SSRF в AI-сгенерированных приложениях: находите endpoint-ы и укрепляйте fetch
SSRF в AI-сгенерированных приложениях может раскрыть внутренние сервисы. Узнайте, как найти рискованные endpoint-ы для fetch и применить списки разрешённых доменов, проверки DNS/IP и жёсткие настройки запросов.
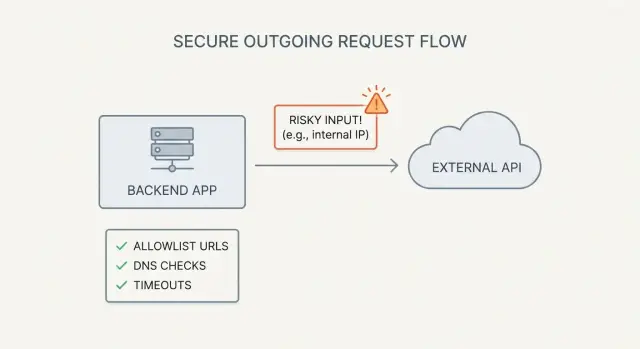
Что такое SSRF (и почему приложения, сгенерированные ИИ, его провоцируют)
SSRF (server-side request forgery) — это ситуация, когда ваше приложение можно обмануть, чтобы оно сделало сетевой запрос по адресу, контролируемому злоумышленником.
Атакующему не нужен доступ к вашим серверам. Ему достаточно любой функциональности, которая принимает URL (или имя хоста) и затем делает fetch с бэкенда.
Простой пример: вы добавили кнопку «Импорт по URL». Браузер отправляет url=https://example.com/data.json в API, и сервер скачивает файл. Если тот же endpoint также примет http://localhost:3000/admin или http://169.254.169.254/ (облачные метаданные), ваш сервер может случайно раскрыть внутренние данные.
Это особенно часто встречается в AI-сгенерированных прототипах. В них часто есть «fetch чего угодно» endpoint-ы (прокси изображений, превью ссылок, тестировщики webhook, генераторы PDF/скриншотов), потому что они делают демо полноценным. Но такие функции часто попадают в релиз без защит, которые делают серверные fetch безопасными.
SSRF опасен потому, что сервер обычно имеет доступ, которого нет у пользователей. Успешная SSRF-атака может:
- Достучаться до внутренних панелей администрирования и сервисов на
localhostили приватных IP - Прочитать облачные метаданные и украсть учётные данные
- Просканировать внутреннюю сеть и найти открытые порты и сервисы
- Обойти правила, основанные на IP (потому что запрос идёт с вашего сервера)
SSRF — это не то же самое, что клиентский запрос из браузера. Если браузер пользователя напрямую загружает URL, это клиентская ситуация. SSRF — это конкретно когда fetch делает ваш бэкенд (или serverless-функция) с доступом вашей сети и вашими секретами.
Где обычно прячется SSRF: какие endpoint-ы проверить
SSRF прячется там, где сервер делает fetch по URL, которым может управлять пользователь. Такие endpoint-ы выглядят безобидно — «просто подтягивают контент», — но ими можно добраться до внутренних сервисов, метаданных облака или других приватных целей.
Начните с перечисления функций продукта, которые принимают URL прямо или косвенно. Частые места: превью ссылок, инструменты «импорт по URL» (CSV/JSON/шаблоны), тестировщики webhook, прокси для файлов и изображений, RSS/фид-ридеры.
Также проверьте админские инструменты. AI-сгенерированные приложения часто включают быстрые «тесты соединения», health-check, которые пингуют зависимости, или экраны настройки интеграций, которые проверяют URL. Они особенно опасны, потому что могут выполняться с повышенным сетевым доступом и обходить обычную валидацию.
Не забывайте про отложенные fetch-запросы. Фоновые задания, очереди и cron-задачи могут сохранить URL сейчас и сделать fetch позже. Такой разрыв усложняет обнаружение уязвимости.
При поиске по коду (и логам запросов) обращайте внимание на имена параметров, которые часто несут URL, даже если звучат невинно: url, callback, avatarUrl, webhookUrl, redirect.
Конкретный пример: настройка «фото профиля по URL» может скачивать изображение сервер-side для изменения размера. Если endpoint принимает avatarUrl без строгих проверок, атакующий может указать внутренний адрес и использовать загрузку изображения как туннель.
Быстрая модель угроз для злоупотребления серверными fetch
Прежде чем править что-либо, чётко определите, к чему пытается добраться атакующий.
Сначала замапьте, что может достичь ваш сервер из своей сети. Обычно это сервисы на localhost (панели админов, debug-порты), приватные диапазоны IP внутри VPC и адреса метаданных облака, которые могут отдать учётные данные. Если приложение работает в контейнере, учтите внутренние имена сервисов и сайдкары.
Далее решите, что надо защищать в первую очередь. Большие «призы» — это секреты и токены (API-ключи, секреты сессий), учётные данные баз данных, внутренние дашборды и любые сервисы, которые доверяют запросам изнутри сети.
Наконец, опишите границы для каждой функции серверного fetch:
- Кто может её инициировать (публично, зарегистрованный пользователь, админ)
- Что ей разрешено запрашивать (конкретные домены или небольшой список партнёров)
- Что никогда не должно быть доступно (localhost, приватные IP, метаданные)
- Для чего используется ответ (сохраняемый файл, парсинг данных, рендер HTML)
Если вы унаследовали прототип от инструментов вроде Bolt или Replit, такая быстрая модель угроз — хорошая первая мера перед углублённым аудитом.
Шаг за шагом: найдите каждый серверный fetch в кодовой базе
SSRF обычно появляется с простой функцией: «скачать этот URL», «импорт по ссылке», «предпросмотр webhook», или «проверить, работает ли сайт». Прежде чем добавлять защиты, вам нужен полный реестр всех мест, где сервер делает исходящие запросы.
1) Охота за исходящими запросами (включая обёртки)
Начните с обычного текстового поиска по репозиторию. Ищите распространённые HTTP-клиенты и вспомогательные хелперы, а не только fetch.
- JavaScript/Node:
fetch,axios,got,superagent,node-fetch - Python:
requests,httpx,urllib,aiohttp - Ruby:
Net::HTTP,Faraday - Обёртки в shell:
curl,wget,exec(,spawn(
Ищите слова, которые часто окружают такие фичи: «webhook», «callback», «import», «download», «proxy», «scrape».
Если приложение сгенерировано инструментами вроде Lovable, Bolt, v0, Cursor или Replit, проверьте хелперы, которые прячут сетевые вызовы за названиями вроде getUrlContent() или scrapePage().
2) Проследите, откуда берётся URL
Для каждой точки вызова идите назад по переменным, пока не дойдёте до источника. Частые источники: поля тела запроса, параметры строки, заголовки, строки в базе данных, переменные окружения и шаблоны, которые комбинируют ввод пользователя с базовым URL.
Обратите внимание на косвенное управление, например пользовательский поддомен, baseUrl на уровне арендатора или ID, который в базе мапится на URL.
3) Проверьте скрытые пути fetch
Уточните, следует ли клиент за редиректами, разрешает ли короткие ссылки или повторные попытки с альтернативными URL. Запрос, который выглядит безопасным, может стать опасным после 302-редиректа на внутренний хост.
4) Подтвердите поведение и задокументируйте его
Инициируйте сбои специально (невалидный домен, таймаут, большой ответ) и посмотрите, что происходит: что логируется, какой текст ошибки возвращается и не отражаются ли данные ответа обратно пользователю.
Задокументируйте каждый endpoint с его входными и выходными данными, требованиями к авторизации и ожидаемыми доменами назначения. Этот реестр станет планом исправления SSRF.
Рабочие allowlist-ы: проверяйте хост, схему и порт
Блок-листы проваливаются, потому что правила для URL сложно учесть, а атакующие настойчивы. Строгий allowlist известных безопасных назначений — самый надёжный вариант, особенно если функция позволяет пользователям импортировать контент по URL.
Разбирайте и нормализуйте URL перед сравнением. Не сравнивайте сырой строкой. Разберите на схему, hostname, порт и путь. Сравнивайте нормализованный хост и эффективный порт (включая значения по умолчанию, например 443 для https).
Практичный поток allowlist-проверки:
- Разберите URL настоящим парсером URL (не регэкспом)
- Требуйте схему https (или http только если действительно необходимо)
- Требуйте наличие hostname (избегайте «голых» IP, если вы их явно не разрешаете)
- Разрешайте только утверждённые порты (обычно 443, иногда 80)
- Сопоставьте hostname с правилами вашего allowlist
Схемы и порты — частые лазейки. Если вы валидируете только домен, забыв про схему, атакующий может попробовать неожиданные обработчики в некоторых окружениях. Если разрешены любые порты, атакующий сможет сканировать внутренние сервисы на нетипичных портах, даже если хост выглядит допустимым.
Поддомены тоже требуют чётких правил. Точное совпадение проще всего (только api.example.com). Если нужны подстановки, ограничьте границу так, чтобы example.com.evil.com не прошло.
Храните allowlist как конфигурацию в одном месте, а не в разбросанном коде. Логируйте, какое правило сработало, чтобы ревью было проще и исключения не застряли незаметно.
DNS-защиты: остановите rebinding и трюки с внутренними IP
DNS rebinding — это простая, но опасная хитрость. Приложение валидирует URL вроде https://example.com/image.png. Это кажется безопасным. Но атакующий контролирует example.com и может изменить то, на что он резолвится после вашей проверки. К моменту подключения хост может указывать на 127.0.0.1 или адрес метаданных облака.
Именно поэтому простых проверок по имени хоста недостаточно.
Более безопасный подход — резолвить хост самостоятельно, проверять каждый возвращённый IP, и подключаться только если все они безопасны.
Что блокировать (IPv4 и IPv6)
Разрешая имя хоста, отвергайте адреса в приватных или специальных диапазонах: приватные сети (RFC1918), IPv6 ULA, loopback (127.0.0.1, ::1), link-local (169.254.0.0/16, fe80::/10), зарезервированные/неопределённые диапазоны (например 0.0.0.0, ::) и формы IPv4-mapped IPv6.
Проверяйте все возвращённые записи, а не только первую. Атакующие часто полагаются на несколько A/AAAA записей, где одна выглядит публичной, а другая — внутренняя.
Повторная проверка ближе к подключению
Если ваш HTTP-клиент это поддерживает, разрешайте и валидируйте прямо перед открытием сокета и избегайте последующих DNS lookup-ов при редиректах. Если вы не контролируете это, минимизируйте время между валидацией и fetch.
Укрепление запроса: таймауты, редиректы и безопасные дефолты
Даже с хорошим allowlist по умолчанию серверные HTTP-клиенты часто остаются слишком либеральными. Цель проста: отваливаться быстро, загружать меньше и никогда не следовать редиректам в места, которые вы не планировали.
Начните с установки строгих ограничений для каждого серверного fetch. Если запрос медленный, большой или непонятный — останавливайте его.
Безопасные дефолты для серверных fetch
Базовая конфигурация, которая хорошо работает на практике:
- Жёсткие таймауты (раздельные для подключения и чтения) и ограничение размера ответа.
- Отключённые редиректы для пользовательских URL, или разрешён только один редирект при условии повторной валидации конечного адреса.
- Разрешать только методы GET (и, возможно, HEAD).
- Срезать чувствительные заголовки. Не прикрепляйте куки, API-ключи или внутренние токены аутентификации к исходящим запросам.
- Логировать короткое резюме (host, path, статус, время). Избегайте логирования полных URL, если в них могут быть секреты.
Типичная ошибка: фича «предпросмотреть этот URL» позволяет редиректы. Атакующий отправляет URL, который 302-редиректит на внутреннюю панель админки или адрес метаданных облака. Ваше приложение следует за редиректом и случайно пересылает заголовок Authorization, используемый для внутренних вызовов.
Ошибки: защищайте пользователей, информируйте инженеров
Когда fetch блокируется или падает, показывайте пользователю общее сообщение (например, «Не удалось получить этот URL»). Подробную причину (таймаут vs редирект vs заблокированный хост) храните только во внутренних логах. Подробные ошибки в UI часто помогают атакующему понять ваши правила валидации.
Распространённые ошибки, которые всё ещё оставляют SSRF открытым
SSRF-ошибки часто переживают «базовые» фиксы. На вид всё защищено, но атакующий всё равно может заставить ваш сервер связаться с внутренними сервисами или метаданными.
Многие команды начинают с простых строковых проверок вроде startsWith('https://'). Это ломается на хитрых URL, необычных кодировках или URL, которые выглядят безопасно, но резолвятся в опасные адреса.
Другие частые промахи:
- Разрешение редиректов без повторной проверки каждого шага
- Валидация хоста, а подключение по другому значению позже
- Блокировка только
127.0.0.1и забывание про IPv6 loopback (::1),0.0.0.0и приватные диапазоны10.*,172.16.*,192.168.* - Пропуск защиты от DNS rebinding (проверили один раз и использовали позже)
Если вы напрямую возвращаете скачанный контент в браузер, появляется вторая проблема: ваш сервер становится прокси. Без строгих лимитов атакующий может подтянуть огромные файлы, чтобы накатать расходы, или прислать неожиданные типы контента, которые фронтенд неправильно обработает.
Краткий чеклист перед релизом для защиты от SSRF
Перед запуском предполагайте, что кто-то попытается превратить любой серверный fetch в туннель.
Инвентаризируйте все места, где пользователь (или другая система) может повлиять на URL, хост или ссылку на удалённый файл. Включите очевидные поля «импорт по URL», а также тестировщики webhook, превью изображений, генераторы PDF, ридеры фидов, «проверить сайт» и интеграции, которые принимают callback URL.
В стейджинге проверьте несколько основ:
- Каждый endpoint и фоновая задача, принимающие URL/hostname, занесены в список.
- Allowlist принудительно применяется сервер-side для каждого fetch (а не только в UI).
- Схема, хост и порт валидируются до выполнения запроса.
- DNS/IP-проверки блокируют внутренние диапазоны для IPv4 и IPv6, и проверка делается близко к подключению.
- Таймауты, лимиты размера ответа и правила редиректов настроены.
Для простых тестов «известно-плохих целей» попробуйте localhost, приватный IP, внутреннее имя хоста и распространённый адрес облачных метаданных. Цель — не эксплуатировать ничего, а убедиться, что приложение отказывает в запросе и не сливает подробную информацию об ошибке.
Пример: безопасное исправление функции «импорт по URL»
Типичный паттерн — удобная функция «Импорт аватара по URL». Генератор добавляет бэкенд-эндпоинт, который принимает URL, скачивает изображение сервер-side и сохраняет его.
Сценарий эксплуатации предсказуем. Атакующий подаёт URL, который вовсе не с хостинга изображений, а внутренний адрес: сервис метаданных, приватная админка или HTTP-порт базы данных, доступный только внутри сети. Если сервер скачивает это, атакующий может узнать секреты, внутренние имена хостов или получить HTML, если вы сохраняете или показываете ответ.
Сделайте fetch скучным и строгим:
- Разрешайте только конкретные хосты изображений, которыми вы управляете или которым доверяете.
- Требуйте https и блокируйте нестандартные порты.
- Резолвьте DNS сами и блокируйте приватные, loopback и link-local IP до подключения.
- Отключите редиректы или разрешите только один редирект с повторной валидацией.
- Установите жёсткие таймауты и небольшой max download size; проверьте content-type и magic bytes.
Добавьте мониторинг, чтобы замечать попытки разведки. Обычно это множество неудачных запросов по разным хостам, повторные попытки попасть на 169.254.169.254 или localhost, или всплески заблокированных DNS/редиректов.
Следующие шаги: сократите поверхность атаки и проведите сфокусированное ревью
Если вы нашли хотя бы один серверный fetch, который может обратиться к URL, предоставленному пользователем, предполагайте, что их больше. Быстрое уменьшение риска — сократить поверхность.
Решите, какие функции fetch вам действительно нужны. Многие приложения выпускаются с лишним набором: «импорт по URL», «превью ссылок», «fetch Open Graph», «тестировщик webhook», «прокси изображений» или «подключение к любому API». Каждая такая функция — потенциальная точка входа для SSRF. Если фича не критична, удаление её часто безопаснее, чем вечное укрепление.
Затем установите несколько правил для каждого серверного fetch:
- Разрешены только утверждённые схемы, порты и хосты (никаких «любой URL»).
- DNS и IP-проверки делаются в момент запроса, а не только однажды при валидации.
- Таймауты, лимиты размера ответа и ограничения редиректов всегда включены.
- Fetch централизован в одном хелпере, чтобы новые endpoint-ы не могли обойти защиту.
Если нужен быстрый внешний чек для AI-сгенерированной кодовой базы, FixMyMess (fixmymess.ai) делает диагностику кода и усиление безопасности прототипов, созданных инструментами вроде Lovable, Bolt, v0, Cursor и Replit. Они также предлагают бесплатный аудит кода, чтобы быстро выявить риски fetch и другие критичные проблемы перед релизом.
Часто задаваемые вопросы
Что такое SSRF простыми словами?
SSRF — это когда ваш бэкенд (или serverless-функция) можно обмануть, чтобы он загрузил URL, которым управляет злоумышленник. Поскольку запрос идёт от вашего сервера, он может достичь внутренних сервисов, приватных IP-адресов или облачных метаданных, недоступных обычному пользователю.
Почему в приложениях, созданных ИИ, часто встречаются ошибки SSRF?
AI-сгенерированные прототипы часто добавляют «удобные» функции, которые выполняют серверные запросы по URL: превью ссылок, прокси для изображений, импорт по URL, тестировщики webhook, генераторы скриншотов/PDF. Такие фичи работают в демо, но обычно поставляются без строгих allowlist-ов, проверок DNS/IP и контроля редиректов.
Какие endpoint-ы стоит проверить в первую очередь на SSRF?
Ищите любые endpoint-ы или задания, которые принимают параметры вроде url, webhookUrl, callback, avatarUrl, redirect или адрес для «тестирования интеграции». Также проверьте фоновые воркеры и cron-задачи, которые сохраняют URL для последующего запроса — SSRF может скрываться вне обычных HTTP-путей.
Как найти все серверные fetch-запросы в кодовой базе?
Начните с инвентаризации всех исходящих запросов: ищите вызовы HTTP-клиентов (fetch/axios/requests и т. п.) и внутренние обёртки. Для каждого места проследите, откуда берётся URL, и проверьте, может ли пользователь прямо или косвенно его контролировать (через базу данных, настройки клиента и т. п.).
Стоит ли использовать allowlist или blocklist для предотвращения SSRF?
По умолчанию используйте allowlist — точные домены, которые вы ожидаете. Разберите URL парсером (не регуляркой), требуйте https и разрешайте только безопасные порты (обычно 443, иногда 80), чтобы атакующий не смог через нестандартный порт дотянуться до внутренних сервисов.
Как защититься от DNS rebinding и приёмов типа «указывает на localhost»?
Поскольку DNS может измениться после проверки имени хоста, разрешайте имя сами, проверьте все возвращаемые IP и отклоняйте приватные, loopback, link-local и другие специальные диапазоны для IPv4 и IPv6. Проводите эту проверку как можно ближе к моменту открытия сокета.
Какие безопасные дефолты для серверных HTTP-запросов?
Ужесточите таймауты, ограничьте максимальный размер ответа и относитесь к редиректам как к опасности для пользовательских URL. Самый безопасный вариант — не следовать редиректам; если редиректы разрешены, после каждого хопа нужно снова валидировать конечный адрес и никогда не пересылать внутренняя авторизационные заголовки или куки.
Какие распространённые «правки» SSRF всё ещё оставляют уязвимость?
Простые строковые проверки вроде startsWith('https://') и «заблокировать localhost» пропускают обходы: IPv6-loopback, приватные диапазоны, редиректы и изменения DNS между проверкой и подключением. Также опасно валидировать один хост, а подключаться к другому, полученному позже.
Как быстро проверить, работают ли мои защиты от SSRF?
Пробуйте известные плохие цели: localhost, приватные IP-диапазоны и распространённый адрес облачных метаданных. Убедитесь, что приложение блокирует их и не выдаёт в UI детализированных причин отказа. Также тестируйте поведение при редиректах и проверьте, что финальный адрес снова проходит валидацию.
Могут ли FixMyMess помочь укрепить AI-сгенерированную кодовую базу от SSRF?
Если ваше приложение сгенерировано с помощью Lovable, Bolt, v0, Cursor или Replit, часто пропускают какую-нибудь скрытую точку fetch или фоновую задачу. FixMyMess (fixmymess.ai) проводит бесплатный аудит кода, инвентаризирует серверные fetch-запросы и помогает укрепить код (allowlist, проверки DNS/IP, правила редиректов, таймауты) для быстрого выхода в продакшен.