Лимиты параллельности фоновых воркеров для защиты базы данных
Лимиты параллельности фоновых воркеров удерживают нагрузку на БД стабильной, ограничивая одновременные задачи и глубину очереди. Узнайте простые правила, быстрые проверки и пример.
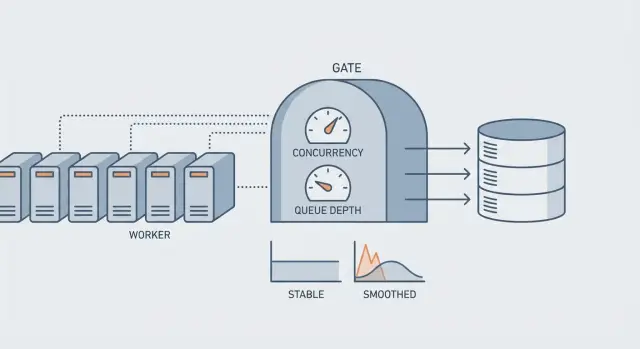
Почему фоновые воркеры могут перегрузить вашу БД
«Всплеск в БД» обычно проявляется цепной реакцией. Страницы, которые раньше были быстрыми, начинают виснуть. Входы не проходят. В API появляются таймауты и растёт горка неудачных или повторённых задач. Даже если фоновая задача отвечает за одну функцию, она может разрушить ощущение работоспособности всего приложения, потому что база данных — общий узкий элемент.
Фоновые воркеры нагружают базы данных быстрее, чем веб‑трафик, потому что они рассчитаны на постоянную и параллельную работу. Веб‑запрос ограничен активностью людей и таймаутами, а воркеры будут забирать задачи одна за другой и работать так быстро, как позволяют CPU. Если каждая задача делает несколько запросов, это превращается в сотни или тысячи запросов в минуту без естественных пауз.
Сложность в том, что это часто выглядит как «медленные запросы», тогда как настоящая проблема — параллелизм. Когда слишком много задач одновременно обращаются к БД, она исчерпывает соединения, начинает внутренне ставить работу в очередь — и всё замедляется сразу.
Признаки того, что корень проблемы в параллельности:
- Одновременно замедляются много разных запросов (а не только один эндпоинт)
- Ошибки пула соединений или сообщения «too many connections»
- Всплеск повторных попыток сразу после деплоя или запуска плановой задачи
- CPU базы растёт, а пропускная способность не увеличивается
Цель ограничения параллельности — не сделать задачи медленнее, а сохранить стабильную пропускную способность: предсказуемая нагрузка на БД, меньше инцидентов и стабильная задержка для реальных пользователей.
Пример: ночная задача «пересобрать индекс поиска» запускает 20 воркеров. Каждый читает строки, обновляет статус и пишет прогресс. Ночь тихая, но БД всё равно насыщается, и к утру трафик попадает в уставшую, перегруженную систему.
Параллельность, скорость и глубина очереди простыми словами
Когда люди говорят «нам нужно больше воркеров», обычно имеют в виду один из трёх рычагов. Каждый решает разную проблему, и поворот не того — может перегрузить базу.
Параллельность — сколько задач выполняется одновременно. Если параллельность 20, то до 20 задач могут одновременно обращаться к БД.
Скорость (rate) — как быстро вы запускаете задачи во времени, например «5 задач в секунду», даже если можно запустить больше.
Глубина очереди — сколько задач ждёт в очереди. Возраст бэклога — как долго самая старая задача ждёт.
Глубина очереди показывает объём. Возраст бэклога показывает боль. Очередь может быть глубокой, но нормально сливаться, или маленькой, но критичной, если задачи застряли и самая старая ждёт часы.
Почему «больше воркеров» часто сначала делает хуже: воркеры конкурируют в одних и тех же местах. Скрытый узкий элемент — обычно база данных: лимиты пула соединений, блокировки строк или таблиц, длинные транзакции. Увеличивая параллельность, вы увеличиваете конкуренцию: запросы ждут соединений, транзакции остаются открытыми дольше, блокировки длятся дольше — и всё замедляется.
Короткий пример: 10 воркеров выполняют задачу, которая держит транзакцию 300 мс. Это кажется мало. Но если они обращаются к одним и тем же таблицам, удвоение до 20 воркеров может удвоить ожидания блокировок и продлить транзакцию до секунд. Веб‑запросы начинают бороться за соединения — и приложение выглядит «упавшим», хотя просто перегружено.
Что обычно ломается первым в базе
При всплеске воркеров первая ошибка часто не «БД медленная», а «БД сейчас не может принять больше работы». Это проявляется таймаутами, очередью ожидающих запросов и ростом ошибок даже при нормальном CPU.
1) Истощение пула соединений
Большинство приложений имеют фиксированный пул соединений на процесс. Каждый воркер или поток требует соединение для выполнения запросов. Если вы запускаете больше воркеров, чем пул способен обслужить, они начинают ждать соединений. Ожидающие воркеры всё ещё занимают память и продолжают ретраить, добавляя давления по всей системе.
Типичная картина: веб‑приложению нужно 20 соединений для нормальной работы, но воркеры забрали оставшийся пул и сайт начинает падать при логинах или оформлении заказа.
2) Блокировки из‑за длинных транзакций
Даже при быстрых запросах длинные транзакции держат строки заблокированными. Если много задач трогают «горячие» строки или таблицы (например, обновляют одного и того же пользователя, баланс счета или поле «last_processed_at»), работа становится последовательной: только одна задача двигается, остальные ждут.
Ожидания блокировок могут выглядеть как случайная медлительность, но корень — слишком много параллельных операций по одним и тем же данным.
3) Дорогие шаблоны запросов в задачах
Задачи часто выполняют много маленькой работы в tight‑цикле, что порождает много запросов. Распространённые ошибки: N+1, обновления по одному вместо пакетных, многократные перерасчёты одних и тех же агрегатов, отсутствие индексов по фильтрам задач и выборка гораздо большего объёма данных, чем реально нужно.
4) Внешние вызовы внутри транзакции
Если задача открывает транзакцию и затем вызывает внешний API (email, платежи, AI, хранилище) до фиксации, соединение и блокировки удерживаются пока воркер ждёт сеть. Умножьте это на параллельных воркеров — и получите быстрое насыщение соединений.
Ограничения параллельности помогают, но лучше работают вместе с короткими транзакциями и предсказуемой стоимостью запросов.
Как выбрать разумные лимиты (без гаданий)
Хороший лимит — это не «число, которое кажется правильным». Это число, которое ваша база выдержит в плохой день, когда трафик высок и кеши промахиваются. Цель — держать БД в безопасных пределах по соединениям и времени запросов, при этом поддерживать стабильный прогресс задач.
Начните с консервативного базиса, привязанного к базе, а не к серверу приложений. Посмотрите на максимальные соединения вашей БД и зарезервируйте запас для веб‑запросов, админских задач и миграций. Затем учтите, сколько времени типичная задача держит соединение.
Практические рекомендации:
- Резервируйте 50–70% соединений БД для онлайн‑трафика и неизвестной работы.
- Оставшиеся 30–50% используйте как общий бюджет для всех воркеров вместе.
- Начинайте с низкой параллельности (часто 1–3 воркера на очередь) и повышайте только если задержка БД остаётся стабильной.
- Перепроверяйте после добавления новых фич — лимиты, которые работали месяц назад, могут сломаться после изменения запроса или пропажи индекса.
Не используйте одно глобальное число для всех задач. Делайте отдельные лимиты по очередям в зависимости от бизнес‑значимости. Критичные очереди (сброс пароля, onboarding) должны оставаться отзывчивыми, даже если массовая очередь (бэфилы, импорты) огромна.
Некоторые типы задач известны как «козлы отпущения» БД: экспорты, расчёты биллинга, большие импорты, всё, что сканирует крупные таблицы. Поставьте отдельные ограничения на такие задачи: например, общий пул воркеров 10, но только 1 экспорт одновременно.
Также решите заранее, что делать, когда очередь растёт:
- Backpressure: замедлить производителей (уменьшить частоту расписания, добавить задержки, ограничить число постановок в минуту).
- Сбрасывать работу: отбрасывать или объединять низкоценные задачи (мерджить дубликаты, хранить только последний запуск).
- Откладывать: перенос тяжёлых задач в окно низкой нагрузки с жёсткими ограничениями.
- Разбивать: разделить большую задачу на мелкие чанки с жёстким лимитом на каждый.
Пошагово: настроить лимиты параллельности и глубины очереди
Начните с перечисления типов задач. Запишите, что именно их триггерит, как часто они запускаются и читают ли или пишут много строк. Отметьте самые «тяжёлые» для БД (импорты, аналитические бэфилы, «синхронизировать всё», email‑рассылки с обновлением состояния пользователя). Их контролируйте в первую очередь.
Дальше задайте потолок на количество одновременно выполняемых задач, затем распределите этот потолок по очередям. Частая схема: очередь по умолчанию для нормальной работы и «тяжёлая» очередь для задач, интенсивно нагружающих БД. Это не даст одному типу задач украсть все соединения.
Практическая стартовая конфигурация:
- Глобальный лимит: держите общее число параллельных задач ниже безопасного бюджета соединений.
- Лимит по очереди: давайте тяжёлым задачам меньшую долю, чем быстрым.
- Лимит на тип задачи: по возможности разрешайте одновременно только 1–2 одинаковых тяжёлых задания.
- Приоритет: ставьте пользовательские работы выше служебных.
- Временные окна: запускайте тяжёлые очереди в ночные часы.
Затем ограничьте глубину очереди. Решите, что делать при полном буфере: ставить в паузу новые постановки, откладывать их или отклонять с понятной ошибкой. Если тяжёлая очередь достигнет, скажем, 1000 задач, можно прекратить принимать новые импорты и попросить пользователей попробовать позже.
Ретраи тоже создают всплески. Добавьте джиттер, чтобы не все повторялись одновременно, и используйте быстрый рост бэкоффа для DB‑ошибок, например таймаутов.
Внедряйте изменения постепенно: сначала снижают параллельность, наблюдают, затем поднимают в маленьких шагах. Если время запроса растёт или соединения упираются в максимум — откатитесь до того, как это почувствуют пользователи.
Мониторинг, который скажет, помогают ли лимиты
Лимиты помогают, когда база остаётся стабильной при росте объёма задач. Вы должны видеть контролируемые пики, а не внезапные провалы, когда всё замедляется.
Сигналы БД, за которыми стоит следить
Следите за небольшим набором метрик вместе:
- Активные соединения (и время ожидания пула)
- Количество медленных запросов и p95‑время запросов
- Ожидания блокировок и deadlock‑и
- Загрузка CPU и давление на память
- IOPS диска и задержки чтения/записи
Если соединения упираются при низком CPU, вероятно слишком много параллельных запросов ждут блокировок или I/O. Если CPU высок и растут медленные запросы — база делает слишком много работы по каждому запросу.
Сигналы от воркеров, которые показывают, помогает ли троттлинг
Отслеживайте выполняемые задачи, очереди, длительность задач (p50 и p95), частоту повторов и dead‑letter. Здоровая система: очередь растёт и уменьшается, но возраст бэклога остаётся примерно постоянным.
Алерты с действиями:
- Возраст бэклога растёт 10–15 минут
- Рост повторных попыток одновременно с таймаутами БД
- Соединения БД держатся около максимума несколько минут
- Длительность задач растёт (особенно p95)
Как решать: если уменьшение параллельности успокаивает метрики БД и снижает длительность задач — нужно ужесточить лимиты. Если уменьшение почти не помогает, а медленные запросы и ожидания блокировок остаются — нужно оптимизировать запросы и индексы, а не параллельность.
Пример: если ночная рассылка вызывает всплеск повторов и рост ожиданий блокировок, лимит может быть адекватен, но выборка получателей требует меньшего размера батчей или лучшего индекса.
Распространённые ошибки, которые всё равно приводят к всплескам
Многие ставят лимиты и всё равно получают внезапные перегрузки. Обычно лимит подгоняли под возможности воркера, а не под базу. Установка параллельности по числу CPU может выглядеть разумно, но игнорирует размер пула соединений, конкуренцию за блокировки и медленные запросы. База может упасть задолго до того, как машина станет «загруженной».
Поведение повторов — ещё один тихий генератор всплесков. Неограниченные повторы или повторы с одинаковой задержкой (например «retry через 30 секунд» для всех) создают шторм повторов. Короткий простой сбой превращается в второй сбой, когда тысячи задач просыпаются одновременно.
Дизайн очередей может усилить проблему. Одна общая очередь для всего позволяет массовой работе голодать критические задачи. Большой бэфил или экспорт задерживает пользовательские задачи, и кто‑то повышает параллельность, чтобы наверстать — что лишь сильнее бьёт по БД.
Во время инцидентов частая ошибка — поднять лимиты, чтобы «прибрать накопившееся». Это часто превращает управляемую очередь в насыщение соединений: вы быстрее очистите очередь, но получите больше таймаутов, ожиданий блокировок и deadlock‑ов, и бэклог вернётся.
Ограждения, которые предотвращают типичные сбои:
- Базируйте параллельность на соединениях БД и стоимости запросов, а не на CPU
- Добавляйте джиттер и экспоненциальный бэкофф у повторов с жёстким максимумом
- Разделяйте очереди для критичной и массовой работы
- Поднимайте лимиты только в крайнем случае и по маленьким шагам
- Определите явную политику delay/shed/reject при полном буфере
Быстрый чек‑лист перед релизом
Прежде чем запускать фоновые воркеры в прод, предполагайте худшее: деплой, рестарт или восстановление после сбоя, когда все воркеры просыпаются одновременно. База не заботится о том, что задачи «фоновы» — она видит внезапную волну соединений и запросов.
Чек‑лист:
- Пик‑математика соединений записана. Сложите веб‑серверы + процессы воркеров × потоки воркеров + админские скрипты. Сравните с лимитом соединений БД и оставьте запас.
- Тяжёлые задачи отделены и ограничены. Самые дорогие типы задач (импорты, бэфилы, большие рассылки) в своей очереди с меньшей параллельностью.
- У глубины очереди есть жёсткий потолок, и возраст бэклога мониторится. Максимальная длина очереди предотвращает бесконечное накопление, алерт по возрасту ловит замедления.
- Повторы не создают шторм. Разбрасывайте повторы, останавливайте после разумного окна и избегайте мгновенных ретраев по ошибкам БД, связанных с нагрузкой.
- У вас есть аварийный рычаг. Знайте, как быстро снизить параллельность воркеров (и как приостановить только тяжёлую очередь) без деплоя.
Практический пример: для ночного отчёта, который трогает много строк, выделите отдельную очередь с параллельностью 1–2, ограничьте глубину этой очереди и заведите алерт если самая старая задача дольше 15 минут.
Пример: как не дать ночной задаче положить приложение
Представьте SaaS, где пользователи активны до поздней ночи, а в 1:00 AM запускается импорт. Импорт читает большой CSV, обогащает строки и пишет обновления в те же таблицы, что используются для логинов, дашбордов и биллинга.
Без ограничений система старается закончить быстрее и запускает как можно больше задач. Через минуты соединения БД упираются в потолок. Запросы по 50 ms начинают уходить в секунды. Веб‑запросы таймаутят. Начинаются ретраи — и получается вторая волна, которая снова борется за базу.
Простая схема меняет всё:
- Поместите импорт в отдельную очередь, отдельно от критичных пользовательских задач (email, webhooks, платежи).
- Ограничьте параллельность импорта до небольшого числа, исходя из возможностей БД (например, 3–5 воркеров).
- Поставьте лимит глубины очереди, чтобы не принимать новые работы, когда backlog уже слишком большой.
- Добавьте ограничение скорости для самых тяжёлых DB‑операций (например, upsert), чтобы сгладить всплески.
Теперь импорт идёт дольше, но предсказуемо. Пользовательские запросы сохраняют свою долю соединений. Если импорт генерирует больше работы, чем система безопасно может съесть, она ждёт в очереди, а не создаёт пробку.
Компромисс прост: чуть более долгое выполнение фоновой задачи в обмен на стабильность приложения. Большинство команд предпочитает, чтобы импорт завершился позже, чем получать обращения в поддержку и экстренные откаты.
Когда лимитов недостаточно (и что менять дальше)
Ограничения параллельности — это страховочные перила, а не панацея. Если вы каждый день упираетесь в лимиты и очередь не отстаивает, обычно проблема в самой задаче, а не в количестве воркеров.
Масштабируйте воркеров, когда задача уже эффективна и у вас просто больше объёма. Исправляйте логику задачи, когда каждая задача весит слишком много (слишком много запросов, повторная работа, долгие блокировки).
Снизьте нагрузку на БД прежде чем добавлять воркеров
Большинство инцидентов возникает из‑за множества маленьких обращений к базе в параллели. Изменения, которые обычно приносят эффект:
- Пакетная обработка: обновляйте/вставляйте чанками, а не по одной строке
- Сделайте задачи идемпотентными: безопасными для повторов без дублирования побочных эффектов
- Сократите круговороты: получите нужные данные за один проход и работайте в памяти
- Добавьте правильные индексы: медленные сканы под нагрузкой множатся
- Укоротите транзакции: делайте меньше работы с удерживаемыми блокировками
Пример: ночная задача «пересчитать статистику» которая загружает 10,000 пользователей и выполняет 10 запросов на пользователя разрушит БД даже при низкой параллельности. Переработка в батчи или агрегирующие запросы превратит шторм запросов в несколько предсказуемых операций.
Разделение чтений и записей: полезно, но не панацея
Перенаправление только чтений на реплики помогает, если задача действительно много читает и реплики успевают. Это не спасёт, когда боль в записях, блокировках или «горячей» таблице, к которой обращаются все задачи. Следите за задержкой реплик: чтение со реплики и запись на основной могут приводить к решениям на устаревших данных.
Если вы собираетесь постоянно полагаться на троттлинг, поставьте конкретную цель (например, сократить запросы на задачу вдвое или держать время выполнения задачи < 30 секунд) и пересматривайте лимиты после оптимизаций.
Следующие шаги для кодов, сгенерированных AI
AI‑сгенерированные приложения часто приходят с небезопасными настройками по умолчанию: «запустить и пусть работает» вместо «выдержит продакшн». Так появляются неограниченные очереди, воркеры, которые порождают столько задач, сколько позволяет машина, и отсутствие обратного давления при замедлении базы.
Типичная картина: фоновая задача читает 50,000 строк и затем пишет по каждой записи без батчей. Даже если каждая запись быстра, суммарная нагрузка насыщает соединения, создаёт очередь блокировок и превращает обычные запросы в таймауты. В этой ситуации разумные лимиты помогают, но это лишь часть решения.
Если вы унаследовали AI‑прототип от Lovable, Bolt, v0, Cursor или Replit и он уже показывает поведение со всплесками, fixmymess.ai может начать с бесплатного аудита кода, чтобы найти точные источники давления на БД и рекомендовать безопасные настройки воркеров и очередей перед релизом.
Часто задаваемые вопросы
Почему фоновые воркеры перегружают базу данных быстрее, чем обычный веб‑трафик?
Фоновые воркеры работают непрерывно и параллельно, поэтому создают постоянную нагрузку на базу данных без естественных пауз. Даже несколько запросов на задачу при высокой параллельности быстро превращаются в ожидания пула соединений, блокировки и таймауты, которые затрагивают всё приложение.
Как понять, что проблема в параллельности, а не в одной медленной выборке?
Если одновременно замедляются многие, не связанные между собой запросы, это обычно признак конкуренции за ресурсы, а не одной медленной операции. Ошибки пула соединений, рост числа повторных попыток сразу после запуска задания и рост CPU при стабильной пропускной способности — всё это указывает на избыточную параллельность.
В чём разница между параллельностью, ограничением скорости и глубиной очереди?
Параллельность — это сколько задач выполняется одновременно. Rate limiting — как быстро вы запускаете задачи во времени. Глубина очереди — сколько задач ждёт в очереди (а возраст бэклога показывает, как давно ждёт самая старая задача). Увеличение параллельности при ограничениях БД обычно сначала усугубляет ситуацию.
Что обычно первым выходит из строя в базе при всплеске воркеров?
Чаще всего первым ломается пул соединений: воркеры и веб‑запросы начинают бороться за ограниченное число соединений. Затем долго работающие транзакции и блокировки превращают работу в «однопроходную», и дополнительные воркеры только увеличивают время ожидания.
Почему опасно вызывать внешние API внутри транзакции?
Транзакции должны быть короткими — не делайте сетевых вызовов (письма, платежи, запросы к AI, хранение) внутри открытой транзакции. Пока транзакция ждёт ответа от внешнего сервиса, она удерживает соединение и блоки; параллельность множит этот эффект и быстро истощает пул соединений.
Как выбрать безопасный лимит параллельности воркеров без гаданий?
Базируйтесь на бюджете соединений: зарезервируйте большую часть для веб‑трафика и непредвиденных задач, а оставшееся выделите всем воркерам вместе. Начинайте с низкой параллельности по очереди и повышайте только если задержки и ожидания блокировок остаются низкими.
Нужно ли использовать одну очередь для всего или разделять очереди?
Разделяйте очереди по влиянию и стоимости для БД, чтобы тяжёлая работа не отъедала ресурсы у критичных задач. У тяжёлых очередей должна быть ниже параллельность, а для известных «агрессоров» (экспорт, бэктанк, импорт) задавайте отдельные ограничения на число одновременных запусков.
Как ограничивать глубину очереди и что делать, когда она заполнена?
Задайте жёсткий потолок и определите поведение при его достижении: задерживать, приостанавливать производителей или отклонять новые задачи с понятным сообщением. Лимит глубины очереди предотвращает бесконечное накопление задач и заставляет обдуманно реагировать на перегрузку.
Как не допустить, чтобы повторы вызвали второй всплеск нагрузки?
Используйте джиттер и экспоненциальный бэкофф с жёстким максимумом по времени повторных попыток, особенно для ошибок БД. Без джиттера многие задачи могут повториться одновременно и создать «шторм повторов», превращая короткий спад в второй, более серьёзный инцидент.
Какие метрики показывают, работают ли лимиты, и что менять дальше?
Отслеживайте количество активных соединений и время ожидания пула, p95‑время запросов, ожидания блокировок/deadlock’и и возраст бэклога задач. Если снижение параллельности быстро нормализует метрики и уменьшает длительность задач — значит лимиты были слишком высоки. Если нет — нужно оптимизировать сами запросы и индексы.