Стратегия повторных попыток для фоновых задач: backoff, лимиты, оповещения
Стратегия повторных попыток для фоновых задач: добавьте backoff, лимиты попыток, dead‑letter очередь и оповещения, чтобы сбои были видимы и безопасно восстанавливались.
Почему «оно не выполнилось» — опасный способ находить ошибки
Фоновые задачи — это мелкие операции, которые приложение выполняет в фоне, чтобы основной продукт оставался быстрым. Они отправляют письма, импортируют CSV, синхронизируют данные, обрабатывают платежи и доставляют вебхуки. Пользователи редко видят саму задачу. Они замечают только результат.
Именно поэтому самая распространённая ситуация выглядит так: в тестах всё работало, а в проде всё тихо перестало работать. Никто не видит страницу с ошибкой. Ничто явно не падает. Вы узнаёте об этом через дни, когда клиент скажет: «я не получил письмо», или всплывёт недостающий экспорт.
Тихие сбои хуже видимых: они подрывают доверие и при этом скрывают причину. Видимые сбои вынуждают реагировать. Тихие создают накопление невыполненных обещаний: непросланные письма, несинхронизированные данные, застрявший онбординг, непроставленные возвраты. К тому моменту, когда вы заметите проблему, вы будете исправлять задачу и убирать за ней последствия.
Хороший план retry — это не «пытаемся снова вечно». Он должен делать четыре вещи:
- Восстанавливаться от временных проблем (таймауты, краткие простои, лимиты запросов).
- Убавлять нагрузку в пиковые моменты, чтобы не добивать базу или внешний API.
- Останавливаться после разумного числа попыток.
- Делать провалы очевидными, чтобы человек мог вмешаться.
Если почтовый провайдер возвращает временный 503, попытка позже имеет смысл. Но если задача падает из‑за неверной переменной шаблона или сломанной аутентификации, повторы просто тратят время и деньги, пока никто не чинит проблему.
Это часто проявляется в AI‑сгенерированных прототипах. Приложение «в целом работает», а фоновые задачи тихо падают из‑за отсутствующих секретов, шаткой обработки ошибок или запутанной логики задач. Первый шаг — сделать провалы громкими, ограниченными и восстанавливаемыми.
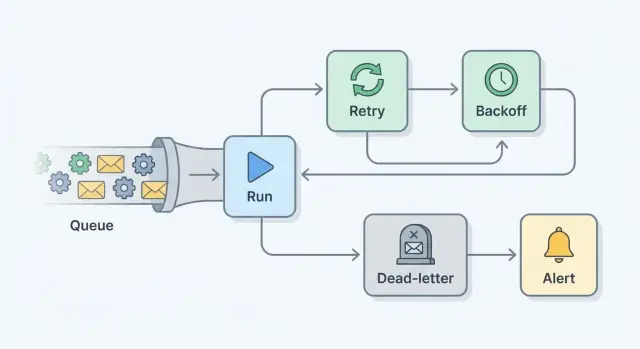
Основные элементы: ретраи, backoff, максимум попыток, dead-letter, оповещения
План повторов — это набор небольших ограждений, который превращает тихие сбои в видимую и восстанавливаемую работу.
Retry — это повторный запуск той же задачи после падения. Он помогает при временных ошибках, например при нестабильном сетевом вызове.
Backoff — пауза между попытками. Вместо мгновенных повторов (и формирования «громового стада») вы увеличиваете ожидание при каждой попытке, часто с небольшой случайной составляющей.
Max attempts — жёсткий предел. После N попыток вы останавливаетесь, чтобы одна плохая задача не вкручивалась в бесконечный цикл.
Dead-letter queue (DLQ) (или таблица неудачных задач) — место, куда попадают задачи после того, как вы сдались. Ничего не теряется. Вы можете посмотреть, что произошло, исправить причину и запустить задачу намеренно.
Оповещения — это то, как люди узнают о проблеме. Цель — не уведомлять при каждом ретрае, а уведомлять, когда нужна человеческая помощь: например, когда задача достигла max attempts или объём DLQ начал расти.
Идея, которая экономит много боли: идемпотентность
Задача идемпотентна, если её безопасно запустить дважды.
«Установить статус счёта PAID» безопаснее, чем «списать деньги с карты». Если действие нельзя сделать полностью идемпотентным, добавьте защиту: уникальный ключ, флаг «уже обработано» или idempotency‑токен провайдера.
Временные и постоянные ошибки
Временные ошибки обычно проходят сами: таймауты, кратковременные простои, заблокированные строки. Постоянные ошибки так не пройдут: отсутствующие записи, неверные адреса электронной почты, неправильный API‑ключ.
Повторы уменьшают количество инцидентов, но не устраняют все ошибки. Цель — ограничить радиус поражения, быстро вывести на поверхность реальные проблемы и дать безопасное место (DLQ) для восстановления.
Знайте, что вы ретраите: временные или постоянные ошибки
План ретраев начинается с одного решения: эта ошибка, скорее всего, исчезнет сама или будет падать каждый раз, пока кто‑то не исправит что‑то вручную? Если вы пытаетесь всё подряд, вы получите шумные очереди, большие счета и задержки, которые скрывают настоящую проблему.
Временные ошибки поддаются retry (с backoff), потому что окружение меняется: сеть восстанавливается, сервисы оживают, блокировка снимается, окно лимита сбрасывается.
Постоянные ошибки не исправятся сами. Их повторение просто тратит время в то время, как пользователи ждут. Это обычно проблемы с данными, правами, миграциями или баги.
Ошибочная классификация опасна. Если считать постоянную ошибку временной, вы можете накопить очередь, которая блокирует нормальную работу, и инциденты будут сложнее заметить, потому что система выглядит «занятой», а не «сломана».
Простое правило: ретрайте только тогда, когда вы можете назвать реалистичное условие, которое изменится без вмешательства человека. Если задача, вероятно, удастся при повторном запуске через 1–10 минут, её можно ретраить. Если завтра она упадёт так же, остановите повторы, отправьте в DLQ и оповестите.
Backoff, который ведёт себя хорошо под нагрузкой
Когда задача падает, худшее, что можно сделать — немедленно ретраить в tight loop. Если причина — частичный аут (partial outage), лимит запросов или медленная БД, мгновенные повторы добавляют нагрузку в тот момент, когда система и так борется.
Экспоненциальный backoff — здоровая отправная точка: каждая следующая попытка ждёт дольше. Простой пример: 5 секунд, 15 секунд, 45 секунд, 2 минуты, затем 5 минут.
Добавьте jitter (слегкаe случайное отклонение) к каждой задержке. Без него воркеры, упавшие вместе, будут повторяться одновременно и создавать новый всплеск. С jitter 2‑минутная пауза может стать 1:30–2:30, что сглаживает нагрузку.
Backoff должен соответствовать задаче. Письмо для сброса пароля и ночной отчёт не нуждаются в одинаковом темпе. Как отправная точка: пользовательские задачи можно ретраить быстрее с небольшим лимитом, тяжёлые задачи и жёсткие внешние API требуют больших капов и jitter при каждой попытке.
Установите максимум попыток и ясные условия остановки
Неограниченные повторы кажутся безопасными, но они могут превратить одну ошибку в вечный цикл. Задача продолжает выполняться, накапливает время в очереди и расходы на API, и скрывает реальный баг, потому что ничего не становится «финальным» провалом.
Есть и практический риск: многократные повторы могут навредить. Вы можете отправить одно и то же письмо много раз, создать дубли записей или списать деньги дважды, если задача не идемпотентна.
Выбирайте max attempts, исходя из последствий. Для рискованных действий, вроде платежей, лучше быстрый финал (часто 1–3 попытки). Для безопасных уведомлений можно позволить больше попыток. Для медленных внешних API допустимы большие количества попыток, но при консервативном backoff.
Добавьте также общий лимит по времени, а не только по счёту. Например: «до 5 попыток, но не дольше 2 часов». Это не даст задаче тянуться днями.
Когда задача достигает max attempts, относитесь к этому как к реальному событию. Запишите достаточно данных для отладки и повторного безопасного запуска: последняя ошибка, тип ошибки, временные метки попыток и полезная нагрузка (или её редактированная версия). Захватите внешние идентификаторы (user_id, order_id), которые помогут связать с логами.
Используйте dead-letter queue, чтобы провалы были восстанавливаемы
Повторы нужны для временных проблем. Некоторые задачи никогда не пройдут без изменений. DLQ — безопасное место для таких задач после достижения max attempts: они перестают жечь ресурсы и становятся видимыми для человека.
Думайте о DLQ как о «входящих, требующих внимания». Вместо потери работы или бесконечных повторов вы сохраняете достаточно деталей для диагностики, исправляете причину и целенаправленно перезапускаете задачу.
Что хранить в записи DLQ
Запись в DLQ должна отвечать на два вопроса: что пыталась сделать задача и почему она провалилась?
Держите запись компактной, но полной: имя задачи (и версию, если есть), входные данные (или ссылку, если они большие), сообщение и тип ошибки (и стек‑трэйс, если доступен), счётчик попыток с временными метками и корреляционные ID (user ID, order ID, request ID) для привязки к логам.
Будьте осторожны с секретами. Если payload может содержать токены или пароли, редактируйте их перед сохранением.
Как безопасно поставить в очередь снова
Реинкью должно быть осознанным действием, а не автоматическим циклом. Исправьте корень проблемы, затем запустите задачу из админки или небольшим скриптом.
Добавьте минимальный аудит: при повторной постановке сбросьте счётчик попыток и зафиксируйте, кто и зачем это сделал. Если входные данные никогда не пройдут валидацию, дайте возможность пометить запись как «не будем пытаться» с короткой заметкой.
Также важна длительность хранения. Храните элементы DLQ достаточно долго, чтобы заметить паттерны и обработать медленные исправления, но не так долго, чтобы чувствительные данные висели без нужды.
Оповещения, которые полезны, а не шумны
Оповещения должны быстро ответить на вопрос: «Что сломалось, кого это затрагивает и что делать дальше?» Если сбои остаются скрытыми часами, вы узнаете о них от клиента.
Начните с триггеров, которые действительно болят, а не с каждого неудачного запуска. Полезные сигналы: повторяющиеся падения одного типа задач, рост числа сообщений в DLQ, долгое время ожидания в очереди (когда задачи ждут дольше обещанного пользователю), резкие падения throughput или всплески ошибок для конкретной задачи.
Направляйте оповещения тем, кто может действовать. В ранних командах это часто on‑call инженер или основатель. Давайте достаточно контекста, чтобы не тратить 20 минут на расследование: имя задачи, окружение, время первого и последнего падения, последние сообщения об ошибке, сколько задач затронуто и попадают ли они в DLQ.
Чтобы избежать шума, используйте три контроля: пороги (уведомлять после N ошибок), группировку (одно оповещение на тип задачи за временное окно) и окно охлаждения (не предупреждать повторно 15 минут, если только ситуация не ухудшается).
Если нужна эскалация, держите её простой: сначала основной on‑call, затем резерв через короткую задержку, и затем более широкий канал с суммарным отчётом влияния, если ситуация продолжает расти.
Сделайте провалы видимыми с помощью логов и простых метрик
План ретраев работает только если вы видите, что происходит. Иначе вы получите прежний отчёт: «задача не выполнилась». Цель простая: каждая попытка оставляет чёткий след, а несколько базовых чисел показывают, ухудшается ли ситуация.
Для логов используйте консистентные поля, чтобы одно падение было легко отследить через все попытки. Каждая попытка должна содержать job ID (или correlation ID), номер попытки, время начала и окончания, и результат. При ошибке логируйте класс ошибки (timeout, auth, validation) и короткое сообщение. Полезно указывать очередь и имя воркера.
Храните логи безопасно. Не логируйте токены, пароли, ключи API, полные заголовки запросов или необработанные персональные данные. Используйте внутренние ID или маскированные значения.
Для метрик не нужно много: отслеживайте процент успешных задач по типу, повторы на задачу (среднее и p95), количество и скорость DLQ, и время до успеха (сколько времени задачи проводят в ретраях).
Во время инцидента небольшая дашборда должна ответить: растёт ли DLQ, одна ли задача даёт большинство повторов, и начались ли ошибки в конкретное время (подсказка на деплой или внешний аут).
Пример: задача отправки письма, которая падает, затем восстанавливается безопасно
Типичная задача — отправить приветственное письмо после регистрации. Недели всё работает, затем саппорт сообщает: «некоторые пользователи не получили письмо». Если вы смотрите только «оно не выполнилось», вы пропустите реальную историю: задача выполнилась, упала и пропала.
Что происходит, когда начинаются падения
В 9:02 задача пытается отправить письмо, но провайдер таймаутит. Это временно, поэтому воркер ретраит с экспоненциальным backoff: ждёт 30 секунд, затем 2 минуты, затем 10 минут. Backoff уменьшает нагрузку на провайдера и вашу систему.
На 5‑й попытке всё ещё неудача. Задача достигает max attempts и останавливается. Вместо того, чтобы потеряться, она приходит в DLQ с полезными деталями: user ID, тип письма (onboarding), последняя ошибка, количество попыток и когда начались сбои.
Поступает одно оповещение, а не 50: «OnboardingEmailJob: 12 сообщений в DLQ за последние 15 минут. Топ ошибка: timeout.» On‑call видит, что это реальная растущая проблема и нужно действовать.
Как вы чините и безопасно переотправляете
В расследовании вы находите причину: API‑ключ был ротирован, а воркер всё ещё использует старый секрет. Это типично для ранних кодовых баз, где секреты захардкожены или загружаются непоследовательно.
После обновления секрета и деплоя вы перекидываете сообщения из DLQ в очередь. Перед закрытием инцидента вы убеждаетесь, что DLQ уменьшается, новые регистрации получают письма в нормальное время, оповещения очищаются и не возвращаются в течение полного окна ретраев, а логи показывают успешные отправки без повторяющихся таймаутов.
Сбой стал видимым, ограниченным и восстанавливаемым — и ни один пользователь не остался незамеченным.
Частые ошибки, приводящие к повторным инцидентам
Повторные инциденты обычно не «неповезло». Они происходят из нескольких паттернов, которые превращают небольшую ошибку в накопление задач.
Одна из самых больших ошибок — ретрай задачи, которая не идемпотентна. Если «запустить дважды» значит «списать дважды» или «отправить два письма», повторы создают проблемы для клиентов даже при мелкой первоначальной ошибке. Добавьте уникальный ключ запроса, проверяйте текущее состояние перед действием и записывайте результат, чтобы второй запуск становился no‑op.
Другой капкан — ловить все ошибки и ретраить бесконечно. Это кажется безопасным, но скрывает реальные баги (плохие данные, сломанная логика, отсутствующие права) и ест ресурсы.
Чаще всего боль вызывают:
- Отсутствие max attempts или стоп‑условия, поэтому сбои крутятся до тех пор, пока кто‑то не заметит.
- Отсутствие DLQ (или эквивалента), поэтому нельзя просмотреть и восстановить неудачные задачи.
- Оповещения, за которыми никто не отвечает, или такие шумные, что их отключают.
- Секреты или персональные данные в payload и логах, превращающие отладку в проблему безопасности.
- Ручные перезапуски без понимания того, что уже успешно выполнилось, создающие дубликаты.
Реалистичный пример: задача по получению квитанции об оплате таймаутится после успешного списания, затем повторы отправляют две квитанции. Спустя недели кто‑то перезапускает пакет «на всякий случай» и клиенты получают спам.
Короткий чеклист перед запуском в продакшен
Перед включением нового воркера или очереди в проде решите, как выглядит «безопасный сбой».
- Определите, какие ошибки повторяемы (таймауты, 503, лимиты) и какие должны падать быстро (плохие данные, отсутствующие записи, ошибки прав).
- Используйте backoff с jitter и разумным пределом, чтобы при ауте не образовалась огромная стопка ретраев.
- Установите max attempts и лимит по времени (например, «остановиться после 10 минут»), затем помечайте как упавшую.
- Включите DLQ (или таблицу неудачных задач) и убедитесь, что можно безопасно переотправить задачу без дубликатов.
- Сделайте провалы наблюдаемыми: логируйте job ID, номер попытки, имя очереди, сообщение об ошибке и безопасный контекст (внутренние ID, а не секреты).
Потом протестируйте весь цикл один раз. Выберите задачу (например, отправку чека), вызовите одно временное падение (верните поддельный 502 один раз) и подтвердите, что она ретраится с ожидаемой задержкой, проходит при следующей попытке и отправляет ровно одно письмо.
Следующие шаги: улучшите одну задачу, затем масштабируйте паттерн
Выберите одну задачу, которая важна каждый день и причиняет боль при падении. Хорошие кандидаты: отправка чеков, синхронизация платежей или выставление счетов. Если вы научитесь делать одну задачу безопасно падать, автоматически восстанавливаться и оповещать, когда это невозможно — у вас будет шаблон для повторного использования.
Начните с малого: классифицируйте ошибки и ретрайте только временные. Добавьте backoff, лимит попыток и путь в DLQ для всего, что всё ещё падает. Добавьте одно действенное оповещение, когда задача достигает max attempts или попадает в DLQ. Оставьте одну понятную строку лога на попытку с job ID, номером попытки и последней ошибкой.
Если у вас унаследован AI‑сгенерированный код, где воркеры «иногда падают», не бросайтесь на большие рефакторинги. Сначала оберните задачи ограждениями (учёт попыток, backoff, условия остановки), а затем чистите логику, когда провалы станут видимыми.
Если вы не уверены безопасно менять код, FixMyMess (fixmymess.ai) может провести бесплатный аудит кода, выявить проблемы в логике задач, retry, обработке секретов и готовности к продакшену, а затем поставить проверенные исправления, готовые к деплою, часто за 48–72 часа.
Часто задаваемые вопросы
Что такое «тихий сбой» в фоновой задаче?
Тихие сбои происходят, когда задача выполняется в фоне, падает, и никто этого не замечает. Пользователи видят только отсутствующий результат, например не пришёл чек на почту или экспорт так и не появился.
Какой хороший план повторных попыток по умолчанию для большинства фоновых задач?
Не пытайтесь повторять бесконечно по умолчанию. Повторяйте только те ошибки, которые, вероятно, скоро пройдут, добавьте backoff, чтобы не перегружать систему, остановитесь после фиксированного лимита и сделайте финальное падение видимым, чтобы человек мог исправить причину.
Как отличить временные ошибки от постоянных?
Временные ошибки — это то, что может разрешиться без изменения кода или данных: таймауты, кратковременные простои, лимиты запросов или блокировки в БД. Постоянные ошибки — это плохие данные, отсутствующие записи, неверные креденшалы или баги; их повторение только оттягивает реальное исправление.
Почему использовать экспоненциальный backoff и jitter вместо немедленных повторов?
Экспоненциальный backoff распределяет повторные попытки всё дальше во времени, что снижает нагрузку на слабые компоненты. Добавьте jitter — небольшую случайность — чтобы параллельные воркеры не ретраились одновременно и не создавали новые всплески.
Почему бесконечные повторы — плохая идея?
Бесконечные повторы скрывают реальные баги и накапливают время в очереди, расходы на API и дублирующие побочные эффекты. Лимит попыток создаёт момент «это требует внимания» и не даёт одной сломанной задаче блокировать всю систему.
Сколько попыток стоит разрешать и как долго пытаться?
Опирайтесь на риск и влияние. Высокоопасные операции (платежи) должны падать быстро (часто 1–3 попытки). Уведомления низкого риска могут позволить больше попыток, но всегда с общим лимитом по времени, чтобы не ретрайить днями.
Что такое dead-letter queue и зачем она нужна?
Очередь dead-letter (DLQ) — это место, куда попадает задача после достижения максимума попыток. Она сохраняет контекст для отладки и позволяет сознательно заново поставить задачу в очередь после исправления причины.
Как безопасно поставить неудавшиеся задачи обратно в очередь, чтобы не получить дубликаты?
Повторяйте только после того, как устранили причину сбоя, и убедитесь, что задача не создаст дубликатов при повторном запуске. Записывайте, кто и зачем перезапустил задачу, и избегайте повторов для задач с входными данными, которые никогда не пройдут валидацию.
Что значит «идемпотентная задача» и когда это важно?
Идемпотентность означает, что повторный запуск задачи не создаст второго чека, второй почты или дубля записи. Старайтесь работать через «установить состояние», добавляйте уникальный ключ или idempotency-токен провайдера, чтобы повторы становились no‑op.
На что нужно оповещать и что логировать для фоновых задач?
Оповещайте в тот момент, когда задача требует действий, например при достижении max attempts или росте DLQ, а не при каждой попытке. Логируйте каждую попытку с job ID и типом ошибки, и отслеживайте простые метрики: рост DLQ, частота повторов и процент успешных выполнений.