дашборд с частым обновлением, страница поиска или административный список "показать всё" могут сильно съедать CPU и I/O. Тогда части приложения, которые создают заказы, обновляют профили или пишут логи, начинают таймаутиться или вести себя непредсказуемо.
Реплика делает одно простое: даёт ещё одну копию данных для чтения. Приложение может отправлять часть SELECT‑запросов на реплику, чтобы первичная база имела больше «времени на дыхание» для INSERT/UPDATE/DELETE.
Что реплика не исправляет:
- Медленные запросы из‑за плохой структуры или отсутствующих индексов
- Проблемы с блокировками из‑за долгих транзакций на primary
- Слишком много записей (реплика не увеличивает пропускную способность для записи)
- Логику приложения, которая предполагает, что каждое чтение мгновенно актуально
Последний пункт — причина, почему решение должно основываться на корректности, а не только на скорости. Реплика обычно немного отстаёт от первичной. Если читать из неё в неподходящий момент, пользователь может не увидеть только что обновлённые настройки, страница «платёж выполнен» может по‑прежнему показывать неоплаченное, а агент поддержки подумает, что действие не произошло.
Хорошее эмпирическое правило: добавляйте реплику, когда у вас явно преобладают чтения, которые вредят отзывчивости записей, и вы можете назвать конкретные эндпойнты, безопасные для показа слегка устаревших данных.
Основы реплики для чтения (без жаргона)
Реплика — это второй сервер базы данных, держащий копию вашей основной БД. У вас остаётся одна «primary» база как источник правды. Все записи идут туда, потому что только там гарантированно находятся самые свежие данные.
Реплика в основном для чтения. Вместо того чтобы каждый рендер страницы, отчёт или график ударял по primary, часть read‑запросов может идти на реплику, чтобы primary оставалась отзывчивой для записей и критичных операций.
Как копия обновляется
Большинство настроек используют асинхронную репликацию. Проще говоря: primary сначала фиксирует изменения, затем реплика получает и применяет эти изменения с небольшой задержкой. Эта задержка называется replication lag. Иногда она микросекунды или миллисекунды. При нагрузке или всплесках она может вырасти до секунд и больше.
Именно этот факт объясняет большинство неприятных сюрпризов.
Компромисс, который вы выбираете
Реплика может сделать приложение быстрее, но платой будет свежесть данных. Чтения с реплики могут немного отставать от primary.
Простая модель для понимания:
- Primary: правильные данные прямо сейчас, обрабатывает записи
- Replica: масштабирует чтения, может отставать
- Lag: разрыв между тем, что вы только что записали, и тем, что видит реплика
Пример: пользователь обновляет адрес электронной почты и сразу же обновляет страницу профиля. Если страница читает из реплики, она может на некоторое время показать старый email. Это не навсегда неверно, но сбивает с толку, если вы не маршрутизируете чтения осторожно.
Признаки, что пора задуматься о реплике
Реплика полезна, когда база данных большую часть времени занята чтениями (SELECT), а не записями. Если CPU базы высокий и ваши топ‑запросы в основном SELECT, это сильный сигнал.
Ещё один признак — «чтения мешают записям». Вы видите, что задержки записи растут именно в пике чтений, хотя объём записей не меняется. Чтения и записи конкурируют за тот же CPU, память и диск, поэтому тяжёлые отчётные страницы могут замедлять оформление заказов, регистрацию или любые обновления.
Внимательно посмотрите, что именно медленнее. Страницы со списками, дашборды, админские таблицы, результаты поиска и выгрузки часто подходят. Эти эндпойнты сканируют много строк и вызываются часто пользователями или фоновыми задачами.
Нагрузка на пул соединений — ещё один практический триггер. Если вы достигаете лимита подключений в основном из‑за читающих эндпойнтов, реплика может уменьшить конкуренцию. Она не исправит неэффективные запросы, но даст дополнительное «пространство».
Кеширование может отложить необходимость реплики, но не всегда его хватает. Часто вы готовы к реплике, когда:
- Хит‑рейт кеша остаётся низким, потому что данные часто меняются или ключи сложно подобрать
- Кеш приводит к пользовательским «неправильным цифрам»
- Вам нужны «достаточно свежие» данные, но не идеально мгновенные
- Экспорт и ad‑hoc фильтры нельзя безопасно кешировать
- Слой кеша уже является источником багов
Процесс принятия решения, который можно применить
Относитесь к добавлению реплики как к небольшому эксперименту с ясной метрикой успеха. Цель не «добавить больше баз данных», а «снять боль, не нарушив корректности».
Начните с конкретики. «Приложение тормозит» — недостаточно. Нужен короткий список эндпойнтов и запросов, которые вы можете измерить до и после.
Процесс, который подходит большинству команд:
- Определите самые тяжёлые read‑эндпойнты по числу запросов и суммарному времени (дашборд, поиск, лента, отчёты).
- Убедитесь, что узкое место — база данных (а не CPU приложения, медленный код, отсутствующий кеш или отвязанные API‑вызовы).
- Разделите чтения на две корзины: must‑be‑fresh (балансы, права доступа, checkout) и can‑be‑slightly‑stale (аналитика, списки активности, публичные страницы).
- Поставьте измеримую цель, например «снизить нагрузку на primary от чтений на 40%» или «уменьшить p95 времени загрузки дашборда с 3с до 1с».
- Определите план отката: как вы быстро переключите чтения обратно на primary, если что‑то пойдёт не так.
Затем решите, куда именно направлять чтения. Хороший первый шаг — отправлять на реплику только те эндпойнты, которые терпят небольшую усталость данных, и оставлять все записи на primary. Избегайте смешивания чтений и записей в одном запросе на первых порах — именно здесь лаг особенно вреден.
Перед включением в проде выполните быструю проверку безопасности:
- Можно ли определить, какая БД обслуживала запрос (логи, теги, трейсинг)?
- Можно ли обнаружить лаг и временно откатиться на primary?
- Есть ли короткий тест‑план для пользовательской корректности (логин, платежи, права)?
Если вы не можете измерить улучшение и быстро откатиться — остановитесь. Реплика добавляет сложность, поэтому выгода должна быть очевидной.
Какие эндпойнты выигрывают (и какие нужно оставить на primary)
Реплика полезна, когда у вас много чтений, которым не требуется идеальная свежесть. Цель — не переносить всё, а снять нагрузку с primary, сохранив корректность приложения.
Отличные кандидаты для реплики
Обычно безопасные, потому что много чтений и это не про деньги или доступ:
- Публичные страницы (маркетинговые страницы, блог, публичные карточки товаров)
- Поиск и листинги (фильтры, категории)
- Аналитика и отчёты (графики, тренды, выгрузки)
- Админ‑списки (таблицы пользователей, заказов, логов), где клики ведут в детали на primary
- Read‑only API, которыми пользуются партнёры или внутренние инструменты
Просмотры профиля и каталоги товаров часто можно отправлять на реплику с осторожностью. Большинство пользователей не заметят, если аватар или биография обновятся с небольшой задержкой.
Эндпойнты, которые должны оставаться на primary
Если это влияет на деньги или доступ — держите на primary. Сюда входят оформление заказа, платежи, статус подписки и всё, что решает, что пользователь видит или может делать.
Также следите за эндпойнтами, которые кажутся только для чтения, но на самом деле пишут: обновляют last_seen, инкрементируют счётчики просмотров, обновляют сессии или записывают «недавно просмотренное». Если вы направите такой эндпойнт на реплику, он может упасть (реплики часто только для чтения) или вести себя непоследовательно.
Простое правило: отправляйте на реплику только идемпотентные, чисто read‑запросы. Всё, что меняет состояние или решает доступ — оставляйте на primary. Если вы не уверены на 100%, держите на primary, пока не проверите.
Как маршрутизировать чтения, не сделав приложение хрупким
Маршрутизация звучит просто: SELECT на реплику, записи на primary. На практике хрупкость возникает вокруг: управление соединениями, моменты «прочитал — но не видел свою запись» и поведение при отставании реплики.
Два практичных подхода к маршрутизации
Обычно маршрутизацию делают в одном из двух мест.
Если вы маршрутизируете в коде приложения, вы выбираете БД по эндпойнту или даже по запросу. Это явно: «просмотр товаров» использует реплику, а «обновить профиль» — primary. Минус — правила маршрутизации рассредоточены по коду и со временем их сложнее отслеживать.
Если вы маршрутизируете через прокси или роутер баз данных, политики живут в одном месте, что облегчает откат. Риск в том, что это может скрывать сюрпризы: запрос, который вы считали безопасным, может попасть на реплику и показать устаревшие данные.
Сделайте систему устойчивой (и лёгкой для отката)
Относитесь к primary и реплике как к разным ресурсам, а не взаимозаменяемым хостам. Используйте отдельные подключения и отдельные пулы, чтобы медленная реплика не забивала пул для записей.
Небольшой набор правил безопасности предотвращит большинство инцидентов:
- После записи держите пользователя «липким» к primary в течение короткого окна (обычно секунды).
- По умолчанию использовать primary для всего, что связано с деньгами, авторизацией, правами доступа или пользовательским контентом сразу после создания.
- Добавьте kill‑switch, который моментально направляет все чтения на primary (флаг конфигурации, env var, feature flag), и протестируйте его.
- Агрессивно ставьте таймауты на чтения с реплики и при падении возвращайтесь на primary, а не отменяйте запрос.
Пример: дашборд загружает 12 виджетов. Медленные некритичные виджеты (недельные графики, топ‑страницы) читаются с реплики, а «текущий тариф» и «последний счёт» — с primary. Если реплика отстаёт, страница всё ещё работает; только графики будут немного устаревшими.
Как безопасно работать с lag реплики
Replication lag — это время между записью на primary и появлением изменения на реплике. Если приложение читает с реплики слишком рано, пользователи увидят старую информацию и подумают, что что‑то сломалось.
Сначала определите, что для вашего продукта означает «безопасная усталость». Для дашборда отставание в 5–30 секунд может быть допустимо. Для биллинга, паролей или прав доступа даже 1 секунда может быть критичной.
Практические правила, предотвращающие сюрпризы
Несколько правил покрывают большинство кейсов:
- Read‑after‑write: после того как пользователь что‑то изменил, направляйте следующие запросы этого пользователя (или по этой записи) на primary в течение короткого окна.
- Держите критичные экраны на primary: платежи, логин, проверка прав и всё, что может заблокировать пользователя.
- Если вы всё же показываете данные с реплики на критичном экране, показывайте состояние «обновляется» и не записывайте это как финальную информацию.
- Обнаруживайте lag и переставайте использовать реплику, когда она слишком отстаёт.
- Избегайте смешивания результатов primary и replica в одном ответе (это создаёт невозможные комбинации).
Конкретный пример: пользователь меняет email и попадает на страницу профиля. Если страница читает с реплики, она может показать старый email. С read‑after‑write вы направляете профиль этого пользователя на primary в течение 30–60 секунд после сохранения. После этого окна обычные чтения с реплики снова безопасны.
Лаг‑осознанная маршрутизация важна при пиках и деплоях. Реплики обычно отстают, когда primary занят или появляется долгий запрос. Если приложение может измерять lag реплики (или делать простую проверку порога), вы можете вернуть чтения на primary, пока реплика не нагонит.
Что ломается первым при добавлении реплики
Первое, что ломается, — то, что пользователи замечают сразу: «Я сохранил, а ничего не изменилось». Небольшая задержка может перерасти в серьёзную проблему доверия.
Тикеты в саппорт часто растут, когда люди редактируют профиль, меняют настройки или публикуют комментарий, а при обновлении страницы видят старые данные. Планируйте сценарии «прочитай свою запись», а не только увеличение пропускной способности.
Проверки авторизации и прав тоже ломаются быстро. Если пользователь только что повысил план, был добавлен в команду или у него отобрали доступ, чтение с реплики может вернуть прежнее состояние. Это приводит к «почему я всё ещё не вижу доступ?» или, что ещё хуже, «почему я всё ещё вижу доступ?»
Фоновые задания также могут вести себя неправильно. Многие системы джобов читают строку, чтобы решить, нужно ли работать. При устаревших чтениях два воркера могут оба решить, что задача в ожидании, и выполнить её дважды, или пропустить её, потому что реплика ещё не синхронизировала изменение.
Даже когда фактически ничего не сломалось, интерфейс может выглядеть непоследовательно. Пагинация и сортировка будут прыгать, если один запрос попал на primary, а следующий — на отстающую реплику. Вы увидите дубликаты, пропавшие элементы или меняющиеся количества страниц между кликами.
Счётчики дрейфуют быстрее, чем ожидают: лимиты скорости, счётчики просмотров, бейджи непрочитанных уведомлений. Если один запрос инкрементировал значение на primary, а следующий прочитал с отстающей реплики, цифры могут откатиться назад.
Если нужен простой дефолт, держите эти вещи на primary, пока не протестируете тщательно:
- Экраны сразу после записи (сохранение, checkout, настройки)
- Логин, проверки прав и чтения, связанные с сессиями
- Таблицы типа work‑queue, которые используют фоновые джобы
- Всё, что зависит от точного порядка или подсчётов
- Лимиты, квоты и счётчики бейджей
Распространённые ошибки и ловушки
Главная ловушка — отправлять все SELECT на реплику, потому что «это же только чтения». Многие чтения — часть потока, который ожидает последнюю запись: «создать аккаунт», затем «загрузить профиль», или «добавить в корзину», затем «показать корзину».
Ещё одна проблема — скрытые зависимости read‑after‑write. Страница настроек может сохранить предпочтения и сразу перечитать их. Эндпойнт логина может читать запись сессии сразу после её создания. Если эти чтения попадут на реплику во время лага, приложение кажется сломанным, хотя запись прошла успешно.
Обработка соединений — тихий источник боли. Если вы используете один пул соединений для primary и replica, приложение может случайно отправлять записи на реплику (или применять настройки реплики на primary). Даже если это «работает», отладка становится сложнее, потому что логи и метрики не показывают явно, какая БД обслужила запрос.
Мониторинг часто добавляют слишком поздно. Отслеживайте lag, ошибки запросов к реплике и медленные запросы отдельно, и заводите алерты на резкие изменения после деплоя.
Несколько ловушек, которые стоит выделить:
- Маршрутизация по имени эндпойнта вместо по требованию свежести
- Забвение, что админ‑инструменты и фоновые джобы тоже выполняют запросы
- Не тестирование поведения при отказах (реплика упала, резкий рост lag)
- Кеширование устаревших чтений и продление их негарантированной задержки
- Отсутствие быстрого переключателя, чтобы направить весь трафик обратно на primary
Запланируйте откат до релиза. Feature‑flag, заставляющий все чтения идти на primary, может сэкономить часы в инциденте.
Быстрая чек‑лист перед включением
Не начинайте с инфраструктуры. Начните с проверки безопасности, чтобы не обменять медленные страницы на путающие баги «почему моё изменение не сохранилось».
- Перечислите самые тяжёлые экраны по чтениям и отметьте, насколько свежими должны быть данные.
- Определите правило read‑after‑write (кто остаётся на primary, на какое время и какие экраны покрываются).
- Измерьте lag реплики и решите порог, при котором вы перестаёте её использовать.
- Убедитесь, что у вас есть kill‑switch и он работает.
- Делайте rollout постепенно и следите за таймаутами, ошибками и пользовательскими несоответствиями.
Простой пример: ускоряем дашборд, не ломая UX
Представьте небольшое SaaS‑приложение. Дашборд показывает графики, «топ‑клиентов» и фильтры по датам, которые запускают тяжёлые отчётные запросы. В то же время настройки обрабатывают платёжные данные, членов команды и права доступа. Трафик растёт, дашборд начинает тормозить, и записи чувствуют себя медленнее в пиковые часы.
Это хорошее время подумать о реплике: не потому что вам нужна новая БД, а потому что тяжёлые чтения перестали конкурировать с важными записями.
Чистое разделение обычно выглядит так:
- Отчёты дашборда, выгрузки и аналитические виджеты читаются с реплики.
- Настройки, права, приглашения и всё, что должно сразу отражать изменение, остаются на primary.
- Смешанные эндпойнты (например, карточки дашборда, которые также показывают текущий тариф пользователя) либо читают тариф с primary, либо принимают небольшую задержку.
Добавьте короткую липкость после записей. Если пользователь поменял роль с «Viewer» на «Admin» и вернулся на дашборд, чтение с реплики может показать старую роль несколько секунд. Пометьте сессию как «читать с primary до времени X» (обычно 30–60 секунд) после успешного сохранения. В течение этого окна чтения идут на primary. По истечении окна возвращайтесь к реплике.
Если у вас унаследованный AI‑generated код, где маршрутизация чтений/записей уже разбросана или хрупка, FixMyMess (fixmymess.ai) фокусируется на диагностике и исправлении проблем вроде небезопасного разделения read/write и отсутствия fallback по lag, чтобы реплики улучшали производительность без проблем с корректностью.
Часто задаваемые вопросы
What problem does a read replica actually solve?
A read replica helps when read traffic is so heavy that it slows down writes on your primary database. The goal is to keep the primary responsive for updates by offloading safe, read-only queries to another copy of the data.
If your app feels slow but the database isn’t actually the bottleneck, a replica won’t fix the real problem.
When should I add a read replica instead of just optimizing queries?
Use a replica when your busiest queries are mostly SELECTs and you see write latency get worse during read spikes. A common sign is that a few screens (dashboards, search, admin lists) consume most of the database time.
If the pain is caused by slow query design or missing indexes, fix that first before adding more moving parts.
Which endpoints are usually safe to send to a replica?
Start by routing endpoints that can tolerate slightly stale data, like analytics widgets, activity feeds, search results, and large admin tables. These usually create lots of read load without needing perfect freshness.
Keep the first rollout narrow so you can measure impact and quickly undo it if users report confusing results.
What should always stay on the primary database?
Keep anything tied to money, access, or immediate user confirmation on the primary database. That includes checkout, payments, subscription status, login, permission checks, and pages users hit right after saving changes.
These flows often require “read your own write,” and replica lag can make the app look broken or inconsistent.
What is replication lag, and why does it matter?
Replication lag is the delay between writing to the primary and seeing that change on the replica. With asynchronous replication, the replica is usually a little behind, and under load it can fall seconds behind.
That’s why a replica decision is about correctness, not just speed.
How do I prevent “I just updated it, but I still see the old data”?
A simple default is: after a user writes, route their reads to the primary for a short window (often seconds). This avoids the “I saved it but it didn’t change” experience.
You can implement this as session-based stickiness or request routing rules for specific endpoints that follow writes.
What tends to break first after adding a replica?
The most common failure is user-visible inconsistency: someone updates settings, refreshes, and sees the old value because the read hit the replica. Another common break is access control, where a recent role change hasn’t reached the replica yet.
Background jobs can also misbehave if they make decisions from stale reads and accidentally run work twice or miss work.
What are the biggest mistakes teams make with read replicas?
Avoid mixing primary and replica reads inside the same response at first, because you can create contradictory results. Also avoid routing “everything that is a SELECT” to the replica, since many reads are part of a write flow.
Keep routing rules easy to reason about, and make rollback easy so you’re not stuck during an incident.
How do I make replica routing safe to roll back?
Have a kill switch that sends all reads back to the primary instantly, and test it before you need it. Also set aggressive timeouts for replica reads and fall back to the primary rather than failing the request.
Monitor replica lag and stop using the replica when lag exceeds a threshold you consider safe for your product.
What if my codebase is messy (or AI-generated) and routing reads sounds risky?
If the codebase has scattered database access, hidden writes inside “read” endpoints, or no clear way to enforce read-after-write rules, adding a replica can create confusing bugs. In that case, it’s often worth fixing routing, connection pooling, and lag fallback behavior first.
FixMyMess helps teams repair AI-generated or inherited code where read/write splitting is brittle, so replicas improve performance without breaking correctness.