Лучшие практики обработки ошибок API для понятных сообщений пользователям
Узнайте лучшие практики обработки ошибок API: единый формат ошибок, безопасные сообщения и простой способ маппинга сбоев сервера на понятные состояния UI.
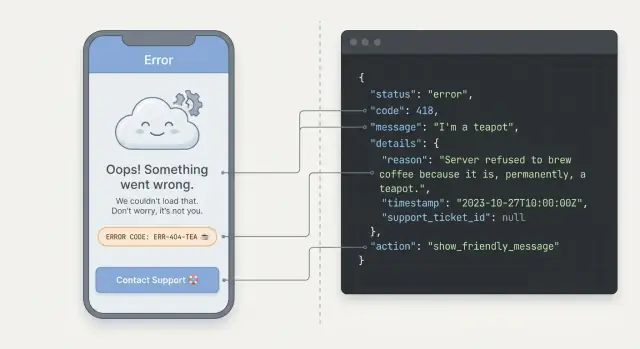
Почему непонятные ошибки API раздражают пользователей
Когда приложение падает, пользователи не видят «исключение». Они видят заблокированную задачу. Если сообщение смутное или пугающее, они могут испугаться, что потеряли данные, сделали что-то не так или даже подверглись взлому. Большинство не станет разбираться. Они уйдут, будут жать кнопку снова или обратятся в поддержку.
Непонятные ошибки ещё и выглядят случайными. На одном экране — «Что-то пошло не так», на другом — длинный стек трейс от сервера, на третьем — вообще ничего. Такая непоследовательность мешает людям понять, чего ждать. Даже если проблема мелкая, опыт кажется ненадёжным.
Для команды непоследовательные ошибки создают шум. Тикеты в поддержку становятся длиннее, потому что пользователи не могут описать, что произошло. Аналитика наполняется неструктурированными «unknown» ошибками. Инженеры тратят время на воспроизведение проблем, потому что форма ответа меняется между endpoint'ами или потому что 500 используется везде.
Когда ошибки непонятны, пользователи обычно делают одно из трёх: повторяют операцию много раз (что может вызвать дублированные запросы и иногда повторные списания), бросают поток (особенно оформление заказа, регистрацию и восстановление пароля) или пишут в поддержку со скриншотами вместо полезных данных.
Чёткая обработка ошибок решает это стандартизируя три вещи:
- единый формат ошибки (чтобы все endpoint'ы падали одинаково)
- безопасные формулировки (чтобы пользователь получил понятный следующий шаг без раскрытия внутренностей)
- предсказуемое поведение UI (чтобы каждая ошибка маппилась на известное состояние, например «повторить», «исправить ввод» или «войти снова»)
Что должна делать хорошая ошибка (для пользователя и для команды)
Хорошая ошибка — это не просто «что-то сломалось». Она помогает человеку восстановиться и помогает команде быстро найти причину.
Для пользователя ошибка должна содержать три вещи: что произошло (простыми словами), что делать дальше (ясный шаг) и в безопасности ли его данные. «Ваша карта была отклонена. Попробуйте другую карту или позвоните в банк. Списаний не было» — это успокаивает и даёт действие. «Платёж не прошёл: 402» — нет.
Для команды та же ошибка должна нести стабильные идентификаторы и полезный контекст. Обычно это небольшой набор кодов ошибок, на которые можно опираться на всех endpoint'ах, плюс согласованные поля, чтобы логирование, оповещения и обработка в UI не ломались, когда один endpoint изменится. Когда пользователь сообщает проблему, поддержка должна взять ID ошибки из UI, а инженер — найти точный трейс.
Что никогда не должно попадать в UI
Некоторые детали полезны для отладки, но небезопасны (или просто сбивают с толку) для пользователей. Не показывайте в пользовательских сообщениях:
- секреты (API-ключи, токены, пароли, строки подключения)
- трассировки стека и внутренние пути к файлам
- сырые SQL, параметры запросов и полный payload
- имена внутренних сервисов и инфраструктуры
- подробные правила валидации, которые помогают злоумышленникам угадывать ввод
Простое правило: возвращайте безопасные, понятные пользователю сообщения, а острые детали сохраняйте в логах, привязанные к стабильному коду и request ID.
Выберите несколько UI-состояний, которые будете поддерживать везде
Если каждый экран придумывает своё поведение при ошибке, пользователи теряются. Согласуйте небольшой набор UI-состояний, которые каждая страница, модалка и форма сможет использовать, и маппируйте ошибки API на эти состояния всегда одинаково.
Для большинства приложений достаточно краткого общего словаря: загрузка, успех, пусто, требуется действие (пользователь должен изменить что-то), повторить (временная проблема) и заблокировано (нельзя продолжить без поддержки или другого плана).
Определите простыми словами, что значит каждое состояние. Например, «пусто» — запрос прошёл, но нечего показывать, а «повторить» — запрос не удался и повтор может помочь.
Решите, что считать повторяемым, а что — нет. Таймаут, лимит по частоте или перегрузка сервера часто повторимы. Отсутствие права, неверный ввод или просроченный аккаунт обычно не повторимы, пока что-то не изменится.
Короткое правило:
- Повторить: временно, безопасно повторять
- Требуется действие: пользователь может исправить (редактировать, войти, подтвердить почту)
- Заблокировано: пользователь не может решить сам
Также планируйте частичный успех. Это случается, когда массовое действие сохранило 8 элементов, а 2 — нет. UI должен показать, что успешно, чётко указать, что нужно исправить, и позволить повторить только для неудачных элементов.
Спроектируйте единый формат ошибки (один вид для всех endpoint'ов)
Если каждый endpoint возвращает ошибки по-разному, UI придётся угадывать. Единая предсказуемая форма ошибки — одна из самых практичных лучших практик обработки ошибок API: она позволяет построить один набор правил в UI и переиспользовать их везде.
Простой JSON-формат
Выберите одну JSON-структуру и возвращайте её при всех ошибках (валидация, аутентификация, rate limit, баги сервера). Держите её небольшой, но с возможностью добавить детали.
{
"error": {
"code": "AUTH_INVALID_CREDENTIALS",
"message": "Email or password is incorrect.",
"details": {
"fields": {
"email": "Not a valid email address"
}
},
"developerMessage": "User not found for email: [email protected]"
},
"requestId": "req_01HZX..."
}
Используйте стабильные коды ошибок и не делайте текст сообщения контрактом. UI должен маппить коды на нужное состояние, а сообщение оставлять человечным.
Часто полезно иметь две подписи: сообщение для пользователя, которое безопасно показывать, и опциональное сообщение для разработчика, которое помогает отладке, но тоже не должно раскрывать секреты.
Для форм зарезервируйте место для ошибок по полям, чтобы подсвечивать конкретные поля без парсинга текста.
Несколько правил, которые предотвратят хаос в будущем:
- Всегда включайте
error.codeиrequestId. - Держите
error.messageбезопасным и простым. - Кладите проблемы на уровне полей в
details.fields. - Сохраняйте коды стабильными, даже если формулировка меняется.
- Никогда не сливайте трассировки стека или учётные данные.
Безопасные сообщения ошибок, понятные пользователям
Хорошие ошибки помогают людям восстановиться. Плохие заставляют повторять одно и то же или бросать процесс. Будьте конкретны в том, что пользователь может сделать дальше, не раскрывая внутренности системы.
Безопасное сообщение объясняет исход и следующий шаг, без утечки таких данных как имена таблиц, трассировки, ответы провайдеров, секретные ключи или факт существования адреса электронной почты в системе.
Держите два уровня сообщений: для пользователя и для разработчика. Пользовательское сообщение должно быть коротким и спокойным. Внутреннее — может содержать техническую причину, неудавшийся сервис и полный трейс (но только в логах, не в ответе API для конечного пользователя).
Рабочие шаблоны:
- Скажите, что произошло простыми словами: «Мы не смогли сохранить ваши изменения.»
- Подскажите, что делать дальше: «Попробуйте снова через минуту» или «Проверьте отмеченные поля.»
- Избегайте вины и жаргона: не пишите «invalid payload» или «unauthorized».
- Используйте одинаковый тон везде, чтобы ошибки казались знакомыми, а не пугающими.
Коды ошибок полезны, но рассматривайте их как опору для поддержки, а не как загадку. Если это помогает службе поддержки, показывайте короткий стабильный код (например, «Error: AUTH-102») и держите его постоянным.
Пример: регистрация не прошла из-за таймаута базы данных. Безопасное сообщение для пользователя: «Мы не смогли создать аккаунт прямо сейчас. Пожалуйста, попробуйте позже.» В логах можно записать: «DB timeout on users_insert, requestId=...».
Если у вас унаследован бэкенд, сгенерированный ИИ, такое разделение часто отсутствует. FixMyMess регулярно видит сырые исключения в ответах пользователям. Одна из первых поправок — переместить технические детали в логи, а в UI оставить чистое и согласованное сообщение.
Маппинг ошибок сервера на состояния UI (простая таблица)
Пользователи не думают в статус-кодах. Они думают в исходах: «Я могу это исправить», «Нужно войти снова» или «Что-то упало». Выберите небольшой набор UI-состояний и сопоставьте каждой ошибке одно из них.
Простой маппинг, который можно переиспользовать
Используйте одинаковый маппинг в web, mobile и админке, чтобы поведение было предсказуемым.
| Что случилось | Типичный код | Состояние UI | Что должен делать UI |
|---|---|---|---|
| Неправильный запрос (приложение отправило неверные данные) | 400 | Нужно исправить ввод | Подсветить поле или показать понятное сообщение. Не предлагать повтор. |
| Не залогинен / сессия истекла | 401 | Требуется повторная аутентификация | Перевести на логин, по возможности сохранить работу пользователя. |
| Залогинен, но нет прав | 403 | Нет доступа | Объяснить, что доступ закрыт, предложить «связаться с админом» или сменить аккаунт. |
| Не найдено | 404 | Ресурс отсутствует | Показать «не найдено» и предложить навигацию назад. |
| Конфликт (уже существует, рассинхронизация версий) | 409 | Требуется разрешение конфликта | Предложить обновить, переименовать или «попробовать снова» после синхронизации. |
| Валидация не прошла | 422 | Нужно исправить ввод | Показать сообщения по полям и сохранить состояние формы. |
| Ограничение частоты | 429 | Подождать и повторить | Сказать подождать, временно отключить кнопку и затем предложить повтор. |
| Ошибка сервера / аутсейдж | 500 | Временный сбой | Извиниться, дать возможность повторить и предложить опцию поддержки. |
Сетевые ошибки и таймауты отличаются от ответов сервера. Обращайтесь с ними как с «оффлайн/нестабильное соединение»: оставайтесь на том же экране, показывайте кнопку повтор и не утверждайте, что «пароль неверен», если запрос вообще не дошёл до сервера.
Практическое правило: если пользователь может исправить ошибку — оставляйте его в контексте (форма остаётся заполненной). Если не может — переводите в безопасное состояние (пере-логин, режим только для чтения или обращение в поддержку).
Пошагово: внедряем единые ошибки без полного рефакторинга
Вам не нужно перестраивать весь API, чтобы улучшить ошибки. Добавьте тонкий, единый слой над тем, что уже есть.
Начните с выбора небольшого набора кодов ошибок, которые вы будете поддерживать повсеместно. Дайте каждому короткое определение, чтобы backend и frontend использовали их одинаково.
Внедрите изменения в одном месте на каждой стороне:
- Выберите 8–15 кодов ошибок (например
AUTH_REQUIRED,INVALID_INPUT,NOT_FOUND,RATE_LIMITED,CONFLICT,INTERNAL). Опишите, что каждый значит и что пользователь должен увидеть. - Добавьте один серверный форматировщик ошибок (middleware/filter), который возвращает одинаковую JSON-форму для всех endpoint'ов, даже при неожиданном исключении.
- Добавьте один клиентский обработчик ошибок, который читает эту форму и маппит её на UI-состояния (ошибка поля, баннер, toast, полноэкранная ошибка).
- Мигрируйте постепенно: сначала обновите самые используемые потоки (логин, регистрация, оформление заказа, сохранение). Остальное оставляйте на потом.
- Зафиксируйте форму тестами, чтобы будущие изменения не ломали клиентов.
Практический подход к миграции — временно поддерживать оба формата: если endpoint уже возвращает кастомный JSON, пропускайте его, иначе оборачивайте в новый формат. Это снижает риск.
Пример: сначала исправьте логин. Сервер перестаёт возвращать сырые трассировки и отдаёт стабильный код ошибки с безопасным сообщением. Клиент видит INVALID_CREDENTIALS и показывает сообщение рядом с полем пароля. Если приходит INTERNAL — показывается общий баннер и предложение повторить.
Это особенно полезно в AI-сгенерированных кодовых базах, где каждый endpoint бросает ошибки по-разному. Один центральный форматировщик и один маппер могут быстро сделать приложение согласованным.
Типичные сценарии и как показывать ошибки в UI
Люди не встречают «ошибку API». Они встречают форму, которая не отправляется, сессию, которая истекла, или платёж, который не прошёл. Если UI обрабатывает все ошибки одинаково, пользователи будут догадываться, пробовать вслепую или уходить.
Формы: валидация должна быть локальной
Когда сервер говорит, что поле неверно, показывайте сообщение рядом с этим полем. Общий баннер «Что-то пошло не так» заставляет пользователя просматривать форму и переделывать ввод.
Хорошие практики:
- Подсвечивайте поле, сохраняйте введённые значения и фокусируйте первое неверное поле.
- Говорите простым языком: «Пароль должен быть не короче 12 символов», а не кодами.
- Если есть общая ошибка (например, «Email уже используется»), показывайте её рядом с кнопкой отправки.
Аутентификация: объясняйте, что может сделать пользователь
Для истёкших сессий придерживайтесь одного правила. Если можно безопасно обновить сессию в фоне — делайте это один раз и продолжайте. Если нельзя (обновление не удалось или действие чувствительное) — показывайте понятный запрос: «Пожалуйста, войдите снова, чтобы продолжить.» Избегайте пустых экранов с ошибкой.
Платежи и конфликты требуют особой осторожности. Скажите, что произошло и какое действие безопасно: «С вашей карты не списывались деньги. Пожалуйста, попробуйте снова.» Для конфликтов: «Этот элемент был обновлён кем-то ещё. Обновите, чтобы увидеть последнюю версию.»
Загрузки файлов должны отвечать на вопрос: что удалось, а что нет? Показывайте прогресс, список успешных файлов и простую кнопку повторить для неудачных. Если повтор может создать дубликаты, предупредите об этом заранее.
Пример: корректная обработка ошибки входа
Пользователь возвращается в приложение через несколько дней и пытается войти. Сохранённый токен сессии истёк, и сервер не принимает его. Это нормально, но опыт зависит от того, как вы это показываете.
Вот простой ответ, который следует лучшим практикам и безопасен:
{
"error": {
"code": "AUTH_TOKEN_EXPIRED",
"message": "Your session expired. Please sign in again.",
"requestId": "req_7f3a1c9b2d"
}
}
Используйте подходящий HTTP-статус (часто 401 Unauthorized для истёкшего или отсутствующего токена). code остаётся стабильным для UI и поддержки. message написано для человека и не раскрывает, какая именно часть аутентификации провалилась или какую библиотеку вы используете.
На стороне UI — одно спокойное действие: «Ваша сессия истекла. Войдите снова.» Кнопка переводит на экран логина. Не показывайте трассировки, сырой JSON или пугающие слова вроде «invalid signature». Если пользователь редактировал что-то, сохраняйте его работу и требуйте повторной аутентификации только при отправке.
Для поддержки покажите небольшую подсказку или кнопку копирования с requestId (или кодом ошибки). Это даёт команде что-то, по чему можно искать в логах: «Пожалуйста, укажите requestId req_7f3a1c9b2d», чтобы быстро найти точную запись.
Логирование и мониторинг, согласованные с вашими кодами ошибок
Если API возвращает чёткий код ошибки, а логи этого не содержат — преимущество теряется. Простое правило: логируйте тот же error.code, что отправляете клиенту, каждый раз.
Хорошая запись в логе небольшая, но содержательная. Фиксируйте достаточно для отладки, не сливая чувствительных данных:
error.codeи HTTP-статус (например:AUTH_INVALID_PASSWORD, 401)requestIdдля корреляции запроса насквозь- безопасный контекст пользователя (userId, но не email и не токены)
- экран или действие (имя маршрута, endpoint, метод)
- внутренние детали для разработчиков (stack trace, upstream error), которые хранятся только на сервере
Генерируйте requestId на краю (или принимайте его от клиента) и возвращайте в ответе. Когда ошибка блокирует пользователя, показывайте короткое сообщение и «Reference ID: X», чтобы поддержка могла быстро найти логи.
Мониторинг — это в основном подсчёт и группировка, но он должен соответствовать тому, как работает UI. Считайте ошибки по коду и по экрану, чтобы заметить паттерны: «PAYMENT_DECLINED чаще всего на checkout» или «RATE_LIMITED всплеск после релиза».
Решите заранее, на что вы будете тревожиться, чтобы оповещения не превратились в шум:
- резкий рост ошибок 500 (сбой сервера)
- повторяющиеся ошибки аутентификации (баг или злоупотребления)
- рост ошибок rate limit (проблемы с пропускной способностью или баг клиента)
- один код ошибки доминирует на одном endpoint'е или экране
Команды, которые исправляют AI-сгенерированные бэкенды, часто видят несогласованные коды и отсутствие request ID. Починка этого — быстрый выигрыш, который ускоряет все последующие исправления.
Частые ошибки и ловушки, которых нужно избегать
Много плохого UX возникает из мелких несогласованностей. Даже если каждый endpoint «правильный», продукт кажется случайным, когда ошибки грязные или небезопасные.
Типичные ловушки:
- Разные формы ошибок от разных endpoint'ов. Фронтенду приходится писать кучу особых случаев (
messageтут,errorтам,errors[0]где-то ещё). - Использование текста сообщения как «кода». Это работает до тех пор, пока кто-то не изменит формулировку ради ясности или перевода — и UI ломается.
- Утечка трассировок, SQL-фрагментов, внутренних ID или секретов. Пользователи не могут на это повлиять, а злоумышленники — могут.
- Обработка любой ошибки как toast «Что-то пошло не так». Если пользователь может исправить — скажите как. Если нет — скажите, что делать дальше.
- Автоповторы для небезопасных действий. Повтор безопасного чтения обычно OK. Повтор записи может создать дубликаты или повторные списания.
Команды часто сталкиваются с этими проблемами в AI-сгенерированных бэкендах. FixMyMess часто видит endpoint'ы с несколькими форматами и случайные утечки секретов в ошибках.
Быстрый чеклист перед релизом
Пройдитесь по этому перед выпуском. Он ловит мелкие пробелы, которые превращаются в злых тикетов.
Проверки вывода API
Убедитесь, что каждый endpoint говорит на одном «языке ошибок». Даже если причина разная, ответ должен быть знаком клиенту и прост для логирования.
- Возвращает ли каждый endpoint одну и ту же топ-уровневую форму ошибки (например:
error.code,error.message,requestId)? - Стабильны ли коды ошибок (не поменяются на следующей неделе) и задокументированы ли простыми словами?
- Всегда ли есть безопасное сообщение для пользователя и отдельные внутренние детали в логах при необходимости?
- Включает ли каждая ошибка
requestId, чтобы служба поддержки быстро её нашла?
Проверки поведения UI
Убедитесь, что приложение реагирует последовательно. Люди запоминают паттерны.
- Маппит ли клиент серверные ошибки на небольшой набор UI-состояний (валидация, требуется аутентификация, не найдено, конфликт, повторить позже)?
- Избегают ли сообщения внутренних деталей (трассировки, SQL, имена провайдеров) и дают ли один понятный следующий шаг?
- Когда ошибка требует действия, указывает ли UI на поле или шаг, который нужно исправить?
- Когда это не на стороне пользователя (сервер упал, таймаут), говорит ли UI, что проблема на нашей стороне и предлагает повтор?
Если ваш проект — AI-сгенерированный прототип, эти основы часто отсутствуют или разрозненны по endpoint'ам. FixMyMess может провести аудит и привести обработку ошибок в порядок без полного переписывания.
Следующие шаги (когда просить помощи в правке кода)
Выберите один критический поток и сделайте его «золотым стандартом» в первую очередь. Логин, checkout или онбординг — хорошие кандидаты, потому что они задействуют аутентификацию, валидацию и сторонние вызовы.
Перед изменениями соберите около 10 реальных примеров ошибок из продакшена (или логов и багрепортов). Перепишите их под ваш новый стандарт: одинаковые поля, одинаковые имена, одинаковый уровень детализации. Это даст ясную цель и сократит споры.
Практический путь, который обычно работает:
- Добавьте один общий серверный форматировщик, который превращает любое выброшенное исключение в ваш стандартный формат.
- Добавьте один общий клиентский маппер, который превращает этот формат в UI-состояния (повторить, исправить ввод, войти снова, обратиться в поддержку).
- Обновите один выбранный поток насквозь, включая тесты и парочку «фейковых» сбоев.
- Раскатайте паттерн endpoint за endpoint'ом, а не всё сразу.
- Держите короткие правила по сообщениям (что показывать пользователям, что оставлять внутренним).
Если ваше приложение было сгенерировано инструментами вроде Lovable, Bolt, v0, Cursor или Replit, заложите дополнительное время. Такие проекты часто имеют несогласованные обработчики по маршрутам, дублированные middleware и сырые объекты ошибок в ответах. Самый быстрый выигрыш — центральное форматирование и удаление разовых ответов.
Просите помощи, когда ошибки связаны с более глубокими проблемами: сломанные потоки аутентификации, открытые секреты, риски SQL-инъекций или «работает локально, но падает в проде». FixMyMess (fixmymess.ai) специализируется на диагностике и ремонте AI-сгенерированных кодовых баз, включая обработку ошибок, усиление безопасности и подготовку к деплою.
Если вы сделаете только одно на этой неделе — приведите в порядок один поток и измерьте результат. Именно так более понятные ошибки превращаются в меньше тикетов в поддержку и спокойных пользователей.
Часто задаваемые вопросы
Что должно обязательно содержать каждое API-ошибочное сообщение?
Хороший минимум — стабильный код ошибки, короткое безопасное для пользователя сообщение и request ID. Код позволяет интерфейсу реагировать предсказуемо, сообщение подсказывает следующий шаг пользователю, а request ID помогает службе поддержки найти точную запись в логах.
Стоит ли полагаться на HTTP-статусы или на собственные коды ошибок?
Сохраняйте смысл HTTP-статусов, но не полагайтесь на них в одиночку. Используйте статус для общей категории (аутентификация, валидация, ошибка сервера), а собственный error.code — для конкретных случаев, чтобы UI не угадывал причину.
Как сделать ошибки согласованными по всему приложению?
Выберите небольшой набор UI-состояний и сопоставляйте каждому коду ошибок одно из них. Тогда одинаковая проблема на разных экранах будет обрабатываться одинаково: одинаковый тон, одинаковый следующий шаг.
Как писать сообщения об ошибках, которые пользователи действительно поймут?
Поясните, что произошло простыми словами, подскажите следующий шаг и при необходимости успокойте пользователя (например, про то, был ли списан платёж). Избегайте жаргона вроде «unauthorized» и формулировок, убеждающих пользователя в его вине.
Какие детали никогда не должны появляться в сообщениях для пользователей?
Не показывайте пользователю трассировки стека, пути к файлам, сырые SQL-запросы, секреты, токены или имена внутренних сервисов. Эти детали путают и могут нести риск безопасности — храните их в логах, связанными с request ID.
Как лучше обрабатывать ошибки валидации в формах?
Рассматривайте валидацию как «нужно действие» и показывайте сообщения рядом с соответствующим полем. Сохраните введённые значения, фокусируйте первое неверное поле и избегайте общих баннеров, которые заставляют пользователя искать, что поправить.
Как приложение должно обрабатывать истёкшие сессии (401)?
Для истёкших сессий показывайте единое правило: либо спокойно обновляйте сессию в фоне, либо просите войти заново и старайтесь сохранить ввод пользователя. Не показывайте пугающий технический текст вроде ошибок подписи токена.
Как обрабатывать rate limit (429) и повторные попытки?
Сообщите пользователю подождать и попробовать снова, при этом в UI можно поставить короткую паузу, чтобы не допустить быстрых повторов. Не предлагайте повтор там, где пользователь должен что-то исправить (например, неверный ввод или недостаточные права).
Когда безопасно автоматически повторять неудачный запрос?
Предполагается, что повторы могут создать дубликаты при операциях записи, если не предусмотрена идемпотентность. Если вы не можете гарантировать безопасность, не выполняйте авто-повтор; предоставьте пользователю явную возможность повторить и объясните последствия.
Как улучшить обработку ошибок без полного переписывания API?
Добавьте один серверный форматировщик ошибок, который приведёт ответы всех endpoint'ов к одному виду, и один клиентский обработчик, который будет маппить коды на UI-состояния. Если бэкенд был сгенерирован ИИ и непоследователен, FixMyMess может быстро провести аудит и исправить утечки исключений, сломанные потоки аутентификации и нестабильные ответы.