Миграция SQLite в Postgres: поэтапный план переключения
Практическое руководство по миграции SQLite в Postgres в приложениях, созданных AI: сопоставление схем, типы данных, изменения индексов, поэтапное переключение и проверки.
Почему эта миграция рискованна в приложениях, созданных AI
AI-сгенерированные прототипы часто «работают», потому что SQLite прощает многое. Он с готовностью хранит странные значения, принимает свободные типы и позволяет двигаться дальше с минимальной настройкой. Многие AI-инструменты по умолчанию используют SQLite, потому что он не требует конфигурации и легко разворачивается. Проблема в том, что эти ранние упрощения становятся скрытыми допущениями в вашем коде.
Когда вы мигрируете SQLite в Postgres, первые поломки обычно кажутся мелкими, но быстро распространяются. Запрос, который был корректен в SQLite, может сломаться в Postgres из‑за строже типизации, другого поведения с датами и булевыми значениями и чувствительности к регистру. Миграции также могут провалиться, потому что SQLite позволял добавлять колонки или менять таблицы способами, которые плохо переводятся в Postgres.
Что ломается первым:
- Аутентификация и сессии (обработка таймстемпов, уникальные ограничения, чувствительность к регистру)
- Запросы «работало локально» (неявные приведения типов, свободный GROUP BY)
- Фоновые задания и импорты (плохие данные, которые SQLite терпел)
- Производительность (пропущенные индексы, которые в SQLite не бросались в глаза)
- Скрипты деплоя (предположения о файловой БД vs серверной БД)
Миграция оправдана, когда вам нужна конкуррентность, настоящие бэкапы, более качественное планирование запросов, безопасный контроль доступа или вы вырастаете из одноузловой архитектуры. Она не стоит усилий, если приложение ещё каждую неделю выбрасывается, у вас нет стабильных требований или узкое место — не база данных, а продукт.
«Нет неожиданных простоев» не значит нулевой риск. Это значит, что вы спланировали типичные ошибки, умеете измерять прогресс и у вас есть чистый путь отката. На практике цель — либо отсутствие видимых пользователю простоев, либо очень короткое запланированное окно с понятным аварийным выходом.
Этот плейбук следует простому сюжету: опишите, что у вас на самом деле есть, аккуратно переведите схему, безопасно перенесите данные, спланируйте индексы и производительность, проведите поэтапный cutover с синхронизацией, внесите изменения в приложение, которые часто пропускают, затем протестируйте и потренируйте откат. Если ваше приложение было сгенерировано инструментами вроде Lovable, Bolt, v0, Cursor или Replit, команды вроде FixMyMess обычно начинают с быстрого обследования кодовой базы, чтобы найти предположения, завязанные на SQLite, прежде чем трогать production-данные.
Что инвентаризировать перед тем, как трогать базу данных
Прежде чем мигрировать SQLite в Postgres, чётко поймите, что у вас есть. Приложения, созданные AI, часто «работают» в демо, но скрывают сюрпризы: молчаливое приведение типов, сырой SQL и фоновые задания, которые продолжают писать данные пока вы пытаетесь их переместить.
Начните с карты «таблица за таблицей». Нужно знать имена, количество строк и какие таблицы быстро растут. Самые большие таблицы обычно определяют план переключения, потому что они дольше копируются и дольше переиндексируются.
Если можно, сделайте быстрый снапшот размера и роста:
-- SQLite: approximate quick checks
SELECT name FROM sqlite_master WHERE type='table';
SELECT COUNT(*) FROM your_big_table;
Далее — поймите трафик. Миграция БД редко блокируется чтениями. Её блокируют записи, о которых вы забыли: вебхуки, очереди, запланированные задания и «вспомогательные скрипты», которые кто‑то запускает вручную.
Вот простой чеклист инвентаризации, который предотвращает большинство неприятных сюрпризов:
- Таблицы: количество строк, крупнейшие таблицы и любые «горячие» таблицы с частыми обновлениями
- Поток данных: какие endpoint’ы пишут, какие только читают, и какие задания запускаются по расписанию
- Стиль запросов: где вы используете ORM, а где — сырой SQL в кодовой базе
- Особенности SQLite: места, которые полагаются на свободную типизацию, неявные булевы значения или странную обработку дат
- Конфигурация: где хранятся и как передаются строки подключения, API‑ключи и секреты БД
Сырой SQL — классическая ловушка. ORM может адаптировать запросы под Postgres, но скопированный SQL‑фрагмент из чата может использовать синтаксис только для SQLite или полагаться на поведение сортировки NULL.
Конкретный пример: прототип в Replit мог хранить булевы как "true"/"false" в одной таблице, 0/1 в другой и полагаться на то, что SQLite примет оба варианта. Postgres заставит вас выбрать, и этот выбор повлияет на запросы, индексы и логику приложения.
Если вы унаследовали запутанное AI-сгенерированное приложение, короткая диагностика кодовой базы (как у FixMyMess) может выявить скрытых писателей и предположения о SQLite до того, как они превратятся в проваленный cutover.
Перевод схемы, который не удивит вас позже
При миграции SQLite в Postgres основной риск — не копирование данных, а обнаружение того, что приложение зависело от непроявленных поведений SQLite.
SQLite часто «принимает» размытые схемы: отсутствующие внешние ключи, свободные типы колонок и неявные правила в коде приложения. AI‑созданные приложения усугубляют это тем, что схема могла быть сгенерирована быстро, а потом скорректирована вживую.
Сделайте схему явной (таблицы, ключи, связи)
Начните с карты каждой таблицы и того, как строки связаны. Не полагайтесь на догадки о поведении приложения — подтвердите это по реальной схеме и реальным данным.
Практический порядок перевода:
- Определите первичный ключ каждой таблицы и то, должен ли он меняться.
- Решите, как работают связи (1:1, 1:many) и добавьте внешние ключи осознанно.
- Добавьте ограничения, на которые вы полагались неявно (NOT NULL, UNIQUE, CHECK).
- Для циклических связей создайте таблицы сначала, затем добавьте внешние ключи.
- Держите имена согласованными (userId vs user_id вызывает тихие ошибки позже).
Автоинкрементные ID: выберите версию Postgres
В SQLite INTEGER PRIMARY KEY — особый случай с автоинкрементом. В Postgres стоит выбрать GENERATED BY DEFAULT AS IDENTITY (или ALWAYS) вместо старого SERIAL и задокументировать это.
Пример: прототип мог вставлять пользователей без явного id и предполагать, что id не пересекаются. Если вы восстановите данные и не сбросите последовательность, следующая вставка может упасть или, хуже, повторно использовать id.
Наконец, сделайте скрипт миграции повторяемым. Postgres строже, поэтому стремитесь к идемпотентным скриптам: создавайте объекты только если их нет и добавляйте ограничения контролируемо, чтобы частичный запуск можно было возобновить без догадок.
Несовпадения типов данных и безопасные конверсии
При миграции SQLite в Postgres большинство страшных багов связано с тихими различиями типов. SQLite с готовностью сохранит "true" в колонке, которую вы считали целочисленной. Postgres не позволит так делать — и это хорошо — но значит, нужны явные преобразования.
Несовпадения, которые реально ломают систему
Несколько паттернов повторяются в AI‑созданных приложениях:
- Булевы: в SQLite часто используют 0/1, "true"/"false" или даже пустую строку. В Postgres используйте
booleanи конвертируйте по чётким правилам (например: только 1 и "true" считаются true). - Целые, сохранённые как текст: ID и счётчики могут быть сохранены как строки. Конвертируйте только если все значения чистые, иначе оставьте текст и добавьте новую целочисленную колонку, которую заполните безопасно.
- NULL и дефолты: SQLite может вести себя свободно с отсутствующими значениями. Postgres будет принуждать
NOT NULLи дефолты. Если в старых строках есть null, добавляйте ограничение только после бэкфилла.
Дата и время — ещё одна ловушка. В проектах на SQLite часто хранят даты как локальные строковые форматы, смешанные форматы или epoch‑секунды. Выберите стандарт: timestamptz в UTC обычно безопаснее. Затем конвертируйте из каждого известного формата по очереди и логируйте строки, которые не распарсятся. Если в приложении для пользователей отображается «вчера» по разным часовым поясам, это часто признак смешения локального времени и UTC.
JSON‑поля требуют осознанного выбора. Если вы фильтруете по ключам внутри JSON и индексируете, храните как jsonb. Если только сохраняете и извлекаете блобы, text подойдёт, но вы потеряете валидацию и возможности запросов.
Деньги и десятичные числа не должны храниться в float. Если в AI‑сгенерированном чекауте итог $19.989999, исправьте, использовав numeric(12,2) (или нужную вам точность) и округляя при конверсии.
Практический подход — прогон сухой конверсии на копии продакшен‑данных, посчитать ошибки по колонкам и только потом фиксировать окончательные типы и ограничения.
План индексов и изменения производительности
После миграции SQLite в Postgres приложение часто «работает», но начинает тормозить. Одна из причин — SQLite и Postgres по‑разному решают, когда и как использовать индексы.
SQLite может обходиться меньшим числом индексов, работая в‑процессе с простым планировщиком и малыми нагрузками. Postgres предназначен для конкуренции и больших объёмов, но он строже относится к статистике, селективности индексов и форме запросов. Если в AI‑созданном приложении допущены случайные полные сканирования таблиц, Postgres их выполнит — просто на более большой и заметной нагрузке.
Начните с выбора индексов по реальным запросам, а не по догадкам. Вытяните топ чтений и записей (логин, списки, поиск, панели отчётов) и проектируйте вокруг них. Пример: если часто выполняется WHERE org_id = ? AND created_at >= ? ORDER BY created_at DESC LIMIT 50, составной индекс (org_id, created_at DESC) обычно полезнее, чем два отдельных индекса по колонкам.
Составные индексы и уникальность
Порядок колонок в составном индексе важен. Ставьте сначала более селективный фильтр (часто org_id или user_id), затем колонку для сортировки или диапазонного сканирования. Указывайте направление сортировки, если оно совпадает с запросом.
Также разделяйте понятия «должно быть уникально» и «помогает производительности». UNIQUE‑ограничение навязывает бизнес‑правило и создаёт соответствующий уникальный индекс. Отдельный уникальный индекс полезен для частичных случаев, но если это правило бизнеса — моделируйте его как ограничение.
Что проверить при тормозящих запросах
После переноса сосредоточьтесь на:
- Отсутствующих составных индексах для типичных фильтров + сортировки
- Неправильных типах данных, вынуждающих приведения (что блокирует использование индексов)
- Устаревшей статистике (запустите ANALYZE после массовых загрузок)
- Последовательных сканах больших таблиц там, где ожидались индексные сканы
- Дополнительной нагрузке записи из‑за слишком большого числа индексов на горячих таблицах
Если вы унаследовали AI‑сгенерированную схему с «проиндексировать всё» или «ничего не индексировать», здесь короткий аудит (как у FixMyMess) окупается быстро.
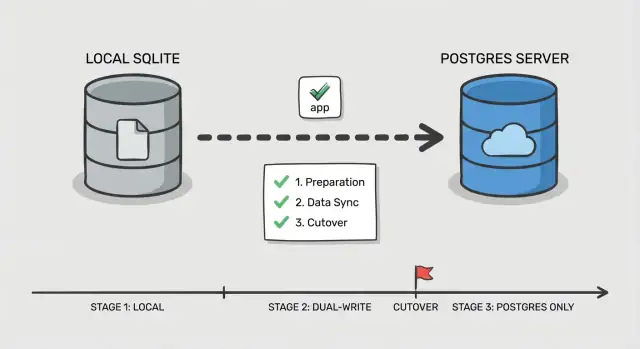
Поэтапный план переключения
Безопасный cutover — это не один большой переключатель, а демонстрация работоспособности каждого шага при продолжении работы пользователей. Это особенно важно при миграции SQLite в Postgres в AI‑созданном приложении, где часто обнаруживаются скрытые запросы и редкие кейсы.
Фаза 0: Решите, как вы будете переключаться
Выберите простой порядок: сначала переключайте чтения, затем записи. Чтения легче валидировать и откатывать. Записи меняют источник правды, поэтому их оставляйте на финальном шаге.
Добавьте один контрольный пункт в приложении: флаг функции или конфигурацию, выбирающую, какая база обслуживает чтения и какая — записи. Держите это просто и явно, чтобы можно было быстро переключить при инциденте.
Фазы 1–5: Выполняйте cutover малыми шагами
Перед тем как трогать трафик, настройте Postgres (база, пользователи, роли и доступ с минимумом прав). Убедитесь, что приложение может подключиться из той же среды, где оно сейчас работает.
Далее следуйте поэтапному сценарию:
- Bulk copy: снимите снапшот SQLite и загрузите его в Postgres.
- Incremental sync: поддерживайте Postgres в актуальном состоянии изменениями, пока приложение всё ещё пишет в SQLite.
- Read cutover: направьте чтения в Postgres, оставив записи в SQLite; наблюдайте за ошибками и медленными запросами.
- Write cutover: переключите записи в Postgres, держите короткое окно для отката.
- Finalize: остановите синхронизацию, заблокируйте старые креденшелы и держите SQLite в режиме только для чтения на определённый период.
Определите откат до любого переключения: какой флаг переворачивает обратно, какие данные можно потерять и как с этим справиться. Например, если приложение пишет сессии и сброс паролей, решите, нужно ли отдельно обрабатывать эти таблицы, чтобы откат не сломал логины.
Если нужен второй взгляд, FixMyMess часто помогает командам прогнать этот план на запутанных AI‑кодовых базах до реального cutover.
Как держать данные синхронизированными во время перехода
При миграции SQLite в Postgres с поэтапным cutover сложность — не в копировании первого снапшота. Сложность — в поддержании согласованности изменений, пока реальные пользователи продолжают работать.
Два простых паттерна синхронизации (и когда их использовать)
Если приложение низконагружено и изменения просто воспроизводить, подойдут периодические задачи бэкфилла: сделайте начальную копию, затем периодически копируйте строки, изменённые с момента последнего запуска (по updated_at или таблице событий). Это просто, но повышает риск неожиданных расхождений перед переключением.
Если приложение активно используется, dual‑write безопаснее: каждая запись пишет в обе базы некоторое время. Это сложнее, но сокращает разрыв и делает cutover менее стрессовым.
Согласование ID
Решите заранее, какая система владеет первичными ключами. Самое простое правило: сохраняйте те же ID в Postgres и никогда их не перенумеровывайте. Если SQLite использовал целые ID, установите последовательности в Postgres выше текущего максимума, чтобы новые строки не конфликтовали. Если переходите на UUID, добавьте новую колонку UUID, заполните её, а старый ID оставьте как стабильную внешнюю ссылку до полного перевода приложения.
Чтобы избежать путаницы, заранее пропишите правила на конфликт:
- Выберите один источник правды для записей (обычно Postgres после старта dual‑write)
- При несоответствии предпочитайте «последнее updated_at», только если часы надёжны
- Для денег, прав доступа и аутентификации предпочитайте явные правила, а не таймстемпы
- Фиксируйте каждый конфликт для последующего разбора
Держите обе системы параллельно достаточно долго, чтобы покрыть обычное использование (обычно несколько дней, иногда полный бизнес‑цикл). Логируйте метрики для быстрой отладки: количество строк по таблицам, контрольные суммы для горячих таблиц, ошибки записей по endpoint’ам и небольшой аудит изменённых ID. Часто команды просят FixMyMess проверить dual‑write и поймать дрейф до того, как его заметят клиенты.
Изменения на уровне приложения, которые обычно пропускают
Смена базы данных — это только половина работы. Многие команды мигрируют данные, переводят приложение на Postgres и потом целый день ловят странные ошибки, которых не было в SQLite.
Настройки соединений и пуллинг
SQLite обычно означает «один файл, низкая конкуренция». Postgres — сервер, и он может принять слишком много соединений, пока внезапно не начнёт отказывать.
Если приложение использует пул, задайте реальный лимит и таймауты. Частая ошибка после миграции SQLite в Postgres — фоновые задачи и веб‑приложение каждый открывают свой пул, множа соединения и создавая замедления, которые выглядят как «Postgres медленный», тогда как на деле проблема — слишком много соединений.
Запросы, которые полагались на снисходительность SQLite
SQLite часто возвращает результат, даже если SQL немного небрежен. Postgres строже, и эта строгость обычно полезна.
Следите за сравнением разных типов (текст к числам), неявными приведениями и свободным GROUP BY. Проверьте также совпадение строк и правила регистра: поиск, который «работал» в SQLite, может изменить поведение, если вы полагались на нечаянную регистронезависимость.
Транзакции и блокировки тоже могут поменяться. Код, который хорошо работал при «писать когда нужно», теперь может попасть в дедлоки или конкуренцию, если он оборачивает большие чтения и записи в одну долгую транзакцию.
Аутентификация и хранение сессий — ещё одна тихая ловушка. Если сессии, токены сброса пароля или refresh‑токены живут в БД, небольшие различия (таймстемпы, уникальные ограничения или задания очистки) могут вызвать внезапные разлогинивания или поломку входа.
Быстрый список проверок на стороне приложения, которые ловят большинство сюрпризов:
- Убедитесь, что все процессы приложения (веб, воркеры, cron) читают одну и ту же конфигурацию БД и лимиты пула.
- Замените SQL, завязанный на SQLite (upserts, функции работы с датами или булевы), на совместимые версии.
- Проведите аудит сырого SQL на предмет различий в кавычках и стиле параметров.
- Пересмотрите границы транзакций и убедитесь, что долгие задачи не держат блокировки дольше необходимого.
- Проверьте таблицы сессий и токенов, логику истечения и уникальные ограничения.
Пример: AI‑прототип мог хранить сессии в таблице с текстовой колонкой "createdAt" и сравнивать её со строковым "now". В SQLite это может выглядеть рабочим, но в Postgres проверки истечения сломаются, если не конвертировать в настоящий timestamp.
Если вы унаследовали кодовую базу от Replit или Cursor, это именно то место, где сервисы вроде FixMyMess находят большинство скрытых точек отказа: данные в порядке, но логика приложения полагается на поведение SQLite.
Тестирование, мониторинг и репетиция отката
Большинство неожиданных простоев происходят потому, что cutover воспринимается как одноразовое событие, а не отрепетированная процедура. AI‑созданные приложения особенно рискованны: в них часто слабая валидация, непоследовательные запросы и краевые случаи, которые проявляются только на реальных данных.
Начните с повторяемого smoke‑теста, который можно запустить за пару минут на обеих базах. Держите его маленьким и сфокусированным на реальных пользовательских путях, а не на всех функциях.
- Регистрация/вход/выход (включая сброс пароля, если есть)
- Создание одной ключевой сущности (проект, заказ или заметка)
- Редактирование этой сущности и проверка, что изменение видно везде
- Удаление (или soft‑delete) и подтверждение работы прав доступа
- Запуск одной административной/отчётной страницы, которая делает join нескольких таблиц
Далее сделайте shadow‑read тест. Для части трафика или cron‑задачи читайте параллельно из Postgres и SQLite и сравнивайте результаты. Логируйте расхождения с контекстом для отладки (id пользователя, входные параметры запроса и возвращённые первичные ключи). Это ловит тонкие проблемы: разный порядок, обработку NULL, регистрозависимость и разницы часовых поясов.
Нагрузите эндпоинты, которые бьют по вашим busiest таблицам, а не всё приложение целиком. Частый кейс при миграции SQLite в Postgres — запрос, который раньше «сходил», теперь требует отсутствующего индекса или лучшего джоина. Следите за p95‑латентностью и заполнением пула соединений.
Наконец, отрепетируйте откат один раз, засечённый по времени. Зафиксируйте точные шаги, кто их выполняет и что считается «остановить мир» (переключатель флага, режим только для чтения или слив трафика). Определите метрики успеха заранее: допустимая ошибка, p95‑порог задержки и счётчик расхождений, который должен быть равен нулю (или иметь чётко обоснованный список исключений).
Типичные ошибки и как их избежать
SQLite прощает. Postgres строг. Многие команды обжигаются, потому что их приложение «как‑то работало» на SQLite, а при миграции оно ломается.
Одна ловушка — считать, что типы данных «просто сработают». SQLite спокойно хранит текст в столбце, похожем на integer, или даты в произвольных строках. Postgres так не сделает. Перед переносом данных просканируйте колонки на смешанные значения ("", "N/A" или "0000-00-00") и решите, какой реальный тип нужен.
Индексы — ещё одна классическая задача «потом», которая превращается в пожар в проде. SQLite на маленьких данных кажется быстрым даже без индексов. Postgres может замедлиться, как только нагрузка вырастет, если вы забыли индексы для внешних ключей, типичных фильтров и колонок сортировки.
Cutover проваливается, когда записи переключаются слишком рано. Если вы начнёте писать в Postgres прежде, чем сможете детектировать дрейф, вы не поймёте, какая база «правильная», когда что‑то пойдёт не так. Добавьте проверки дрейфа (количества строк, диапазоны updated_at, контрольные суммы) прежде чем доверять новой системе.
Также следите за спрятанным путём к файлу SQLite. AI‑прототипы часто используют дефолт вроде ./db.sqlite в одной переменной окружения или Docker‑образе. Всё выглядит нормально в staging, а в проде всё ещё пишут в старый файл.
Долгие миграции — тихий убийца на больших таблицах. Один ALTER TABLE или бэкфилл может блокировать записи достаточно, чтобы вызвать таймауты.
Избегайте этого с помощью короткого pre‑flight чеклиста:
- Проведите аудит «грязных» колонок и нормализуйте значения до кастов.
- Создайте индексы в Postgres до завершения первой полной загрузки.
- Не включайте dual‑write или change capture, пока проверки дрейфа не запущены.
- Просканируйте конфиги и контейнеры на предмет забытых путей к SQLite.
- Разбейте большие бэкфиллы на батчи с лимитами по времени.
Если вы унаследовали шаткое AI‑приложение, команды вроде FixMyMess часто начинают с быстрого аудита, чтобы выявить эти риски до окна cutover.
Короткий чеклист и следующие шаги
Если вы запомните только одно при миграции SQLite в Postgres, то пусть это будет: большинство неожиданных простоев — из‑за мелких разрывов между планом и тем, что приложение реально делает в проде.
До cutover (подготовка)
Сделайте это до работы с production‑трафиком. Если пункт вызывает сомнения — приостановитесь и проверьте на тестовом запуске.
- Подтвердите, что бэкапы восстанавливаются корректно (не только что существуют) и зафиксируйте состояние cutover‑окна.
- Валидируйте переведённую схему против реального использования: ограничения, дефолты и поведение с таймстемпами.
- Убедитесь, что путь синхронизации уже запущен и стабилен (dual‑write или change capture) с понятной ответственностью за ошибки.
- Прогоните короткий продоподобный нагрузочный тест на Postgres и проверьте ключевые страницы или эндпоинты.
Во время cutover (безопасное переключение)
Цель — быстрый, скучный переключатель с понятными сигналами и понятным выходом.
- Используйте один явный переключатель (env var, флаг конфигурации или роутер) и определите, кто его нажимает.
- Перед переключением включите мониторинг: частота ошибок, задержки, соединения с БД и лаг репликации/синхронизации.
- Имейте готовый и отрепетированный откат: как вернуть приложение обратно и как обработать записи, сделанные во время cutover.
После переключения сначала проверьте корректность, затем производительность. Сравните количества строк и контрольные суммы по ключевым таблицам, прогоните несколько критических запросов end‑to‑end (вход, оформление заказа, создание/редактирование) и просканируйте логи на новые ошибки: нарушения ограничений, сюрпризы с часовыми поясами.
Далее займитесь производительностью: вытяните самые медленные запросы, проверьте использование индексов и исправьте те, которые приносят наибольшую боль пользователям.
Если ваше приложение было сгенерировано Lovable, Bolt, v0, Cursor или Replit, слой базы данных часто скрывает запутанные допущения (строковые даты, отсутствующие ограничения, небезопасные запросы). FixMyMess предлагает бесплатный аудит кода, чтобы выявить риски миграции заранее, до принятия окончательного плана cutover.