Предохранители (circuit breakers) для ненадёжных провайдеров, чтобы предотвратить каскадные отказы
Узнайте, как предохранители (circuit breakers) для ненадёжных провайдеров предотвращают каскадные отказы с помощью таймаутов, повторов, фолбэков и безопасного восстановления, когда зависимости стабилизируются.
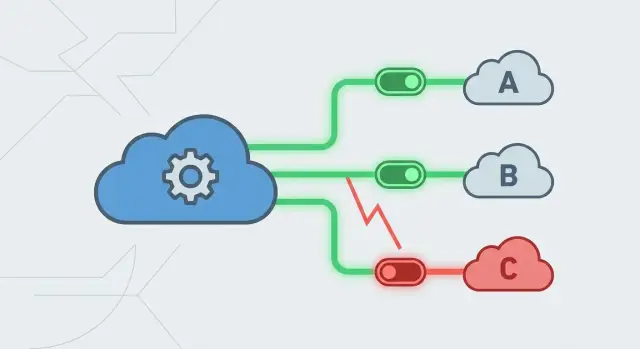
Почему ненадёжный провайдер может свалить в загрузку хорошее приложение
Приложение может быть написано по-человечески, но всё равно упасть, если одна из внешних зависимостей начнёт капризничать. Платёжный шлюз замедляется, почтовый сервис отвечает ошибками, или прокси базы данных начинает подвисать. Если приложение продолжает вызывать эту зависимость, будто ничего не произошло, небольшая проблема быстро разрастается.
Это и есть каскадный отказ: одна медленная или падающая зависимость заставляет запросы ждать, ожидания накапливаются, и вскоре здоровые части приложения не справляются. Потоки застревают, пулы подключений заполняются, очереди растут, и всё кажется «падением», хотя большая часть кода в порядке.
Часто это начинается с обычных причин:
- Таймауты слишком длинные, и каждый запрос ждёт намного дольше, чем готовы терпеть пользователи.
- Лимиты скорости, за которыми следуют повторы, что ещё сильнее давит на троттлинг.
- Частичные отказы: часть вызовов проходит, часть зависает — это труднее заметить.
- «Медленный успех», когда ответы в конце концов приходят, но в 10× дольше и засоряют ресурсы.
Повторы без ограничений делают всё хуже. Если каждое действие пользователя запускает три повтора, а у вас сотни пользователей, бьющих по одному и тому же провайдеру, вы сами создадите всплеск трафика. Вот почему важны предохранители (circuit breakers): они не дают приложению снова и снова дотрагиваться до раскалённой сковороды.
С точки зрения пользователя всё просто и болезненно: кнопки крутятся вечно, страницы обновляются с ошибкой, люди кликают повторно, потому что ничего не происходит. Это ведёт к дублирующим действиям (двойные заказы, двойные списания, несколько заявок). Ещё хуже — пользователь не понимает, сохранились ли данные и прошёл ли платёж.
Этот режим отказа часто встречается в унаследованных AI‑сгенерированных приложениях: отсутствующие таймауты, агрессивные повторы и обработка только «счастливого пути» превращают сбой провайдера в полный аврал. Исправление начинается с того, чтобы считать падение зависимости нормой, а не исключением.
Circuit breaker за минуту: что он делает и зачем
Circuit breaker — это страховка вокруг внешнего вызова. Когда зависимость начинает давать сбои, вы временно прекращаете к ней обращения. Это предотвращает увеличение количества ошибок и блокировку потоков. Вместо того чтобы каждый запрос висел, вы быстро возвращаете отказ и переключаетесь на фолбэк.
Обычно предохранитель проходит три состояния:
- Закрыто: вызовы выполняются как обычно, вы считаете результаты.
- Открыто: провайдер выглядит нездоровым, вызовы блокируются сразу и вы возвращаете контролируемый ответ.
- Полуоткрыто: после окна остывания вы пропускаете небольшое число тестовых вызовов, чтобы проверить восстановление.
Это не просто «добавьте таймауты и повторы». Таймаут ограничивает, как долго вы ждёте, но при медленном провайдере всё равно может накопиться много ожиданий. Повторы умножают трафик в самый неподходящий момент. Предохранитель добавляет правило более высокого уровня: вы увидели достаточно ошибок — перестаём пытаться на время.
Правильно настроенный результат преднамеренно скучен:
- Пользователь получает быстрый ответ, пусть и деградированный (кэшированные данные, отложенная обработка или ясное «повторите позже»).
- Серверы остаются отзывчивыми, потому что они не застревают, ожидая падшего провайдера.
- Инциденты ограничиваются: одна шаткая зависимость не запускает цепную реакцию.
Пример: если в потоке регистрации отправка письма подтягивает почтовый API, который начинает тайм-аутиться, предохранитель может остановить попытки отправки на несколько минут и поставить письма в очередь. Пользователь всё ещё сможет создать учётную запись, а не смотреть на крутящийся спиннер.
AI‑сгенерированные кодовые базы часто упускают этот паттерн или реализуют его неправильно. FixMyMess часто видит длинные таймауты вместе с агрессивными повторами, что превращает провайдерский глич в полный отказ. Circuit breaker — один из самых быстрых способов сделать падения зависимостей предсказуемыми.
Куда ставить предохранители в первую очередь (наибольший эффект)
Начните там, где одна зависимость может задержать всё приложение. Лучшие цели — не «редкие фичи», а вызовы на экранах с высоким трафиком и в критичных потоках.
Проще приоритизировать по двум измерениям:
- Риск: провайдер часто падает, замедляется или троттлится.
- Радиус разрушения: один медленный вызов блокирует много запросов, занимает воркеры или ломает ключевой пользовательский сценарий.
Выбирайте зависимости, которые громко падают (и часто)
Первую защиту стоит ставить на внешние сторонние сервисы в критическом пути: платежи, почта/SMS, провайдеры аутентификации и LLM API. Они вне вашего контроля и могут деградировать без предупреждения.
Если есть возможность защитить только одну вещь — выберите ту, что может отнять деньги или доступ. Зависание корзины хуже задержки чекаута. Таймаут входа хуже потерянной аналитики.
Сосредоточьтесь на эндпойнтах, связанными с критичными действиями
Предохранители особенно важны на эндпойнтах, где пользователь пытается что‑то завершить: вход, регистрация, онбординг, чек-аут, сброс пароля и любые «submit»‑действия, которые должны быстро вернуть ответ.
Чтобы выбрать первые места для добавления breaker, сделайте следующее:
- Выделите ключевые эндпойнты по трафику и бизнес‑влиянию.
- Смэпьте внешние вызовы, которые делает каждый эндпойнт.
- Отметьте синхронные вызовы в пути request/response.
- Решите, что считать «ошибкой» (таймауты, 5xx, но также некорректные или неполные payload‑ы).
- Убедитесь, что понимаете текущее поведение при медленной зависимости (спиннеры, накопление очередей, истощение потоков).
Команды часто удивляются, что считать ошибкой. Провайдер может вернуть HTTP 200 с поломанный payload, без нужных полей или с токеном, который нельзя использовать. Относите такое поведение к ошибкам, иначе предохранитель не откроется вовремя.
Пример: если онбординг вызывает LLM, чтобы сгенерировать приветственное сообщение, и вызов занимает 20 секунд, пользователи подумают, что регистрация сломана. Закройте предохранитель вокруг этого вызова, установите понятный таймаут и верните простой дефолтный текст.
Унаследованный AI‑код усложняет задачу: вызовы к провайдерам часто перемешаны по обработчикам и маршрутам. Практический первый шаг — изолировать каждый провайдер за чистым интерфейсом, чтобы добавить таймауты, предохранители и фолбэки без переписывания всего приложения.
Важные настройки: таймауты, пороги и окна восстановления
Circuit breaker хорош ровно настолько, насколько корректно настроены его параметры. Слишком мягко — пользователи всё равно почувствуют перебой. Слишком жёстко — вы заблокируете рабочий трафик.
Таймауты: сколько вы готовы ждать
Выбирайте таймауты по контексту пользователя. Для кнопки «Сохранить» ждать 10 секунд кажется сломанным. Для фоновой синхронизации можно допустить больше.
Полезное правило: таймаут должен быть короче того времени, в течение которого приложение может позволить себе быть заблокированным. Если он слишком большой, запросы накапливаются, воркеры захламляются, и небольшая просадка провайдера превращается в аварию.
Повторы помогают только тогда, когда сбои кратковременны и провайдер не перегружен. Повтор после таймаута часто ухудшает ситуацию, потому что удваивает трафик именно тогда, когда зависимость в беде.
Пороги и восстановление: когда открывать, когда тестировать
Вам нужны три числа: когда открывать, сколько ждать и как тестировать восстановление.
Практическая стартовая конфигурация:
- Открывать после явного всплеска, например 5 ошибок из последних 20 вызовов.
- Ждать 30–60 секунд перед попыткой теста.
- В полуоткрытом состоянии пропускать 1–3 пробных вызова, а не лавину.
- Ограничить повторы 0–1 и только для безопасных идемпотентных запросов.
- Таймауты по эндпойнту часто в районе 1–3 секунд для пользовательских действий.
Пробные вызовы в полуоткрытом — это «носок в воду». После окна восстановления вы даёте нескольким контролируемым запросам пройти. Если они стабильно успешны — замыкаете цепь. Если плавают — снова открываете.
Пример: если почтовый провайдер отсылает коды входа и начинает тайм‑аутиться, используйте короткий таймаут, чтобы UI не висел, открывайте предохранитель после нескольких ошибок и проверяйте раз в минуту. Пользователи увидят понятный шаг, а не бесконечные спиннеры.
Если вы унаследовали AI‑сгенерированный код с «повторять вечно» циклами, исправление этих настроек часто даёт наибольший эффект.
Пошагово: как внедрить circuit breaker без излишнего оверхенда
Самый быстрый путь получить выгоду — централизовать логику. Не разбросывайте проверки по всему коду. Поместите поведение в одном месте, чтобы можно было потом настраивать, не ища по множеству файлов.
Простой поток, который работает в большинстве приложений
Создайте одну «клиент‑обёртку» для каждого внешнего провайдера (платежи, почта, модель AI, auth, доставка). Все вызовы идут через неё. Эта обёртка управляет таймаутами, повторами, состоянием предохранителя и логированием.
Простая реализация обычно выглядит так:
- Централизуйте вызовы в одном модуле с единым интерфейсом.
- Нормализуйте ошибки в небольшой набор, который понимает ваше приложение (таймаут, недоступен, неверный запрос).
- Отслеживайте недавние результаты в скользящем окне и открывайте цепь, когда ошибки превышают порог.
- Если цепь открыта — быстро возвращайте контролируемый фолбэк.
- После окна остывания проводите аккуратные пробы и закрывайте только после реального успеха.
Что означает «безопасный фолбэк» на практике
Фолбэк не должен притворяться, что всё прошло успешно. Он должен позволить пользователю двигаться дальше, не усугубляя ситуацию.
Если почта не работает — примите форму, покажите подтверждение и поставьте письмо в очередь на отправку. Если API цен упал — покажите кэшированные цены с пометкой «на момент» и честной пометкой о возможной устарелости. Если вызов связан с деньгами или безопасностью — явно укажите на неопределённость.
Храните решения по фолбэкам рядом с обёрткой. Остальной код приложения должен вызывать sendEmail() или chargeCard() и получать однозначный результат.
Распространённая ошибка в унаследованных прототипах — вызов стороннего API из множества маршрутов с разными стратегиями повторов. В тестах всё ок, а в проде — таймауты и повторы запускаются везде и приводят к таймингу и лавине ретраев. Обёртка с реальным таймаутом, быстрым отказом и окном остывания прекращает накопление и защищает базу и очереди.
Проектирование фолбэков, с которыми пользователи могут жить
Circuit breaker останавливает кровотечение. Фолбэки позволяют пользователям работать дальше. Хороший фолбэк честен, безопасен и легко объясним.
Начните с цели пользователя для каждого вызова. Если цель — «увидеть баланс», фолбэк может показать «последний известный баланс с отметкой времени». Если цель — «завершить покупку», фолбэк может «сохранить запрос на заказ и подтвердить позже», а не «притвориться, что оплата прошла». Правило: не врать. Люди прощают «подтвердим чуть позже» гораздо охотнее, чем двойные списания.
Выбирайте, показывать сообщение или делать бесшумную деградацию, исходя из влияния. Если пользователь может принять неправильное решение (деньги, безопасность, дедлайны) — показывайте ясное сообщение и дальнейшие шаги. Если это косметика — тихая деградация допустима.
Сделайте всё наблюдаемым (чтобы быстро чинить)
Фолбэки без логов превращают инциденты в догадки. Логируйте достаточно контекста, чтобы понять, что произошло:
- Что пытался сделать пользователь (и какие ключевые входные данные можно безопасно сохранить)
- Статус провайдера (таймаут, 500, троттлинг, circuit open)
- Correlation ID сквозь запрос, вызов провайдера и путь фолбэка
- Итог (в очереди, кэшировано, создана ручная проверка)
- Сообщение, показанное пользователю
В AI‑сгенерированных приложениях фолбэки бывают, но непонятно, какой путь сработал. Исправление простое: делайте каждый фолбэк явным, трассируемым и честным.
Реалистичный сценарий: падает платёжный провайдер в середине дня
12:10 во вторник. Чекаут был здоров, но он зависит от стороннего платёжного API. Провайдер начинает тайм‑аутиться. Не жестко падать, а виснуть по 10–20 секунд.
Без защиты проблема распространяется. Каждый запрос чекаута ждёт, затем повторяется. Застрявшие запросы накапливаются, занимая воркеры и соединения с базой. Клиенты обновляют страницу и снова нажимают «Оплатить». Часть запросов проходит, часть — нет, в итоге медленные страницы, дубли попыток и поддержка, заваленная вопросами «Меня списали?».
С circuit breaker история меняется быстро. После серии таймаутов breaker открывается для платежного клиента. Чекаут перестаёт ждать 20 секунд, получает быстрый отказ и показывает понятное сообщение вроде: «Платежи временно недоступны. Ваш заказ сохранён. Попробуйте через несколько минут.»
Вместо того чтобы швырять ещё попытки на платёжный API, приложение фиксирует намерение (корзина, сумма, пользователь, ID отложенного заказа). По возможности ставит попытку платежа в очередь или предлагает альтернативу. Главное — пользователь получает быстрый и честный ответ, а система остаётся отзывчивой.
Когда предохранитель открылся, вы также получаете более чистые сигналы: «зависимость payments — вниз», вместо расплывчатой медлительности по всей системе. Восстановление не требует героизма: после окна сброса цепь переходит в полуоткрытое, делает несколько пробных вызовов и закрывается, если провайдер снова здоров.
Частые ошибки, усугубляющие простои
Отказы обычно ухудшаются, потому что приложение продолжает давить, ждать и блокировать, пока всё не забьётся. Circuit breakers помогают, но важно избегать нескольких ловушек.
Бесконечные немедленные повторы — классический усилитель. Если провайдер глючит, и тысячи клиентов одновременно ретраят, вы сами создаёте всплеск и дольше держите провайдера в беде.
Отсутствие таймаутов — ещё одна проблема. Без таймаута запросы висят, очереди растут, серверы замедляются, и вскоре даже здоровые части приложения выглядят упавшими.
Обратите внимание на область действия предохранителя. Один глобальный breaker для многих функций — опасная штука. Авария платёжного провайдера не должна блокировать вход или чтение собственных данных.
Пять быстрых тревожных сигналов:
- Повторы, которые срабатывают мгновенно и бесконечно (без бэкоффа и без ограничения)
- Таймауты отсутствуют или настолько длинные, что запросы накапливаются
- Один предохранитель общ для многих зависимостей или эндпойнтов
- Фолбэк сообщает «успех», когда действие не произошло
- Цепь открывается и никогда не пробует восстановиться
Фолбэки, которые не врут
Самый опасный фолбэк — тот, что скрывает отказ. Если пользователь нажал «Оплатить», провайдер упал, а приложение показало «Платёж выполнен», вы получите споры и недовольство.
Безопаснее честно сказать: «Не удалось обработать платёж. Ваш заказ сохранён. Попробуйте через несколько минут.» По возможности держите пользователя в потоке: сохраните прогресс, предложите доступ только для чтения или альтернативный путь.
Быстрая проверка, которую можно сделать уже сегодня
Несколько простых шагов могут предотвратить сценарий «один провайдер хрупок — всё тает». Начните с трёх ключевых внешних зависимостей (платежи, auth, почта/хранилище) и проверьте код, который их вызывает:
- Каждый исходящий вызов имеет реальный таймаут, который вы установили осознанно.
- Повторы ограничены и осмысленны. Не повторяйте ничего, что может создать дубли записей или списаний, если нет идемпотентности.
- У каждой критичной зависимости есть «план Б», который пользователь поймёт.
- Изменения состояния предохранителя видны в логах (а лучше — и на дашборде).
- Восстановление происходит автоматически через безопасные полуоткрытые пробы.
Чтобы быстро протестировать, симулируйте падение провайдера в безопасной среде на пять минут. Заставьте вызов падать (блокированный сетевой трафик, принудительный 500), убедитесь, что пользователи получают предсказуемый результат (сообщение, кэш или отложенная работа), проверьте, что breaker открылся, затем восстановите провайдера и убедитесь, что он вернулся без ручного вмешательства.
Следующие шаги: сделать падения зависимостей скучными, а не катастрофическими
Запишите ваши топ‑зависимости и точные пользовательские потоки, которые они затрагивают: «Чекаут», «Вход», «Сброс пароля», «Отправка приглашения». Решите, что значит «достаточно хорошо», если каждая из них упадёт. Иногда правильный ответ — быстро отказать с понятным сообщением и безопасным повтором позже.
После этого добавьте одну обёртку‑слой на каждый провайдер, чтобы таймауты, повторы, паттерн circuit breaker и логирование жили в одном месте. Если вы сделаете только одно на этой неделе — выберите зависимость, связанную с доходом или доступом.
Если вы унаследовали AI‑сгенерированное приложение, которое разваливается под реальной нагрузкой, FixMyMess (fixmymess.ai) может провести бесплатный аудит кода и указать отсутствующие таймауты, рискованные циклы повтора и слабую обработку ошибок зависимостей. Часто можно быстро стабилизировать худшие интеграции, добавив чистые обёртки, здравые значения по умолчанию и честные фолбэки.
Часто задаваемые вопросы
Что такое каскадный отказ, простыми словами?
Каскадный отказ происходит, когда одна медленная или падающая зависимость заставляет приложение ждать, а эти накопившиеся ожидания съедают потоки, соединения или очередь. Решение — перестать ждать бесконечно и прекратить постоянные обращения к падающему сервису, чтобы остальная часть приложения оставалась отзывчивой.
Чем circuit breaker отличается от простых таймаутов и повторов?
Circuit breaker — это правило вокруг внешнего вызова, которое перестаёт пропускать запросы к зависимости, когда она явно нездорова. Вместо того чтобы виснуть, приложение даёт быстрый контролируемый ответ (например, кэшированные данные или «повторите позже»), что предотвращает засорение серверов.
Как выбрать адекватный таймаут для пользовательского запроса?
Ориентируйтесь на терпимость пользователя: для клика по кнопке или загрузки страницы выбирайте короткий таймаут, чтобы интерфейс оставался отзывчивым (часто пару секунд, а не 20). Если вызов необязателен — таймаут ещё короче и поведение деградирует аккуратно; если критично — лучше быстро вернуть ошибку и объяснение, чем позволить запросам накапливаться.
Когда следует избегать повторов, а когда они безопасны?
Избегайте повторов по умолчанию для всего, что может создать дубль побочного эффекта — списание денег, отправка письма или запись в базу. Повтор безопасен только для идемпотентных операций; даже тогда используйте экспоненциальную задержку и ограничение числа попыток, чтобы не усиливать нагрузку на провайдера.
Куда сначала ставить circuit breakers для максимального эффекта?
Ставьте предохранители вокруг синхронных вызовов на критическом пути: логин/аутентификация, оформление заказа/платежи, отправка SMS/позывных кодов и любые API, без которых страницы не смогут отрендериться. Наибольший эффект там, где одна зависимость может заблокировать много запросов и занять общие ресурсы.
Что на самом деле означают состояния closed, open и half-open?
«Закрыто» значит, что вызовы идут как обычно и вы считаете неудачи. «Открыто» — вы временно блокируете вызовы и сразу возвращаете контролируемый ответ. «Полуоткрыто» — после окна ожидания вы пропускаете небольшое количество пробных вызовов, чтобы проверить, восстановился ли провайдер, прежде чем полностью закрыть цепь.
Какой фолбэк подойдет, когда провайдер упал?
Хороший фолбэк позволяет пользователю двигаться дальше, не выдавая ложное подтверждение. Например: если почта не отправляется — принять регистрацию и поставить письмо в очередь; если API цен недоступен — показать последнее известное значение с пометкой времени и предупреждением, что оно может быть устаревшим. Для денег и безопасности будьте предельно ясны, что произошло и что нет.
Стоит ли использовать один глобальный circuit breaker для всего?
Не используйте один глобальный breaker для всего. Область действия должна соответствовать зависимостям и типу вызова. Авария платежного провайдера не должна блокировать доступ к профилям, а падение почты — ломать вход. Слишком широкая область приводит к ненужной деградации не связанного функционала.
Как тестировать circuit breakers, не вызывая реального инцидента?
В имитационной среде отключите зависимость на пару минут и проверьте: запросы быстро возвращают контролируемый результат, пользователи видят предсказуемое поведение (сообщение, кэш, очередь), система остаётся отзывчивой под нагрузкой. Затем включите провайдера и убедитесь, что circuit breaker проходит через полуоткрытое состояние и восстанавливается автоматически без ручного вмешательства.
Почему AI‑сгенерированные приложения так плохо справляются с ненадёжными провайдерами и что может сделать FixMyMess?
AI‑сгенерированный код часто реализует только «счастливый путь»: длинные или отсутствующие таймауты, агрессивные петли повторов и вызовы провайдеров раскиданы по разным обработчикам. FixMyMess может провести бесплатный аудит кода, указать отсутствующие таймауты, проблемные циклы повтора и слабые сценарии обработки ошибок, и быстро стабилизировать худшие интеграции, добавив чистые обёртки, адекватные таймауты и честные фолбэки — часто за 48–72 часа.