Предотвратить каскадные запросы на клиенте и ускорить приложение
Устраните каскадные (последовательные) клиентские запросы: запускайте независимые вызовы параллельно или агрегируйте данные на сервере, чтобы сократить время загрузки и time-to-interactive.
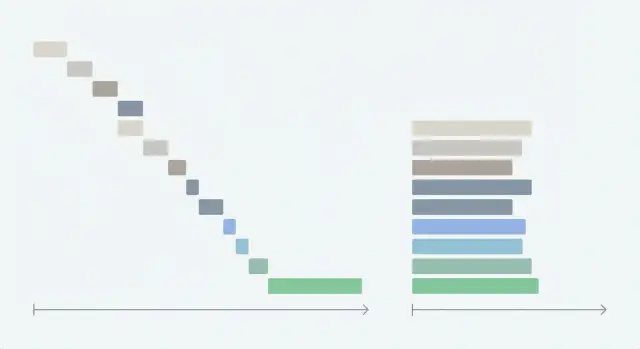
Что такое каскадные (waterfall) запросы и почему они замедляют приложение
Каскадный запрос происходит, когда ваше приложение делает один сетевой вызов, ждёт его завершения, а затем запускает следующий. Каждому запросу добавляется собственная задержка, так что общее время ожидания превращается в сумму всех задержек, а не примерно в самую длинную задержку.
Это вредит показателям time-to-interactive, потому что экран часто не может показать ничего полезного, пока не вернётся последний запрос. Пользователь видит это как пустую страницу, затянувшийся спиннер или интерфейс, который появляется, но остаётся наполовину пустым и постоянно смещается.
Каскады обычно проявляются в нескольких повторяющихся паттернах:
- Цепочки fetch, где запрос B запускается только в success‑хэндлере запроса A.
- Рендеринг, привязанный к приходу данных, так что глубокие части страницы даже не монтируются, пока не вернутся ранние данные.
- Вложенные компоненты, которые каждый «фетчат при монтировании», что заставляет дочерние запросы ждать родителей.
- «Удобный» код, разбивающий один экран на пять эндпоинтов, даже когда данные всегда нужны вместе.
Это особенно часто встречается в прототипах, сгенерированных ИИ. На быстрой локальной машине они могут ощущаться нормальными, но в продакшене становятся вялыми, потому что последовательные вызовы накапливаются.
Хорошая новость в том, что обычно можно предотвратить каскадные запросы на клиенте без полной переработки. Многие исправления простые: выполняйте независимые запросы параллельно, начинайте загрузку раньше и переносите координацию на сервер, когда клиент делает слишком много работы.
Как быстро заметить каскад на стороне клиента
Начните с наблюдения за экраном, как это сделал бы пользователь. Каскады часто выглядят «занятно», но не отзывчиво.
Яркий намёк — опыт загрузки. Если спиннер появляется, исчезает, затем снова появляется, приложение, вероятно, ждёт цепочки. Ещё один признак — UI, который приходит по этапам: сначала шапка, затем сайдбар, затем таблица, затем фильтры. Такое ступенчатое ощущение обычно означает, что данные приходят по одному запросу за раз.
Сосредоточьтесь на экранах, о которых чаще всего жалуются пользователи. Каскады любят дашборды, страницы настроек и любые виды с большим количеством «мелких» данных.
Что смотреть в браузере
Откройте DevTools и перейдите на вкладку Network. Перезагрузите страницу и смотрите на:
- Длинную цепочку, где каждый запрос стартует только после завершения предыдущего
- Паузы между запросами (ничего не происходит, пока UI ждёт)
- Множество похожих вызовов, отличающихся лишь незначительно
- Запросы, блокирующие первый значимый контент
- «Fan-out», который случается поздно (один вызов возвращается и затем триггерит несколько других)
После того как вы заметили подозрительную цепочку, кликните по первому запросу и проверьте, что его триггерило (Initiator или stack trace, в зависимости от браузера). Если fetch в одном компоненте триггерит другой fetch в дочернем компоненте — вы нашли форму водопада.
Сверка с логами бэкенда
Каскад также может проявляться как повторяющиеся вызовы одних и тех же данных. Дашборд может получать текущего пользователя в трёх разных компонентах, потому что каждый «на всякий случай» запрашивает его снова.
В кодовых базах, сгенерированных ИИ, это частая проблема: компоненты копируют логику fetch и непреднамеренно создают цепочки и дубликаты.
Пример: экран дашборда, который ждёт пять эндпоинтов
Типичный реальный водопад — дашборд, собранный из прототипа, который загружает данные по‑этапно. Каждый запрос ждёт предыдущий, поэтому страница не может прийти в стабильное состояние.
Представьте, что страница при монтировании делает так: fetch /api/me, затем /api/team, затем /api/permissions, затем /api/widgets, затем для каждого виджета /api/widgets/:id/data. Если каждый вызов занимает 200–400 мс, пользователи могут ждать 1.5–3 секунды, прежде чем экран станет удобным, даже при неплохом соединении.
Вот типичный набор эндпоинтов (имена могут отличаться, важен сам порядок):
GET /api/me(основы профиля: имя, аватар)GET /api/team(id команды, название)GET /api/permissions?teamId=...(роли, фичи)GET /api/widgets?teamId=...(список карточек)GET /api/widgets/:id/data(числа, графики, недавние элементы)
Проблема не в количестве запросов, а в принудительном порядке.
Часто страница ждёт /api/me прежде чем стартовать /api/team, хотя их можно было бы запустить вместе. Затем она ждёт permissions перед рендером карточек, и пользователь смотрит на пустой каркас. Потом карточки появляются по одной и смещают интерфейс по мере прихода данных.
Чтобы предотвратить каскадные запросы на клиенте, отделите то, что действительно зависит друг от друга, от того, что просто было закодировано последовательно.
Некоторые вызовы обычно можно выполнять параллельно (например, /api/me и /api/team, а иногда и /api/widgets). Другие действительно зависимы (например, /api/permissions, которому нужен teamId, и запросы данных виджетов, которым нужны ID виджетов).
Главная идея: обычно для стабильного первого вида нужно лишь небольшое множество полей (хедер, лэйаут, плейсхолдеры). Всё остальное можно распараллелить или сгруппировать.
Быстрые выигрыши до большого рефактора
Не всегда нужна полная переработка, чтобы избежать каскадов. Несколько целевых правок могут сэкономить секунды времени до интерактивности и уменьшить «прыгающий» эффект интерфейса.
Сначала подтвердите, что действительно медленно. В Network отсортируйте по Duration и найдите эндпоинт, который доминирует по времени. Легко переработать три «очевидных» вызова и при этом пропустить реальную проблему — например медленную проверку permissions.
Затем сделайте первый экран полезным быстрее. Если данные не нужны для первого значимого вида (например, «рекомендации», «недавняя активность» или тяжёлый график), грузите их после того, как пользователь сможет уже кликать. Люди терпимее к фоновым загрузкам, чем к пустой странице.
Набор быстрых изменений, которые обычно окупаются:
- Начинайте запросы раньше (при навигации или смене маршрута), а не после монтирования глубоко вложенных компонентов.
- Остановите дублирующие запросы — фетчьте общие данные один раз и переиспользуйте их.
- Кэшируйте результаты в памяти на короткое время, чтобы при возврате не повторять те же вызовы.
- Профетчьте вероятный следующий экран, когда приложение простаивает, но только если это безопасно и не чувствительно.
- Перенесите некритичные вызовы «после paint», чтобы сначала сделать страницу интерактивной.
Пример: дашборды часто повторно фетчат /me в каждой плитке, потому что каждый виджет запрашивает пользователя отдельно. Простое решение — фетчить пользователя один раз на уровне экрана и передать вниз.
Шаг за шагом: рефакторим последовательные запросы в параллельные
Начните с списка всех запросов, которые делает экран, и зачем они нужны. Пометьте каждый как независимый (может загрузиться сразу) или зависимый (нужен ID или значение из другого ответа).
Распространённая цепочка: загрузить пользователя, затем команду по user.teamId, затем проекты по team.id. Только team и projects действительно зависят друг от друга. Всё, что не требует этих ID, не должно быть в цепочке.
1) Замапьте, что может выполняться вместе
Сгруппируйте запросы в два ведра: «можно фетчить сейчас» и «нужно ждать X». Планируйте две волны:
- Волна 1: стартуйте всё независимое одновременно.
- Волна 2: как только получите нужные ID, запустите зависимые запросы тоже параллельно.
2) Замените цепочки await на параллельные вызовы
Если вы видите await за await для несвязанных вызовов — это первая цель для рефактора.
async function loadScreenData() {
const [me, flags, notifications] = await Promise.all([
api.get("/me"),
api.get("/feature-flags"),
api.get("/notifications"),
]);
const [team, projects] = await Promise.all([
api.get(`/teams/${me.teamId}`),
api.get(`/teams/${me.teamId}/projects`),
]);
return { me, flags, notifications, team, projects };
}
Держите параллельные группы небольшими и осмысленными. Если один вызов опционален (например, «советы» или «новости»), грузите его после первого paint.
3) Централизуйте загрузку данных на уровне экрана
Вместо того чтобы разбрасывать фетчи по виджетам, создайте одну функцию load screen data (или хук на уровне маршрута), которая владеет данными экрана.
Это упрощает отслеживание зависимостей, делает retries и кэширование предсказуемее и помогает избежать «пяти спиннеров» повсюду.
Стремитесь к одному состоянию загрузки на экран, когда это возможно. Пользователи обычно предпочитают «дашборд загружается» вместо пяти отдельных спиннеров, которые завершаются в разное время.
Измеряйте до и после. Отслеживайте время до первого контента и time-to-interactive.
Когда агрегировать на сервере вместо клиента
Агрегация на сервере означает, что один запрос возвращает всё, что нужно экрану, вместо того чтобы браузер делал много маленьких вызовов.
Если цель — предотвратить каскадные запросы на клиенте, это иногда самое аккуратное решение, потому что клиент перестаёт координировать цепочку зависимых вызовов.
Агрегация полезна в ситуациях:
- Экран нуждается в множестве мелких эндпоинтов.
- Заметна латентность (пользователи на мобильных или в удалённых регионах).
- Каждый эндпоинт повторяет одну и ту же работу (аутентификация, проверки прав, DB‑lookup).
Пять запросов по 150–300 мс быстро превращаются в полноценную секунду или больше, прежде чем UI успокоится.
Простой контракт делает поведение предсказуемым. Например, дашборд может иметь один эндпоинт, возвращающий базу:
GET /dashboard->{ profile, team, widgets }
Следите за областью охвата. Избегайте агрегации, когда ответ становится огромным, включает редко используемые данные «на всякий случай» или смешивает данные с разными правилами приватности. Красный флаг — когда ответ становится настолько широким, что малейшее изменение ломает много несвязанных частей UI.
Безопасный план миграции — добавить агрегированный эндпоинт, сохранив старые вызовы работающими. Внедрите изменение клиента под feature‑флагом, сравните результаты и постепенно переключайте трафик. Когда новый путь стабилизируется — убирайте старые вызовы.
Уменьшите размер полезной нагрузки и повторяющиеся запросы
Думайте не только об порядке запросов. Смотрите, насколько велик каждый ответ и как часто вы запрашиваете одни и те же данные. Даже идеально параллельные запросы могут казаться медленными, если каждый ответ тяжёлый или повторяется.
Обрежьте API‑ответы до того, что реально используется на экране. Если карточке нужен name, status и updatedAt, не шлите полный объект с логами, комментариями и длинными описаниями.
Батчьте похожие запросы, где можно. Частый паттерн — сначала получить список, а затем по одному получать детали каждого элемента. Такое поведение N+1 добавляет скрытые задержки и нагрузку на сервер. Предпочитайте один эндпоинт, который принимает массив ID и возвращает соответствующие элементы в одном ответе.
Дубликаты часто приходят из разных компонентов, запрашивающих одно и то же независимо. Храните общие данные за одним слоем запроса (или в одном сторе), чтобы они фетчились один раз и переиспользовались.
Практические проверки, которые обычно окупаются:
- Добавьте пагинацию или лимиты, чтобы начальная загрузка оставалась небольшой.
- Запрашивайте только нужные поля (избегайте «include everything»).
- Батчьте «fetch by ID» в один запрос «fetch by IDs».
- Дедупликейтите текущие в полёте запросы, чтобы два компонента не спровоцировали один и тот же вызов.
- Следите за N+1 паттернами на бэкенде (один API‑вызов, вызывающий множество DB‑запросов).
Пример: если дашборд загружает 200 проектов при первом рендере, но показывает только 20 — запросите 20 и подгружайте остальное при скролле или поиске.
Состояния загрузки, ошибки и кэширование без новых багов
После рефакторинга, направленного на предотвращение каскадов, следующий риск — баги UX: пустые экраны, спиннеры, которые не исчезают, и мигающие данные.
Решите, что действительно блокирует взаимодействие, а что может приходить позже.
Разделите данные на две группы:
- Блокирующие данные: нужны для рендера структуры страницы или для первой значимой операции.
- Неблокирующие данные: приятны в наличии, но их можно загрузить после того, как страница станет пригодной.
Показывайте частичный UI честно
Skeleton‑плейсхолдеры работают лучше, когда они соответствуют финальному макету. Используйте их, чтобы зарезервировать место и показать структуру, затем заполните реальными значениями.
Для тяжёлых виджетов (графики, редакторы, карты) рендерьте лёгкий плейсхолдер и загружайте виджет после основного контента.
Простой паттерн:
- Сразу рендерьте лэйаут с безопасными значениями
- Показывайте skeleton только там, где появятся данные
- Загружайте тяжёлые виджеты после основного контента
- Блокируйте кнопки только если они действительно зависят от отсутствующих данных
- Предпочитайте текст «последнее обновление» вместо бесконечного спиннера
Ошибки: проваливайтесь локально, а не глобально
Параллельные вызовы означают, что одни могут успехнуться, а другие — упасть. Обрабатывайте ошибки по секции и сохраняйте остальную часть экрана интерактивной. Покажите небольшое сообщение об ошибке с кнопкой retry для этой части.
Избегайте бесконтрольных автоповторов. Используйте backoff и максимум попыток, чтобы не создавать лавину повторных запросов.
Кэширование помогает, но только при ясных правилах. Решите, как долго данные «свежи» (например, 30 секунд для уведомлений, 5 минут для профиля). Когда данные устарели, можно показывать закэшированные значения мгновенно и обновлять в фоне, но отмечайте это, если точность важна.
Наконец, защищайтесь от гонок при быстрой навигации пользователя. Если пользователь ушёл со страницы — отменяйте текущие запросы и игнорируйте поздние ответы. Иначе старый ответ может перезаписать более новый стейт.
Частые ошибки, которые возвращают водопады
Каскады часто возвращаются после «успешного» рефактора, потому что загрузка данных разрешена в слишком многих местах. Цель — не просто распараллелить текущие вызовы. Цель — сохранить архитектуру такой, чтобы она оставалась параллельной со временем.
1) Скрытые фетчи внутри вложенных компонентов
Обычная ловушка: основной экран переведен на параллельные вызовы, но дочерние компоненты всё ещё фетчат при монтировании. Локально кажется нормально, но когда добавляют новый виджет, клиент тихо начинает ждать его.
Простое правило помогает: фетчьте на одном уровне (route или screen), а затем передавайте данные вниз. Если компонент действительно должен владеть своими данными, делайте это явно и измеримо.
2) «Зависимые» запросы, которые на самом деле независимы
Команды иногда цепляют вызовы, потому что так кажется безопаснее. Но часто запрос B нужен лишь маленький кусок из A (например, ID), который у вас уже есть или который можно получить раньше.
Быстрый тест: «Если A упадёт, сможет ли B выполняться?» Если да — они не зависят друг от друга.
3) Чрезмерное распараллеливание, которое перегружает бэкенд
Параллель хорошо, пока не превращается в лавину. Запуск 20 запросов одновременно может вызвать rate limit, замедлить базу или породить ретраи, добавляющие ещё задержек.
Держите параллелизм под контролем:
- Ограничивайте конкурентность (например, 4–6 одновременно)
- Дедупликейтите идентичные вызовы между компонентами
- Кэшируйте стабильные данные (например, текущий пользователь)
- Добавьте backoff для ретраев
4) Мега‑эндпоинт, возвращающий слишком много
Агрегация помогает, но единый эндпоинт, возвращающий «всё» со временем растёт и становится новой бутылочной горловиной. Клиент делает один вызов, но этот вызов медленно считается, трудно кешируется и хрупок.
5) Дополнительные круги из‑за проверок аутентификации
Если аутентификация проверяется поздно, можно получить сценарий: загрузка страницы → 401 → обновление токена → повтор всех запросов.
Сделайте состояние аутентификации доступным рано и не запускайте запросы, пока сессия не подтверждена.
Контрольный список перед релизом рефакта
Сделайте последний прогон, ориентируясь на время для пользователя, а не только на чистоту кода. Водопады могут вернуться через небольшие изменения, типа нового фичфлага или лишнего «на всякий случай» запроса.
Пройдитесь по главному экрану как впервые при холодной загрузке (пустой кэш). Если страница не может показать ничего полезного, пока не завершатся многие вызовы — вероятно, у вас всё ещё есть скрытая цепочка.
Небольшой препрод чеклист:
- Начинайте с одного‑двух «must-have» запросов, затем грузите остальное после первого видимого контента.
- Стартуйте независимые вызовы в один и тот же тик, а не после разрешения другого промиса.
- Сделайте одного явного владельца загрузки данных экрана (функция или хук).
- Уберите дубликаты по дизайну (общий кэш клиента, мемоизированные загрузчики или агрегированный ответ).
- Перепроверьте Network timing и time-to-interactive после рефактора при тех же условиях симуляции.
Небольшая реальность: если ваш дашборд параллельно фетчит профиль, permissions и данные рабочей области и быстро показывает хедер и навигацию, он должен так и оставаться. Если позже появляется бейдж «статус биллинга», который ждёт разрешения permissions прежде чем стартовать — вы ввели новый мини‑водопад.
Следующие шаги: верните приложению быструю и надёжную загрузку
Если после рефактора приложение всё ещё кажется медленным, предполагайте, что где‑то спрятались дополнительные водопады. Это часто случается в кодовых базах, сгенерированных ИИ, где компонент экрана выглядит чисто, но хук ниже сцепляет запросы, делает повторные вызовы при каждом рендере или фетчит одни и те же данные для каждой строки.
Выберите один реальный экран, который важен пользователям (обычно дашборд или home), и измерьте одно: сколько времени до появления первого пригодного для использования экрана. Затем спланируйте самое маленькое изменение, которое улучшит этот показатель.
Фокусированный аудит поможет избежать «фич скоростей», создающих новые баги. Ищите:
- Цепочки fetch, триггеримые обновлениями состояния (fetch A ставит состояние, которое запускает fetch B)
- N+1 запросы (список + по одному запросу на элемент)
- Повторяющиеся вызовы из‑за отсутствия мемоизации или нестабильных зависимостей
- Эндпоинты, возвращающие слишком много данных, заставляющие долго парсить и рендерить
- Рискованные упрощения, появляющиеся при рефакторах (секреты в клиенте или небезопасная генерация запросов)
Если вы унаследовали запутанный код, сгенерированный ИИ, и хотите второе мнение, FixMyMess (fixmymess.ai) проводит диагностику кода и исправляет сломанные AI‑построенные приложения: распутывает последовательные цепочки запросов и оптимизирует API, чтобы экраны предсказуемо загружались в продакшене. Предлагается бесплатный аудит кода, и большинство исправлений делается в течение 48–72 часов.
Часто задаваемые вопросы
Что такое каскадный запрос на стороне клиента простыми словами?
Каскадный запрос — это когда приложение запускает запрос B только после того, как завершился запрос A, хотя их можно было бы выполнить одновременно. Такая принудительная последовательность суммирует задержки и обычно проявляется как длинный спиннер, пустой каркас страницы или интерфейс, который заполняется по частям.
Как быстро подтвердить наличие водопада в браузере?
Откройте DevTools → Network, перезагрузите страницу и посмотрите на цепочку запросов: если каждый следующий стартует только после окончания предыдущего — это сигнал водопада. Также обращайте внимание на паузы (idle gaps) и «fan-out», когда один ответ запускает несколько последующих запросов — такая модель времени обычно значит, что координация запросов происходит слишком поздно.
Какой самый быстрый фикс для последовательных вызовов `await`?
Если запросы независимы, замените последовательные await на Promise.all, чтобы они стартовали одновременно. Если запросы зависят от ID, запускайте всё, что можно, в первой волне, а потом — зависимые вызовы одновременно во второй волне.
Как остановить повторные запросы из разных компонентов?
Выполняйте запрос один раз на уровне экрана или маршрута и передавайте результат вниз, вместо того чтобы позволять нескольким вложенным компонентам запрашивать одно и то же на монтировании. Это уменьшит дубликаты и предотвратит скрытые цепочки, где дочерние компоненты начинают загрузку лишь после рендера родителей.
Какие данные загружать сначала, а какие — в фоне?
Сначала загрузите минимальные «блокирующие» данные, чтобы отобразить макет и основные взаимодействия, а затем подгружайте «неблокирующие» данные в фоне. Например, отложите графики, рекомендации и тяжёлые таблицы, чтобы пользователь мог быстрее начать пользоваться интерфейсом.
Как сделать загрузку плавной после распараллеливания запросов?
Используйте skeleton‑заполнители, соответствующие итоговому макету, чтобы контент не «прыгнул» при появлении данных. Избегайте множества спиннеров; стремитесь к одному понятному состоянию загрузки на экран и небольшим плейсхолдерам по секциям, чтобы частичный контент выглядел естественно.
Как правильно обрабатывать ошибки при параллельных запросах?
Обрабатывайте ошибки на уровне секции и держите остальную часть экрана интерактивной, потому что параллельные запросы могут падать независимо. Для упавшей секции предлагайте маленькую кнопку повторной попытки и избегайте агрессивных автоповторов, которые могут застопорить UI или перегрузить бэкенд.
Когда лучше агрегировать данные на сервере, а не на клиенте?
Когда экран требует много мелких эндпоинтов, заметна задержка (мобильные пользователи, удалённые регионы) или каждый эндпоинт повторяет одно и то же (аутентификацию, проверки прав, DB‑запросы), стоит агрегировать на сервере. Одна точка /dashboard, возвращающая { profile, team, widgets }, убирает необходимость клиентской координации — но не делайте ответ слишком большим или универсальным, иначе он станет новой узкой горлышкой.
Как избежать N+1 запросов на дашборде или в списках?
Это происходит, когда вы сначала загружаете список, а затем по одному запрашиваете детали для каждого элемента — в результате множества лишних круговых вызовов. Решение — батчить запросы (fetch by IDs) или возвращать нужные поля сразу в ответе списка, чтобы клиент не вызывал каскад.
Почему в кодовой базе, сгенерированной ИИ, часто появляются водопады и что делать, если унаследовал такой проект?
AI‑генерированные прототипы часто размазывают логику фетчей по множеству компонентов, копируют/вставляют запросы и непреднамеренно создают цепочки через обновления состояния. Если вы унаследовали такое приложение (Lovable, Bolt, v0, Cursor, Replit) и оно быстро дома, но медленно в проде, FixMyMess (fixmymess.ai) может провести аудит и распутать цепочки запросов, дубликаты и рискованные API‑паттерны.