Миграция из JSON-blob в нормализованные таблицы с бэкифиллами
Узнайте, как безопасно мигрировать из JSON-blob в нормализованные таблицы поэтапно: новая схема, бэкифиллы, двойная запись, безопасное переключение и варианты отката.
Почему столбцы с JSON-блобом перестают работать по мере роста приложения
Столбец JSON-блоб — это одно поле в базе данных, которое хранит целый объект как текст, например { "status": "paid", "coupon": "NEW10", "notes": "..." }. Команды начинают с него, потому что это кажется быстрым: можно добавлять поля без изменения схемы, и многие генераторы кода по умолчанию используют такой подход, когда нужно двигаться быстро.
Проблемы проявляются, как только у приложения появляются реальные пользователи, большой объём данных и настоящие вопросы, на которые база должна отвечать. То, что раньше было простой записью, превращается в медленные чтения, запутанную отчётность и массу особых случаев в коде.
Обычно вы почувствуете, что JSON-блоб ломается, по нескольким предсказуемым признакам:
- Запросы замедляются, потому что фильтрация и сортировка внутри JSON хуже оптимизируются.
- Поля расходятся по форме (иногда
phone, иногдаphoneNumber, иногда отсутствует). - Отчётность превращается в гадание, потому что нельзя полагаться на типы, обязательные поля или связи.
- Исправления данных становятся рискованными, потому что вы редактируете большие блобы вместо одного явного столбца.
- Ошибки скрываются месяцами, потому что плохие данные всё ещё «вписываются» в JSON.
JSON-блобы также скрывают проблемы качества данных, пока их исправление не станет дорогим. Значение, которое должно быть числом, тихо превращается в строку. Поле, которое должно быть обязательным, исчезает. Позже, когда нужны точные итоги, дедупликация или журналы соответствия, вы обнаружите, что никогда не вводили правила.
«Нормализованные таблицы» означают разделение этого блоба на отдельные таблицы и столбцы, каждый из которых представляет одну сущность с явными типами и связями. Вместо одного order.data у вас могут быть orders, order_items, payments и addresses — со столбцами, которые можно индексировать и валидировать.
Есть случаи, когда стоит подождать. Не начинайте миграцию, если продукт меняется каждый день, объём данных крошечный или у вас нет чёткого определения значений полей. Сначала решите, что должно остаться стабильным.
Если вы унаследовали приложение, где «всё в JSON» — это обычная история: в демо работает, а в продакшене разваливается. Хорошая новость: вы можете мигрировать безопасно поэтапно с бэкифиллами, без крупномасштабного переписывания.
Промапьте текущие данные до любых изменений
Прежде чем переходить от JSON-блоба к нормализованным таблицам, выясните, как этот блоб реально используется сейчас. Большинство неудачных миграций начинаются с догадок о содержимом JSON и о том, какие части важны.
Запишите основные сценарии чтения и записи, которые затрагивают блоб, опираясь на реальное поведение: страницы, которые загружают пользователи, формы, которые они отправляют, API-вызовы, фоновые задания и экспорты, на которые опирается команда. В большинстве приложений первые несколько паттернов предсказуемы: загрузка страницы для пользователя, действие сохранения, хотя бы одно фоновое задание, представление админа/отчёта, которое читает много строк, и одна–две интеграции или вебхука, которые затрагивают только часть блоба.
Затем откройте несколько реальных продакшен-строк и перечислите поля, которые влияют на решения. Пропускайте шум вроде временного состояния UI, старых флагов, которые никто не читает, или случайных ключей, появившихся однажды и больше не вернувшихся.
По мере перечисления полей помечайте каждое как обязательное, опциональное или устаревшее.
- Обязательное: приложение ломается или бизнес-правила не выполняются без него.
- Опциональное: полезно, но бывает не всегда.
- Устаревшее: можно удалить позже, после подтверждения, что ничего не читает это поле.
Следите за дублированием одних и тех же данных в разных формах. Частый признак — когда поле существует и как отдельный столбец, и внутри JSON, или когда два JSON-ключа означают одно и то же (например, userId vs customer_id). Эти дубли затрудняют бэкифиллы и усложняют отладку.
Определите критерии успеха в измеримых терминах до изменения схемы. Быстрее работающие запросы на конкретных экранах. Отчётность без кастомного разбора JSON. Меньше ошибок с данными. Проще валидация. Меньше обращений в поддержку из-за «отсутствующих данных». Если вы не можете измерить улучшение, сложно понять, когда миграция действительно завершена.
Проектируйте нормализованную схему маленькими, безопасными кусками
Не пытайтесь заменить весь JSON-столбец за один раз. Выберите первый кусок, который явно важен: экран, на который жалуются пользователи; отчёт, который работает медленно; или API-эндпоинт, который постоянно таймаутит. Маленькая победа заставляет сфокусироваться и ограничивает объём работы.
Начните с именования реальных сущностей. Если блоб смешивает «профиль пользователя», «тариф», «платежи» и «события аудита», это не поля одной таблицы — это отдельные таблицы со связями. Простой тест: можете ли вы описать каждую таблицу одним предложением без слова «JSON»?
Выбирайте идентификаторы, которые не будут меняться. Если у вас уже есть первичный ключ для родительской строки (как account_id), сохраняйте его и используйте как внешний ключ в новых таблицах. Для дочерних записей добавьте стабильные ID (payment_id, event_id) вместо опоры на позиции в массиве внутри JSON. Это важно при бэкифиллах и воспроизведениях, потому что нужен надёжный способ сопоставить строки.
Вводите ограничения, которые вы готовы поддерживать сегодня, а не идеальный набор правил на будущее. Для первого кусочка сосредоточьтесь на:
NOT NULLдля обязательных колонок (например,user_id,created_at).- Базовых внешних ключах там, где вы доверяете родительской таблице.
- Уникальности там, где дубликаты ломают функциональность (например, один активный план на аккаунт).
Если нужна прослеживаемость в переходе, держите её явной и временной. Колонка raw_json в новой таблице может помочь отлаживать маппинги, но это должен быть осознанный выбор, а не новое свалочное место.
Планируйте индексы под реальные запросы, а не теоретические. Если приложение всегда получает «последние события для аккаунта» или «текущий план для пользователя», индексируйте эти конкретные фильтры и порядок сортировки. Один маленький кусок с правильными индексами лучше гигантской схемы, по которой никто не может быстро сделать запрос.
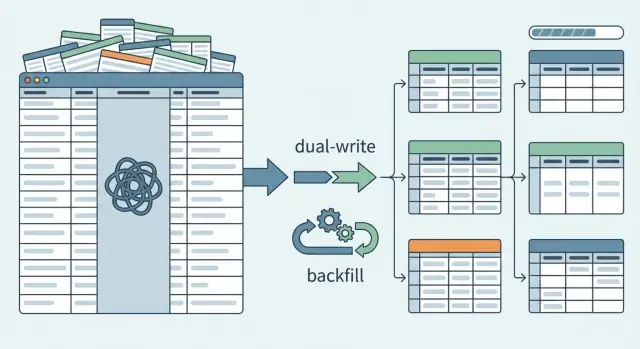
Настройте поэтапную миграцию с минимальным риском
Самый безопасный путь — добавлять, не заменять. Создайте новые таблицы и оставьте текущий JSON-столбец на месте. Продакшен остаётся стабильным, пока вы доказываете работоспособность нового пути.
Пока что держите старое поведение по умолчанию. Чтения продолжают приходить из JSON-столбца даже после появления новых таблиц. За кулисами можно включать новый путь чтения для небольшой части трафика или пары внутренних аккаунтов.
Флаг фичи тут помогает: он позволяет переключать чтение между старым источником (JSON) и новым (таблицы) без риска. Также это даёт мгновенный откат, если что-то пойдёт не так.
Далее начните двойную запись. При создании или обновлении записи записывайте её и в JSON-колонку, и в новые нормализованные таблицы. Это даёт возможность новым данным аккумулироваться в новой структуре, пока приложение всё ещё опирается на старую.
Двойные записи могут расходиться, если не ввести простые защитные механизмы. Практичный паттерн — хранить updated_at и небольшой schema_version в обоих местах. Когда версии не совпадают, вы знаете, что строка устарела и требует внимания, прежде чем ей доверять.
Минимальная поэтапная настройка, которая выдерживает продакшен, обычно выглядит так:
- Добавить новые таблицы и индексы, но не удалять JSON-столбец.
- Ввести флаг для чтения, по умолчанию использующий JSON.
- Реализовать двойную запись для создания и обновлений.
- Хранить
updated_atи простойschema_versionдля сравнения. - Логировать несоответствия и иметь быстрый переключатель для отката.
Бэкифиллы: перенос существующих JSON-данных в новые таблицы
Бэкифилл — это преобразование грязного JSON в чистые строки. Отнеситесь к нему как к настоящему конвейеру данных, а не к одноразовому скрипту. Хотите иметь возможность остановить, перезапустить и прогнать заново без дублирования или порчи данных в приёмных таблицах.
Сделайте задачу идемпотентной и возобновляемой. Частый подход: распарсить JSON, смаппить в новые колонки, затем выполнить upsert в целевые таблицы, используя стабильный естественный ключ (например, user_id + имя поля) или детерминированный сгенерированный ID. Храните чекпоинт, чтобы всегда знать, что было обработано.
Чтобы снизить риск, делайте бэкифилл малыми партиями и отслеживайте прогресс. Диапазоны ID хорошо работают, когда ID плотные. Временные окна подходят, когда данные естественно событийные. Очередь первичных ключей безопаснее, если ID разрежены. Многие команды также выполняют проход «изменённые с последнего запуска» в конце, чтобы поймать всё, что изменилось во время бэкифилла.
Валидация важнее скорости. JSON часто скрывает плохие типы и пропуски, поэтому явно опишите правила парсинга: значения по умолчанию, преобразования типов и что значит «пусто». Если вы видите "age": "", сохраняете ли вы NULL, 0 или отклоняете запись? Решите и придерживайтесь правила.
Предположите, что некоторый JSON будет сломан, и проектируйте обработку ошибок. Не останавливайте всю задачу из-за одной строки. Карантинируйте и логируйте ошибки, чтобы исправлять их осознанно:
- Записывайте ID исходной строки и путь в JSON, где произошла ошибка.
- Сохраняйте фрагмент raw JSON, вызвавший ошибку.
- Помечайте причину (некорректный JSON, отсутствует обязательное поле, несоответствие типов).
- Продолжайте обработку следующей записи.
Именно здесь миграции часто терпят неудачу в AI-сгенерированных приложениях: частичные парсинги, тихое усечение и «best effort» преобразования, которые кажутся нормальными, пока отчёты или биллинг не начнут от них зависеть. Жёсткий лог того, что не удалось перенести и почему, превращает сюрпризы в короткий список задач.
Проверяйте корректность сравнениями и защитными ограждениями
Самое страшное — не перенести данные, а доверять результату. Нужны простые проверки, которые понятно скажут, совпадают ли новые таблицы с тем, что приложение раньше читало из JSON.
Начните со сравнений, которые вычисляют одно и то же двумя способами: (1) распарсить JSON-колонку, как делал старый код, и (2) прочитать из новых таблиц. Делайте это сначала для пользовательского поведения: права, цены, лимиты планов, флаг статуса. Потом расширяйте проверку на более глубокие поля.
Развёртывайте с выборкой, прежде чем пытаться валидировать всё. Сэмплируйте небольшую выборку (например, недавние записи по клиенту или по дню), просматривайте несоответствия, исправляйте маппинги, затем расширяйте охват, пока не сможете проверять весь датасет.
При отслеживании несоответствий держите категории, по которым просто действовать:
- Missing: значение есть в JSON, но нет строки в новых таблицах.
- Different: обе стороны есть, но не совпадают после нормализации (типы, округление, регистр).
- Invalid: JSON не парсится или не проходит валидацию.
- Unexpected: новые таблицы содержат значения, которых никогда не было в JSON.
Запишите, что вы считаете источником правды на время перехода. Частые варианты: «JSON — источник правды (новые таблицы выводимы)» или «новые таблицы — источник правды (JSON — совместимость)». Выбирайте по фазе. Иначе инженеры будут «исправлять» несоответствия, обновляя обе стороны по-разному.
Защитные ограждения делают ошибки дешевле: флаги для чтения, жёсткие лимиты на количество строк, которые может изменить бэкифилл за прогон, и оповещения при росте процента несоответствий. Делайте каждую фазу обратимой: переключатель на чтение JSON, способ приостановить записи и план очистки для частично мигрированных данных.
Плавное переключение чтений, чтобы не сломать пользователей
Когда новые таблицы заполнены и поддерживаются в актуальном состоянии, меняйте источник чтения небольшими шагами. Обрабатывайте каждый путь чтения как отдельный релиз, а не как одно большое переключение.
Ставьте новое чтение за флагом. Запускайте на небольшой доле трафика сначала (или только на внутренних аккаунтах), затем расширяйте. Это держит ошибки локализованными и упрощает откат.
Практическая последовательность, работающая в большинстве приложений:
- Переключайте по одному экрану или API-эндпоинту.
- Держите чтение из JSON как fallback для этого эндпоинта.
- Параллельно сравнивайте результаты и логируйте несоответствия.
- Увеличивайте экспозицию постепенно (1%, 10%, 50%, 100%).
- Уберите fallback только после длительного периода совпадения результатов.
После каждого переключения следите за тем, что пользователи почувствуют первыми: рост ошибок, таймауты и медленные запросы. Нормализованные чтения могут превратиться в много мелких запросов, а отсутствие индекса может сделать ранее быструю страницу медленной. Добавьте оповещения до релиза, а не после.
Держите двойную запись, пока не уверены в новых чтениях под реальной нагрузкой. Если прекратить записывать в блоб слишком рано, откат превратится в инцидент с потерей данных. Двойная запись — это страховка. Убирайте её только когда уверены, что не придётся возвращаться.
По мере миграции явно фиксируйте зависимости, основанные только на блобе. Если фича всё ещё полагается на ключ, существующий только в JSON, решите: сделать его явным столбцом/таблицей или удалить. Оставлять это неопределённым — значит рисковать тем, что команда будет читать из обеих моделей вечно.
Распространённые ошибки, приводящие к потере данных или простоям
Большинство инцидентов при миграции из JSON в таблицы происходят потому, что работу воспринимают как одно переключение. На самом деле вы некоторое время держите две модели данных одновременно, и именно пересечение — место, где всё ломается.
Частая ошибка — включение двойной записи без решения, что делать при конфликте. Даже если обе записи делаются в одном запросе, всё равно нужен конфликт-политика (чья версия выигрывает) и способ обнаружить и воспроизвести пропущенные записи.
Бэкифиллы также создают проблемы, когда их нельзя возобновить. Долгие задания будут прерываться: деплои, таймауты, блокировки строк или проблемная запись. Если задание перезапускается с начала, вы рискуете дубликатами, частичными обновлениями или нагрузкой, похожей на DoS для вашей базы.
Ещё одна серьёзная проблема — тихий дрейф данных. Команды «чистят» значения полей во время миграции (например, меняют значения статуса или форматы дат) и забывают документировать маппинг. Всё кажется нормальным, пока отчёты, письма или биллинг не начнут вести себя по-другому.
Ошибки, которые проявляются чаще всего:
- Нет чёткой политики конфликтов для двойных записей и нет аудита для поиска несоответствий.
- Бэкифиллы не идемпотентны и не имеют чекпоинтов.
- Изменение смысла поля в середине миграции без версионированного маппинга и тестов.
- Забыты downstream-чтецы: аналитика, экспорты, вебхуки и фоновые задания.
- Удаление JSON-столбца слишком рано, до полного перемещения и верификации чтений.
Реальный пример: приложение хранит «профиль пользователя», «подписку» и «права» в одном JSON-столбце. Бэкифилл копирует данные в новые таблицы, но ночная задача всё ещё читает JSON и перезаписывает нормализованные таблицы, стирая недавние изменения. Обычно решение — не более хитрый код, а ясные правила: возобновляемые бэкифиллы, строгие маппинги и сохранение старого столбца до тех пор, пока новая модель не подтвердит соответствие реальности.
Быстрый чеклист перед финальным переключением
День переключения должен быть скучным. Если он всё ещё кажется прыжком веры, вероятно, нужен ещё один сухой прогон.
- Таблицы и релизы безопасно деплоятся: новые таблицы в проде, миграции можно запускать повторно, индексы и ограничения проверены.
- Бэкифилл виден и повторяем: виден прогресс, количество ошибок и чекпоинты, можно перезапустить без дублирования.
- Двойная запись включена, правила конфликтов записаны: вы знаете, чей источник выигрывает (например, новейший
updated_at) и логируете конфликты. - Переключения чтений защищены: чтения можно переключать по эндпоинту или по тенанту через флаги, и вернуть назад быстро.
- Уровень несоответствий допустим, и откат отработан: сравнивали ключевые итоги, выборочно проверяли записи и репетировали откат на похожих данных.
Пример сценария: приведение в порядок AI-сгенерированного приложения, где всё в JSON
Основатель выкладывает CRM-прототип, сгенерированный ИИ, за уикенд. Он работает для демо, но каждый профиль клиента хранится в одном JSON-блобе в столбце таблицы. Профиль может включать имя, email, статус, last_contacted, заметки и кастомные поля.
Через три месяца проблемы проявляются. Отчёты медлительны, потому что база парсит JSON для каждой диаграммы. Хуже — поле status в полном беспорядке: "Active", "active", "ACTIV", "In progress", "In-Progress" и "inprogress" примерно одно и то же. Фильтры пропускают записи, дашборды не совпадают, а заметки продаж попадают не в ту стадию.
Безопасный первый кусок — нормализовать только то, что двигает дашборд: клиентов и статусы.
Этот кусок может выглядеть так:
- Таблица
customersсо стабильными колонками (id,name,email,created_at). - Таблица справочника
statuses(id,canonical_name) с допустимым набором значений. - Связь между ними (либо
customers.status_id, либо отдельная таблицаcustomer_statusв зависимости от требований истории).
Далее бэкифилл из существующего JSON:
- Распарсить каждый профиль и вставить или обновить строку в
customers. - Смаппить грязные строки статусов в канонические статусы, с явным бакетом «unknown» для нераспознанного.
- Логировать всё, что не удалось распарсить, чтобы исправлять данные, а не догадываться.
Переключение остаётся поэтапным. Сначала переключите только чтение для дашборда на новые таблицы. Держите JSON-чтение для остального приложения и сравнивайте счётчики и итоги. Когда дашборд станет корректным и быстрым, переносите остальные экраны по одному.
Следующие шаги: завершить миграцию и сохранить чистоту данных
Когда чтения полностью перейдут на новые таблицы и у вас будет стабильный период без сюрпризов, решите судьбу старого JSON-столбца. Большинство команд либо «замораживают» его (прекращают записи, держат в качестве короткого safety window), либо удаляют после бэкапов и подписи на согласование.
Если вы отложили элементы безопасности ради скорости — добавьте их теперь. Нормализованные таблицы окупаются в долгосрочной перспективе тогда, когда они предотвращают плохие данные, а не только позволяют их хранить.
Закрепите новый контракт
Запишите правила, от которых теперь зависит приложение: какие поля обязательны, что значит «валидно» и где хранится каждая часть данных. Это будет контракт данных для будущих фич и поможет новым участникам команды не вернуть блоб «на время».
Одностраничный документ будет достаточен: имена таблиц, ключевые колонки, владение (кто что записывает) и короткий пример валидной записи.
Предотвратите откат обратно в блобы
После миграции самый большой риск — дрейф: новые фичи тихо начинают складывать дополнительные поля в catch-all JSON-столбец.
Заморозьте или удалите JSON-столбец после оговоренного окна стабильности. Добавьте отложенные ограничения и индексы, которые вы временно отложили (внешние ключи, уникалы, NOT NULL и индексы для ваших ключевых запросов). Если вы оставляете JSON-поле для истинного «misc» метаданных, добавьте лёгкую проверку, чтобы новые ключи не появлялись без плана.
Если вы унаследовали AI-сгенерированный код, который сильно опирается на JSON-блобы, и вам нужно подготовить его к продакшену, FixMyMess (fixmymess.ai) специализируется на диагностике и ремонте таких архитектур, включая поэтапные миграции, исправления логики и усиление безопасности с человеческой верификацией перед релизом.