Таймауты и повторы API: разумные лимиты для вызовов к третьим сторонам
Таймауты и повторы API предотвращают замедления сторонних сервисов от «замораживания" приложения. Установите разумные таймауты, экспоненциальный backoff, лимиты повторов и безопасные значения по умолчанию.
Почему медленные сторонние API могут «заморозить" ваше приложение
Вызов к стороннему API кажется небольшой задачей, пока от каждого запроса это не зависит. Когда провайдер замедляется, ваше приложение начинает ждать и ждать. Пользователи видят бесконечные индикаторы загрузки. Фоновые задания перестают завершаться. Ничего «не падает», но всё выглядит застрявшим.
Большинство приложений работают с ограниченными ресурсами: фиксированное число веб-потоков, слоты serverless или воркеры очереди. Когда запрос блокируется из‑за медленного провайдера, он удерживает эту ёмкость. Пара медленных вызовов может превратиться в затор, где новая работа даже не может начаться.
Застрявшие запросы обычно проявляются так:
- Веб-запросы висят до таймаута браузера, хотя серверы кажутся «включенными».
- Воркеры заняты, но не завершают задания, и очередь продолжает расти.
- Один эндпоинт начинает потреблять большинство потоков (или соединений с БД), потому что ждёт внешнего вызова.
- Повторы срабатывают вслепую, повторяя тот же медленный вызов и ещё больше увеличивая бэклог.
Таймауты и повторы нужны для одного: быстро падать, повторяться безопасно и восстанавливаться грациозно. Чёткий таймаут останавливает один медленный провайдер от замораживания всей системы. Консервативные повторы помогают восстановиться после кратковременных сбоев, не создавая самоиндуцированного простоя.
Это удивляет людей, потому что дефолты HTTP‑клиентов часто слишком терпимы. Некоторые настроены на очень большие таймауты, а некоторые фактически ждут бесконечно, если вы не зададите и connect, и read таймауты. Многие AI‑сгенерированные прототипы отдают эти дефолты в продакшен, поэтому система делает ровно то, чему её научили: продолжать ждать.
Если относиться к каждому стороннему вызову как к потенциальному узкому месту, можно спроектировать приложение так, чтобы оно деградировало аккуратно: показать полезное сообщение, поставить задачу в очередь на потом или переключиться на запасной вариант вместо того, чтобы всё забилось.
Ключевые понятия: таймауты, повторы, backoff и лимиты
Чтобы интеграции со сторонними сервисами были надёжными, будьте ясны в четырёх вещах: сколько вы ждёте, повторяете ли попытки, как распределяете паузы и когда прекращаете.
Таймауты (разные «часы")
Таймаут — это жёсткое правило: «Если прогресса нет к X секунде, остановиться и вернуть управление приложению». Распространённые типы:
- Connect timeout: сколько ждать установки соединения (DNS, рукопожатие, сетевой путь). Помогает быстро откинуть «мертвые» сети.
- Read timeout: сколько ждать данных после открытия соединения. Именно здесь медленные провайдеры чаще всего причиняют проблемы.
- Total/request timeout: максимальное время для всего вызова от начала до конца. Это ваш последний страховочный сет.
Без таймаутов один медленный провайдер может занять потоки сервера или воркеры очереди, пока всё не забьётся.
Повторы vs. таймауты
Повтор — это ещё одна попытка после ошибки. Повторы не заменяют таймауты. Повторы без таймаутов могут быть хуже, чем их отсутствие, потому что вы можете накопить несколько застрявших запросов вместо одного.
Повторы помогают при временных проблемах: кратковременных таймаутах, 502/503, сетевых перебоях. Они рискованны для «реальных" ошибок — неверных учётных данных или некорректных запросов, когда повтор не поможет.
Backoff и jitter (ждать разумнее)
Backoff значит, что вы увеличиваете интервал между повторами (например: 1 с, затем 2 с, затем 4 с). Jitter — небольшой случайный сдвиг, чтобы клиенты не повторяли в один и тот же момент и не перегружали провайдера снова.
Лимиты повторов (когда сдаваться)
Лимит попыток ограничивает число попыток. «Сдаться» — это контролируемый результат: показать сообщение вроде «Сервис сейчас медленный, попробуйте позже», сохранить состояние пользователя (корзина, черновик, форма) и залогировать ошибку для последующего разбирательства вместо вечного ожидания.
Как выбрать разумные значения таймаутов
Таймауты — это не единое число для всего. Подбирайте их по провайдеру и по типу вызова, основываясь на том, что приемлемо для пользователей и что ваше приложение может выдержать при медленном провайдере.
Практичная отправная точка — разделять «смогу ли я подключиться?» и «получу ли я ответ?». Многие HTTP‑клиенты позволяют задавать оба таймаута.
Типичные стартовые диапазоны:
- Connect timeout: 0.2–1 с для большинства публичных API, до 2 с если ожидается редкая сет. задержка.
- Read/response timeout: 2–10 с для типичных запросов; 15–30 с только для явно долгих эндпоинтов (отчёты, экспорт).
- Запросы на запись (создание оплаты, заказа): держите таймауты умеренными (обычно 5–10 с) и полагайтесь на безопасные правила повторов, а не на вечное ожидание.
- Опросы/проверки статуса: короткие таймауты (2–5 с) и меньше повторов.
Пользовательские запросы должны быть строже, чем фоновые работы. Если страница оформления заказа ждёт, ограничьте вызов к третьей стороне 3–5 сек и покажите очевидный запасной вариант. Ночная синхронизация в фоне может ждать дольше, но всё равно нужна граница, чтобы не накапливались застрявшие воркеры.
Также задайте общий дедлайн для всей операции, включая повторы. Например: «Пробуем в общей сложности до 20 секунд, затем считаем ошибкой». Без этого повторы могут тихо превратить 5‑секундный вызов в проблему на 2 минуты.
Записывайте свои допущения, чтобы следующий инженер не гадал:
- Наблюдаемая латентность провайдера (p50 и p95)
- Толерантность UX (сколько пользователь готов ждать)
- Максимальное суммарное время с учётом повторов
- Какие эндпоинты могут быть медленнее и почему
Когда повторять, а когда нет
Повторы нужны для проблем, которые скорее всего пройдут сами собой. Если запрос неверен, повторы только зря тратят время и могут ухудшить ситуацию.
Обычно повторять имеет смысл при временных ошибках: сбои соединения, DNS, таймауты. Также это оправдано при ограничении по скорости (HTTP 429) и некоторых 5xx (502/503/504), когда провайдер может быть перегружен.
Простое правило:
- Повторять при сетевых ошибках, таймаутах, 429 и некоторых 5xx (например, 502/503/504).
- Не повторять большинство 4xx (400, 401/403, 404) до тех пор, пока что‑то не поменяется.
- Учитывать заголовок
Retry-After, если API его отправляет. - Прекращать попытки, если получено явное сообщение о постоянной ошибке.
Будьте осторожны с запросами с «неизвестным результатом». Если вы таймаутитесь после отправки списания по карте, повтор может создать дубликат, если не используются идемпотентные ключи или токен заказа.
Практический подход — разделить шаблоны:
- Быстрый повтор для мелких сбоев (одна быстрая попытка через ~100–200 мс).
- Короткая серия backoff для троттлинга или частичных сбоев (несколько попыток с увеличивающимися задержками).
Это сохраняет отзывчивость приложения и одновременно позволяет восстановиться, когда провайдер нужен немного времени.
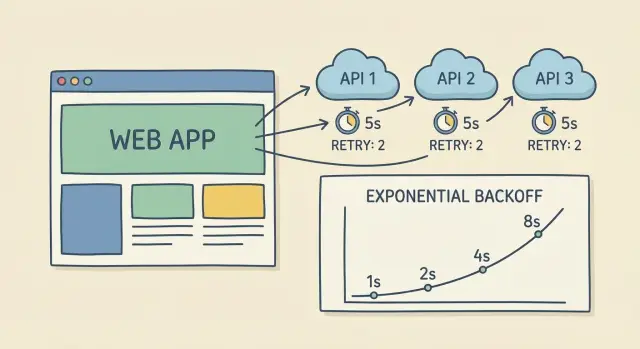
Экспоненциальный backoff с jitter — просто объяснение
Когда вызов API падает или таймаутится, немедленные повторы часто усугубляют ситуацию. Экспоненциальный backoff означает: подождать немного, затем дольше с каждой попыткой. Это снижает нагрузку на провайдера и даёт сервису время восстановиться.
Простая прогрессия (с лимитом, чтобы не растягивать):
- Попытка 1: ждать 0.25 с
- Попытка 2: ждать 0.5 с
- Попытка 3: ждать 1 с
- Попытка 4: ждать 2 с (установите cap здесь)
Jitter добавляет небольшой случайный сдвиг. Без него тысячи клиентов могут ретраить одновременно (ровно через секунду), создавая новый пик и очередную волну сбоев. С jitter одно приложение ждёт 0.8 с, другое — 1.3 с, поэтому повторы растягиваются.
Два важных ограничения:
- Ограничьте максимальную задержку (часто 2–5 с).
- Держите количество попыток небольшим и предсказуемым, обычно 2–4 повтора.
Так легче просчитать худший случай и избежать скрытых очередей застрявшей работы.
Сделайте повторы безопасными: идемпотентность и защита от дублей
Повторы помогают при сетевых сбоях, но могут создать хаос. Если вы повторяете неидемпотентное действие (списание карты, создание заказа), одно и то же нажатие может выполниться дважды. Так появляются двойные списания, дублирование аккаунтов или два отгрузки.
Простое правило: повторяйте только те вызовы, которые безопасно повторять. Чтения (GET) обычно безопасны. Записи (POST, создающие что‑то) требуют защиты перед включением повторов.
Используйте идемпотентные ключи, если провайдер их поддерживает
Многие API платежей, отправки сообщений и заказов допускают отправку idempotency key. Сгенерируйте уникальный ключ для действия пользователя (например, одна попытка оформления) и используйте его для всех повторов. Провайдер тогда вернёт один и тот же результат вместо повторного выполнения действия.
Храните этот ключ вместе с ответом и поддерживайте его стабильным, даже если пользователь обновит страницу.
Добавьте собственную дедупликацию, если провайдер не поддерживает
Если идемпотентности нет, можно предотвратить дубликаты на своей стороне. Держите это просто:
- Создайте запись запроса с уникальным
request_idперед вызовом провайдера. - Наложите уникальное ограничение (например:
user_id + cart_id + action_type). - Сохраняйте ответ провайдера (успех или ошибка) и переиспользуйте его при повторах.
- Добавьте короткое TTL, чтобы не блокировать легитимные будущие покупки.
- Логируйте стабильный ID запроса, чтобы саппорт мог проследить цепочку событий.
Пример: при оформлении заказа первый запрос на списание таймаутится, но провайдер позже всё же обработал его. Если вы повторяете без идемпотентности или дедупа, можно снять деньги дважды. Со стабильным request_id вы повторяете безопасно и показываете единый итог.
Остановка бесконечных сбоев: капы, circuit breaker и запасные варианты
Повторы помогают при кратковременных сбоях. Если провайдер лежит или сильно тормозит, повторы могут превратить одну маленькую проблему в поток застрявших запросов. Цель — не «никогда не падать», а «падать контролируемо», чтобы приложение оставалось полезным.
Поставьте жёсткие ограничения на каждый вызов
Каждый исходящий вызов нуждается в лимитах, которые быстро прекращают проблему. Короткий список капов и их последовательное применение:
- Максимум попыток (например, всего 3 попытки)
- Максимальное суммарное время (например, остановиться после 10 секунд)
- Максимум параллельных вызовов (чтобы не допустить 500 одновременных запросов)
- Чёткое определение того, что можно повторять (только ожидаемые восстановимые ошибки)
Эти ограничения не дадут одному медленному провайдеру заморозить веб‑сервер, раздувать очередь или тратить лимиты по скорингу.
Используйте circuit breaker при падении провайдера
Circuit breaker — простое правило: если слишком много вызовов падает за короткий период, приостановите вызовы на некоторое время. В период паузы вы сразу возвращаете контролируемый ответ вместо ожидания таймаутов. После остывания разрешите небольшое количество тестовых вызовов, чтобы проверить восстановление провайдера.
Это помогает изолировать падение провайдера от вашего ядра. Пользователи всё ещё могут входить, просматривать и сохранять прогресс, даже если одна интеграция нездорова.
Добавьте запасные варианты, чтобы пользователи могли двигаться дальше
Запасной вариант может быть простым: кэшированные данные, сообщение «повторите через минуту» или деградированный режим, который пропускает не‑критичную функцию.
Пример: если тарифы доставки таймаутятся при оформлении заказа, покажите стандартную ставку или разрешите оформить заказ, подтвердив доставку позже.
Пошагово: добавляем таймауты и повторы в существующее приложение
Начните с приведения поведения к единообразию. Если каждый инженер ставит таймауты по‑разному (или забывает их), один медленный провайдер всё равно способен связать приложение.
1) Централизуйте HTTP‑настройки
Создайте общий HTTP‑клиент (или обёртку) и пропускайте через него все исходящие вызовы. Дайте безопасные значения по умолчанию: connect timeout, response timeout и жёсткий cap на общее время (включая повторы). Логируйте каждый запрос с названием провайдера, чтобы быстро заметить паттерны.
Затем добавьте небольшой слой политик per‑provider. Платежи, почта, карты и модели AI ведут себя по‑разному, поэтому одни и те же правила повторов редко подходят всем.
2) Добавьте переопределения для каждого провайдера
Для каждого провайдера задайте:
- Таймауты (короче для быстрых эндпоинтов, длиннее только там, где нужно)
- Правила повторов (какие коды статуса и сетевые ошибки подходят)
- Лимиты повторов (максимум попыток и суммарное время)
- Обработку ограничения скорости (уважайте 429 и
Retry-Afterс ограниченным числом повторов)
Держите повторы консервативными. Сломавшийся провайдер должен быстро падать, чтобы освободить ресурсы приложения.
3) Измеряйте то, что чувствуют пользователи
Отслеживайте несколько метрик и ревью регулярно: частота таймаутов, число повторов на запрос, успех после повтора и общая латентность (включая ожидания). Если повторы «работают», но добавляют 8 секунд к оформлению заказа — пользователи всё равно будут ощущать торможение.
4) Проверьте это, искусственно замедлив провайдера
Тестируйте в staging, симулируя медленные ответы и нестабильные соединения. Заставьте провайдера «спать» 10 секунд и убедитесь, что ваше приложение таймаутится через 2 секунды, ретраит с backoff и потом останавливается по лимиту. Также протестируйте частичные отказы, где каждый третий запрос падает.
Типичные ошибки, приводящие к застрявшим запросам
Застрявшие запросы обычно возникают из одной корневой проблемы: нет ясного лимита на то, как долго приложение будет пытаться. Когда провайдер тормозит, воркеры сидят и ждут, а бэклог растёт пока всё не кажется замороженным.
Вот паттерны, которые тихо создают пробки:
- Число повторов настолько велико, что фактически бесконечно.
- Немедленные повторы без паузы, особенно под нагрузкой.
- Нет общего дедлайна, поэтому пользователь ждёт дольше, а сервер остаётся занятым.
- Повторяются постоянные ошибки (плохой API‑ключ, недостаточные права, неверная полезная нагрузка) вместо исправления запроса.
- Игнорирование лимитов по скорости (429), что часто приводит к ещё более жёсткому троттлингу.
Полезная модель: повторы — для временных проблем, не для постоянных. Когда провайдер упал или медлит, нужно меньше, но умнее попыток, а не больше.
Что безопасно: 2–3 дополнительных попытки, экспоненциальный backoff с jitter и жёсткий cap на всю операцию (например, «остановиться через 10 секунд независимо от всего»). Для ответов 429 воспринимайте время ожидания, предложенное провайдером, как часть контракта.
Реалистичный пример: один провайдер замедляется при оформлении заказа
Представьте поток оформления заказа с тремя сторонними вызовами: платежный API для списания, API доставки для получения тарифов и почтовый провайдер для отправки квитанции.
Однажды днём провайдер доставки начинает тормозить. Ваше приложение запрашивает тарифы, но запрос висит 25–30 секунд. Клиент смотрит на крутящийся индикатор. Если сервер удерживает этот запрос открытым, вы занимаете потоки и ставите другие попытки оформления в очередь. Один медленный провайдер может сделать сайт неработоспособным.
Более безопасный поток:
- Платежи: короткий таймаут; не ретраить автоматически после попытки списания, если вы не можете доказать безопасность повтора.
- Тарифы доставки: быстро таймаутить (например, 2–3 с), сделать небольшое число повторов с backoff, затем остановиться.
- Запасной вариант: если тарифы всё ещё медленные, показать стандартную ставку или позволить оформить заказ и подтвердить доставку позже.
- Сообщение пользователю: «Не удалось загрузить актуальные тарифы. Вы всё ещё можете оформить заказ — мы подтвердим доставку по e‑mail.»
Где происходят повторы, имеет значение. На странице оформления заказа держите таймауты жёсткими, чтобы быстро дать ответ пользователю. После создания заказа можно выполнять более длительные фоновые повторы (с жёсткими лимитами), чтобы получить окончательный тариф и обновить заказ без удержания пользователя.
Короткий чек‑лист перед релизом
Перед выкатом пройдитесь по каждому стороннему вызову (платежи, почта, карты, auth, доставка, AI‑провайдеры). Цель простая: один медленный провайдер не должен заморозить приложение, а кратковременный отказ не должен создавать стопку застрявших запросов.
Убедитесь, что у каждого вызова есть:
- Короткий connect timeout
- Разумный read timeout
- Общий дедлайн для всей операции (включая повторы)
Для повторов:
- Повторять только временные ошибки (таймауты, сетевые сбои, явные 429/5xx)
- Использовать экспоненциальный backoff с jitter
- Везде применять максимумы попыток и максимальное суммарное время (HTTP‑клиент, очередь задач, фоновые воркеры)
Наконец, сделайте повторы безопасными. Если операция может создать дубли (списания, заказы, создание аккаунта), добавьте идемпотентные ключи или дедупинг до включения повторов.
Мониторинг должен показывать поведение по каждому провайдеру: частоту таймаутов, частоту повторов и среднюю латентность. Это поможет заметить проблему раньше, чем она превратится в пользовательскую заморозку.
Следующие шаги: стабилизируйте интеграции без избыточной архитектуры
Начните с поиска вызовов, которые могут ждать бесконечно. Ищите запросы без явного таймаута, фоновые задания, которые ретраят «до успеха», и воркеры, которые никогда не сдаются. Это те, кто тихо накапливает застрявшую работу и превращает мелкую заминку провайдера в простой.
Выберите один‑два критичных сторонних API и завершите шаблон end‑to‑end, прежде чем брать всё остальное. Критично там, где текут деньги, вход в систему, сообщения или любое действие, блокирующее пользователя. Реализуйте чёткий таймаут, политику повторов с backoff и жёсткий лимит попыток. Добавьте базовое логирование, чтобы можно было ответить на вопросы: сколько раз мы ретраили, сколько времени ждали и успешно ли в итоге завершилось?
Когда случается инцидент, скорость важнее идеального инструмента. Напишите небольшой план действий: как временно отключить провайдера (feature flag или конфиг), что показывать пользователям, что проверять в первую очередь (статус провайдера, частота ошибок, глубина очереди) и когда включать обратно.
Если вы унаследовали AI‑сгенерированную кодовую базу с небезопасными дефолтами, FixMyMess (fixmymess.ai) может провести бесплатный аудит кода, указать пропущенные таймауты, бесконтрольные повторы и хрупкие интеграции, а затем помочь превратить прототип в готовый к продакшен софт с правками, проверенными человеком.
Часто задаваемые вопросы
Why can a single slow third-party API make my whole app feel frozen?
Ваше приложение имеет ограничённую ёмкость (веб-потоки, слоты serverless или воркеры). Если запрос ждёт медленного стороннего API без жёсткого таймаута, он занимает эту ёмкость, и новая работа не может начаться — поэтому всё кажется «зависшим», хотя ничего не «падает».
What timeouts should I set for most third-party API calls?
Установите короткий таймаут на подключение и отдельный таймаут чтения/ответа, плюс общий дедлайн для запроса. Обычно на старте это ~0.2–1 с на подключение и 2–10 с на ответ, затем корректируйте в зависимости от провайдера и ожиданий пользователей.
What’s the difference between a timeout and a retry?
Таймаут прекращает ожидание и возвращает контроль приложению. Повторная попытка — это новая попытка после ошибки. Обычно нужны оба: таймауты, чтобы не держать работу в подвешенном состоянии, и небольшое число повторных попыток, чтобы восстановиться после кратковременных сбоев.
Which errors should I retry, and which should I avoid retrying?
Повторять стоит только те ошибки, которые, вероятно, временные: таймауты, сетевые сбои, 429 и некоторые 5xx. Не повторяйте большинство 4xx (неверные запросы, плохие ключи), потому что повтор того же запроса ничего не исправит.
How do I do backoff and jitter without making things worse?
Используйте экспоненциальный backoff, чтобы увеличивать паузу между попытками, и добавляйте jitter, чтобы многие клиенты не повторяли одновременно. Делайте это умеренно: 2–4 попытки с ограничением задержки, чтобы не получить длинные ожидания или большие очереди.
Why can retries cause double charges or duplicate orders?
Повторные попытки могут повторить действие записи, если первый запрос всё же был выполнен, а ответ не дошёл до вас. Это приводит к двойным списаниям или повторным заказам, если не использовать идемпотентность или дедупликацию.
Should timeouts be different for web requests vs. background jobs?
Для пользовательских запросов (например, оформление заказа) делайте таймауты короткими и показывайте понятный запасной вариант. Для фоновых задач можно ждать дольше, но всё равно нужно жёсткие лимиты, чтобы один провайдер не занял все воркеры и не раздувал очередь.
When should I add a circuit breaker?
Цепь защиты: если слишком много вызовов падает за короткое окно, временно приостановите вызовы к провайдеру. Это позволит мгновенно возвращать контролируемый ответ вместо ожидания таймаутов и поможет остальной части приложения оставаться работоспособной.
Why do AI-generated prototypes often ship with unsafe HTTP defaults?
Большинство HTTP-клиентов по умолчанию используют слишком мягкие настройки или вообще не задают оба таймаута (connect/read). Многие AI-сгенерированные прототипы сохраняют эти дефолтные значения, поэтому приложение продолжает ждать бесконечно, как его научили.
What’s the fastest way to add sane timeouts and retries to an existing app?
Сначала централизуйте все исходящие HTTP-вызовы за общим клиентом, чтобы задавать безопасные значения по умолчанию. Если вы унаследовали AI-сгенерированную базу и не знаете, где пропущены таймауты и повторы, FixMyMess может провести бесплатный аудит кода и быстро исправить интеграции с проверкой человеком.