Очередь DLQ для фоновых задач: повторы и безопасное воспроизведение
Узнайте, как очередь dead-letter для фоновых задач ловит poison messages, ограничивает повторы и позволяет безопасно воспроизводить задачи без дублирующих побочных эффектов.
Что идёт не так, когда фоновые задачи постоянно падают
Фоновая задача обычно выполняется «вне поля зрения»: отправить письмо, списать деньги, изменить размер изображения, синхронизировать запись. Когда она падает один раз, повтор часто решает проблему. Проблема начинается, когда та же задача падает снова и снова, без ограничения и без понятного места, куда её положить.
Такую задачу часто называют «poison message». Простыми словами: один плохой вход или ситуация, из‑за которых воркер падает каждый раз, когда сталкивается с ней. Это может быть неверный payload, отсутствующая запись в базе, истёкший API‑ключ или баг в коде, который проявляется только для одного клиента.
Бесконечные повторы вредят сильнее, чем кажется. Они могут:
- Создать outage, заставляя воркеры тратить время на одни и те же неудачные задачи вместо обработки рабочих.\n- Увеличить расходы (больше вычислений, операций очереди, трафика БД).\n- Засыпать логи и алерты, пока реальные проблемы игнорируются.\n- Вызывать повторные побочные эффекты — например, двойное списание или повторную отправку письма, если задача падает после выполнения действия.
Обычная неисправность — частичный успех. Пример: задача отправляет письмо, потом падает, не записав в базу, что письмо было «отправлено». При следующем повторе флаг не найден и письмо отправляется снова. В результате — дубли, сердитые пользователи и запутанная история аудита.
Именно поэтому команды добавляют dead-letter queue (DLQ) для фоновых задач. Вместо вечных повторов вы ограничиваете попытки и откладываете падающую задачу в сторону с деталями ошибки. Затем исправляете причину и воспроизводите её целенаправленно.
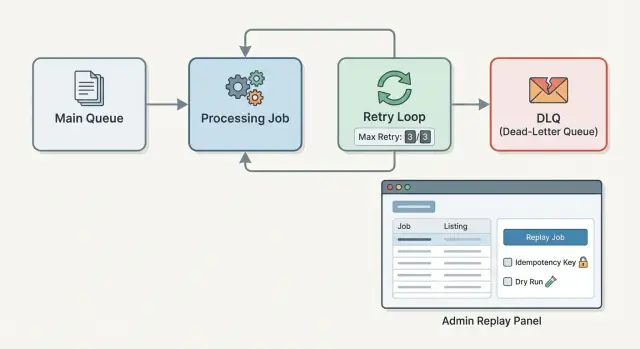
Надёжная схема состоит из трёх частей: политика повторов, которая останавливается до того, как всё развалится; запись в DLQ, сохраняющая, что случилось; и поток воспроизведения, аккуратно работающий с дублями. Если вы унаследовали ненадёжный воркер (включая сгенерированный AI), эти предохранители превратят шумную систему в ту, которой можно доверять.
Очередь DLQ, объяснённая без жаргона
Dead-letter queue (DLQ) — это место хранения фоновых задач, которые упали и не должны автоматически пытаться снова. Это не кладбище, где работа тихо исчезает. Это место, где ошибки становятся видимыми, доступными для проверки и исправления.
Думайте о ней как о перемещении застрявшей задачи с основной линии, чтобы остальная система могла продолжать работу. Вы выбираете ясность вместо бесконечных повторов.
Несколько терминов, которые путают:
- Очередь повторов: задачи, которые упали, но, как ожидается, смогут выполниться позже (например, временная сеть). Они запускаются снова после задержки.
- DLQ: задачи, которые упали и требуют человеческого вмешательства, исправления данных или кода, либо решения перед повтором.
- Parking lot queue: более общий бакет, который некоторые команды используют для «не срочных» элементов. На практике он часто превращается в неформальный DLQ без чётких правил.
Когда же повторять, а когда отправлять в DLQ? Повторяйте, если отказ, скорее всего, временный и безопасно повторим. Отправляйте в DLQ, если повторы вряд ли помогут или могут навредить. Например, «превышен лимит запросов у провайдера» обычно стоит повторить. «Неверный ID клиента» или «отсутствуют обязательные поля» обычно требуют исправления данных или кода и попадают в DLQ.
Когда задача попадает в DLQ, она должна нести достаточно контекста для отладки и безопасного повторного запуска позже:
- Payload задачи (точные входные данные)
- Сообщение об ошибке и стек вызовов (или эквивалент)
- Счётчик повторов и временные метки (первое падение, последняя попытка)
- Стабильный идемпотентный ключ или отпечаток задачи
- Последнее известное состояние побочных эффектов (если есть), например «charge created» или «email sent»
Последний пункт важен. DLQ — это не просто ловушка для ошибок. Это способ, чтобы следующая попытка была контролируемой и информированной.
Решите, что повторяемо, а что нет
Повторы полезны только когда проблема временная. Если проблема постоянная, повторы просто тратят время воркеров и скрывают реальную проблему. Это первое решение при внедрении DLQ: что можно попробовать снова, а что нужно останавливать сразу.
Простое правило работает хорошо: повторяйте, если задача может сработать позже без изменения кода или входных данных. Если с тем же payload это никогда не сработает, не пытайтесь повторять.
Классифицируйте ошибки по намерению
Вместо того чтобы трактовать все исключения одинаково, разбейте их на понятные категории:
- Временные: тайм‑ауты сети, обрывы соединения с БД, кратковременные 5xx от провайдера.\n- Троттлинг: rate limits (429), превышение квоты, «try again in 60 seconds».\n- Не найдено / отсутствующее состояние: связанная запись удалена, пользователь больше не существует.\n- Неверный ввод: payload не проходит валидацию, отсутствует обязательное поле, неверный формат.\n- Аутентификация / права: истёкшие креды, отозванный доступ, запрещённое действие.
Эта классификация должна определять дальнейшие действия: немедленный повтор, отложенный повтор или перемещение в DLQ с понятной причиной.
Пример: задача, которая списывает деньги с карты, падает с тайм‑аутом у платежного API. Это временная ошибка — имеет смысл повторить. Но если задача падает из‑за отсутствия customer ID в payload, повторы не помогут. Перемещайте её в DLQ и сигнализируйте кому‑то исправить данные (или того, кто создаёт задачу).
Почему это важно для алертов и воспроизведения
DLQ — это не просто стоянка. Причина, по которой вы поместили задачу туда, говорит, что делать дальше:
- Временные ошибки часто означают, что нужна лучшая стратегия backoff, а не человек.\n- Неверный ввод обычно требует фикса кода или данных перед воспроизведением.\n- Ошибки аутентификации обычно требуют ротации ключей.
Это также делает воспроизведение безопаснее. Если задача в DLQ с причиной «invalid payload», админский инструмент может по умолчанию блокировать воспроизведение и попросить исправление сначала. Многие унаследованные воркеры ломаются, потому что всё считается «повторяемым», пока кто‑то не задаст чёткие категории и условия остановки.
Установите политику повторов, которая не сломает систему
Повторы полезны, но неконтролируемые повторы могут превратить одну сломанную задачу в общесистемный outage. Хорошая политика ограничивает ущерб, распределяет нагрузку во времени и прекращает попытки, когда задача явно не будет работать.
Максимум попыток должен соответствовать типу ошибки. «Один размер на всех» — путь к повтору не тех вещей. Нестабильный сетевой вызов может заслуживать 5–10 попыток. Плохой payload (отсутствуют обязательные поля) не должен получать 10 попыток — его надо быстро в DLQ. Рассматривайте DLQ как место, куда идут задачи, когда ваш бюджет повторов исчерпан.
Backoff и джиттер простыми словами
Backoff — значит увеличивать интервалы между попытками. Это даёт время зависимым сервисам восстановиться и не даёт воркерам молотить один и тот же эндпоинт.
- Фиксированный бэкофф: ждать одинаковое время между повторами.\n- Экспоненциальный бэкофф: ждать всё дольше с каждой попыткой.\n- Джиттер: добавлять небольшую случайную задержку, чтобы многие задачи не ринулись в одну секунду.
Пример: у платёжного провайдера кратковременный отказ. Без джиттера все неудачные задачи попытаются через 30 секунд и вызовут вторую волну отказов.
Ограничения по времени, которые предотвращают «бесконечную боль»
Задайте два таймера:
- Таймаут на попытку (сколько максимум может длиться одна попытка до отмены).\n- Общее окно времени (как долго вы готовы пытаться, прежде чем сдаться).
Практичный дефолт для многих команд: 3–5 попыток, экспоненциальный бэкофф от 10–30 секунд, небольшой джиттер (0–10 секунд), таймаут на попытку, соответствующий нормальному времени вызова, и общее окно 15–60 минут. Цель не в совершенстве, а в том, чтобы остановить накатывающиеся повторы прежде, чем они заблокируют рабочую очередь.
Что сохранять при перемещении задачи в DLQ
Когда фоновая задача попадает в dead-letter queue (DLQ), вы сохраняете не просто «упавшее сообщение», а дело, к которому кто‑то может вернуться через дни, чтобы понять, исправить и безопасно воспроизвести.
Начните с минимального набора данных, нужного для воспроизведения и принятия решения. Запись DLQ обычно включает:
- Тип задачи (какой воркер должен её обработать) и версию (если форма payload меняется со временем)\n- Оригинальный payload (как получен) и редактированное, безопасное для админа резюме\n- Счётчик попыток и история повторов (сколько раз и почему падала)\n- Временные метки: первое появление, последняя попытка, перемещение в DLQ\n- Детали ошибки: последнее сообщение/стек и цепочка корневых причин, если она у вас есть
Стабильный ID задачи критичен. Генерируйте его при создании задачи и сохраняйте одинаковым через повторы и воспроизведения. Добавьте ключ дедупликации или идемпотентности, который представляет побочный эффект, который вы хотите совершить (например, send_invoice_email:invoice_123:recipient_456). Это позволит воспроизводить задачу, не дублируя действие.
Будьте осторожны с тем, что видит админ. Payload часто содержит секреты, токены или персональные данные. Храните сырой payload только если действительно нужно, но также сохраняйте безопасную, редактированную версию (например, показывайте user ID, а не email; последние 4 цифры карты, а не полный токен).
И наконец, сохраняйте и последнюю ошибку, и первоначальную причину, когда это возможно. Пример: задача может закончиться «timeout calling provider», но корень в «missing API key». Если DLQ хранит всю цепочку, фикса очевидна и воспроизведение безопаснее.
Шаг за шагом: добавьте DLQ и ограниченные повторы в воркер
Относитесь к каждому запуску задачи как к небольшой транзакции: либо она завершилась, либо упала так, чтобы вы могли о ней подумать позже. Dead-letter queue — это просто место, куда попадают «мы попытались достаточно, теперь нужно человеческое внимание» задачи.
Простой поток, работающий в большинстве стеков:
- Запускайте обработчик внутри try/catch (или эквивалента), который ловит типизированную ошибку, а не только строку.\n- При ошибке увеличивайте счётчик попыток и вычисляйте время следующего запуска с учётом бэкоффа (например: 1м, 5м, 20м) с небольшим джиттером, чтобы повторы не сходились.\n- Если ошибка явно неповторима (плохой ввод, отсутствующая запись, отказ в доступе), или попытки исчерпаны, перемещайте задачу в DLQ вместо очередного повтора.\n- Триггерьте алерт с достаточным контекстом для отладки (тип задачи, id, попытка, класс ошибки, время первого появления). Избегайте в алартах полных payload‑ов — там часто секреты или персональные данные.\n- Отслеживайте несколько счётчиков, чтобы проблемы проявлялись рано.
try {
handle(job)
markDone(job)
} catch (err) {
attempts = job.attempts + 1
if (!isRetryable(err) || attempts >= MAX_ATTEMPTS) {
moveToDLQ(job, err)
alert(job, err)
} else {
reschedule(job, backoff(attempts))
}
}
Для дашбордов не нужно ничего причудливого. Отслеживайте текущие выполняющиеся задачи, задачи, запланированные на повтор, глубину DLQ и «DLQ добавлено в час».
Предотвращение дубликатов побочных эффектов при воспроизведении
Воспроизведение упавшей задачи — вот где прячется реальный риск. Оригинальная задача могла уже совершить опасную операцию (списать деньги, отправить письмо, создать запись), а затем упала при логировании или втором шаге. Если вы воспроизведёте из DLQ без защиты, можно списать деньги дважды, отправить два письма или создать дубли записей.
Проще всего оставаться в безопасности с идемпотентностью. Проще говоря: один и тот же запрос должен давать один и тот же результат, даже если вы выполните его дважды. Задача должна уметь сказать «я уже сделал это» и завершиться, не повторяя побочный эффект.
Практические способы:
- Идемпотентные ключи: генерируйте стабильный ключ на одно реальное действие (например,
invoice_123_charge) и храните результат. При воспроизведении сначала проверяйте этот ключ.\n- Уникальные ограничения: заставьте базу данных гарантировать «только одно» (одна выплата на заказ, одно приветственное письмо на пользователя) и трактуйте дубли как успех.\n- Паттерн outbox: один раз записывайте намерение в базу, затем отдельный отправщик доставляет его. Повторы просто перепроверяют и отправляют только то, что ещё в ожидании.
Хорошая модель: «записал один раз — отправил позже». Сначала зафиксируйте долговечный факт, например «оплата для заказа 8821 авторизована» в транзакции. Только после этого делайте внешний вызов (email provider, платежный шлюз). Если задача упала на полпути, воспроизведение увидит сохранённый факт и выполнит минимальное оставшееся.
Пример: задача отправляет чек после покупки. Если она отправила письмо и упала до установки receipt_sent=true, повтор отправит второе письмо. Исправьте это, сохранив receipt_sent_at с уникальным ключом вроде receipt:{order_id} до отправки, или положив письмо в таблицу outbox, а доставкой будет заниматься отдельный отправщик.
Постройте админский поток воспроизведения, безопасный по умолчанию
Если люди могут воспроизвести упавшие задачи в один клик, они это будут делать. Админский флоу должен предполагать ошибки, спешку и неполный контекст. Безопасность по умолчанию означает, что самое простое действие — и самое безопасное.
Начните с набора представлений, которые быстро отвечают на базовые вопросы:
- Список DLQ: фильтровать по типу задачи, классу ошибки, дате и окружению.\n- Просмотр детали: payload, идемпотентный ключ, заголовки/метаданные и точная ошибка.\n- Воспроизведение: опции «воспроизвести сейчас» vs «по расписанию», одиночное vs пакетное.\n- Отклонить/решить: место для пометки «не исправлять» с указанием причины.
В детальном представлении показывайте историю попыток: временные метки, версию воркера, счётчик повторов и любые записанные побочные эффекты (например, «создан счёт #1234»). На основе этого принимаются хорошие решения.
Контролы воспроизведения должны заставлять оператора явно указать намерение. Пакетное воспроизведение должно требовать предварительного просмотра фильтра («совпадает 32 задачи») и второе подтверждение с указанием типа и риска побочного эффекта («может отправить письма»). Режим dry run полезен: провалидировать текущие входные данные и зависимости без записи или внешних вызовов и показать, что бы произошло.
Предохранители предотвращают превращение одной плохой задачи в две плохие:
- Блокировать воспроизведение, если тот же идемпотентный ключ уже завершился успешно.\n- По умолчанию назначать отложенное выполнение для пакетных действий, а не немедленное.\n- Требовать явного выбора, если задача известна как неповторимая.\n- Ограничивать скорость воспроизведений по типу задачи, чтобы избежать всплесков.\n- Всегда писать запись аудита.
Права важны. Ограничьте воспроизведение небольшой ролью и логируйте, кто и когда воспроизвёл задачу, включая причину.
Частые ошибки и ловушки, которых следует избегать
Большинство DLQ‑настроек терпят неудачу по скучным причинам: правила неясны, повторы слишком агрессивны или воспроизведение воспринимается как безобидная кнопка.
Типичные ловушки (и как их избежать):
- Повторять всё вечно. Если каждая ошибка — «попробуй снова», вы никогда не узнаете, что сломалось. Задайте чёткие правила для DLQ (плохой ввод, отсутствующие записи, проблемы с правами, 4xx от сторонних сервисов) и быстро выводите такие задачи из горячего потока.\n- Нет лимита + нет бэкоффа = шторма повторов. Один outage может превратиться в лавину, замедляющую всю систему. Установите максимум попыток, используйте экспоненциальный бэкофф с джиттером и прекращайте повторы при явно неповторимых ошибках.\n- Кнопка «воспроизвести», которая может удвоить побочные эффекты. Воспроизведение задачи, которая уже списала деньги или отправила письмо, может нанести реальный вред. Сделайте обработчики идемпотентными (ключи, уникальные ограничения или маркер «уже обработано») и проектируйте воспроизведение так, чтобы оно было безопасно даже при повторном нажатии.\n- Логирование секретов внутри payload или ошибок. DLQ часто хранит оригинальное тело задачи. Если там токены, пароли или данные клиентов — вы получили тихую утечку. Редактируйте чувствительные поля перед enqueue и очищайте сообщения об ошибках перед сохранением.\n- Использование DLQ как долгосрочного хранилища. DLQ без владельца превращается в могильник. Назначьте владельца, политику хранения и план очистки. Отслеживайте метрики (размер DLQ, возраст старейшей записи, процент успешных воспроизведений), чтобы всё было под контролем.
Простое правило: DLQ должен быть кратковременным ящиком для расследований, а не свалкой. Если он растёт — это баг продукта или проблема опс, и кто‑то должен этим заняться.
Пример: упавшая задача отправки письма, которую нельзя отправлять дважды
Пользователь регистрируется, и приложение добавляет в очередь фоновую задачу «отправить приветственное письмо». Задача включает user_id, to_email, template_id и send_id (уникальный идемпотентный ключ для этого письма).
У одной регистрации адрес имеет неверный формат, например alex@@example.com. Воркер вызывает почтового провайдера, получает 400 «invalid recipient» и падает.
Политика повторов пытает ещё пару раз (например, 3 попытки в течение 10 минут) на случай временных проблем. Каждая попытка падает одинаково, поэтому задача переходит в DLQ с понятной, неповторяемой причиной: «Invalid email format: alex@@example.com». Эта короткая причина важна — админ понимает, что исправлять, не копаясь в стектрейсах.
Во время инцидента логи и метрики должны рассказывать историю:
- Попытки задачи: 3 (все упали с тем же 400)\n- Количество в DLQ: +1 (тег reason=invalid_recipient)\n- Отправки писем: 0 (нет сохранённого provider message id)\n- Время до DLQ: 10м (показывает ограничение повторов)
Админ открывает элемент DLQ, правит ввод (или исправляет запись пользователя) и нажимает воспроизвести. Поток воспроизведения должен быть безопасен по умолчанию: он добавляет задачу обратно с тем же send_id, и воркер сначала проверяет таблицу sent_emails. Если запись для send_id уже есть — задача завершается. Если нет — письмо отправляется, сохраняется provider message id и задача помечается выполненной.
Чтобы в будущем избежать такой ошибки, валидируйте заранее (отклоняйте плохие email до момента постановки в очередь) и держите идемпотентность для каждого побочного эффекта (письма, списания, вебхуки).
Короткий чеклист и следующие шаги
Dead-letter queue для фоновых задач полезна в продакшне только если мелочи настроены правильно. Именно эти детали не дают ошибкам превращаться в дубликаты, outage или молчаливые повреждения данных.
Чеклист для настройки повторов и захвата в DLQ:
- Ограничьте попытки и задайте бэкофф (например, 5 попыток с экспоненциальным бэкоффом и джиттером), плюс жёсткий таймаут на попытку.\n- Опишите явно, что повторяемо, а что нет (сетевая нестабильность, 429/503, временные блокировки БД) и по умолчанию делайте всё остальное неповторяемым.\n- Добавьте стоп‑условие для poison messages (повторы с той же сигнатурой ошибки, неверный payload, отсутствующие поля), чтобы они быстро шли в DLQ.\n- Сохраняйте минимум DLQ‑данных: тип задачи, аргументы (редактированные), счётчик попыток, последний класс ошибки и сообщение, стек, временные метки и версию воркера.\n- Редактируйте секреты и личные данные перед сохранением (токены, пароли, полные email, сырые тела запросов) и ведите аудит того, кто что менял.
Чеклист для безопасности воспроизведения:
- Выберите стратегию идемпотентности для каждого типа задачи (идемпотентный ключ, уникальное ограничение или маркер «уже обработано») и протестируйте воспроизведение той же задачи дважды.\n- Разделите повторы и воспроизведение: воспроизведение должно требовать решения человека и, по возможности, заметки с причиной.\n- Ограничьте доступ (только админы), добавьте явное подтверждение и превью того, что произойдёт (включая побочные эффекты вроде платежей или писем).\n- Решите, какие изменения допустимы перед воспроизведением (редактирование payload, смена назначения, переопределение конфигурации) и логируйте каждое изменение.\n- После воспроизведения записывайте результат (успешно, снова упало с новой ошибкой или отменено), чтобы DLQ не стал чёрной дырой.
Если вы работаете с кодовой базой, сгенерированной AI, где повторы, идемпотентность и безопасное воспроизведение изначально не были продуманы, FixMyMess (fixmymess.ai) может помочь диагностировать поведение очереди и воркеров, исправить логику и укрепить систему для продакшна.
Часто задаваемые вопросы
Что такое «poison message» в очереди фоновых задач?
Poison message — это задача, которая всегда падает при тех же входных данных, поэтому повторы не помогают. Решение: быстро прекратить автоматические повторы, переместить задачу в DLQ вместе с ошибкой и полезной нагрузкой, а затем исправить код или данные перед целевым воспроизведением.
В чём разница между очередью повторов и dead-letter queue (DLQ)?
Очередь повторов предназначена для сбоев, которые, скорее всего, временные и безопасно повторимы (тайм-ауты, кратковременные сбои). DLQ — это для задач, требующих решения или исправления перед повтором (неверный payload, отсутствующая запись, проблемы с правами), чтобы они не забивали воркеры.
Сколько попыток должна получать фоновая задача перед переходом в DLQ?
Практичный дефолт — небольшое число попыток с увеличивающимися задержками и жёсткая остановка по времени. Начните с 3–5 попыток с экспоненциальным бэкоффом, затем переместите задачу в DLQ, когда бюджет повторов исчерпан.
Как решить, какие ошибки повторяемы, а какие — нет?
Повторяйте только тогда, когда точно такой же payload может позже сработать без изменения кода или данных. Тайм-ауты, временные 5xx и кратковременные отказы БД обычно повторяемы; неверный ввод, отсутствующие поля и «не найдено» — обычно быстро в DLQ.
Что нужно сохранять, когда задача попадает в DLQ?
Запишите достаточно, чтобы воспроизвести и безопасно воспроизвести позже: тип задачи, payload (с редактированными чувствительными полями), счётчик попыток и тайминги, полные данные об ошибке. Также сохраняйте стабильный ID задачи и идемпотентный ключ, чтобы повтор не повторял побочные эффекты.
Как предотвратить двойные списания или дублирующие письма при воспроизведении задач из DLQ?
Идемпотентность — основная защита: задача должна уметь выполняться дважды и давать один и тот же результат без повторного побочного эффекта. Используйте стабильный идемпотентный ключ, уникальные ограничения или пометку «уже обработано», чтобы избежать двойных списаний или писем.
Как выглядит безопасный админский процесс воспроизведения?
Сделайте воспроизведение осознанным и добавьте защитные меры: покажите payload и ошибку, блокируйте воспроизведение, если идемпотентный ключ уже прошёл, и логируйте, кто и почему воспроизвёл задачу. При сомнении сначала воспроизведите одну задачу и проверьте состояние побочных эффектов, прежде чем запускать батч.
Почему бесконечные повторы так опасны в продакшне?
Бесконечные повторы могут загнать воркеры и превратить одну плохую задачу в outage. Они также увеличивают стоимость (вычисления, операции с очередью), засыпают логи и повышают риск повторных побочных эффектов при частичном успехе.
Как избежать утечки секретов или персональных данных через DLQ?
Санитизируйте payload и детали ошибки перед хранением или показом — в задачах часто есть токены, креденшелы и персональные данные. Храните только то, что действительно нужно для отладки, и не выводите сырые секреты в логи или алерты.
Может ли FixMyMess помочь, если моя система фоновых задач сгенерирована AI и постоянно падает?
Да — особенно если логика повтора, идемпотентность и безопасное воспроизведение изначально не были предусмотрены. FixMyMess может сделать аудит очереди и воркеров, выявить причины сбоев и дублирований, а затем исправить и упрочить код для продакшна, зачастую в течение 48–72 часов после бесплатного аудита кода.