Поэтапный план реконструкции: начните с критического пути
Узнайте поэтапный план реконструкции: начните с критического пути, подтвердите стабильность, затем добавляйте второстепенные функции, не нарушая работу в продакшне.
Что такое поэтапная перестройка и почему это важно
Поэтапный план перестройки — это когда вы обновляете приложение небольшими, заранее спланированными шагами, вместо попытки починить всё сразу. Сначала приводят в порядок то, что обязательно должно работать, а остальные вещи добавляют только после стабилизации ядра.
Выпуск всех функций одним гигантским релизом обычно проваливается по простой причине: невозможно понять, какое изменение породило проблему. Баги множатся, сроки сдвигаются, команда тратит время на тушение пожаров вместо движения вперёд.
Прототипы, сгенерированные ИИ, повышают ставки. Внешне они могут выглядеть завершёнными, но внутри — беспорядок: неочевидный поток данных, скопированная логика, отсутствие обработки ошибок и рискованные настройки по умолчанию, например открытые ключи или слабая аутентификация. Если навалить сверху новые фичи, придётся переделывать одни и те же части снова и снова.
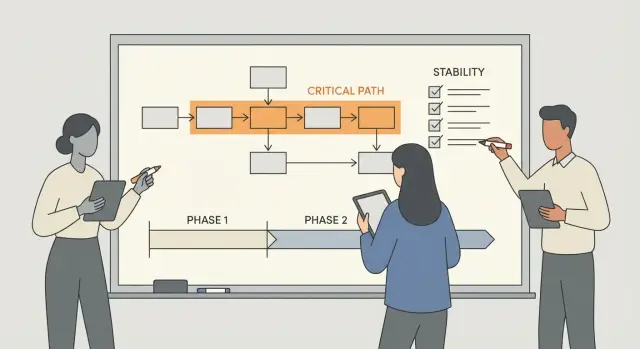
Ключевая идея — критический путь. Это минимальный набор шагов, которые реальный пользователь должен пройти, чтобы получить основную ценность вашего продукта, без обходных манёвров.
Простой способ найти его — описать приложение в одном предложении, затем выписать шаги, которые совершает новичок, чтобы получить этот результат. Для многих продуктов критический путь включает несколько предсказуемых частей: регистрация или вход, выполнение основного действия (создать бронь, загрузить файл, оформить заказ), момент получения ценности (оплата, отправка, подтверждение), затем просмотр результата и возврат позже без потери данных.
Всё остальное вторично, пока этот путь не станет надёжным. Если небольшое приложение позволяет пользователям записаться на приём, критический путь — доступ к аккаунту, доступные слоты, создание брони, подтверждение и сохранённая запись. Изящные фильтры, админ-панели и шаблоны писем могут подождать, пока поток бронирования не заработает стабильно.
Команды, ремонтирующие приложения, созданные ИИ, часто обнаруживают, что фокус на критическом пути сначала уменьшает переделки, упрощает тестирование и превращает сломанный прототип в то, чему можно доверять в продакшне.
Найдите критический путь прежде чем трогать код
Поэтапный план начинается с одного простого вопроса: какая одна пользовательская цель должна работать всегда?
Опишите цель с точки зрения пользователя. Примеры: «Зарегистрироваться и создать первый проект», «Записаться и оплатить приём», «Импортировать файл и получить отчёт». Выберите ту, что двигает бизнес. Всё остальное — опционально, пока этот путь не отлажен.
Далее спишите минимальные шаги от первого касания до успеха. Держите их скучными и прямыми. Вы ещё не проектируете идеальный опыт — вы определяете, что не должно ломаться. Обычно это: точка входа до первого действия, создание аккаунта или вход, основное действие, необратимый шаг (оплата или запись данных), затем подтверждение.
Потом перечислите зависимости под этими шагами. Здесь часто прячется реальный риск в ИИ-прототипах: аутентификация собрана на заглушках, платежи в «тестовом режиме», запись данных без валидации и письма, которые раскрывают секреты или вообще не уходят.
Наконец, договоритесь, что вне зоны Фазы 1, и запишите это. Для небольшого приложения это может означать социальный вход, админ-панель, аналитику, экспорт, роли команд и красивое онбординг-окно.
Конкретный пример: если основная ценность вашего приложения — «пользователи платят, затем генерируют документ», то критический путь — не «сделать панель красивой». Это оплата, генерация документа и сохранение результата. Когда они стабильны, функционал Фазы 2 имеет безопасную платформу для добавления.
Установите измеримую базу стабильности
Перед началом перестройки запишите, что значит «сломано» сейчас. Если пропустить этот шаг, Фаза 1 может показаться лучше, оставаясь по сути уязвимой в тех же местах.
Начните с перечня ошибок, которые вы уже видите в реальном использовании. Частые проблемы в ИИ-прототипах: логин, который случайно падает, краши на определённых входных данных, незавершённые платежи, данные, исчезающие после обновления, и страницы, которые грузятся так долго, что пользователи сдаются.
Дальше зафиксируйте боли пользователей простым языком. Ищите места, где люди отваливаются: экран, который они бросают, действие, которое повторяют, или шаг, где скапливаются запросы в поддержку. Быстрый подход — собрать 10–20 недавних сообщений или отчётов об ошибках и пометить каждое по месту возникновения (регистрация, оформление, загрузка, панель).
Теперь определите «стабильность» набором сигналов, которые можно проверять каждый день. Держите их в пределах 3–5 показателей и делайте измеримыми. Например: процент успешных входов, количество сессий без краха, целостность данных для ключевых действий, производительность критических экранов и нагрузка поддержки, связанная с основными ошибками.
Выберите короткое окно для измерения базы — обычно 3–7 дней. Достаточно, чтобы не попасть на «хороший день», но недолго, чтобы не тормозить работу.
Объём Фазы 1: сделать ядро безопасным и надёжным
Фаза 1 не про красоту приложения. Она про надёжность ядра. Если план начинается с полировки второстепенных экранов, вы рискуете получить красивый, но по-прежнему ломающийся продукт при реальных входах, оплатах или сохранениях.
Хорошее правило — выбрать минимальный набор функций, необходимый бизнесу, и сделать этот путь безопасным. Всё остальное ждёт.
Что должно быть в Фазе 1
Начните с базовой безопасности, которая потом тихо может сломать всё. Уберите открытые секреты, ужесточите аутентификацию и валидируйте каждый ввод перед записью в базу или вызовом API. Многие ИИ-прототипы сливают ключи, пропускают проверки или принимают небезопасный ввод.
Далее стабилизируйте модель данных и рабочие процессы, которые чаще всего её задействуют. Если приложение не может надёжно создавать, читать, обновлять и удалять ключевые записи, то добавление функций только увеличит путаницу. Держите правила простыми и последовательными, чтобы одно и то же действие всегда давало одинаковый результат.
Сделайте проблемы видимыми. Добавьте понятное логирование для критического пути и собирайте ошибки с достаточной детализацией для воспроизведения. Без этого вы будете гадать, что именно сломалось.
Наконец, сделайте деплой скучным. Хотите один понятный способ выкатывать, с теми же шагами каждый раз, чтобы исправления не терялись между машинами и средами.
Быстрый чеклист для Фазы 1
«Безопасно и надёжно» обычно означает:
- Секреты удалены из кода и при необходимости повёрнуты
- Аутентификация корректна для основных ролей, сессии ведут себя предсказуемо
- Критические вводимые данные валидируются, основные векторы инъекций закрыты
- Основные рабочие процессы проходят повторяемые тесты и легко наблюдаемы в логах
- Деплои повторяемы и дают одинаковый результат
Пошагово: перестраиваем критический путь
Перестройте основной пользовательский поток как единый простой путь от начала до конца. Это не даст поэтапному плану раствориться в приятных, но ненужных штуках.
1) Воссоздайте поток сквозь всю систему (самая простая версия)
Выберите один успешный исход и сделайте только то, что для него нужно. Если экран, настройка или интеграция не требуются для этого результата — оставьте их на потом.
Опишите поток в 5–8 шагов простым языком (что делает пользователь, что система сохраняет, что он видит дальше). Реализуйте минимально рабочую версию с базовым UI, простым API и минимальными действиями с базой. Заглушите некритичные интеграции (платёж в песочнице, тестовое письмо или логирование события) и сделайте сбои очевидными — понятные ошибки и состояния загрузки. Затем прогоните поток вручную несколько раз с реальными похожими данными, чтобы поймать очевидные поломки.
2) Добавляйте тесты только там, где поломка действительно больно бьёт
Полного покрытия пока не нужно. Добавьте небольшой набор тестов, которые защитят основной путь от регрессий: тест входа, тест завершения основного действия и тест подтверждения сохранения данных. Даже такие базовые проверки уберегут от «вчера работало» после быстрого фиксa.
3) Исправляйте по классам ошибок
Баги идут пачками. Группируйте проблемы по типу и решайте их пачками, чтобы не метаться. Частые группы: аутентификация (сессии, редиректы), целостность данных (ограничения, миграции) и платежи (вебхуки, идемпотентность). Делайте каждое изменение небольшим и ревьюемым, выкатывайте исправления часто.
Пример: реалистичная поэтапная перестройка для маленького приложения
Представьте крошечный SaaS, который помогает менеджеру по маркетингу загрузить CSV, пометить лиды и сгенерировать простой отчёт (топ сегментов и счётчики). Текущий ИИ-прототип внешне нормален, но регистрации падают случайно, права доступа непоследовательны, а данные иногда исчезают после обновления.
Вот план поэтапной перестройки, который даёт бизнесу возможность работать, пока вы сокращаете риски.
Фаза 1: сделайте ядро безопасным и скучным (в хорошем смысле)
Начните от регистрации до первого отчёта, всё остальное — опционально.
- Доверяемая регистрация и вход (последовательные сессии, сброс пароля работает, секреты не в коде)
- Права доступа соответствуют реальности (пользователи не видят чужие данные, демонстрационные данные отделены)
- Надёжное сохранение и загрузка данных (загрузка, теги и входные параметры отчёта сохраняются всегда)
- Базовый UI (простые стабильные экраны без полуработающих кнопок)
Хороший тест: могут ли пять разных человек от «создать аккаунт» до «первого отчёта» пройти без помощи, два раза подряд?
Фаза 2: функции, которые помогают командам работать ежедневно
Стройте на стабильной основе: приглашения в команду, экспорт и одна–две интеграции (например, отправка помеченных лидов в CRM). Каждое добавление должно обходиться без переписывания основного потока.
Фаза 3: полировка и функции для продвинутых пользователей
Когда приложение устойчиво в реальной эксплуатации, добавляйте аналитические панели, больше ролей, расширенные настройки и другие приятные вещи.
Частые ловушки, замедляющие поэтапную перестройку
Поэтапная перестройка работает, когда у каждой фазы есть чёткая точка завершения. Большинство задержек возникает, когда команда занята, но не добивается, чтобы приложение надёжно выполняло одну задачу сквозь.
Одна распространённая ошибка — привести всё в порядок прежде, чем приложение запустится. Рефакторы полезны, но если вход, оплата или сохранение всё ещё ломаются, у вас нет надёжной базы для следующего шага. Аккуратный код — это бонус, а не первая цель.
Другой капкан — перестроить UI, пока основная логика ещё сломана. Красивый экран может скрыть то, что система под ним не работает. Если пользователи не могут завершить основной поток без ошибок, визуальная полировка лишь увеличит объём переработок.
Прогресс также срывается из-за добавления фич ради видимости движения. Новый фильтр, панель или интеграция красиво смотрятся на демо, но они добавляют состояния и крайние случаи, усложняя подтверждение стабильности.
Самая дорогостоящая ловушка — оставить ту же запутанную архитектуру и надеяться, что она масштабируется. Если ИИ-сгенерированный код смешивает UI, бизнес-логику и обращения к базе в одном месте, каждое изменение ломает что-то ещё. Небольшая целенаправленная реструктуризация рано может сэкономить недели позже.
Следите за признаками:
- ПРы затрагивают несвязанные файлы «раз уж мы здесь»
- Баги возвращаются после пометки как исправленные
- Вы не можете объяснить главный поток в 5 шагах
- Тестирование пропускают потому что «оно занимает слишком много времени»
Быстрые проверки перед добавлением второстепенных функций
Второстепенные функции кажутся безопасными, потому что это «просто UI» или «приятно иметь». Но если добавлять их до полной стабилизации ядра, они часто открывают те же баги, которые вы только что зафиксировали. Рассматривайте окончание Фазы 1 как ворота, которые нужно пройти.
Чеклист выхода из Фазы 1
Прогоняйте эти проверки только по критическому пути (регистрация, вход, оплата, основной рабочий процесс — то, без чего приложение не может жить):
- Производительность: измерьте загрузку страниц и самые медленные шаги в основном потоке. Ищите повторяющиеся запросы, большие полезные нагрузки или эндпоинты, делающие лишнюю работу «про запас».
- Безопасность: убедитесь, что секретов нет в репозитории или фронтенде. Проверьте контроль доступа несколькими реальными тестами. Повторно проверьте распространённые векторы инъекций и небезопасные загрузки.
- Надёжность: добавьте таймауты на внешние вызовы, настройте разумные повторные попытки (не бесконечные) и сделайте ошибки грациозными (понятные сообщения, никаких пустых экранов).
- Готовность к релизу: убедитесь, что можно деплоить безопасно, мониторить ключевые ошибки и откатывать релиз.
- Ворота принятия решения: запишите критерии прохода (например, «вход срабатывает 100 раз подряд» и «нет уязвимостей высокого уровня»). Если вы не можете выразить это в одном предложении, вы ещё не готовы.
Если ваше ИИ-приложение выбрасывает пользователей из сессии случайно, не добавляйте новый виджет на панель. Сначала докажите, что сессии стабильны при реальной нагрузке, потом двигайтесь дальше.
Как не допустить, чтобы Фаза 2 нарушила Фазу 1
Фаза 1 — это место, где вы заслуживаете доверие: приложение работает, основной поток отлажен, страшные баги исчезли. Фаза 2 — место, где команды часто подрывают этот прогресс, добавляя «ещё одну фичу», которая незаметно вторгается в ядро.
Практическая защита — чёткая граница между основным доменом (критическим путём) и опциональными функциями. Относитесь к ядру как к маленькому продукту внутри продукта. Фичи могут вызывать его, но не должны переписывать.
Проведите жёсткую границу вокруг ядра
Сделайте в кодовой базе очевидным, что является ядром, а что опцией. Если новая функция нуждается в чем-то из ядра, добавьте это через маленький интерфейс, а не лезьте во внутренности.
Например, если критический путь — регистрация → вход → оплата, функция промокодов не должна разбросанно менять правила кассы. Она должна отправлять запрос промокода в интерфейс кассы, который валидирует ввод и применяет скидку в одном контролируемом месте.
Быстрая проверка границ:
- У ядра есть свой модуль или папка с тестами
- Код фичи не импортирует внутренности ядра напрямую
- Общий код остаётся небольшим (валидация, типы, утилиты)
- Изменения данных проходят через один сервис ядра, а не через разбросанные запросы
Делайте решения видимыми и стандарты строгими
Кратко фиксируйте принятые решения: что поменяли, почему и чего не стоит делать. Короткая заметка экономит часы, особенно когда неясны намерения.
Установите правила для новой работы, чтобы беспорядок не вернулся:
- Нет слияний фич без прохождения тестов Фазы 1
- Новые поля в базе идут с планом отката
- Секреты никогда не в репозитории, даже «временно»
- Любое изменение ядра требует второго взгляда
- Если фича требует 3+ правок ядра — остановитесь и пересмотрите интерфейс
Планируйте второстепенные функции после подтверждения стабильности
Поэтапный план работает, только если Фаза 1 остаётся защищённой. Прежде чем добавить что-то новое, убедитесь, что основной поток скучный в лучшем смысле: всё происходит одинаково, ошибки предсказуемы, а исправления не создают новых сюрпризов.
При решении, что отложить на Фазу 2 и далее, отделяйте «приятно иметь» от «нужно, чтобы светло было». Если фича не нужна для критического пути, она должна конкурировать за место в Фазе 2.
Простой способ ранжировать фичи — оценить каждую по ценности для пользователя и риску для стабильности. Учитывайте, сколько пользователей сейчас её ждут, касается ли она аутентификации/платежей/прав доступа/модели данных, насколько большой объём изменений, сколько неизвестного осталось и какую нагрузку поддержки она создаст.
Выпускайте второстепенные функции маленькими партиями и слушайте обратную связь. Одна плотная итерация с фидбеком лучше пяти бесполезных фич.
После каждой партии оставляйте время на упрочение, чтобы Фаза 1 не сломалась: короткая регрессия по критическому пути, исправление производительности и обработки ошибок перед следующей пачкой, удаление временных флагов, проверка безопасности и обновление мониторинга, чтобы проблемы появлялись быстро.
Следующие шаги: получите чёткий поэтапный план для вашего ИИ-приложения
Если ваше приложение было сгенерировано инструментами вроде Lovable, Bolt, v0, Cursor или Replit, самый быстрый путь — поэтапная перестройка, которая сначала защищает основной пользовательский путь и избегает наслоения функций на шаткую основу.
Прежде чем просить о помощи, соберите небольшой стартовый набор, чтобы человек быстро разобрался, что реально: доступ к репозиторию (или заархивированная копия) и детали окружения, шаги критического пути, недавние логи или скриншоты ошибок, любые ключи, которые могли быть раскрыты, и целевой критерий успеха Фазы 1.
Иногда достаточно фокусированного ремонта. В других случаях перестройка быстрее, чем заплатки. Ремонт выигрывает, когда структура ядра в целом здорова и баги локальны. Перестройка выигрывает, когда видны повторяющиеся проблемы: запутанные модули, непоследовательные модели данных или всплывающие проблемы безопасности.
Если вы унаследовали ИИ-сгенерированный код, который не выдерживает продакшн, FixMyMess (fixmymess.ai) может начать с бесплатного аудита кода, чтобы определить, что ломает критический путь, а затем сосредоточиться на логике, усилении безопасности, рефакторинге самых больных мест и подготовке к деплою. Это даёт конкретный объём Фазы 1, которому можно доверять, прежде чем инвестировать в Фазу 2.
Часто задаваемые вопросы
Что именно такое поэтапная перестройка?
Поэтапная перестройка — это разбить реконструкцию приложения на небольшие, запланированные куски, начиная с одного пользовательского пути, который должен срабатывать каждый раз. Это позволяет избежать хаоса, когда всё меняется одновременно: вы можете выпускать исправления, видеть реальные улучшения и держать продукт работоспособным в процессе стабилизации.
Что вы имеете в виду под «критическим путём»?
Критический путь — это набор минимальных шагов, которые реальный пользователь должен пройти, чтобы получить основную ценность продукта без обходных путей. Если этот путь стабилен, второстепенные функции можно добавлять безопасно, не ломая приложение постоянно.
Как быстро найти критический путь моего приложения?
Опишите ценность приложения в одном предложении, затем перечислите, что делает первый пользователь, чтобы получить этот результат. Оставьте только минимальные шаги от входа до успеха, включите необратимый момент (оплата или запись в базу) и подтверждение, что всё прошло успешно.
Почему прототипы, сгенерированные ИИ, часто ломаются при попытке выпускать их в продакшн?
Прототипы, сгенерированные ИИ, часто выглядят готовыми, но внутри хрупкие: скопированная логика, пропущенная валидация и неочевидный поток данных. Когда вы добавляете функции поверх такой основы, приходится переделывать одни и те же части снова и снова, потому что ядро ненадёжно.
Как задать базу стабильности перед перестройкой?
Опишите «сломано» простыми словами на основе реального опыта пользователей, затем измерьте это в коротком окне (3–7 дней). Выберите несколько сигналов, которые можно проверять ежедневно: успех входа, сохранение ключевых записей, отсутствие падений и т. п. Это даст базовую линию до начала работ.
Что должно быть в объёме Фазы 1 (а что должно подождать)?
Фаза 1 должна включать только то, что делает основной путь безопасным и надёжным: удаление секретов из кода, корректная аутентификация, права доступа, валидация вводимых данных, последовательные сохранения и достаточное логирование, чтобы видеть ошибки. Всё, что не помогает пройти основной путь от начала до конца, обычно ждёт следующей фазы.
Как безопасно перестроить критический путь, не отвлекаясь?
Реализуйте самую простую сквозную версию критического потока — даже с базовым UI. Добавьте небольшой набор тестов, защищающих этот путь, и исправляйте ошибки партиями по типу (аутентификация, целостность данных, платежи), чтобы не метаться между несвязанными багами.
Как не дать Фазе 2 сломать Фазу 1?
Трактуйте Фазу 1 как защищённое ядро и добавляйте новые функции через узкий интерфейс, а не редактируя логику ядра везде. Требуйте прохода фазовых тестов для слияний и прогоняйте короткую регрессию по критическому пути после каждой пачки фич.
Какие самые распространённые ошибки замедляют поэтапную перестройку?
Частые ошибки — делать чистые рефакторы и UI-полировку до тех пор, пока пользователи не могут нормально войти, оплатить или сохранить данные. Другой типичный порок — «ещё одна фича», чтобы показать прогресс: она добавляет состояния и пограничные случаи, прежде чем вы убедились в стабильности ядра.
Я получил в наследство приложение, сгенерированное ИИ, которое не держится в продакшне — что делать в первую очередь?
Если вы не технически подкованы, начните с описания шагов критического пути, сбора нескольких примеров недавних сбоев (скриншоты или логи) и списка возможных раскрытых ключей. FixMyMess может сделать бесплатный аудит кода AI-сгенерированного приложения, определить, что ломает критический путь, а затем выполнить целевые исправления и подготовку к деплою за 48–72 часа или посоветовать, когда проще перестроить, чем латать.