Надёжные счётчики при одновременных запросах — как остановить дрейф метрик
Узнайте, как сохранить надёжные счётчики при одновременных запросах с помощью атомарных обновлений, ключей идемпотентности и пакетных записей, чтобы метрики оставались точными в продакшене.
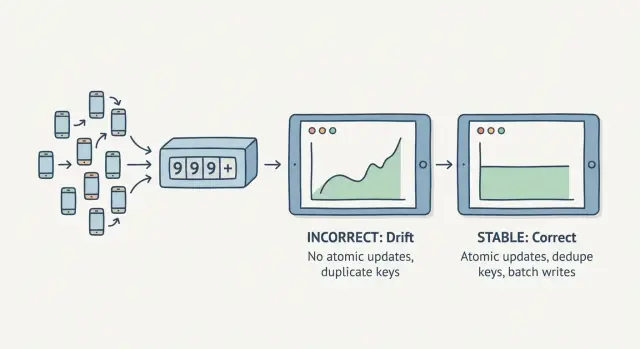
Почему счётчики дрейфуют, когда трафик приходит одновременно
Счётчик дрейфует, когда ему нельзя доверять. Вы обновляете панель и видите, что общее значение изменилось, хотя ничего нового не произошло. Или число скачет после короткого всплеска. Это трудно поймать в тестах, потому что обычно нужна настоящая конкуренция запросов.
Дрейф часто проявляется так:
- Один и тот же отчёт показывает разные итоги при каждом обновлении.
- Счётчики скачут после всплеска трафика или деплоя.
- Итого в одном месте (база данных) не совпадает с другим (аналитика).
Обычная причина — условие гонки: многие запросы пытаются обновить одно и то же число одновременно. Если ваш код делает «прочитать текущее значение, прибавить 1, записать обратно», два запроса могут оба прочитать 10, оба прибавить 1 и оба записать 11. Одно приращение теряется.
Поэтому проблема часто проявляется только после запуска. На ноутбуке или в спокойном стейджинге запросы приходят по одному. После кампании, популярной фичи или фоновых заданий, выполняющихся параллельно, обновления сталкиваются.
Есть ещё компромисс между точностью и свежестью. Обновлять счётчик при каждом запросе можно, но только если обновление действительно безопасно при параллельности. Многие команды выбирают почти реальное время: быстро собирают события, затем обновляют итоги небольшими батчами каждые несколько секунд. Число выглядит чуть задержанным, но обычно стабильнее и его проще сделать корректным.
Простой пример: два пользователя нажали «Купить» в одну секунду. Если оба запроса отдельно вычисляют и записывают новый итог, счётчик покупок может недосчитать, хотя оба заказа прошли.
Выберите правильный тип метрики до того, как писать код
Многие «проблемы со счётчиками» на самом деле — проблемы определения. Если вы выбрали неправильный тип метрики, исправление инкремента не сделает аналитику стабильной.
Когда просят «счётчик», обычно имеют в виду одно из:
- Counter (счётчик): сколько раз что-то произошло (просмотры страниц, клики по кнопке)
- Sum (сумма): общая сумма по событиям (доход, минут просмотра)
- Unique count (уникальные): сколько разных пользователей/объектов что-то сделали (уникальные регистрации, уникальные покупатели)
- Rate (коэффициент/скорость): отношение за время (регистраций в час, конверсия)
Простой +1 часто подходит для низкоценностных событий с большим объёмом, например просмотров страниц. Небольшой шум от дублей обычно не критичен.
Но как только в игру вступают деньги, состояние пользователя или сообщения, нужна более строгая дефиниция «истины». Регистрации, покупки, отправка писем для сброса пароля, приглашения и «начало пробного периода» ретрасятся чаще, чем ожидают (клиенты, фоновые задания, платёжные провайдеры). Учёт ретраев как новых событий — причина раздутых дашбордов.
Практичный способ решения — выбрать источник правды:
- Append-only events (журнал событий): храните каждое событие отдельно, затем вычисляйте итоги по событиям.
- Stored totals (хранимые итоги): держите текущее число и обновляйте его по мере поступления событий.
Журналы событий проще аудировать и пересчитывать. Хранимые итоги читаются быстрее, но работают только если обновления корректны и дубликаты блокируются.
Пример: checkout получил payment_succeeded дважды, потому что первый webhook таймаутнулся. Если ваша метрика «покупки» — простой счётчик, она вырастет на 2. Если ваша истина — «одна покупка на payment_id», вы считаете уникальные payment_id, а не сырые доставки webhook.
Атомарные обновления: самый надёжный способ инкремента
Когда вам нужны надёжные счётчики при параллельности, используйте атомарные обновления. «Атомарно» значит, изменение происходит как единая операция: либо применяется полностью, либо нет. Никаких частичных состояний, никаких перезаписей между запросами.
Классический баг — read-modify-write: прочитал 100, прибавил 1 в коде приложения, записал 101. Два запроса могут оба прочитать 100 и оба записать 101.
Атомарные обновления выполняют инкремент внутри базы или хранилища, где это безопасно даже при множественных одновременных запросах:
UPDATE counters
SET value = value + 1
WHERE name = 'signups';
INCR signups
Быстрая проверка здравого смысла: если ваше приложение читает значение счётчика только чтобы прибавить к нему, вероятно, вы снова в зоне read-modify-write.
Атомарные инкременты не бесплатны. Если одна строка/ключ постоянно обновляется ("hot key", например глобальный счётчик просмотров), вы можете столкнуться с:
- конфликтами блокировок или замедлением обновлений
- повышенной задержкой во время всплесков
- отставанием репликации, если вы читаете с реплик
- таймаутами, которые вызывают ретраи
Ключи дедупликации: прекратите двойной учёт из-за ретраев и повторных доставок
Идемпотентность значит, что повторная отправка одного и того же действия даёт тот же эффект, что и однократная отправка. Для счётчиков это разница между «в основном правильным» и действительно надёжным.
Дублирующие события обычны:
- пользователь дважды нажал «Оплатить»;
- мобильный клиент потерял связь и ретраит;
- провайдер webhook повторно отправляет после 500;
- очередь повторно доставляет задание.
Ключ дедупликации обычно — event_id, который уникально идентифицирует реальное событие. Он может приходить от провайдера (идентификатор webhook), генерироваться клиентом UUID, создаваться на сервере или быть детерминированным ключом вроде order_id + event_type.
Когда у вас есть event_id, храните его и отказывайтесь учитывать одно и то же событие дважды. Базовое правило: сначала вставьте event_id, затем инкрементируйте, или сделайте оба действия в одной транзакции.
Распространённые варианты хранения:
- таблица processed events с UNIQUE-ограничением на
event_id - UNIQUE-индекс в таблице аналитики/событий
- кэш (например Redis) с TTL для коротких окон дедупликации
Пример: приходят вебхуки о покупке, обработчик таймаутится, и провайдер повторно шлёт webhook. Без дедупликации вы запишете две покупки и добавите доход дважды. С уникальным event_id второй запрос станет no-op.
Пакетные записи: меньше обращений в базу, стабильнее аналитика
При нагрузке одиночные записи по строке накапливаются. Это увеличивает время удержания блокировок, замедляет ответы и повышает шанс таймаутов или частичных сбоев. Батчинг сокращает количество кругов к базе и делает аналитику стабильнее.
Простая модель: быстро захватываем события, затем пишем сводки реже, но большими пачками. Общие подходы: буферизация с периодической отгрузкой каждые N секунд, очередь и агрегация в воркерах, плановые роллапы (ежечасно/ежедневно) или гибрид (маленькие realtime счётчики плюс периодические бэфиллы).
Компромисс — свежесть. Дашборд может отставать на секунды или минуты, но вы обычно получите меньше упавших записей и меньше всплесков из-за шторма ретраев.
Выбирайте окно батча в зависимости от назначения метрики:
- Секунды: live-ленты, rate limiting, виджеты «активны сейчас»
- Десятки секунд: маркетинговые дашборды и воронки регистраций
- Минуты: доход и большинство админ-отчётов
- Часы/дни: отчёты для финансов и аудита
Безопасный шаблон для счётчиков и аналитики
Относитесь к каждому инкременту как к следствию конкретного события. Счётчик — всего лишь сводка.
Шаблон, который выдерживает нагрузку:
-
Назовите событие и выберите стабильный уникальный id. Используйте то, что не меняется при ретраях (например:
order_id,payment_intent_idили сгенерированныйevent_id, проходящий через весь поток). -
Сначала запишите событие (или лёгкую строку дедупликации). Сохраните id в таблице
eventsилиdedupeс уникальным ограничением. -
Инкрементируйте атомарно. Используйте одиночный оператор инкремента, а не «прочитать, прибавить, записать». Если возможно, выполняйте запись события и обновление счётчика в одной транзакции.
-
Сделайте ретраи безопасными. Если вставка dedupe терпит неудачу из‑за уже существующего ключа, считайте это успешным и пропустите инкремент.
-
Батчьте там, где это имеет смысл, не нарушая правил. Буферизуйте инкременты и сливайте их периодически, но только после того, как запись события/dedupe надёжно сохранена.
Пример: пользователь нажал «Купить», ваш сервер создал событие purchase_completed с ключом дедупликации order_123. Если платёжный провайдер повторит webhook, вторая вставка упирается в UNIQUE-ограничение и вы не добавляете вторую покупку.
Ретраи, таймауты и очереди сообщений без раздутия счётчиков
Многие системы гарантируют «по крайней мере один раз» (at-least-once). По-простому: одно и то же сообщение может появиться дважды.
Таймауты — самая коварная версия. Клиент вызывает ваше API, ждёт, таймаутится и ретраит. Но сервер мог уже завершить работу и зафиксировать обновление счётчика. Теперь у вас два «успешных» запроса для одного реального действия.
Правило: повторяйте только ту работу, которая идемпотентна.
Практичный паттерн для очереди:
- API создаёт событие с уникальным
event_id(например,purchase-<order_id>) и ставит его в очередь. - Ворк обрабатывает событие и в одной транзакции пишет два шага: (1) отмечает
event_idкак обработанный, (2) инкрементирует счётчик. - Если сообщение доставляется повторно, воркер видит, что
event_idуже обработан, и пропускает инкремент.
Для отладки инцидентов храните логи простыми и последовательными:
event_id- временные метки (получено и зафиксировано)
- источник (API, очередь, cron)
- исход (processed, skipped as duplicate, failed)
- счётчик повторов
Распространённые ошибки, вызывающие дрейф метрик
Эти проблемы повторяются в разных продуктах.
Ошибка 1: читать и затем писать инкременты
Два запроса могут прочитать одно и то же значение и записать одинаковое новое. Используйте атомарный инкремент в базе, чтобы обновление происходило одной операцией.
Ошибка 2: считать до того, как действие действительно завершилось успешно
Если вы инкрементируете при старте запроса, вы будете переучитывать, когда действие позже провалится (отклонённый платёж, неотправленное письмо, откат транзакции). Считайте после фактического сигнала успеха.
Ошибка 3: ключи дедупликации без принуждения
Ключ дедупликации работает только если вы принуждаете уникальность на уровне базы (unique constraint/index). Без этого дубли всё равно проскользнут при ретраях и параллельных воркерах.
Ошибка 4: батчи, которые теряют данные
Батчинг снижает нагрузку, но данные в памяти могут пропасть при рестарте. Сделайте поведение flush явным: по времени, по размеру и при завершении процесса.
Ошибка 5: сломанные границы дня в роллапах
Ежедневные метрики дрейфуют, когда сервисы расходятся по часовым зонам или границам дня. Выберите один стандарт (обычно UTC), храните временные метки последовательно и держите сырые события достаточно долго, чтобы пересчитать роллапы.
Быстрые проверки, чтобы убедиться, что счётчики заслуживают доверия
Если вы не можете объяснить инкремент, вы не можете доказать его корректность. Даже простая таблица сырых событий достаточно хороша для spot-чеков.
Быстрая проверка здравомыслия:
- Можете ли вы отследить каждое приращение до
event_id, сохранённого вместе с сырым событием? - Принуждаете ли вы уникальность ключей дедупликации (unique index/constraint)?
- Обновляются ли счётчики атомарно (один оператор), а не read-modify-write в коде приложения?
- Сопоставляете ли вы итоги с сырыми событиями (даже ежедневная выборочная сверка)?
- Настроены ли оповещения о внезапных сбросах или необычно больших скачках?
Практический тест: выберите одну метрику, например «новые регистрации», вытащите 50 недавних event_id и проверьте, что каждое соотносится ровно с одним инкрементом. Затем воспроизведите тот же запрос/сообщение несколько раз и подтвердите, что счётчик не меняется.
Пример: исправление счётчиков регистраций и покупок в реальном приложении
Небольшое подписочное приложение отслеживает регистрации, покупки и «письмо приветствия отправлено». Недели всё выглядит хорошо. Затем трафик растёт и поддержка начинает слышать «Меня списали дважды» или «Я нажимал один раз». Итого отклоняются от отчётов платёжной системы.
Что происходит: двойные клики, ретраи клиентов после таймаутов и повторные платежные вебхуки. Если ваш код инкрементирует сначала, а потом разбирается, метрики дрейфуют.
Стабильное решение сочетает три шага:
- Дедупликация на действие:
signup:<user_id>,purchase:<payment_event_id>,email:<message_id>, сохраняемые с уникальным ограничением. - Атомарные инкременты: замените read-modify-write на одиночный инкремент в базе.
- Батчьте горячие обновления: оставьте realtime там, где нужно, батчьте там, где можно.
Простой план развёртывания:
- Повторите одинаковый webhook-пейлоуд 5–10 раз в стейджинге и убедитесь, что счётчики не двигаются после первого раза.
- Включите изменения за флагом функции и постепенно откройте для небольшой части трафика.
- Запустите задачу сверки, чтобы сравнить сырые события и счётчики и бэфилл差 на найденные расхождения.
- Мониторьте «попадания дедупликации», чтобы убедиться, что ретраи ловятся.
Следующие шаги: стабилизируйте метрики без полной переделки
Обычно не нужен полный пересмотр. Нужна чёткая карта, где создаются счётчики, где могут возникать ретраи и где проскальзывают дубликаты.
Начните с базового инвентаря:
- Где живёт каждый счётчик (база данных, кэш, аналитический инструмент)
- Откуда исходят события (эндпойнты, фоновые задания, вебхуки)
- Все пути ретраев (клиентские ретраи, ретраи очереди, повторные вебхуки)
- Как вы идентифицируете событие (
event_id,request_id,order_id) - Где происходят записи (в одном месте или в нескольких)
Затем исправляйте в этом порядке:
- Прекратите двойной учёт (ключи дедупликации и идемпотентная обработка на самых горячих путях)
- Сделайте инкременты атомарными
- Улучшайте производительность (батчинг, асинхронная обработка)
- Добавьте постоянные проверки (сверка сырых событий и счётчиков, оповещения о странных скачках)
Если вы унаследовали кодовую базу, сгенерированную AI, предполагаете, что логика счётчиков была скопирована и реализована по-разному в нескольких местах. Унификация этих путей в одну общую функцию или сервис часто даёт самое быстрое и надёжное исправление.
Если хотите второе мнение, FixMyMess (fixmymess.ai) специализируется на диагностике и ремонте проблем вроде неатомарных обновлений, отсутствия идемпотентности и чувствительных к повторным доставкам webhook в AI-сгенерированных приложениях. Бесплатный аудит кода может быстро выявить несколько мест, которые дают наибольший дрейф под реальным трафиком.