Проверки готовности и работоспособности, которые ловят настоящие отказы
Узнайте, как проектировать проверки готовности и работоспособности, которые проверяют базу данных, очередь и критичные API — чтобы сбои проявлялись до того, как заметят пользователи.
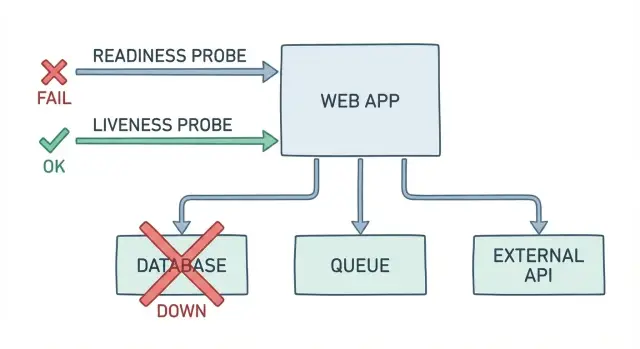
Почему простые проверки «OK» всё ещё оставляют пользователей без сервиса
Базовый эндпойнт /health обычно отвечает на один вопрос: работает ли процесс? Это не то же самое, что «может ли пользователь сейчас войти, оплатить или закончить работу». Когда проверка возвращает «OK», а приложение не выполняет свою реальную задачу, вы получаете ложнозелёные алерты и более долгий, грязный инцидент.
Так это выглядит в реальной жизни. Под поднят, CPU в норме, эндпойнт здоровья говорит «OK». Но вход не проходит, потому что база данных заблокирована во время миграции. Платежи падают, потому что секреты обновились и учётные данные истекли. Фоновые задачи накапливаются, потому что соединение с очередью застряло, и подтверждения заказов никогда не отправляются.
Ложнозелёные пробы съедают время и доверие. Оператор получает сигнал «всё в порядке» и метается по ложным следам. Поддержка узнаёт о проблеме раньше мониторинга. Пользователи повторяют попытки, уходят и запоминают плохой опыт.
Проверки готовности и работоспособности должны отражать то, что нужно пользователям, чтобы они могли работать. Хорошая проба — это не показательное «OK». Это небольшой, быстрый тест критического пути.
Проба, понимающая зависимости, должна отвечать на вопросы вроде:
- Можем ли мы подключиться к базе данных и выполнить маленький запрос?
- Можем ли мы аутентифицироваться в очереди и опубликовать сообщение (или хотя бы проверить, что соединение живо)?
- Валидны ли требуемые учётные данные и не истёк ли их срок?
- Доступны ли внешние сервисы, от которых мы действительно зависим?
Если вы унаследовали AI‑сгенерированное приложение, которое «запускается», но ломается в проде (обычно вокруг auth, секретов и очередей), более умные пробы не дадут плохим деплоям тихо навредить пользователям.
Readiness vs liveness простыми словами
Readiness отвечает: может ли этот конкретный экземпляр безопасно принимать трафик прямо сейчас? Если нет — он должен оставаться запущенным, но быть выведенным из ротации, чтобы пользователи не попадали на сломанный экземпляр.
Liveness отвечает: жив ли процесс и делает ли он прогресс, или он застрял так, что перезапуск это исправит? Если нет — платформа должна перезапустить его.
Простой пример readiness: приложение загрузилось, но база данных упала или учётные данные неверны. Процесс запущен, но каждый вход и загрузка страниц падают. Хорошая readiness‑проверка провалится здесь, чтобы запросы не шли на этот экземпляр, пока база не заработает.
Простой пример liveness: баг вызывает дедлок, и приложение перестаёт отвечать, хотя контейнер всё ещё работает. Readiness тоже может начать падать, но это не решит корневую проблему. Liveness‑проверка указывает, что приложение не делает прогресса, и триггерит перезапуск для восстановления.
Как запомнить:
- Readiness защищает пользователей от сломанных экземпляров.
- Liveness помогает системе восстановиться от зависших экземпляров.
Эти проверки — не полноценные end‑to‑end тесты. Они не должны прогонять полные пользовательские сценарии или опрашивать все зависимости на каждой пробе. Держите их маленькими и сфокусированными на нескольких вещах, которые обязательно должны быть верны, чтобы приложение безопасно обслуживало трафик.
Начните с того, что действительно важно для пользователей
Проба полезна только если она соответствует тому, что делают пользователи. Прежде чем писать readiness и liveness, выпишите несколько действий, которые определяют «приложение работает» для вашего продукта. Если эти действия падают — пользователи сломаны, даже если ваш эндпойнт возвращает 200.
Держите список маленьким и реальным: вход и загрузка дашборда, создание проекта или заказа, загрузка файла и его отображение, запуск задания или отправка сообщения, завершение оплаты (если у вас есть платежи).
Теперь сопоставьте каждое действие с тем, что ему нужно. «Создать проект» обычно значит, что база записываемая и миграции применены. «Загрузить файл» может требовать объектного хранилища и фонового воркера. «Отправить сообщение» зависит от доступности очереди и работающих потребителей.
Из этой карты выберите минимальные проверки, которые лучше всего представляют «пользователь может завершить путь». Ping базы — недостаточно, если записи блокируются. Проверка соединения с очередью — недостаточно, если публикация падает. Стремитесь к одной‑двум проверкам на критический путь, опираясь на зависимости, которые чаще всего ломают опыт.
Наконец, решите, что значит «деградировано, но работает». Могут ли пользователи просматривать, но не создавать? Могут ли они войти, но загрузки временно отключены? Примите это решение сознательно — оно управляет поведением readiness (принимать ли трафик или нет).
Простой сценарий: приложение загружается, но новые проекты никогда не появляются, потому что воркер не может поставить задачу в очередь. UI‑эндпойнт здоровья всё ещё говорит «OK». Readiness‑проверка, включающая лёгкую постановку в очередь (или проверку публикации), поймает проблему, которую ощущают пользователи.
Что проверять: БД, очередь и ваши критические зависимости
Полезный эндпойнт здоровья должен отвечать на один вопрос: если отправить реальный пользовательский запрос прямо сейчас, сработает ли он? Это значит, что readiness (и любые дополнительные проверки зависимостей) должны трогать те же зависимости, что и приложение, а не просто возвращать «OK», потому что веб‑сервер жив.
База данных
Начните просто и безопасно. Проверьте, что можно подключиться теми же учётными данными, что и приложение, и выполнить крошечный read‑only запрос вроде SELECT 1. Это ловит поломки сети, истёкшие пароли и неверные строки подключения. Держите запрос быстрым, не блокируйте таблицы и не запускайте миграции из пробы.
Очередь и фоновая работа
Если ваше приложение зависит от фоновых задач, проверять лишь API недостаточно. Проба должна подтвердить, что вы можете опубликовать тестовое сообщение (или хотя бы аутентифицироваться у брокера), и что воркеры действительно потребляют. Следите за растущим бэклогом: очередь может быть «вверх», но работа на самом деле застопорена.
Практический стартовый набор:
- Подключение к БД + один лёгкий запрос
- Публикация в очередь (и, в идеале, сигнал о потреблении от воркера)
- Один критический внутренний сервис, без которого вы не можете работать
- Один внешний API, от которого зависит ваш основной поток
- Санация конфигурации: обязательные env vars присутствуют и секреты провязаны правильно
Внешние API требуют дополнительной осторожности. Вы не тестируете весь интернет, но должны знать, если учётные данные неверны, DNS сломан или ответы сильно замедлились.
Конкретный пример: запрос регистрации записывает пользователя в БД, затем ставит задачу «отправить приветственное письмо». Если проверка БД проходит, но очередь не принимает сообщения, пользователи «регистрируются», но никогда не получают письма подтверждения. Readiness‑проверка, включающая очередь, блокирует трафик до восстановления этого пути, вместо тихой поставки молча сломанных фич.
Пошагово: как сделать readiness‑проверку, которая блокирует трафик
Readiness должна отвечать: может ли этот экземпляр обрабатывать реальные пользовательские запросы прямо сейчас? Если нет — она должна падать, чтобы новый трафик удерживался.
1) Докажите минимум, который имеет значение
Начните с минимальной операции с БД, которая всё ещё доказывает работоспособность приложения. TCP‑коннект не достаточен. Предпочитайте маленький запрос, который использует те же учётные данные, схему и сетевой путь, что и приложение.
Обычная практика — эндпойнт вроде /ready, который выполняет быстрый запрос и проверяет одну‑две критические зависимости.
- Выполните один лёгкий DB‑запрос (например,
SELECT 1) через обычное подключение приложения. - Установите строгие таймауты (сотни миллисекунд, а не секунды), чтобы сбои появлялись быстро.
- Если БД недоступна или таймаут, возвращайте «not ready», чтобы балансировщик не посылал трафик на этот экземпляр.
- Включите человеко‑читаемую причину в теле ответа, но никогда не включайте секреты, строки подключения или полные дампы ошибок.
- Добавьте короткий период старта, чтобы холодные старты не вызывали флапы, пока приложение прогревается.
2) Сделайте сбои очевидными (но безопасными)
Возвращайте чёткий код состояния (например, 503) и небольшой безопасный payload:
{ "ready": false, "reason": "db_timeout" }
Поле reason экономит время при инцидентах, потому что указывает на зависимость, не раскрывая приватных данных.
3) Подключите это к маршрутизации
В Kubernetes readiness управляет тем, получает ли под трафик. Убедитесь, что приложение сообщает ready только когда может выполнить реальную операцию.
Пошагово: как сделать liveness‑проверку, которая триггерит перезапуск
Liveness отвечает: делает ли процесс прогресс или он застрял? Если он застрял, перезапуск часто — самый быстрый путь назад для пользователей.
- Выберите «сигнал прогресса», который доказывает, что приложение не заблокировано. Хорошие сигналы локальны и просты: метка времени watchdog, обновляемая главным циклом, или «время с последнего завершённого запроса».
- Держите это лёгким и локальным. Liveness не должна вызывать БД, очередь или внешние сервисы; сетевые сбои вызовут ненужные перезапуски.
- Добавьте пороги, чтобы избежать рестарт‑лупов. Проверяйте регулярно, но требуйте нескольких последовательных провалов перед объявлением контейнера мёртвым. Также добавьте стартовый grace‑период.
- Логируйте причину прямо перед фейлом. Запишите одну понятную строку с сигналом застревания и несколькими ключевыми счётчиками (ожидающие задачи, занятые потоки, память).
- Тестируйте под реальной нагрузкой, а не только в dev. Симулируйте высокий load, медленные downstream‑вызовы и большие payload. Многие приложения выглядят нормально, пока пул потоков не заполнится и процесс не перестанет отвечать.
Пример: сервис принимает HTTP‑запросы, но все воркеры заблокированы из‑за дедлока. Запросы висят, пользователи видят бесконечный спиннер, и readiness может оставаться зелёной. Liveness‑проверка, отслеживающая «время с последнего завершённого запроса», может заметить зависание и перезапустить процесс.
В идеале readiness и liveness работают вместе: readiness защищает пользователей от сломанных зависимостей, а liveness спасает вас от зависшего кода.
Таймауты, ретраи и пороги, которые нормально ведут себя в продакшене
Пробы должны быть быстрыми и скучными. Если проба выполняется слишком долго, запросы накапливаются, приложение делает лишнюю работу, и сама проба может стать причиной отказа. Для большинства приложений цель — короткий таймаут (часто 1–2 секунды) и небольшая фиксированная работа на пробу.
Избегайте тяжёлых ретраев внутри пробы. Ретраи могут скрывать реальные сбои и добавлять нагрузку, когда системы уже страдают. Если БД таймаутит, проба с тройным ретраем может иногда возвращать успех, но при этом сильнее бить по базе в самый худший момент.
Простые пороги, разделяющие глюки и простои
Вместо ретраев внутри пробы используйте простые пороги на уровне оркестратора. В Kubernetes это обычно значит позволить нескольким провалам перед действием.
Практическая стартовая точка:
- Readiness timeout: 1–2с, failureThreshold: 2–3
- Liveness timeout: 1–2с, failureThreshold: 3–5
- periodSeconds: 5–10 (не дергайте пробу каждую секунду, если в этом нет крайней нужды)
- successThreshold: 1
Думайте об этом как о небольшом бюджете отказов: один медленный ответ не должен создавать хаос, но повторные провалы должны сработать.
Unready vs dead: выбирайте наименее разрушительное действие
Readiness и liveness — разные рычаги. Если зависимость упала, обычно безопаснее пометить приложение not‑ready, чтобы оно перестало принимать трафик. Перезапуск часто не решит проблему с упавшей БД или очередью и может замедлить восстановление.
Используйте readiness, чтобы сказать: «Я сейчас не могу обслуживать пользователей корректно». Используйте liveness, чтобы сказать: «Я застрял и нужен перезапуск».
Распрострённые ошибки, которые создают ложнозелёные проверки (или постоянный флап)
Большинство ошибок с проверками сводится к двум проблемам: они либо слишком поверхностны (всё «OK», хотя пользователи не могут войти), либо слишком глубоки (падают на нормальных глюках и вызывают рестарты).
Классическое ложнозелёное поведение — проба, которая лишь доказывает, что веб‑сервер запущен. Если приложение может принять HTTP, но не может читать из БД, публиковать в очередь или загрузить критичную конфигурацию, пользователи всё ещё сломаны.
Частые ошибки:
- Использование полного end‑to‑end сценария как liveness (логин + БД + очередь + внешний API). Когда любая зависимость моргнёт — оркестратор убьёт «здоровый» процесс и вызовет самонанесённый даунтайм.
- Привязка readiness к нестабильным внешним сервисам. Если платёжный или email API медлит 30 секунд, вы можете флапать ready/not‑ready и кидать трафик. Лучше мягкие сигналы (кеш последнего успеха, состояние circuit breaker), чем жёсткий провал каждый раз.
- Логирование или возврат сырых дампов ошибок. Эндпойнты здоровья — искушение печатать stack trace, строки подключения и токены. Держите ответы минимальными и очищенными.
- Говорить «ready», пока приложение ещё не готово. Частые виновники: миграции ещё идут, кеши не прогреты, воркеры не подключены или потребитель очереди упал.
- Игнорирование таймаутов и порогов. Проба без жёстких таймаутов может накапливать запросы. Проба без порогов может постоянно колебаться.
Держите liveness поверхностной (процесс застрял или нет) и readiness честной (может ли он безопасно обслуживать пользователей).
Сделайте сбои видимыми и понятными
Парализующая проба почти так же плоха, как всегда зелёная. Когда readiness и liveness падают, вы хотите, чтобы оператор понимал, что сломалось, насколько широко и что система делает для восстановления.
Логируйте провалы проб стабильным коротким кодом. Держите набор кодов маленьким и постоянным, чтобы их можно было искать и графить. Включайте одно предложение контекста, избегайте дампов стека при каждом провале.
Полезный вывод пробы обычно содержит стабильный код (например, DB_CONN_TIMEOUT или QUEUE_AUTH_FAILED), имя зависимости и операцию (connect, query, publish, consume) и базовый статус ready или not-ready. Если используете degraded, чётко опишите, что это значит и какой трафик безопасен.
Убедитесь, что «not‑ready» действительно работает. Протестируйте, вызвав реальный отказ зависимости (например, отзовите учетные данные очереди в стейджинге). Подтвердите, что экземпляр удаляется из ротации и на него больше не идут запросы. Если пользователи всё ещё попадают на него — ваша готовность не связана с маршрутизацией так, как вы думали.
Быть столь же строжными с рестартами. Liveness‑провал должен триггерить перезапуск только когда процесс действительно застрял. Если кратковременный сбой БД вызывает постоянные рестарты, вы превратите проблему зависимости в полноценный даунтайм.
Конкретный пример: логины падают, потому что БД доступна, но миграции не применены. Приложение отвечает HTTP 200 на /health, но каждый вход бросает ошибку. Лучше readiness‑проверка вернёт not-ready с MIGRATION_PENDING, не давая сломанным экземплярам принимать трафик.
Быстрый чек‑лист перед выпуском проб в прод
Прежде чем полагаться на readiness и liveness в продакшене, проверьте, что пробы падают по тем же причинам, по которым ломаются реальные пользователи. Если зависимость умирает — проба должна быстро и ясно это показать.
Readiness должна блокировать трафик при падении ключевых зависимостей: недоступная БД, неверные учётные данные или таймаут простого запроса. Проверки очереди должны отражать реальный поток сообщений, а не только «достучался ли клиент до сервера». У каждой пробы должен быть жёсткий таймаут. Ответы при падении должны быть безопасны для экспонирования (коды и короткие причины, без stack trace или секретов). И деплои не должны флапать — добавьте стартовый grace‑период для прогрева.
Один тест в стейджинге, который стоит прогнать
Смоделируйте реальный отказ: заблокируйте доступ к базе на несколько минут или остановите воркеры очереди. Подтвердите, что readiness быстро краснеет, трафик останавливается, и приложение чисто восстанавливается, когда зависимость возвращается.
Пример: приложение выглядит нормально, но очередь сломана
Обычная неисправность выглядит так: пользователи оформляют заказ, checkout возвращает 200, и ваш «health» отвечает «OK». Но клиенты никогда не получают подтверждений заказа, и тикеты в поддержку накапливаются.
Что случилось? Веб‑приложение всё ещё обслуживает запросы, но путь сообщений в очереди сломан. Может быть, приложение не может опубликовать из‑за неверных учётных данных. Может быть, очередь жива, но сильно перегружена, и обработка задерживается на часы. Снаружи приложение выглядит нормально.
Вот где важны readiness и liveness. Старая проба доказывала только одно: веб‑сервер может ответить. Лучшая readiness‑проверка скорее похожа на health‑probe зависимости и проверяет, что действительно нужно для реальных пользователей.
Простая readiness‑проверка для этого случая:
- Попытаться безопасно и быстро опубликовать в очередь (или выполнить проверку прав) с коротким таймаутом.
- Опционально проверить задержку очереди (например, возраст старшего сообщения) и провалить readiness, если она выше порога.
- Вернуть «not ready», чтобы трафик не шёл на этот экземпляр, пока путь очереди не восстановится.
Liveness другое. Если воркер очереди завис (дедлок, утечка памяти, зацикленное «отравленное» сообщение), обычно нужно перезапустить процесс воркера, в то время как веб‑процесс может оставаться живым. Часто это значит отдельные пробы: веб‑контейнер держите живым, а воркер может падать по liveness, когда перестаёт делать прогресс.
Рассматривайте дальнейшее расследование как работу, а не догадки. Логируйте точную причину (timeout публикации, ошибка авторизации, всплеск бэклога), затем изолируйте источник: сервис очереди, учётные данные, сетевые политики или код потребителя.
Следующие шаги: улучшайте пробы, затем чините корневые причины
Если у вас уже есть эндпойнты здоровья, следующий шаг — сделать их полезными. Хорошие readiness и liveness‑проверки не просто говорят, что процесс запущен. Они ловят реальные поломки рано и не дают сломанным подам обслуживать пользователей.
Выпишите, что должно работать, чтобы пользователь завершил основное действие (войти, оплатить, загрузить, отправить сообщение). Выберите три ключевые зависимости, от которых зависит этот путь. Для каждой добавьте одну проверку, которая доказывает, что приложение действительно может её использовать, а не просто достучаться до хоста.
После этого чините то, что показывают пробы. Если readiness падает из‑за утечки соединений с БД, проба делает своё дело — надо закрывать соединения, настраивать лимиты пула, обрабатывать таймауты и возвращать понятные ошибки. Если проверки очереди падают из‑за накопления сообщений, смотрите на потребителей, логику ретраев и обработку dead‑letter.
Если вы унаследовали AI‑сгенерированный прототип, который «зелёный» на базовых пробах, но ломается под реальным трафиком, полезный аудит поможет. FixMyMess (fixmymess.ai) специализируется на починке AI‑сгенерированных приложений: от слоя аутентификации и секретов до надёжных фоновых задач, часто начиная с бесплатного аудита кода, чтобы показать, что реально ломается в продакшене.
Часто задаваемые вопросы
Почему мой эндпойнт /health говорит OK, хотя пользователи не могут войти или оплатить?
Базовый эндпойнт /health обычно проверяет лишь одно: отвечает ли процесс. Но пользователи всё ещё могут быть заблокированы, если база данных заблокирована, истёкли учётные данные, миграции не применены или очередь зависла. Полезная проверка должна отражать, может ли приложение выполнить минимальную работу, от которой зависят пользователи.
Как проще всего объяснить разницу между readiness и liveness?
Readiness означает «должен ли этот экземпляр получать трафик прямо сейчас?» — и должна проваливаться, когда ключевые зависимости для реальных запросов недоступны. Liveness означает «застрял ли процесс так, что перезапуск может помочь?» — и должна проваливаться только когда приложение перестаёт делать прогресс, а не при кратковременном сбое зависимости.
Что должна делать проверка готовности для базы данных?
Начните с одной маленькой операции по тому же пути, что и приложение — например, выполнить SELECT 1 через обычное соединение с жёстким таймаутом. Это ловит поломки сети, неправильные учётные данные и многие простои БД. Если основной поток требует записей, рассмотрите безопасный сигнал, связанный с записью (например, проверку, что миграции применены), а не только чтение.
Как включить очередь в readiness, не делая пробы тяжёлыми?
Если приложение полагается на фоновые задания, probe только API брокера недостаточно. Проверка готовности должна убедиться, что приложение может опубликовать сообщение (или хотя бы выполнить handshake/проверку прав) с коротким таймаутом. Это часто место, где всё «вверх», но подтверждения, письма или асинхронные операции тихо не выполняются. Держите проверку лёгкой, чтобы не нагружать систему при инцидентах.
Можно ли вызывать базу данных или внешние API из liveness?
Не вызывайте внешние сервисы из liveness — короткие сбои у третьих сторон приведут к перезапускам и усугубят аварию. Liveness должна быть локальной: watchdog‑метка времени, heartbeat цикла событий или «время с последнего завершённого запроса» обычно достаточно. Внешние зависимости отражайте в readiness.
Как выставлять таймауты и ретраи для readiness и liveness?
Используйте жёсткие таймауты, чтобы пробы падали быстро, а кратковременные сбои обрабатывал оркестратор через порог отказов. Это уменьшит трафик проб во время частичных сбоев и не будет скрывать реальные проблемы внутренними ретраями. В целом: лучше быстро стать not‑ready, чем держать полуслепые поды в ротации.
Как остановить флапы readiness, если сторонний API нестабилен?
Частая причина флапа — привязка readiness к ненадёжному стороннему сервису. Позвольте опциям деградировать (например, пометить degraded) вместо жёсткого not‑ready, если это безопасно. И избегайте тому, чтобы пробы выполняли слишком много работы — они не должны превращаться в мини‑нагрузочные тесты.
Что должны возвращать эндпойнты здоровья, когда что‑то не так?
Возвращайте понятный статус‑код (часто 503) и короткий, стабильный код причины вроде db_timeout или queue_auth_failed. Логируйте тот же код один раз за окно отказов, чтобы его можно было искать, не спамя логи. Никогда не включайте stack trace, токены, строки подключения или необработанные исключения в ответ проб.
Может ли приложение быть «деградированным, но работоспособным», и как readiness должен это обрабатывать?
Да — если это осознанный выбор продукта. Можно оставаться ready для только чтения, отключив операции создания, но это требует, чтобы приложение строго применяло те же правила, чтобы пользователи не попадали на сломанные пути. Если вы не можете надёжно разделить «безопасно» и «опасно», выключайте readiness и не принимайте трафик, пока основной путь не восстановится.
Моё приложение сгенерировано AI и ломается в продакшне — вы можете помочь?
AI‑сгенерированные приложения часто «запускаются», но ломаются в продакшне на аутентификации, секретах, миграциях и фоновых задачах — базовые пробы это не ловят. FixMyMess (fixmymess.ai) помогает диагностировать и исправлять такие поломки, включая усиление проб так, чтобы плохие деплои не вредили пользователям молча. Если не знаете, с чего начать, бесплатный код‑аудит быстро покажет реальные точки отказа.