Структурированное логирование для 5‑минутной отладки в продакшене
Структурированное логирование упрощает быстрое воспроизведение багов в продакшене. Добавьте идентификаторы запросов, обработчики ошибок в UI и готовые шаблоны логов, чтобы отладка занимала 5 минут.
Почему баги в продакшене кажутся невозможными для воспроизведения
Часто отчет о баге в продакшене выглядит так: «Потом сломалось, когда я нажал кнопку». Нет скриншота, нет точного времени, нет ID пользователя и нет подсказки, какое устройство или браузер использовались. Когда вы пытаетесь повторить — у вас всё работает.
Продакшен — это беспорядок, потому что точные условия трудно воссоздать. У реальных пользователей разные аккаунты, разные данные, нестабильные сети, открыты несколько вкладок и устаревшие сессии. Одна редкая проблема синхронизации может привести к падению, которого вы никогда не увидите в стейджинге.
Консольные принты и расплывчатые сообщения об ошибках в таком окружении не выдерживают проверки. Консоль пользователя — не ваша консоль, и даже если вы собираете логи, «что‑то сломалось» не говорит, какой запрос, какой флаг фичи или какой внешний сервис это вызвал. Хуже того, одна необработанная ошибка может остановить приложение до того, как будет записана та самая деталь, которая вам нужна.
Цель проста: когда приходит репорт, вы должны за минуты ответить на три вопроса:
- Что произошло (событие и действие пользователя)
- Где это произошло (точный запрос, страница и компонент)
- Почему это произошло (ошибка и важный контекст)
Именно поэтому важно структурированное логирование. Вместо случайных предложений вы логируете одинаковые события с одинаковыми полями каждый раз, чтобы фильтровать и прослеживать историю через сервисы и экраны.
Не требуется большой рефакторинг, чтобы к этому прийти. Небольшие изменения быстро складываются: добавьте идентификатор запроса в каждый запрос, включайте его в каждую строку лога и перехватывайте падения UI с помощью error boundaries, чтобы сохранить контекст при сбое интерфейса.
Вот реалистичный пример. Основатель говорит: «Оформление заказа иногда крутится вечно». Без нормальных логов вы догадываетесь: провайдер платежей? база? авторизация? С request ID и согласованными событиями вы ищете по одному ID и видите: checkout_started, payment_intent_created, затем таймаут на inventory_reserve, и потом ошибка в UI. У вас появляется один путь, который можно воспроизвести.
Если вы унаследовали AI‑сгенерированное приложение, где логи случайны или отсутствуют, это обычно одно из самых выгодных исправлений. Команды вроде FixMyMess часто начинают с быстрого аудита того, что уже трассируется, и добавляют минимальное логирование, чтобы следующая ошибка занимала 5 минут вместо недели догадок.
Что такое структурированные логи, простыми словами
Простые текстовые логи — это то, что вы, вероятно, видели: предложение в консоли типа «User login failed». Их легко писать, но сложно использовать в продакшене. У каждого своё формулирование, детали пропускаются, и поиск превращается в угадывание.
Структурированное логирование означает, что каждая строка лога имеет одинаковую форму и включает ключевые детали как именованные поля (часто в JSON). Вместо предложения вы записываете событие и контекст вокруг него. Так вы можете фильтровать, группировать и сравнивать логи как данные.
Хороший лог должен отвечать на несколько базовых вопросов:
- Кто пострадал (какой пользователь или аккаунт)
- Что случилось (действие или событие)
- Где это произошло (сервис, маршрут, экран, функция)
- Когда это произошло (временная метка обычно добавляется автоматически)
- Результат (успех или ошибка, и почему)
Вот разница на практике.
Plain‑text (трудно искать):
Login failed for user
Structured (легко фильтровать и группировать):
{
"level": "warn",
"event": "auth.login",
"userId": "u_123",
"requestId": "req_8f31",
"route": "/api/login",
"status": 401,
"error": "INVALID_PASSWORD"
}
Самые полезные поля обычно — скучные вещи, которые вы захотите иметь позже: event, userId (или account/team ID), requestId и status. Если вы добавите только четыре поля, начните с них. Они позволяют ответить: «Какой именно запрос попал от этого пользователя и что вернуло приложение?»
Структура — вот что ускоряет отладку в продакшене. Вы можете быстро найти все event = auth.login сбоев, сгруппировать по status или получить все логи с requestId = req_8f31, чтобы увидеть полную историю одной проблемы. Это отличает 30‑минутный скроллинг от поиска проблемы за 5 минут.
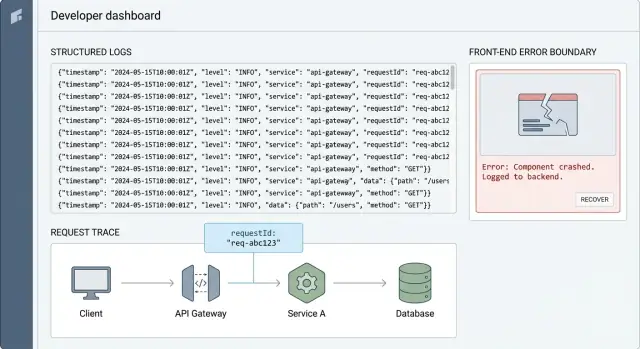
Request ID: самый быстрый путь проследить одну проблему пользователя
Request ID — это короткая уникальная строка (например, req_7f3a...), которую вы прикрепляете к одному действию пользователя. Смысл прост: она связывает всё, что случилось для этого действия — от клика на фронтенде до API и запроса к базе.
Без неё отладка в продакшене превращается в угадайку. Вы ищете по времени, пользователю или эндпоинту и всё равно получаете кучу несвязанных сообщений. С request ID вы сужаете поиск до одной истории и читаете её по порядку.
Это и есть корреляция: один и тот же ID появляется во всех строках лога, которые относятся к одному запросу. Это клей, который делает структурированное логирование действительно полезным под давлением.
Где нужно создавать request ID
Создавайте ID как можно раньше и передавайте через все слои.
- На границе (CDN / load balancer) или в API‑шлюзе, если он есть
- Иначе — в точке входа бэкенда (первое middleware, обрабатывающее запрос)
- Если ни того, ни другого нет (часто в AI‑прототипах), создавайте его в обработчике сервера до любой другой работы
После создания возвращайте его клиенту в заголовке ответа. Когда пользователь сообщает «Сломалось», вы можете попросить этот ID или показывать его в интерфейсе поддержки.
Когда переиспользовать, а когда генерировать новый ID
Повторно используйте тот же request ID на протяжении всего запроса, включая внутренние вызовы, которые он инициирует. Если ваш API вызывает другой сервис, передавайте ID дальше, чтобы след оставался непрерывен.
Генерируйте новый ID, когда вы больше не обрабатываете тот же запрос:
- Ретраи: сохраняйте оригинальный ID как parent, но давайте каждой попытке свой attempt ID (чтобы видеть повторяющиеся ошибки)
- Фоновые задания: создавайте новый job ID и сохраняйте оригинальный request ID как «trigger», чтобы связать задачу с действием пользователя
Простой пример: пользователь нажал «Pay» и получил ошибку. Фронтенд логирует requestId=abc123, API логирует тот же abc123 с маршрутом и ID пользователя, а уровень базы данных логирует abc123 рядом с запросом и временем. Когда платеж падает, вы поднимаете abc123 и видите, где именно всё сломалось — обычно это занимает минуты.
Как добавить request ID от края до края (шаг за шагом)
Request ID — короткое уникальное значение, которое следует за действием пользователя по системе. Когда поддержка говорит «платёж упал в 14:14», request ID позволяет за секунды собрать все связанные строки логов.
Пошаговая настройка
Используйте один и тот же базовый шаблон в любой стеке:
- Создайте (или примите) request ID на краю сервера. Если клиент уже присылает его (часто в
X-Request-Id), оставьте. Если нет — генерируйте при входе запроса в API. - Сохраните его в контексте запроса, чтобы он был в каждом логе. Положите туда, где код сможет читать без передачи через каждую функцию. Многие фреймворки имеют local request storage. Если нет — прикрепите к объекту запроса.
- Верните его клиенту в заголовке ответа. Добавьте заголовок
X-Request-Id. Это даст поддержке и пользователям что‑то, что можно скопировать. - Пробрасывайте его во всё downstream. Добавляйте тот же заголовок во внешние HTTP‑вызовы, включайте в полезную нагрузку очередей/джобов и передавайте в обёртки базы данных, чтобы медленные запросы можно было связать с тем же запросом.
- Включайте его в отчёты об ошибках (опционально). При захвате исключений прикрепляйте
requestId, чтобы краш‑репорты и логи совпадали. Для ошибок, видимых пользователю, можно показывать короткий «код поддержки», производный от request ID.
Вот простой пример на Node/Express‑стиле. Идея та же в других языках:
import crypto from "crypto";
app.use((req, res, next) => {
const incoming = req.header("X-Request-Id");
req.requestId = incoming || crypto.randomUUID();
res.setHeader("X-Request-Id", req.requestId);
next();
});
function log(req, level, message, extra = {}) {
console.log(JSON.stringify({
level,
message,
requestId: req.requestId,
...extra
}));
}
После этого ваше структурированное логирование становится сразу полезнее: каждое событие можно искать по requestId, даже если проблема перескакивает между сервисами.
Если вы унаследовали AI‑сгенерированное приложение, где логи — случайные строки (или их вообще нет), добавление request ID — одно из самых быстрых исправлений, потому что это улучшает отладку без изменения бизнес‑логики.
Проектирование событий логов, которые действительно можно искать
Хорошие логи читаются как таймлайн. Когда что‑то ломается, вы должны понять: что случилось, к какому запросу и какое решение принял код.
В структурированном логировании это означает, что каждая строка — маленькая запись с теми же полями каждый раз, а не свободная фраза. Последовательность — то, что делает поиск работоспособным.
Начните с небольшого набора имён событий
Выберите несколько ключевых типов событий и переиспользуйте их по всему приложению. Не придумывайте новое имя для одной и той же вещи каждую неделю.
Вот распространённые типы событий, которые остаются полезными со временем:
- request_started
- request_finished
- db_query
- auth_failed
- error
Называйте события в lowercase с подчёркиваниями и держите смысл стабильным. Например, если у вас уже есть auth_failed, не добавляйте login_denied и sign_in_rejected, если только они действительно не означают разное.
Логируйте решение, а не строку кода
Простое правило: логируйте, когда программа принимает решение, меняющее результат. Именно ту точку вы захотите найти позже.
Плохо: логировать каждую строку вокруг вызова базы.
Лучше: один db_query‑событие, которое говорит, что важно: какая модель/таблица (не сырый SQL), удалось ли, и сколько времени заняло.
Всегда включайте поля результата
Сделайте фильтр по ошибкам и медленным путям простым. Добавьте несколько полей, которые есть в большинстве событий:
- ok: true или false
- errorType: короткая категория вроде ValidationError, AuthError, Timeout
- durationMs: для всего, что измеряется по времени (запросы, БД, внешние API)
- statusCode: для HTTP‑ответов
Реалистичный пример: если пользователь сообщает «оформление заказа падает», вы должны уметь искать event=auth_failed или ok=false, затем сузить по statusCode=401 или errorType=AuthError, и наконец заметить медленную часть, отсортировав по durationMs.
В AI‑сгенерированном коде это часто отсутствует или не согласовано. В FixMyMess одно из первых исправлений — нормализовать имена событий и поля, чтобы отладка в продакшене перестала быть угадайкой.
Уровни логов и объём, чтобы не утонуть в шуме
Если каждое событие — ошибка, вы перестаёте верить логам. Если вы логируете всё как debug — вы зарываете важную подсказку. Хорошая отладка в продакшене начинается с простого обещания: дефолтные логи должны объяснять, что произошло, без потопления системы.
Для чего нужен каждый уровень
Думайте об уровнях логов как о системе сортировки по срочности и ожидаемости. В структурированном логе уровень — ещё одно поле, по которому можно фильтровать.
- DEBUG: детали, которые нужны только при расследовании. Пример: время ответа внешнего API или точная ветка кода.
- INFO: обычные вехи. Пример: «пользователь вошёл», «создан payment intent», «задание выполнено».
- WARN: что‑то пошло не так, но приложение может восстановиться. Пример: повторный запрос, использование fallback, 429 от стороннего сервиса.
- ERROR: операция провалилась и требует внимания. Пример: необработанное исключение, провал записи в базу или 5xx ответ.
Практическое правило: если всплеск этого показателя разбудит кого‑то ночью — это, скорее всего, ERROR. Если это помогает объяснить жалобу пользователя позже — скорее INFO. Если полезно только при открытом тикете — DEBUG.
Контролируйте объём
Трафик по популярным эндпоинтам быстро создаёт шум, особенно в AI‑сгенерированных приложениях, где логирование часто добавляют повсеместно без плана. Вместо удаления логов контролируйте поток.
Используйте простые приёмы:
- Сэмплирование: логируйте 1% успешных запросов, но 100% WARN и ERROR. Сэмплирование полезно для health checks, polling‑эндпоинтов и разговорчивых фоновых джобов.
- Ограничение по частоте: если одно и то же предупреждение повторяется, логируйте его раз в минуту с счётчиком.
- Одно событие на исход: предпочитайте один
request_finishedс duration и статусом вместо 10 мелких логов.
Наконец, следите за производительностью. Избегайте тяжёлой сборки строк или сериализации JSON в горячих путях. Логируйте стабильные поля (как route, status, duration_ms) и вычисляйте дорогие детали только если уровень включён.
Error boundaries: поймайте падения и сохраните полезный контекст
Error boundary — это страховочная сетка в UI. Когда компонент падает при рендере, в lifecycle или конструкторе, boundary перехватывает ошибку, показывает запасной экран и (самое важное) записывает, что случилось. Это превращает пустую страницу и расплывчатую жалобу в то, что можно воспроизвести.
Что он ловит: синхронные UI‑ошибки при построении страницы. Что не ловит: ошибки в обработчиках событий, таймауты или большинство асинхронного кода. Для них всё ещё нужны обычные try/catch и обработка отклонённых промисов.
Что логировать при падении UI
Когда boundary срабатывает, запишите одно событие с достаточным контекстом, чтобы группировать и искать похожие падения. Если у вас структурированное логирование, держите ключи одинаковыми.
Снимите:
route(текущий путь) и важное состояние UI (вкладка, открытый модал, шаг мастера)component(где упало) иerrorName+messageuserAction(что пользователь только что сделал, например «нажал Сохранить»)requestId(если он есть от сервера или клиента API)buildинфо (версия приложения, окружение), чтобы сопоставить с релизом
Вот простая форма:
log.error("ui_crash", {
route,
component,
userAction,
requestId,
errorName: error.name,
message: error.message,
stack: error.stack,
appVersion,
});
Что видеть пользователю и что нужно разработчикам
Сообщение для пользователя должно быть спокойным и безопасным: «Что‑то пошло не так. Пожалуйста, обновите страницу. Если ошибка повторяется, свяжитесь с поддержкой.» Не показывайте сырые тексты ошибок, стеки или ID, которые раскрывают внутренности.
Разработчикам же нужен полный контекст в логах. Хорошая практика — показывать в UI короткий «код ошибки» (например, временную метку или случайный токен) и логировать детальное событие с тем же токеном.
На сервере используйте эквивалентные страховочные сетки: глобальный обработчик ошибок для запросов, плюс обработчики unhandled promise rejections и uncaught exceptions. Именно здесь многие AI‑сгенерированные приложения терпят неудачу, и почему команды вроде FixMyMess часто находят «молчащие» падения без requestId и полезных логов.
Если вы настроите это однажды, продакшен‑краш перестаёт быть загадкой и становится поисковым событием, которое можно быстро исправить.
Логирование безопасно: не сливайте секреты и персональные данные
Хорошие логи помогают быстро исправлять ошибки. Плохие логи создают новые проблемы: протекшие пароли, раскрытые API‑ключи и персональные данные, которые вы не планировали хранить. Простое правило работает хорошо: логируйте то, что нужно для отладки поведения, а не то, что пользователь вводил.
Никогда не логируйте эти данные (даже «временно»): пароли, session cookie, токены авторизации (JWT), API‑ключи, OAuth‑коды, приватные ключи, полные номера карт, CVV, банковские данные. Также рассматривайте личные данные как чувствительные: email, телефоны, адреса, IP (в многих случаях) и свободный текст, который может содержать всё что угодно.
Более безопасные альтернативы, которые всё ещё помогают отлаживать
Вместо дампа полного payload логируйте маленькие, стабильные куски контекста, которые помогают воспроизвести проблему.
- Редактируйте: заменяйте секреты на "[REDACTED]" автоматически.
- Частичные значения: логируйте только последние 4 символа токена или номера карты.
- Хэшируйте: сохраняйте однонаправленный хэш email, чтобы коррелировать события без хранения email.
- Используйте ID: userId, orderId, invoiceId и requestId обычно достаточно.
- Резюмируйте: логируйте количество и типы ("3 items", "payment_method=card") вместо полного объекта.
Пример: вместо полного тела запроса для оформления заказа логируйте orderId, userId, cartItemCount и paymentProviderErrorCode.
Почему AI‑сгенерированный код выдает секреты (и как это остановить)
AI‑сгенерированные прототипы часто логируют целые тела запросов, заголовки или переменные окружения в режиме «debug». Это риск в продакшене, и легко пропустить, потому что «работает». Ищите распространённые ловушки: console.log(req.headers), print(request.json()), логирование process.env или запись всего объекта ошибки, который включает заголовки.
Защитите себя двумя привычками: очищайте перед логированием и блокируйте опасные ключи по умолчанию. Сделайте небольшой «safe logger»‑обёртку, которая всегда редактирует поля вроде password, token, authorization, cookie, apiKey и secret, где бы они ни встречались.
Наконец, думайте про хранение. Храните подробные логи только столько, сколько действительно требуется для отладки и аудитов безопасности. Оставляйте резюме дольше, удаляйте сырые детали раньше и упрощайте процедуру удаления логов по запросу пользователя.
Реалистичный пример отладки за 5 минут
Пользователь сообщает: «Не могу войти. На моём ноутбуке работает, в продакшене — нет». Локально воспроизвести не получается, и единственная подсказка — временная метка и их email.
Со структурированными логами и request ID вы работаете в обратном порядке от репорта к одному запросу.
Минута 1: найдите запрос
В интерфейсе поддержки или в приложении у вас показывается короткий «код поддержки» (который на деле — requestId). Если такого UI ещё нет, вы можете искать логи по идентификатору пользователя (хэш email) вокруг указанного времени и взять requestId из первого совпадения.
Минуты 2–4: проследите поток и найдите шаг, где всё падает
Отфильтруйте логи по requestId=9f3c... — и у вас чистая история: одна попытка входа, end‑to‑end, через несколько сервисов.
{"level":"info","event":"auth.login.start","requestId":"9f3c...","userHash":"u_7b1...","ip":"203.0.113.10"}
{"level":"info","event":"auth.oauth.callback","requestId":"9f3c...","provider":"google","elapsedMs":412}
{"level":"error","event":"db.query.failed","requestId":"9f3c...","queryName":"getUserByProviderId","errorCode":"28P01","message":"password authentication failed"}
{"level":"warn","event":"auth.login.denied","requestId":"9f3c...","reason":"dependency_error","status":503}
Третья строка — и есть ответ: база отклоняет подключение в продакшене. Поскольку лог имеет стабильное event‑имя и поля вроде queryName и errorCode, вы не тратите время на чтение стен текста или угадывание, к какому стек‑трейсу относится этот пользователь.
Если на клиенте есть error boundary, вы можете увидеть соответствующее событие ui.error_boundary.caught с тем же requestId (переданным в заголовке) и экраном, где это произошло. Это подтверждает видимый пользователю эффект без скриншотов.
Минута 5: превратите логи в воспроизводимый тест
Теперь можно написать точный тест, который соответствует реальности:
- Используйте тот же путь входа (Google callback)
- Запустите против production‑похожей конфигурации (правильный источник DB user/secret)
- Выполните единственную падающую операцию (
getUserByProviderId) - Убедитесь в ожидаемом поведении (возвращается 503 с безопасным сообщением)
Во многих AI‑сгенерированных кодовых базах, с которыми мы работаем в FixMyMess, такая ошибка возникает потому, что секреты хардкодятся локально, а в продакшене подтягиваются иначе. Смысл логов — не больше данных, а правильные поля, чтобы из жалобы пользователя получить один падающий шаг быстро.
Краткий чек‑лист, типичные ошибки и следующие шаги
Когда возникает проблема в продакшене, вам нужны логи, которые быстро отвечают на три вопроса: что произошло, у кого и где сломалось. Этот чек‑лист помогает держать структурированное логирование полезным под давлением.
Короткий чек‑лист
- У каждого запроса есть
requestId, и он присутствует в каждой строке лога для этого запроса. - Каждый лог ошибки включает
errorTypeи stack trace (или ближайший аналог в языке). - Авторизация и платежи (или любые денежные потоки) имеют явные события «start» и «finish», чтобы понять, где поток остановился.
- Секреты и токены по умолчанию редактируются, и вы никогда не дампите полные payload.
- Те же основные поля всегда присутствуют:
service,route,userId(илиanonId),requestIdиdurationMs.
Если ничего больше не делаете — убедитесь, что можно вставить один requestId в поиске логов и увидеть всю историю от первого обработчика до последнего обращения к базе.
Типичные ошибки, которые отнимают время
Даже хорошие команды натыкаются на несколько ловушек, делающих логи бесполезными в нужный момент.
- Несогласованные имена полей (например
req_id,requestIdиrequest_idв разных местах). - Отсутствие контекста (ошибка залогирована, но непонятно, какой маршрут, пользователь или шаг её вызвал).
- Логирование только при ошибках (нужны ключевые «вехи», чтобы увидеть, где поток остановился).
- Слишком много шума на неправильном уровне (всё как
info, и реальные предупреждения теряются). - Случайные утечки данных (токены, API‑ключи, сессии или полные платёжные данные в логах).
Следующие шаги: выберите 3 критичных для пользователей потока (обычно регистрация/вход, оформление заказа и сброс пароля). Добавьте request ID end‑to‑end, затем 3–6 событий на поток (start, ключевой шаг, finish и явный event failure). Когда эти потоки станут надёжными, расширяйте остальное приложение.
Если ваш AI‑сгенерированный код трудно отлаживать из‑за беспорядочных или отсутствующих логов, FixMyMess может провести бесплатный аудит кода и помочь добавить request ID, согласованные поля событий и безопасную обработку ошибок, чтобы вопросы продакшена стали проще воспроизводимыми.