Корреляционные ID, чтобы отслеживать клики через API и задачи
Корреляционные ID связывают клик пользователя с логами API и фоновыми задачами, чтобы вы быстро находили ошибки, давали точные баг‑репорты и исправляли проблемы без догадок.
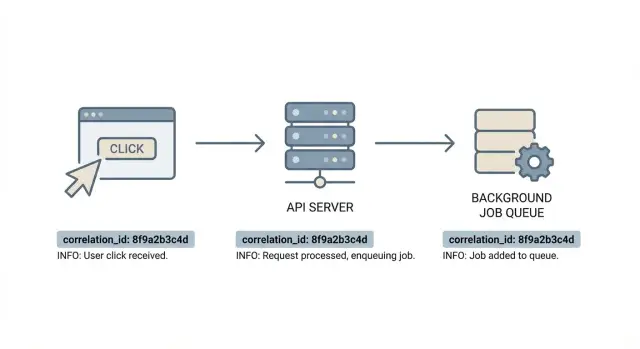
Почему отладка кажется случайной без общего ID
Жалоба о баге часто начинается просто: «Я нажал Сохранить и всё упало». Затем вы открываете логи, и начинается угадайка. В консоли браузера одно множество сообщений, логи API — в другом месте, а логи фоновых задач хранятся в третьей системе. Даже если везде много логов, они не совпадают по контексту.
Тогда отладка кажется случайной. Вы ищете по диапазону времени, ID пользователя или по расплывчатому тексту вроде «оплата не удалась», надеясь попасть на нужные строки. Если активных пользователей много или идут ретраи, легко пойти по неверной нитке.
Это также причина, почему так часто звучит «на моей машине работает». На вашем ноутбуке вы повторяете клик и он проходит. В продакшене тот же клик мог попасть на другой сервер, промахнуться кэшем, вызвать медленный сторонний сервис или поставить в очередь задачу, которая позже упадёт. Без единого способа связать события история распадается на фрагменты.
Одно действие пользователя может быстро разветвиться: клик во фронтенде вызывает один или несколько API‑вызовов; API трогает базу данных и возможно другие сервисы; может поставить в очередь задачи для письма, биллинга, обработки изображений или индексирования; эти задачи выполняются позже на других машинах, иногда с ретраями. Вебхуки и колбэки добавляют ещё шагов.
Цель проста: одна дорожка, по которой можно пройти от начала до конца. С корреляционными ID вы берёте тикет поддержки, хватаете один идентификатор и вытягиваете связанное событие фронтенда, точный API‑запрос и все строки логов из задач, что выполнялись после. Отладка перестаёт быть сборищем улик и превращается в надёжную временную шкалу.
Что такое корреляционный ID (и чем он не является)
Корреляционный ID — это одна метка, которая сопровождает единицу работы по всей системе. Думайте о нём как о контексте для «одного действия пользователя»: один клик, один API‑запрос, фоновые задачи, которые он запустил, и любые downstream‑вызовы.
Каждая строка лога, относящаяся к этой цепочке, содержит тот же ID. Это позволяет выполнить один поиск и увидеть всю историю.
Корреляционный ID — не идентификатор пользователя. Он не должен описывать, кто пользователь, на что он кликнул или какие данные были задействованы. Это непрозрачная метка, которая помогает связать события между системами без догадок.
Его часто путают с другими ID:
- Session ID связывает множество действий во времени с одной сессией браузера. Полезен для авторизации и аналитики, но слишком широк для трассировки одного сломанного действия.
- ID записи в базе идентифицирует строку (например, номер заказа). Полезен для бизнес‑логики, но не связывает автоматически фронтенд, API и обработку очередей.
- Correlation ID (request ID) связывает все шаги одного потока, даже когда задействованы несколько сервисов и задач.
Когда его создавать? Желательно на краю: в браузере, когда действие начинается (и отправлять как заголовок), или в первой точке входа API (gateway/load balancer/app server), если клиенту нельзя полностью доверять. Многие команды принимают клиентский ID, валидируют формат и генерируют новый, если его нет или он неверен.
Как он должен выглядеть? Сделайте его уникальным, непрозрачным и безопасным для логирования. Подходят UUID или ULID‑стиля значения. Не включайте почты, ID пользователей или что‑то чувствительное.
Куда должен путешествовать ID в типичном приложении
Корреляционный ID помогает только если он переживает весь путь. Думайте о нём как о метке, идущей от браузера через API в фоновую работу, чтобы каждая строка лога могла быть привязана к одному моменту.
В большинстве приложений это означает перенос одного и того же ID через:
- событие на фронтенде (клик или отправка формы)
- API‑запрос
- downstream‑вызовы (внутренние сервисы и третьи стороны)
- фоновые задачи (публикация и обработка воркером)
- конечные сайд‑эффекты (записи, письма, обработка файлов)
Используйте одни и те же «контейнеры» везде. В вебе самым распространённым носителем является HTTP‑заголовок (многие команды используют имена вроде X-Request-Id или X-Correlation-Id). На сервере сохраняйте его в контексте запроса, чтобы каждая строка лога могла автоматически его включать. Для задач кладите его в метаданные задачи или в payload, чтобы воркер мог восстановить его перед логированием.
Точки, где трассируемость обычно ломается:
- редиректы и переходы между доменами, которые сбрасывают кастомные заголовки
- ретраи и таймауты, которые создают новый request ID без копирования старого
- публикаторы в очереди, забывающие включить ID в payload
- код воркера, который логирует до того, как загрузил ID в контекст логирования
- fan‑out работа (один клик запускает много задач) без понятной parent‑child‑связи
Простое правило, которое избегает многих путаниц: первый бэкенд, получивший запрос, — источник истины. Фронтенд может пересылать существующий ID, если он есть, но бэкенд решает, что принимается, а что создаётся.
Пошагово: добавляем корреляционные ID от края до края
Выберите одно имя заголовка и используйте его везде. Согласованность важнее точного написания, потому что каждый шаг (браузер, API, очередь, воркер) должен распознавать одно и то же поле.
Начните на фронтенде. Когда пользователь нажимает кнопку, либо переиспользуйте существующий ID для текущего действия, либо создайте новый. Храните его в памяти (или в краткоживущем объекте контекста запроса) и прикрепляйте к каждому API‑вызову, который запускается этим кликом.
На стороне API читайте заголовок в middleware. Если он отсутствует — сгенерируйте его. Сохраните в контексте запроса, чтобы логи, ошибки и downstream‑вызовы могли его включать. Также возвращайте его в заголовке ответа, чтобы браузер (и поддержка) могли ссылаться на точный использованный ID.
Практический поток выглядит так:
- Фронтенд устанавливает
X-Correlation-Idодин раз на действие пользователя и переиспользует его для связанных запросов. - API принимает заголовок (или создает свой), сохраняет в контексте запроса и включает в ответы.
- При постановке в очередь копируется тот же ID в метаданные или payload задачи.
- Воркеры восстанавливают ID в контексте логирования до начала обработки.
- Ошибки включают ID в ответы, отображаемые пользователю или поддержке.
Ретраи — место, где команды часто теряют след. Если запрос ретраится из‑за таймаута, сохраняйте тот же ID, чтобы было видно, что это одно действие пользователя. Если пользователь нажал снова позже — генерируйте новый ID.
Если у вас запутанный код, реализуйте это сначала в одном месте на каждом слое: один фронтенд‑хелпер, одно API‑middleware и одна обёртка для задач. Обычно этого достаточно, чтобы отладка стала предсказуемой.
Логи, которые делают ID полезным
Корреляционный ID помогает только если он появляется в тех логах, которые вы реально читаете. Проще всего сделать его удобным для поиска, логируя в согласованном структурированном формате. JSON‑логи легко фильтровать по correlation_id и сравнивать между фронтендом, API и фоновыми задачами.
Как минимум, каждая строка лога, связанная с запросом, должна включать несколько надёжных полей:
correlation_idroute(илиaction)status(HTTP‑статус или результат задачи)message(короткое понятное описание)duration_ms(когда применимо)
Не логируйте всё подряд. Чистая база — одна строка в начале запроса, одна в конце, и дополнительные строки только для важных ветвей: ошибки валидации, ретраи, внешние вызовы и исключения.
Вот как это выглядит в успехе и при ошибке:
{"level":"info","message":"request_start","correlation_id":"c-9f3a","route":"POST /checkout","user_id":"u_42"}
{"level":"info","message":"request_end","correlation_id":"c-9f3a","route":"POST /checkout","status":200,"duration_ms":184}
{"level":"error","message":"payment_failed","correlation_id":"c-9f3a","route":"POST /checkout","status":402,"error":"card_declined"}
Будьте осторожны с тем, что логируете. Не пишите целые тела запросов, заголовки авторизации, токены, куки или секреты. Вместо этого логируйте небольшие сводки вроде items_count, plan=pro, provider=stripe или email_domain=gmail.com. Это особенно важно для быстрых прототипов, где логи иногда случайно печатают переменные окружения или базы данных.
Фоновые задачи: как сохранить след через очереди
Логи запросов и логи задач отвечают на разные вопросы. Логи запросов показывают, что произошло, пока пользователь ждал: клик, API‑вызов, ответ. Логи задач — что случилось после: письма, обработка файлов, ретраи и ошибки, появляющиеся спустя минуты. Без единого ID эти два мира не встретятся.
Когда вы публикуете сообщение в очередь, прикрепляйте тот же ID, что был в API‑запросе. Некоторые команды кладут его в метаданные сообщения (headers/attributes) и также в payload как запасной вариант. Главное — консистентность: выберите одно имя поля и используйте его везде, чтобы поиск по логам был предсказуем.
Читаемый паттерн:
- Один корневой корреляционный ID на действие пользователя.
- Когда API ставит задачу в очередь, включайте корневой ID и при желании отдельный job ID.
- Если один клик создаёт несколько задач, используйте один корневой ID для всех них.
- Для планировщика задач без клика генерируйте новый корневой ID на этапе планирования.
На стороне воркера считайте ID первым: до того как логировать что‑либо, вытащите ID из сообщения, установите его в контекст логов и только потом приступайте к обработке. Иначе самая болезненная ошибка случится: задача сделала полезную работу, упала, и в логе нет ID.
Для fan‑out есть дополнительное правило: сохраняйте общий корневой ID, но добавляйте дочерний идентификатор для каждой задачи, чтобы было видно, какая ветка упала.
Как сделать ID видимым для поддержки и баг‑репортов
Если ID видим только инженерам, он не поможет, когда клиент сообщает «кнопка ничего не сделала». Сделайте корреляционный ID легко доступным при ошибках, чтобы поддержка могла запросить его и инженеры сразу перейти к нужным логам.
Простой подход — показывать короткую метку в ошибочных состояниях, не на каждом экране. Поместите её туда, где пользователи уже смотрят за деталями: в тосте с ошибкой, в сообщении об ошибке формы или на странице «Что‑то пошло не так».
Как показывать так, чтобы не путать пользователей
Используйте спокойную формулировку вроде: «Reference: ABCD-1234.» Избегайте слов «trace» или «distributed». Если ID длинный, показывайте укороченную версию (например, первые 8–12 символов) и предоставляйте полное значение через кнопку «Копировать».
Поддержка тоже должна иметь простой сценарий: просите «Reference» код, а если его нет — попросите воспроизвести и сделать скриншот ошибки. Если возможно, соберите примерное время и что кликнул пользователь, затем вставьте код в тикет, чтобы инженеры могли мгновенно искать.
Примечание о приватности
Относитесь к корреляционным ID как к диагностической метке, а не к персональным данным. Не кодируйте адреса электронной почты, ID пользователей или отпечатки устройств в значении. Держите его скучным и случайным, чтобы его можно было безопасно прикрепить к скриншоту или тикету.
Распространённые ошибки, которые ломают трассируемость
Большинство сбоев трассировки — не сложные баги. Это мелкие решения, которые разрывают цепь между кликом, API‑запросом и фоновой задачей.
- Генерация нового ID на каждом шаге. Новые ID годятся для подопераций, но сохраняйте оригинал как parent.
- Перезапись пришедшего ID. Шлюзы, CDN или партнёры могли уже прислать request ID. Если вы его заменяете, теряете возможность соотнести их логи с вашими.
- Потеря ID при постановке в очередь. Если в логе API есть ID, а в логе задачи его нет — вы в догадках.
- Логирование только в одном слое. Только фронтенд‑ID не поможет, если сервер упал до ответа. Только серверный ID не поможет поддержке связать то, что видел пользователь.
- Использование ID как средства безопасности. Корреляционный ID — не сессионный токен. Не используйте его для авторизации и не кладите в него секреты.
Простой пример: пользователь нажимает «Export». Браузер создаёт ID, но API генерирует новый и логирует только его. Экспорт‑задача позже логирует свой случайный ID. В итоге для одного клика у вас три несвязанных ID.
Простое правило исправляет большинство случаев: принимайте входящий ID, валидируйте формат и передавайте его без изменений. Если нужны дополнительные данные, добавляйте второе поле вроде parent_id или job_id.
Быстрый чек‑лист, чтобы убедиться, что всё работает
Вы поймёте, что корреляционные ID делают своё дело, когда один ID ответит на вопрос: «что случилось после того клика?»
Протестируйте одно действие (стейджинг подходит): нажмите «Сохранить», возьмите корреляционный ID из UI или заголовка ответа, затем найдите его в серверных логах. Вы должны увидеть явный старт и конец запроса, плюс все downstream‑вызовы.
Чек‑лист:
- Один ID находит начало запроса, ключевые шаги и завершение запроса.
- Тот же ID появляется во всех фоновых задачах, созданных этим запросом (enqueue, job start, job end).
- Ошибки включают ID и понятное сообщение о том, что не сработало (не только стек‑трейс).
- Ретраи сохраняют тот же корреляционный ID для одного действия пользователя и добавляют номер попытки.
- Поддержка может запросить ID и найти всю цепочку без догадок.
Проверки реальности: если поиск по корреляционному ID возвращает только одну строку — вы не прикрепляете его ко всем строкам логов. Если один клик даёт несколько несвязанных ID — вы генерируете новые ID в API или рантайме задач вместо передачи оригинального.
Пример: отслеживание одного сломанного клика через API и задачу
Клиент нажимает «Оплатить» на странице оформления заказа. Кнопка кружится секунду, потом UI показывает общую ошибку: «Что‑то пошло не так». Без общего ID вы гадали бы. С корреляционными ID вы идёте по одной нитке от браузера к бэкенду и в очередь.
В браузере приложение создаёт ID сразу при клике и посылает его в заголовке API (например, X-Correlation-Id). Пользователь видит его только если вы решили показывать референс‑код при ошибках.
Что искать, по порядку:
- Консоль браузера:
pay_click correlationId=7f3a... - Access‑лог API:
POST /api/pay correlationId=7f3a... status=500 - Error‑лог API:
correlationId=7f3a... error="Stripe token missing" userId=... - Запись в очереди:
job=enrich_receipt correlationId=7f3a... queued - Лог воркера:
correlationId=7f3a... failed error="DB timeout" retry=1
Поиск теперь быстрый. Вместо сканирования всех ошибок платежей за последний час вы фильтруете логи по correlationId=7f3a... и получаете плотную временную шкалу: клик в 10:14:03, ошибка API в 10:14:04, ретрай задачи в 10:14:20.
Часто вы обнаруживаете две проблемы одновременно: баг в продукте («Stripe token missing») и недостаточную наблюдаемость, из‑за которой всё казалось случайным (воркер не логировал тот же ID или сообщение в очереди его теряло).
Следующие шаги, если сейчас отладить приложение трудно
Если приложение кажется невозвратно запутанным, не пытайтесь исправить всё сразу. Внедряйте это в одном маленьком куске, подтвердите, что работает, затем расширяйте.
Начните с одного действия пользователя, которое часто ломается (например, «Сохранить настройки») и проследите его через один эндпоинт API и один тип задачи. Выберите что‑то, что можно многократно воспроизводить. Когда вы сможете взять один ID из браузера и найти все связанные строки логов, вы построили паттерн, который можно тиражировать.
Напишите короткую конвенцию, чтобы избежать дрейфа:
- какое имя заголовка вы принимаете и пересылаете
- какое имя поля в логах вы записываете
- где генерируется ID и когда он переиспользуется
- как он передаётся в фоновые задачи
- где поддержка может увидеть его в UI
Если вы унаследовали AI‑сгенерированный прототип, который ломается в продакшене, часто полезно начать с фокусированного аудита того, где ID и контекст логов теряются между API, очередями и воркерами. Команды используют FixMyMess (fixmymess.ai) для такого диагноза и ремонта кода, особенно когда нужно быстро сделать приложение пригодным для продакшена.
После того как первый эндпоинт и задача трассируются, расширяйте по одному куску. Отладка станет лучше каждую неделю, без ожидания большого рефакторинга.
Часто задаваемые вопросы
Что такое корреляционный ID простыми словами?
Корреляционный ID — это одиночное непрозрачное значение, которое помечает один поток от начала до конца: один клик и всё, что он запускает. Оно позволяет выполнить один поиск по логам и увидеть связанные события во фронтенде, API, внешних вызовах и фоновых задачах.
Где должен генерироваться корреляционный ID?
Создавайте его на ближайшем надёжном крае: обычно это первый бэкенд‑вход (шлюз или middleware API). Если клиент присылает ID, принимайте его только если он соответствует ожидаемому формату; иначе генерируйте новый и используйте его как источник истины.
Должен ли корреляционный ID содержать данные о пользователе или бизнес‑данные?
Относитесь к нему как к диагностической метке, а не к идентификатору пользователя. В нём не должно быть адресов электронной почты, ID пользователей, номеров заказов или других чувствительных данных — эти значения попадут в логи, скриншоты и тикеты поддержки.
Как передать корреляционный ID из браузера в API?
Выберите одно имя заголовка и отправляйте его в каждом API‑запросе, связанном с тем же действием пользователя. Также возвращайте его в заголовке ответа, чтобы браузер и служба поддержки могли ссылаться на точный ID, который использовал сервер.
Должны ли ретраи использовать тот же корреляционный ID или генерировать новый?
Да, если ретрай относится к тому же действию пользователя — сохраняйте тот же ID. Это показывает, что несколько попыток принадлежат одному клику; при необходимости добавляйте счётчик попыток в логи.
Как сохранить корреляционный ID, когда работа переходит в очередь/фоновые задачи?
Скопируйте тот же корреляционный ID в метаданные или полезную нагрузку сообщения при постановке в очередь, и пусть воркер загружает его в контекст логирования до того, как начнёт писать что‑либо в лог. Если воркер логирует без восстановления ID, след оборвётся именно там, где нужна трассировка.
Что делать, если один клик запускает несколько фоновых задач?
Используйте один корневой корреляционный ID для всего клика и добавляйте отдельный идентификатор задачи для каждой ветви, если нужно различать их. Тогда можно искать по корневому ID, чтобы увидеть всю историю, и при этом точно понять, какая задача упала.
Что следует логировать наряду с корреляционным ID, чтобы он был действительно полезен?
Логируйте его как последовательное поле на каждой строке, связанной с запросом или задачей, желательно в структурированных логах, чтобы фильтрация была простой. Базовая схема: одна строка в начале запроса, одна в конце, дополнительные строки только для важных веток — внешних вызовов, ретраев и исключений.
Как показать корреляционный ID пользователям и службе поддержки, не запутав их?
Показывайте его только в состояниях ошибки как простой код «Reference», чтобы нетехнические пользователи могли его передать без путаницы. Если полный ID длинный, отображайте укороченную версию и предоставьте кнопку «Копировать» для полного значения для поддержки.
Как быстрее всего внедрить это в запутанном или AI‑сгенерированном коде?
Часто достаточно добавить один фронтенд‑хелпер, одно API‑middleware и один обёртку для задач, чтобы стандартизовать ID и логирование, затем расширять это по эндпоинтам. Если у вас унаследованный AI‑сгенерированный код, где ID, авторизация или логирование перепутаны, FixMyMess может провести бесплатный аудит кода и обычно исправить критичные проблемы за 48–72 часа, включая настройку сквозной трассируемости.