Наблюдаемость обработчиков вебхуков: логи, идентификаторы событий и админ‑просмотр
Вебхуки молчат при ошибках без нужной видимости. Узнайте, как сделать наблюдаемыми обработчики вебхуков с логами проверки подписи, сохранением ID событий и простой админ‑панелью.
Почему обработчики вебхуков кажутся невидимыми, когда они ломаются
Вебхуки сложнее отлаживать, чем обычные API‑вызовы, потому что вы не нажимаете кнопку, которая отправляет запрос. Провайдер посылает событие в удобный для него момент, из инфраструктуры, которой вы не контролируете, и чаще всего вы узнаёте о проблеме только после жалобы клиента.
С типичным API‑эндпоинтом вы можете воспроизвести вызов, посмотреть ответ и править код. С вебхуками сбой может пройти тихо: провайдер повторяет попытки в фоне, ваше приложение возвращает общий 500, и вы остаётесь догадываться — был ли запрос подлинным, сработал ли обработчик и где именно он остановился.
Самое раздражающее — это пробел, который появляется после начала ретраев. Вы можете увидеть всплеск трафика, но потом ничего полезного: нет явного идентификатора события, нет следа того, что происходило при каждой попытке, и нет записи о том, обработали ли вы уже это событие. Так легко получилось двойное списание, пропуск обновления подписки или создание дубликатов записей.
Наблюдаемость обработчика вебхуков — это способность быстро ответить на несколько вопросов, не читая сырые полезные данные и не включая шумный debug‑режим:
- Кто отправил этот запрос и прошла ли проверка подписи?
- Что это за событие (ID, тип, временная метка) и видели ли мы его раньше?
- Что сделал наш обработчик и почему он упал (если упал)?
Хорошая наблюдаемость остаётся небольшой, безопасной и простой в поддержке. Не нужен сложный мониторинг: несколько структурированных логов, сохранённый идентификатор события и крошечная админ‑панель превратят невидимый вебхук в понятный инцидент за минуты.
Что значит «наблюдаемый» для эндпоинта вебхука
«Наблюдаемый» означает, что когда доставка не удалась (или выглядит нормально, но привела к неверному результату), вы можете ответить, что произошло, без догадок, повторной слепой отправки или добавления одноразовых print‑вызовов.
Для любой доставки вы должны уметь ответить:
- Получили ли мы запрос и когда?
- Прошла ли верификация подписи или нет, и почему?
- Какое это было событие (event ID) и обработано ли оно уже?
- Сколько заняла обработка и где ушло время?
- Что мы вернули отправителю (код статуса и тип ошибки)?
Это ядро: ясная трасса от «пришло» до «завершено» с достаточным контекстом, чтобы отладить ретраи, дубликаты и частичные ошибки.
Хорошая базовая практика — сохранять небольшой набор заголовков запроса (не все), результат проверки подписи (прошла/не прошла плюс короткая причина), стабильный идентификатор события, метки времени (получено/начато/завершено) и итог (processed, skipped as duplicate, rejected as invalid).
Будьте осторожны с конфиденциальностью. Не логируйте секреты, сырые подписи, токены аутентификации или полные полезные данные по умолчанию. Если нужна видимость тела запроса — сохраняйте минимальную, отредактированную сводку (например: тип события, хеш customer ID, сумма) и храните сырое тело только для краткосрочной отладки в защищённом месте.
Если в полезных данных могут быть персональные данные (имена, емейлы, адреса, данные о здоровье или финансах), обращайтесь с логами вебхуков как с данными пользователей: задайте сроки хранения, ограничьте доступ и документируйте, кто может их просматривать. Часто это именно то, что отличает «полезное логирование» от инцидента соответствия.
Логируйте проверки подписи, не сливая секреты
Проверка подписи — это тест «вы действительно тот, за кого себя выдаёте?» для вашего вебхука. Она не даёт случайным отправителям притворяться вашим платежным провайдером, почтовым сервисом или другой системой.
Для наблюдаемости нужно достаточно деталей, чтобы быстро ответить: выполнялась ли верификация и почему она не прошла. Суть — логировать результаты и контекст, а не секреты.
Безопасный шаблон — одна запись проверки на каждый запрос с полями, полезными для саппорта и отладки, но безопасными для передачи в тикете.
Логируйте, например:
- Result:
verified=true/falseи понятнуюreason, напримерmissing_signature,bad_format,timestamp_out_of_windowилиmismatch - What you expected: имя алгоритма (например
hmac-sha256) и какой заголовок вы проверяли (только имя заголовка) - Timing context: серверный таймстамп, возраст запроса (в секундах) и применялась ли защита от воспроизведения
- Identifiers: ваш сгенерированный
request_idи, если есть, event ID провайдера
Не логируйте секретный ключ, сырую подпись, полный необработанный payload или неотредактированные заголовки.
Когда верификация не проходит, избегайте логов с «дампом» запроса. Лучше логировать короткую редактированную сводку: размер тела, content‑type и какие обязательные заголовки были присутствующими.
Добавьте простые счётчики, чтобы ошибки были видны даже когда никто не смотрит логи. Минимум — отслеживать итоги для verified, failed и missing signature (опционально по провайдеру). Если при деплое случайно поменяли ожидаемое имя заголовка, в логах должен подскочить reason=missing_signature, а не просто туманная 401 без подсказки.
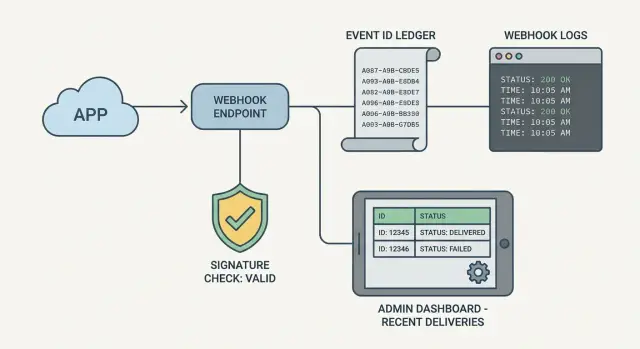
Сохраняйте ID событий, чтобы дедупить и трассировать ретраи
Большинство провайдеров повторяют одно и то же событие, если ваш эндпоинт таймаутит, возвращает 500 или попадает в сетевую ошибку. Если вы не сохраняете стабильный идентификатор события, можно списать платёж дважды, создать ресурс дважды или отправить дублирующие письма. Сохранение event ID — самый простой путь к идемпотентности: одно и то же событие может прийти 1 или 10 раз, но вы примените его эффект только один раз.
Начните с сохранения небольшой записи для каждого входящего вебхука, даже если пока не делаете ничего больше. Это можно хранить в таблице БД, key‑value хранилище или в очереди с аудиторной таблицей.
Минимальная запись обычно включает провайдера, event ID, время получения, статус (received/processed/failed/ignored) и короткое сообщение об ошибке.
Далее, для каждого запроса делайте в таком порядке: извлечь event ID, попытаться вставить запись с уникальным ограничением на (provider, event ID), и если запись уже есть — быстро вернуть 200 и пропустить бизнес‑действие. Эта простая проверка превращает ретраи из догадок в понятную хронологию.
Некоторые провайдеры не присылают явный event ID, или ваш обработчик не может его прочитать до верификации. В таких случаях выведите собственный идентификатор из стабильных частей запроса, например хэш от provider + путь запроса + стабильный заголовок + сырые байты тела. Избегайте таймстампов и всего, что меняется между попытками.
Время хранения важно, потому что полезные данные вебхуков часто содержат персональные данные. Практическое правило: храните сводки дольше, а сырые данные краткосрочно (или вообще не храните). Держите строку события (provider, event ID, таймстемпы, статус) 30–90 дней, сырое тело — 24–72 часа (если вообще нужно), и ограничьте длину сообщений об ошибках, чтобы снизить риск утечки секретов.
Пример: провайдер платежей повторяет одно и то же invoice.paid событие три раза. С сохранёнными ID вы видите одну запись со статусом processed и последующие доставки помечены как duplicate — вы уверены, что клиента не списали дважды и понимаете, почему провайдер продолжал пытаться.
Записывайте жизненный цикл: от получения до ответа
Вебхук может выглядеть «нормально», потому что отправителю отдан 200, а внутри вашего приложения всё упало. Чтобы наблюдаемость стала реальной, разделите получение доставки (что вы отдали отправителю) и бизнес‑обработку (что реально сделал ваш код).
По возможности подтверждайте быстро, а тяжёлую работу выполняйте в фоне. Даже если обрабатываете в синхронном режиме, фиксируйте оба этапа отдельными шагами, чтобы понять, была ли проблема в верификации, парсинге, БД или тайм‑аутах.
Простая модель жизненного цикла, по которой можно делать запросы
Выберите небольшой набор состояний и придерживайтесь его. Суть не в идеальной детализации, а в быстрых ответах.
Записывайте одну запись (row/document) на входящее событие с:
- Таймстемпами: received, verified, processing started, processing finished, responded
- Длительностями: время верификации, время обработки, общее время
- Состоянием: received, verified, processed, failed, ignored
- Ответом: код статуса, версия обработчика (опционально), класс ошибки (без секретов)
- Корреляцией: event ID провайдера и ваш внутренний correlation ID
С этим в месте паттерны проявляются быстро. Если большинство ошибок случается после верификации и занимают ~25 секунд, вероятнее всего проблема в медленных запросах к БД, зависшем worker‑е очереди или отсутствующем индексе.
Correlation ID связывает вебхук с остальной системой
Вебхук редко заканчивается на эндпоинте. Он создаёт пользователя, отмечает счёт оплаченным, отправляет письмо или обновляет доступ.
Храните event ID провайдера и генерируйте correlation ID, который передаётся в логи и в downstream job‑ы. Тогда один поиск покажет цепочку: запрос получен, подпись проверена, задача поставлена в очередь, платёж отмечен, письмо отправлено.
Это важно в кодовой базе, где обработчик смешивает «ответить на вебхук» и «выполнить всю работу» в одной функции. Явный жизненный цикл превращает тайну в хронологию.
Пошагово: добавляем наблюдаемость в существующий обработчик
Каждый входящий вебхук должен оставлять след, по которому можно пройтись позже, даже если он упал на полпути.
Практический порядок, который хорошо работает на уже существующем эндпоинте:
- Добавьте структурированные логи с согласованным набором полей на каждый запрос (provider, event ID, request ID, signature checked, outcome, duration).
- Проверяйте подпись рано, затем логируйте только результат (pass/fail) и причину. Никогда не логируйте секрет или сырую подпись.
- Сохраняйте event ID провайдера сразу, как только он доступен, и дедупьте по нему. Если это ретрай — верните безопасный ответ и запишите, что он был deduped.
- Оборачивайте бизнес‑логику так, чтобы вы всегда фиксировали статус, класс ошибки и время, даже если бросается исключение.
- Добавьте крошечную админ‑панель, показывающую последние события вебхуков и детали, необходимые, чтобы ответить «что произошло?»
После первого шага держите схему логов стабильной. Если поля меняются каждую неделю, поиск превращается в догадки. По возможности генерируйте request ID на краю (edge) и пробрасывайте его в логи и в запись события.
Для проверок подписи делайте сообщения об ошибках человечными: «Signature failed: missing header X» — это действие‑ориентированно. «Invalid signature» мало что говорит. Здесь же команды чаще всего случайно сливают чувствительные данные, поэтому строго контролируйте, что сохраняете.
Для админ‑панели не нужна полная аналитика. Таблица из 50 последних событий и страница деталей обычно достаточно. На странице деталей показывайте время получения, event ID, статус обработки, код ответа, длительность и последний класс ошибки (например: ValidationError vs DatabaseError).
Небольшая админ‑панель, которая отвечает «что произошло?»
Не нужна развёрнутая дашборд‑система, чтобы разбираться с вебхуками. Самый маленький полезный админ‑просмотр — экран с таблицей недавних событий и панелью деталей. Когда спрашивают, почему платёж, регистрация или отправка не обновились, вы должны ответить за пару минут.
Таблица недавних событий должна показывать достаточно, чтобы заметить паттерны: повторяющиеся ретраи, сбой у провайдера или возвраты 500 со стороны обработчика. Держите формат согласованным, чтобы было удобно сканировать.
Включите:
- Event ID (ID провайдера и ваш внутренний ID, если есть)
- Провайдер и тип события, время получения
- Статус (received, verified, processed, failed, ignored)
- Попытки и время последней попытки
- Последнее сообщение об ошибке (короткое, усечённое)
В панели деталей покажите то, что нужно человеку: прошла ли проверка подписи, какая версия обработчика выполнялась, что было возвращено, ключевые таймстемпы (received/verified/processed) и correlation ID, который связывается с логами.
Действия могут быть полезны, но только если они безопасны: переобработать (только если идемпотентно), пометить как ignored (для шума или тестов), добавить внутреннюю заметку и скопировать сводку для саппорта (event ID, статус, последнее сообщение об ошибке).
Ограничьте доступ к этой панели только администраторам и логируйте каждое админ‑действие (кто, когда, почему).
Распространённые ошибки, которые усложняют отладку вебхуков
Вебхук может быть «рабочим» и при этом абсолютно непонятным при сбое. Большая часть проблем — мелкие решения, которые скрывают реальную причину или создают шум.
Одна из больших ошибок — логировать полные сырые payload’ы. Многие тела вебхуков содержат емейлы, адреса, токены или даже секреты по ошибке. Вместо этого логируйте безопасную сводку: тип события, провайдера, event ID, таймстемп запроса и короткий хеш тела. Если нужен глубже уровень — храните зашифрованную копию с коротким сроком хранения и жёстким доступом.
Ретраи легко становятся проблемой сами по себе. Если событие уже обработано, возврат не‑2xx часто вызывает бесконечные повторы и дублирующие действия. Сделайте «уже обработано» явным исходом и возвращайте 2xx с понятной записью в логах о дедупе.
Ещё одна ловушка — смешивать ошибки верификации с ошибками обработки. Если обе помечены просто «500», вы теряете способность быстро действовать. Верификация — это сигнал безопасности; сбой в бизнес‑логике после верификации — баг приложения.
Операционные проблемы, которые встречаются часто:
- Нет тайм‑аутов на вызовы к БД или внешним API, обработчик висит пока провайдер не бросит попытку
- Ошибки логируются без провайдера, типа события, event ID и внутреннего request ID
- Логируются только исключения, а не принятое решение (ignored, queued, processed, deduped)
- Разные форматы логов в разных окружениях, из‑за чего сравнение сложно
Пример: провайдер платежей ретрит событие 12 раз. Ваши логи показывают 12 строк с «500», но нет ни малейшей подсказки — подпись не прошла ли, БД не успела ли ответить, или событие уже было обработано. С наблюдаемостью первая запись показала бы «verified ok», следующая — «DB timeout after 3s», а последующие ретраи — помеченные как deduped, когда event ID сохранён.
Быстрые проверки перед тем, как считать всё готовым
Тестируйте наблюдаемость так, будто вы уставший человек под давлением. Если вы не можете быстро ответить на базовые вопросы, будущий вы будет страдать, когда провайдер часами будет ретрить одно и то же событие.
Начните с простого бенчмарка: возьмите реальный event ID провайдера и засеките время. Вы должны найти это единичное событие (и его историю доставок) за меньше чем 30 секунд, без угадываний, какой сервер его обслуживал.
Короткий чек‑лист ловит большинство пробелов:
- Поиск работает: вставка event ID провайдера показывает одну ясную запись, а не пять почти‑дубликатов
- Статус подписи очевиден: логи показывают verified yes/no и причину при ошибке
- Ретраи видны: число попыток и время последней попытки легко найти
- Тип ошибки ясен: можно отличить исключение от тайм‑аута и ошибки валидации
- Данные в безопасности: секреты и персоналка исключены или отредактированы
Проведите одну реалистичную тренировку. Спровоцируйте событие, которое известно тем, что упадёт (например, payload без обязательного поля). Подтвердите, что вы можете ответить: дошло ли это до вас, прошла ли верификация, что вы вернули, было ли медленно и ретрилось ли оно.
Наконец, проверьте случайные утечки. Вебхуки часто содержат емейлы, адреса, токены или полные метаданные карт. Логи должны хранить только необходимое для отладки: event ID, провайдер, таймстемпы, результат подписи, статус и короткое сообщение об ошибке.
Пример: неудавшийся платёжный вебхук и как вы его трассируете
Типичный тикет саппорта: провайдер платёжных услуг присылает invoice.paid, карта клиента списана, но у клиента по‑прежнему нет доступа к платному плану.
С наблюдаемостью вы перестаёте догадываться. Открываете админ‑панель и ищете по временному окну. Находите точный вызов вебхука.
Первые вопросы отвечаются сразу: проверка подписи — “pass”, event ID провайдера сохранён (например evt_01H...), и метка времени запроса совпадает с тем, что показывает провайдер. Вы знаете, что запрос реальный и дошёл до сервера.
В деталях события жизненный цикл показывает:
- Received: 2026-01-20 14:03:12
- Verified: pass
- Processing: failed
- Responded: 500
Поле ошибки указывает причину, например: "Cannot insert subscription row: missing user_id." Это говорит, что баг в вашем коде, а не у провайдера.
Далее идут ретраи. Здесь важна идемпотентность. Поскольку вы храните event ID и считаете его уникальным, обработчик не даёт доступ дважды. Последующие доставки записываются как дубликаты и пропускаются, либо переобрабатываются безопасно, в зависимости от вашей архитектуры.
После исправления бага вы можете переобработать провалившееся событие из админ‑панели. Статус меняется на processed, код ответа становится 200, и клиент получает доступ.
Для саппорта у вас теперь чистые факты: метка времени исходного события, event ID и текущий статус (received, verified, processed, failed).
Следующие шаги, если код вебхуков всё ещё хрупок
Если ваш обработчик вебхуков всё ещё как чёрный ящик, начните с самой маленькой правки, которая даёт сигнал: залогируйте результат проверки подписи (pass/fail) и сохраните event ID провайдера. Часто этого достаточно, чтобы превратить «не работает» в понятный путь к исправлению, без изменения бизнес‑логики.
Держите первые логи скучными и безопасными. Фиксируйте исходы и время, а не секреты. Логируйте, что проверка не прошла, какого провайдера это касалось и какой event ID был включён, но никогда не логируйте сырые заголовки или значения подписи.
Когда вы надёжно сохраняете event ID и статусы, добавьте простую админ‑панель. Не стройте полный дашборд сразу. Простая таблица, отвечающая на вопросы «получили ли мы это, прошла ли проверка, обработали ли мы это, какая была ошибка и что мы вернули?» — часто достаточна.
Если код был сгенерирован AI и выглядит ненадёжно, запланируйте рефакторинг. Признаки проблем: сломанные предположения об аутентификации, запутанное поведение ретраев (двойные списания, дубликаты писем) и секреты, разбросанные в конфиге или логах.
Практический порядок работ:
- Добавить структурированные логи для результата проверки подписи и request ID
- Сохранять event ID вебхуков и дедупить по ним
- Записывать явный жизненный цикл статусов (received, verified, processed, failed)
- Добавить небольшую админ‑панель для недавних событий и ошибок
- Сделать целевой рефакторинг для ретраев, идемпотентности и обработки секретов
Если вы работаете с AI‑генерированным прототипом и нужно быстро вывести его в продакшн, FixMyMess (fixmymess.ai) помогает диагностировать и исправлять такие случаи: от ненадёжной аутентификации до небезопасных логов и багов ретраев.
Часто задаваемые вопросы
Как проще всего сделать мой обработчик вебхуков наблюдаемым?
Начните с трёх вещей на каждом запросе: результат проверки подписи, идентификатор события провайдера и явный итог вроде processed, failed или deduped. Добавьте времена (получено и завершено), чтобы замечать тайм-ауты. Эта минимальная база обычно превращает таинственный 500 в понятную проблему, которую можно исправить.
Почему ошибки вебхуков так трудно отлаживать по сравнению с обычными API‑вызовами?
Вебхуки сложно отлаживать, потому что вы не контролируете момент и место отправки — провайдеры чаще всего делают это асинхронно и повторяют доставку в фоне. Без сохранённых идентификаторов событий и структурированных логов каждая попытка выглядит как новый запрос, и нельзя понять — дубликат это, проблема с подписью или баг в обработке.
Что мне логировать для проверки подписи, чтобы не слить секреты?
Логируйте результат и причину, но не секретные данные. Хорошая запись: verified=true/false и короткая причина (missing_signature, timestamp_out_of_window), вместе с тем, какой заголовок вы смотрели и именем алгоритма. Никогда не логируйте секрет, сырую подпись или полные заголовки.
Как остановить повторы, которые вызывают двойные списания или дубликаты записей?
Сохраняйте идентификатор события провайдера как можно раньше и применяйте уникальное ограничение на (provider, event_id). Если запись уже есть, верните безопасный 2xx и пропустите бизнес‑действие, при этом зафиксировав, что событие было deduped. Это предотвращает двойное списание, дублирующее создание записей и повторные письма.
Что делать, если провайдер не присылает надёжный идентификатор события?
Сгенерируйте надёжный производный идентификатор из частей, которые не меняются между попытками: хэш от имени провайдера + путь запроса + стабильный заголовок + сырые байты тела. Не включайте таймстампы или что‑то, что отличается при каждой доставке. После генерации используйте его как обычный event ID для дедупа и трейсинга.
Какие поля жизненного цикла нужно записывать, чтобы понять, где произошёл сбой?
Разделяйте «получение доставки» и «бизнес‑обработку». Записывайте, когда запрос пришёл, когда завершилась верификация, когда началась и закончилась обработка, и какой код вы вернули. Так видно, ответили ли вы 200, но потом что‑то упало внутри, или же обработка заняла слишком много времени и провайдер отвалился.
Как логировать данные вебхуков, не создавая проблем с конфиденциальностью и соответствием?
По умолчанию храните только безопасные сводки: провайдер, event ID, тип события, таймстемпы, статус и короткий класс ошибки без секретов и персональных данных. Если храните сырые тела вообще — шифруйте их, ограничьте доступ и срок хранения. Обращайтесь с логами вебхуков как с пользовательскими данными: политика хранения и доступ критичны.
Что должен включать минимальный админ‑просмотр для вебхуков?
Достаточно таблицы последних событий и страницы деталей. Покажите event ID, провайдера, тип, время получения, статус, число попыток и время последней попытки, результат верификации, код ответа, длительность и последний класс ошибки. Кнопка «переобработать» возможна, но только если обработчик идемпотентен.
Какие самые распространённые ошибки усложняют отладку вебхуков?
Не вываливайте сырые тела в логи, не храните полные заголовки и токены. Отделяйте ошибки верификации от ошибок обработки и задавайте тайм‑ауты для БД и внешних вызовов. И главное — сохраняйте event ID, иначе вы теряете возможность понять дубликаты и повторы.
Мой обработчик вебхуков сгенерирован AI и постоянно ломается — что делать?
Если обработчик сгенерирован AI и ненадёжен, начните с аудита: проверка подписи, идемпотентность, обработка секретов и безопасность логов. Если нужно быстро починить — FixMyMess (fixmymess.ai) делает диагностику и исправления, включая обработчики вебхуков с ненадёжной аутентификацией, багами ретраев и небезопасным логированием.