Маскировать PII в логах: скрытие email, токенов и идентификаторов
Скрывайте PII в логах: готовые паттерны маскировки для email, токенов и идентификаторов, чтобы отлаживать ошибки, не раскрывая данные пользователей.
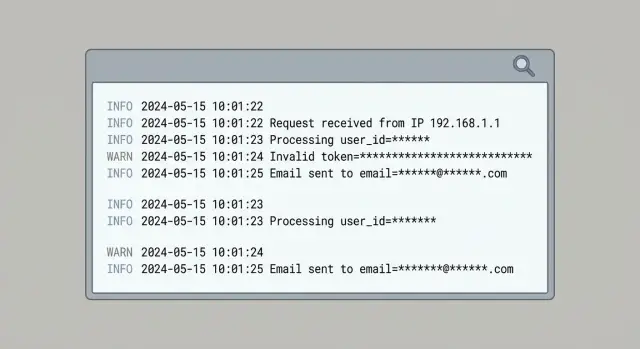
Что считается PII в логах (и почему оно продолжает появляться)
PII — это любая информация, которая сама по себе может идентифицировать человека или становится идентифицирующей в сочетании с другими данными. В логах и аналитике это обычно адреса электронной почты, номера телефонов, имена, домашние или платёжные адреса и IP‑адреса. Сюда также входят «технические» идентификаторы, которые на практике часто указывают на конкретного человека: user IDs, device IDs, рекламные идентификаторы, session IDs, cookie и точное местоположение.
PII появляется, потому что логирование часто добавляют под давлением — особенно когда что‑то ломается. Обычная краткая мысль: «запишем весь объект» и почистим позже. Этот "весь объект" как правило содержит поля, которые вы изначально не собирались хранить.
Типичные точки входа — тела запросов (signup, сброс пароля, сообщения в поддержку), заголовки (Authorization, cookie и иногда email в кастомных заголовках), объекты ошибок (они могут включать оригинальный запрос или сериализованные данные пользователя), строки запроса (параметры трекинга, email, вставленные в URL) и payload‑ы сторонних SDK, которые автоматически собирают данные устройства и сети.
События аналитики повторяют ту же проблему. Команды копируют поля из серверных логов в события, например user_email, session или свойства "debug", чтобы упростить построение метрик. Эти события затем расходятся по множеству вендоров и дашбордов, увеличивая радиус поражения одной ошибки.
Редактирование (redaction) лучше, чем просто «будьте аккуратны», потому что режим неудачи предсказуем: выходит новый эндпоинт, кто‑то добавляет debug‑лог, или библиотека меняет формат сериализации. Рассматривайте редактирование как стандартный слой безопасности, а не как настроенную по желанию разработчика опцию.
Решите, что вам действительно нужно сохранять для отладки
Прежде чем что‑то скрывать, чётко определите цели логов. Большинство команд собирают намного больше, чем используют, и именно избыточные данные становятся местом появления email, токенов и сырых заголовков.
Запишите конкретные вопросы, на которые вы ожидаете, что логи будут отвечать во время инцидента. Если строка лога не помогает ответить на один из этих вопросов — её можно удалить или уменьшить объём данных.
Большинство потребностей отладки сводится к базису: что упало и когда, какой эндпоинт/версия была вызвана, произошло ли это до или после аутентификации, вызвала ли ошибку внешняя зависимость, и относятся ли несколько ошибок к одному запросу или сессии.
Отталкиваясь от этого, определите безопасную «минимально полезную» форму лога, которой можно доверять повсеместно: timestamp, request ID (или trace ID), имя маршрута, код статуса и внутренний код ошибки. Добавляйте небольшую контролируемую контекстную информацию — feature flags или короткое имя компонента. Избегайте дампа целых объектов.
Отделите потребности поддержки пользователей от инженерных. Саппорту часто нужно найти пользователя и понять влияние, но для этого не обязательно сохранять email в каждом событии. Более чистый паттерн — хранить стабильный внутренний ключ пользователя в логах и выполнять поиск пользователя внутри защищённой админ‑системы.
Некоторые вещи никогда не должны логироваться, даже временно: пароли и одноразовые коды, полные токены и API‑ключи, session cookie, сырые заголовки Authorization и полные тела запросов/ответов.
Пример: если пользователи жалуются «Вход не удался», можно залогировать request_id=abc123, route=/login, status=401, error=AUTH_INVALID_TOKEN, auth_stage=post-parse. Этого достаточно для отладки без записи токена.
Паттерны маскировки для адресов электронной почты
Email часто попадают в логи: формы регистрации, сброс пароля, приглашения, тикеты в поддержку и ошибки «пользователь не найден». Если хотите редактировать PII в логах, не теряя ценности для отладки, сохраняйте ровно столько, чтобы увидеть закономерности (например, домен), не раскрывая полный адрес.
Безопасный дефолт — сохранить домен и лишь маленькую подсказку локальной части, например j***@example.com или jo***@example.com. Обычно этого достаточно, чтобы заметить «сбои сгруппированы по example.com», не раскрывая личности.
Плюс, нужно аккуратно относиться к «плюс‑адресации». [email protected] и [email protected] часто принадлежат одной и той же почтовой коробке. Если маскировать наивно, одну персону можно принять за нескольких пользователей. Нормализуйте перед маской: приведите адрес к нижнему регистру, отбросьте +tag, затем примените маску.
Если нужна стабильная корреляция между событиями, лучше использовать ключированный хеш вместо частичного раскрытия: hash(email) + "@" + domain. Используйте секрет приложения (pepper), чтобы нельзя было восстановить адрес по списку распространённых email. Никогда не логируйте сырой email вместе с хешем.
Свободный текст — главный источник утечек: сообщения исключений, отладочные print‑ы и вставленные тела запросов. Добавьте шаг «сканировать‑и‑заменять» в логгер, чтобы email очищались даже когда они появляются внутри предложений.
Распространённые варианты, которые остаются полезными:
- Домен + первые 1–2 символа локальной части:
ma***@gmail.com - Домен + только длина локальной части:
[email protected] - Ключированный хеш + домен:
a9f3c1…@example.com - Полная замена при высоком риске:
[REDACTED_EMAIL]
Что бы вы ни выбрали, приведите это в исполнение в одном месте (общая утилита для логирования), чтобы было единообразно во всех сервисах и аналитике.
Паттерны маскировки для токенов, API‑ключей и session ID
Секреты протекают, потому что они находятся в «банальных» местах, которые инженеры логируют без мыслей: заголовок Authorization, cookie, строки запроса и поля JSON вроде token, apiKey, sessionId или csrf. Простое правило: никогда не логируйте сырые секреты, даже при ошибках.
Разные типы секретов требуют разного подхода. API‑ключи обычно долгоживущие и их следует считать паролями. JWT могут содержать читаемые claims, поэтому их логирование может раскрыть email или user ID. Session ID и CSRF токены короткоживущие, но всё ещё позволяют угнать сессию.
Практичный паттерн — хранить ровно столько, чтобы коррелировать события:
- Префикс + суффикс: сохраняйте первые 4 и последние 4 символа
- Только длина: логируйте
len=32, когда корреляция не нужна - Теги типа:
kind=jwtилиkind=api_keyдля разбора/отладки - Стабильный хеш: необратимый хеш, когда нужна согласованная сопоставляемость
Сделайте ваш редактор устойчивым к реальным строкам. Секреты появляются как Bearer <token>, но также внутри склеенных сообщений, без пробелов и в странных регистрах. Редактируйте по шаблону, а не по «красивому формату».
Вот простой пример до/после:
BEFORE error="upstream 401" Authorization="Bearer eyJhbGciOi..." cookie="sid=s%3A0f1a9..." query="?api_key=sk_live_ABC123..."
AFTER error="upstream 401" Authorization="Bearer eyJh...9Q2w" cookie="sid=<redacted len=48>" query="?api_key=sk_l...8xKQ"
Обработка user ID, device ID и других идентификаторов
Не все ID безобидны. Если идентификатор можно связать с реальным человеком (напрямую или комбинируя с другими данными), считайте его персональным. Это включает многие «внутренние» поля: user_id, account_id, device_id, ip_address и «анонимные» cookie ID, если они сохраняются долго.
Полезное правило: если по этому значению можно найти человека в базе данных — оно чувствительное.
Отдавайте предпочтение стабильным необратимым ID для отладки
Вам всё ещё нужно связывать события во время инцидента. Самый безопасный паттерн — стабильное, но необратимое представление, например солёный хеш. Вы получаете повторяемую корреляцию без раскрытия исходного значения.
Например, вместо user_id=483920 логируйте user_key=hash(tenant_salt + user_id). Держите соль вне логов, ротацию при необходимости и используйте разные соли для разных окружений.
Чтобы логи оставались полезными, включайте корреляционные поля, которые не привязаны к человеку: request_id для одного запроса, trace_id для следования за вызовом между сервисами, короткоживущий session_key, который быстро истекает, и tenant_id, когда он идентифицирует организацию, а не отдельного пользователя.
Мульти‑тенантные приложения требуют дополнительной осторожности. tenant_id обычно безопасно хранить, если это компания/рабочее пространство, а не отдельный пользователь. Не хешируйте user IDs глобально — используйте hash(tenant_id + user_id), чтобы идентификаторы нельзя было сопоставить между арендаторами.
Структурированные против неструктурированных логов (и как редактировать каждое)
Именно в неструктурированных логах PII чаще всего проскальзывает. Быстрый console.log(user) или ошибка, включающая заголовки запроса, могут вывалить email, токены и ID в одну грязную строку. Попав в инструмент логирования, это трудно исправить.
Структурированное логирование (обычно JSON) делает редактирование предсказуемым. Вместо того чтобы гадать через regex по всей строке, вы можете целенаправленно обработать поля user.email, auth.token или request.headers.authorization.
Сначала редактируйте на уровне полей, затем используйте regex как страховку для свободного текста. Только regex на полнотой строки пропускает пограничные случаи и может избыточно маскировать, что затруднит отладку.
Практический подход: логируйте стабильную метадату (эндоинт, статус, feature flag, короткий код ошибки), сохраняйте «форму» без контента (длина токена, домен email, последние 4 символа) и разделяйте свободный текст на message + структурированный context. Затем добавьте финальный шаг очистки для любых оставшихся строк, похожих на email или токен.
Упростите это общей функцией redact() и используйте её везде (логирование, отчёты об ошибках, аналитика). Если разные команды реализуют свои правила — что‑то обязательно ускользнёт.
export function redact(value) {
if (value == null) return value;
const s = String(value);
// emails
const email = s.replace(/[A-Z0-9._%+-]+@([A-Z0-9.-]+\\.[A-Z]{2,})/gi, "<redacted:@$1>");
// bearer tokens / api keys (best-effort)
return email.replace(/\b(Bearer\s+)?[A-Za-z0-9-_]{20,}\b/g, "<redacted:token>");
}
Шаг за шагом: добавляем редактирование в ваш pipeline логирования
Редактирование работает лучше, когда оно автоматическое. Цель — удалить чувствительные значения до того, как что‑то покинет работающее приложение, чтобы не полагаться на настройки вендора или отложенную задачу очистки.
Начните с перечисления всех мест, где создаются логи и события. Команды помнят API‑сервер, но забывают воркеры, реверс‑прокси, мобильный клиент или репортер ошибок в браузере.
Далее определите «карту редактирования»: имена полей, которые вы никогда не хотите отправлять (например, email, authorization, cookie, set-cookie, password, token) плюс правила по шаблонам для грязного свободного текста.
Затем добавьте слой редактирования прямо перед экспортом, желательно в одной общей функции, чтобы её было трудно обойти. Делайте развёртывание контролируемым: добавляйте тесты, выкатывайте постепенно и проверяйте, что отладка по‑прежнему работает.
Докажите это тестами, а не надеждой
Используйте «грязные» фикстуры: запрос с Authorization: Bearer ..., JSON‑тело с email и URL, содержащий reset‑токен. Ваши тесты должны подтверждать, что чувствительные части заменены, а оставшийся контекст всё ещё объясняет, что произошло.
Редактирование PII в событиях аналитики без потери инсайтов
Аналитика протекает так же, как логи: URL, referrer, значения форм и сообщения об ошибках. Разница — куда это попадает. Данные аналитики копируются в больше мест и часто хранятся дольше.
Хороший дефолт: отправлять меньше, но отправлять последовательно. Заменяйте свойства пользователя псевдонимным ID и добавляйте только грубые атрибуты, которые реально используются (уровень тарифа, версия приложения, страна, тип устройства). Так вы решаете продуктовые вопросы, не отправляя сырые идентификаторы.
Паттерны знакомы: избегайте email/телефона/полного имени как идентификаторов, суммируйте чувствительные строки (присутствует/отсутствует, длина или категория), обрезайте query‑строки и фрагменты из URL, и для ошибок отправляйте код и категорию вместо полного payload, который может содержать ввод пользователя. Если нужна корреляция — хешируйте с секретной солью и никогда не отправляйте сырое значение.
Сырые URL — частая утечка. Ссылки для сброса пароля могут содержать token=..., приглашения — email в query, и эти значения могут быть захвачены как свойства page‑view.
Событие регистрации обычно не нуждается в [email protected]. Обычно достаточно signup_method=email, опционально email_domain=company.com и флага успешного подтверждения.
Распространённые ошибки, которые всё ещё дают утечки PII
Большинство утечек происходят не из‑за «плохого» правила редактирования. Они случаются потому, что кому‑то понадобилось больше деталей во время инцидента или потому, что один путь логирования отличается от остальных.
Режим инцидента, который не выключили
Классическая ошибка — включить подробное логирование запросов во время аутсейжа (бodies, headers, query strings), починить баг и забыть отключить. Через недели логи содержат пароли в payload, bearer‑токены в заголовках и email в query params.
Редактирование помогает, но не спасёт, если вы продолжаете собирать гораздо больше, чем нужно.
Редактирование слишком узкое или непоследовательное
Маскировать только поле email недостаточно. PII появляется под разными ключами и в вложенных структурах, просачивается из мест, о которых забывают: воркеры, background‑job‑ы, клиентское логирование и репортеры ошибок. Если хотите полного покрытия — одни и те же правила должны выполняться везде, где производятся логи, и быть покрыты тестами с реальными грязными вводами.
Быстрая чек‑листа перед релизом
Сделайте последний проход с простой целью: сохранить достаточно деталей, чтобы понять, что и где произошло, но не хранить секреты или прямые идентификаторы.
- Найдите худшие нарушители: пароли, заголовки Authorization, cookie и полные токены. Если нужно доказать наличие токена — логируйте только короткий отпечаток (первые 6 и последние 4) или однонаправленный хеш.
- Убедитесь, что email и телефоны маскируются везде, включая свободный текст и стектрейсы.
- Замените идентификаторы пользователей на анонимные IDs (или хешируйте их стабильной солью), чтобы проследить путь без раскрытия исходника.
- Проверьте события аналитики на сырые идентификаторы и полные URL. В query‑строках часто лежат reset‑токены, коды приглашений или подсказки сессии.
- Добавьте автоматические тесты, которые прогоняют типичные payload (signup, login, password reset, webhook failures) через ваш логгер и проверяют, что в выводе нет секретов.
Простая проверка: вызовите неудачный вход в staging и посмотрите точную строку лога. Если она содержит email, cookie или заголовок auth — вы ещё не закончили.
Следующие шаги: быстро проверьте, что утекает, и исправьте
Начните с доказательств. Просканируйте недавние логи и payload‑ы аналитики, чтобы найти то, что фактически появляется: шаблоны email, токеноподобные строки, полные имена, адреса, IP и отладочные дампы, которые стали постоянными.
Когда увидите повторяющиеся случаи, обрабатывайте их как небольшой бэклог. Сначала исправляйте самые рискованные источники (аутентификация, сброс пароля, регистрация, биллинг, формы поддержки), затем расширяйтесь наружу. Остановите новые утечки, прежде чем беспокоиться об очистке старых данных.
Если вы унаследовали AI‑сгенерированную кодовую базу, эта работа часто идёт быстрее, потому что точки утечек повторяются по файлам (дампы полных запросов, заголовки, cookie, переменные окружения). Исправьте это один раз на границе логирования, и вы устраните целые классы ошибок.
Если нужна внешняя помощь, FixMyMess (fixmymess.ai) специализируется на диагностике и ремонте AI‑сгенерированных приложений, включая ужесточение логирования, починку сломанных потоков аутентификации и усиление безопасности, чтобы прототипы было безопасно запускать в продакшене.