API OpenAPI-first pour prototypes désordonnés : rester synchronisés
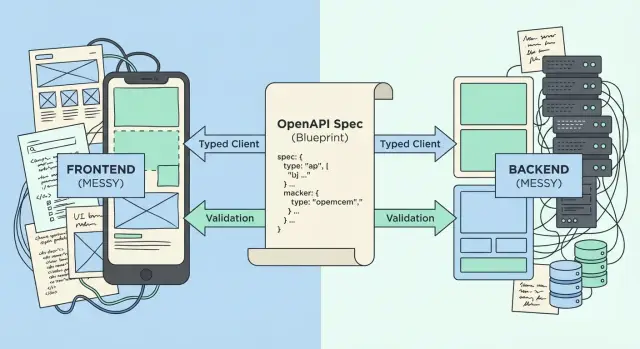
L'approche OpenAPI-first vous aide à transformer un prototype désordonné en un contrat fiable : générez des clients typés, validez requêtes et réponses, et maintenez l'alignement frontend-backend.
Pourquoi les prototypes s'effondrent quand l'API n'est pas définie
La plupart des prototypes commencent par la vitesse : un écran, un endpoint, un changement rapide. Ensuite l'API bouge sans trace claire de ce qu'elle doit accepter ou renvoyer. Les endpoints sont renommés, des params de query apparaissent ou disparaissent, et la forme des réponses change selon la dernière personne qui a touché le code.
Le frontend comble généralement les vides en devinant. Quelqu'un hardcode un nom de champ qui marchait hier. Un autre ajoute un paramètre optionnel. Le backend commence discrètement à renvoyer un format d'erreur différent. Rien ne semble cassé isolément, mais le système devient fragile très vite.
De petites incongruités deviennent de gros bugs parce qu'elles restent cachées jusqu'au pire moment. Un champ requis devient optionnel et le checkout casse. Une réponse passe de userId à id et l'UI affiche des zones vides. Un booléen devient une chaîne et la validation passe à un endroit mais échoue à un autre. Les en-têtes d'auth diffèrent selon les endpoints et les utilisateurs sont déconnectés aléatoirement. Les réponses d'erreur varient, donc l'UI ne peut pas afficher le bon message.
Une « source unique de vérité » règle ces problèmes au quotidien : une description convenue de chaque endpoint (chemin, méthode, params, corps de requête, forme de réponse, format d'erreur) que le frontend et le backend suivent. Quand cette source change, tout le monde le voit et met à jour ensemble. C'est la promesse des API OpenAPI-first.
Vous n'avez pas besoin d'une réécriture complète pour y arriver. Même un prototype généré par IA peut s'améliorer pas à pas : documentez les endpoints réellement utilisés, verrouillez les formes qui comptent, puis corrigez le code pour qu'il corresponde.
Que signifie vraiment « OpenAPI-first »
OpenAPI est un contrat écrit pour votre API. C'est généralement un fichier YAML ou JSON qui décrit endpoints, entrées et sorties d'une manière lisible par les humains et les outils. Au lieu de compter sur « ça marchait hier », vous pouvez pointer vers un document unique et dire : ceci est la vérité.
OpenAPI-first signifie que le contrat est décidé en premier, puis le code suit.
Avec une approche « spec last », les équipes construisent rapidement des endpoints, le frontend devine les formes, et tout le monde bricole quand ça casse. Plus tard, quelqu'un documente ce qui existe, mais la doc est en retard et la dérive devient normale.
Avec « spec first », vous vous mettez d'accord sur les comportements en amont, même si le backend est encore désordonné. Le spec devient le plan : ce que le frontend doit appeler, ce que le backend doit renvoyer, et ce qui se passe quand ça tourne mal.
Un spec utile rend quatre choses non ambiguës :
- Endpoints et méthodes : chemins, verbes HTTP, paramètres, et quelques exemples.
- Règles d'auth : comment les utilisateurs s'authentifient, quels headers ou tokens sont requis, et ce qui arrive en cas d'échec d'auth.
- Schémas de données : champs exacts pour les requêtes et réponses (types, requis vs optionnels, formats).
- Erreurs : formes d'erreur standard et codes de statut, pour que les échecs soient prédictibles.
Le bénéfice pratique est l'alignement. Le backend implémente selon le spec. Le frontend peut générer des types et appels qui correspondent. QA teste en se basant dessus. Le produit peut le lire et confirmer que l'API supporte les parcours utilisateurs réels.
Cela compte encore plus pour les prototypes construits par IA où les endpoints « existent en quelque sorte » mais ne sont pas cohérents. Une route renvoie { user: ... }, une autre renvoie { data: { user: ... } }, et les erreurs peuvent être du texte brut à un endroit et du JSON ailleurs. Écrire un contrat cohérent force ces décisions au grand jour et arrête les suppositions.
Comment créer votre premier spec OpenAPI à partir d'un prototype désordonné
Les prototypes désordonnés ont généralement une API, simplement pas écrite. Votre premier spec doit décrire ce que le système fait aujourd'hui, puis devenir plus cohérent à chaque itération. L'objectif est le progrès, pas la perfection.
Commencez par collecter des preuves de ce qui existe déjà : routes backend, appels réseau du frontend, logs serveur, et toutes les notes ou captures d'écran. Dans des bases de code générées par IA (outils comme Bolt, v0, Cursor ou Replit), vous trouverez souvent des endpoints qui marchent pour un écran et cassent en usage réel : checks d'auth manquants, noms de champs étranges, erreurs incohérentes. Capturez des requêtes et réponses réelles, même si elles sont moches.
Choisissez d'abord un workflow étroit pour ne pas noyer le travail. Une bonne tranche est quelque chose de critique pour le business, comme « inscription + création de projet » ou « checkout + confirmation de paiement ». Si vous pouvez décrire un flux bout en bout, vous aurez un spec utilisable immédiatement.
Avant d'écrire les endpoints, fixez quelques règles simples qui évitent le chaos futur. Décidez d'un style de chemin (comme /projects/{projectId}), d'une convention de nommage (camelCase ou snake_case), d'un seul pattern de pagination, d'une forme d'erreur partagée, et d'exigences d'auth claires par endpoint.
Écrivez maintenant la version 0.1 du spec, même incomplète. Documentez les champs dont vous êtes sûr, et utilisez les descriptions pour signaler les incertitudes. Le plus grand gain est de rendre explicites les corps de requête et les réponses, car c'est là que le frontend devine le plus.
Une approche pratique : prenez une vraie réponse depuis les logs, utilisez-la pour rédiger un schéma, puis retirez les champs que vous ne voulez pas garantir à long terme.
Enfin, faites une revue rapide avec les personnes touchant les deux côtés : celui qui gère les appels frontend et celui qui gère les handlers backend. Un rapide passage corrige souvent des codes de statut non concordants, des champs requis manquants, et des confusions de nommage.
Générez des clients typés pour que le frontend cesse de deviner
Un client typé est une petite librairie générée depuis votre spec OpenAPI qui connaît déjà vos endpoints, paramètres et formes de réponse. Plutôt que le frontend devine ce que le backend renvoie (et se faire surprendre en production), votre éditeur peut vous avertir dès que vous utilisez mal l'API.
En pratique, cela remplace les appels fetch écrits à la main par un flux répétable : générez le client depuis le spec, importez les fonctions et types générés, et mettez à jour l'UI pour les utiliser. Corrigez ensuite les erreurs de type immédiatement plutôt que de déboguer des 400 plus tard.
Le typage attrape tôt des problèmes courants : champs requis manquants, valeurs d'enum erronées, et noms incohérents (snake_case vs camelCase). Il aide aussi pour des données délicates comme les dates. Si l'API indique qu'un champ est une chaîne date-time, vous pouvez le gérer de façon homogène au lieu de le convertir différemment selon les parties de l'UI.
Les types ne suffisent pas seuls. Les vraies apps ont encore besoin de comportements runtime : timeouts pour que l'UI ne reste pas bloquée, retries pour les réseaux instables, et injection du token d'auth pour que chaque requête soit signée de la même manière. Un bon pattern est de configurer une instance cliente avec ces règles, puis de l'utiliser partout.
Une règle non négociable : la génération du client est une étape de build, pas un one-off. Si le spec change, le client doit être régénéré dans le même commit, sinon la dérive revient.
Validez requêtes et réponses pour détecter la dérive tôt
Le code typé aide à écrire les bonnes formes, mais il ne protège pas votre API quand du trafic réel la frappe. Les vérifications de types se font à la compilation. La validation runtime se produit quand le serveur reçoit une requête ou envoie une réponse. Sans elle, les clients peuvent envoyer des champs manquants, de mauvais formats ou des données en trop et le backend peut les accepter par accident.
Avec des API OpenAPI-first, le spec est le contrat. La validation runtime est la façon d'appliquer ce contrat au quotidien, même quand le code change vite.
Validez les requêtes entrantes (et échouez vite)
Commencez par vérifier les basiques sur chaque endpoint. Vous voulez des erreurs claires plutôt qu'une coercition silencieuse : champs requis, formats (emails, UUID, dates, URLs), valeurs autorisées (enums), et la manière de traiter les champs inattendus (rejeter ou supprimer). Mettez des limites raisonnables sur la taille des payloads pour la sécurité.
Un bug courant dans un prototype désordonné : le frontend envoie userId comme nombre à un endroit et comme chaîne à un autre. Les types peuvent ne pas le détecter si des parties de l'app ont été générées ou modifiées séparément. La validation runtime l'attrape à la première requête invalide et indique exactement ce qui a échoué.
Validez les réponses sortantes (pour que le backend ne dérive pas)
La dérive se cache souvent dans les réponses. Un refactor backend change totalCount en total, ou renvoie null là où le spec dit string. L'UI casse de manière apparemment aléatoire.
La validation des réponses force le serveur à rester honnête : si la réponse est hors spec, vous le voyez immédiatement dans les logs et les tests.
Standardisez aussi les réponses d'erreur pour que l'UI gère les échecs sans cas particuliers. Gardez une forme unique partout : un code stable (lisible par la machine), un court message (lisible par l'humain), des details optionnels (erreurs par champ), et un traceId de requête pour le support.
Garder le frontend et le backend alignés lors des changements
Quand une API change, le plus grand risque n'est pas le changement lui-même. C'est la divergence silencieuse : le frontend continue d'envoyer l'ancienne forme, le backend attend la nouvelle, et le bug n'apparaît qu'en production.
Traitez le spec comme la poignée de main entre équipes. Si la poignée change, tout le monde ajuste sa prise avant d'aller plus loin.
Un workflow simple empêche la dérive :
- Mettez d'abord à jour le spec OpenAPI (requête, réponse, erreurs).
- Régénérez le client typé et les types.
- Implémentez le changement backend pour qu'il corresponde au spec.
- Mettez à jour le frontend en utilisant les types régénérés.
- Exécutez validations et tests avant de merger.
Cet ordre force les désaccords à apparaître tôt, quand le changement est encore petit.
Les changements cassants arriveront. Le vrai problème, ce sont les changements cassants sans avertissement. Si vous devez renommer un champ, changer un paramètre requis, ou altérer un comportement, envisagez de publier une nouvelle version et de garder l'ancienne active brièvement pour que le frontend ait une fenêtre sûre de migration. Pour les endpoints et champs obsolètes, marquez-les comme dépréciés dans le spec et suivez une date réelle de suppression, sinon les dépréciations traînent indéfiniment.
Une courte checklist « done » aide à éviter les changements à moitié finis :
- Spec mis à jour (y compris les cas d'erreur).
- Client typé régénéré et commité.
- Compatibilité ascendante vérifiée (ou version incrémentée).
- Items dépréciés marqués et suivis.
- Tests QA mis à jour depuis le spec.
Erreurs courantes qui font échouer l'approche OpenAPI-first
Les API OpenAPI-first fonctionnent quand le spec est traité comme un véritable artefact produit, pas comme un fichier qui dort dans un repo. La plupart des échecs arrivent quand les équipes adoptent les outils (générateurs, docs, mocks) mais évitent la partie difficile : se mettre d'accord sur un contrat clair et l'appliquer.
Un piège fréquent est de mélanger les styles. On commence avec des chemins propres, puis on ajoute un endpoint qui accepte un blob JSON libre parce que le prototype en a besoin aujourd'hui. Une semaine plus tard, la moitié de l'API est propre et l'autre moitié est ad hoc, donc les clients typés cassent ou se retrouvent remplis de any.
Un autre problème est d'ignorer les cas d'erreur. Si le spec décrit seulement les chemins heureux, l'UI n'a aucun moyen fiable de gérer les échecs. On obtient alors une logique fragile du type « si le message contient… » et une montagne d'états UI spécifiques.
L'auth est souvent vague aussi. Les prototypes ont communément un contournement hardcodé, un token collé dans le local storage, ou un flux OAuth à moitié fini. Si le spec n'explicite pas tôt les schémas de sécurité et les headers requis, frontend et backend construisent des hypothèses différentes et le débogage devient du tâtonnement.
La génération client peut aussi devenir un événement unique. Les équipes génèrent un client typé une fois, puis changent le backend sans régénérer. Le client cesse de refléter la réalité, et les devs commencent à contourner les erreurs de type plutôt qu'à corriger le contrat.
Enfin, beaucoup d'équipes traitent le spec comme de la documentation seulement. Si les serveurs ne valident pas les requêtes et réponses contre lui (même en dev ou staging), le spec devient une wishlist. Le contrat réel devient ce que le backend renvoie aujourd'hui.
Un test simple : si un dev frontend dit « je vais juste essayer et voir ce que ça renvoie », vous n'utilisez pas le spec comme contrat.
Vérifications rapides avant de déclarer l'API « stable »
« Stable » ne veut pas dire « parfait ». Cela signifie que l'on peut construire dessus sans deviner, et que les changements sont délibérés plutôt qu'accidentels.
Commencez par une question basique : y a-t-il un et un seul spec que tout le monde considère comme la vérité ? Si le backend a un fichier, le frontend un autre, et un contractant a une troisième copie dans un chat, vous n'avez pas une API stable. Vous avez trois opinions.
Ensuite, vérifiez la couverture. Un spec peut être bien écrit et inutile s'il omet le parcours principal. Choisissez un flux principal (inscription, connexion, créer l'objet principal, le lister, le mettre à jour) et confirmez que chaque appel de ce flux est documenté.
Ces vérifications attrapent la plupart des problèmes du type « ça marche sur ma machine » :
- Un seul fichier OpenAPI partagé est utilisé pour la génération de code et la revue, pas copié partout.
- Les schémas marquent clairement ce qui est requis, ce qui peut être null, et ce qui peut être omis.
- Les erreurs sont prévisibles : même forme, même nommage, et codes de statut en accord avec la réalité.
- Vous pouvez régénérer des clients typés et exécuter la validation requête/réponse avec une commande reproductible.
- Le spec correspond au comportement en production pour les endpoints principaux, pas seulement aux tests locaux.
Méfiez-vous du glissement « optionnel » qui devient un tiroir-poubelle. Si un champ est vraiment optionnel, dites ce qui se passe quand il manque. S'il est requis pour que l'écran fonctionne, marquez-le requis.
Un exemple fréquent dans les prototypes : renvoyer 200 avec { "error": "Not logged in" } quand l'auth échoue. C'est pratique, mais ça casse la génération de clients typés et pousse la gestion des erreurs dans des vérifications frontend aléatoires. Une API stable renvoie un clair 401 avec un objet d'erreur cohérent.
Un exemple réaliste : nettoyer une API de prototype générée par IA
Imaginez un prototype généré par un outil IA : page de login, écran profil, écran paiements. Tout a l'air correct en démo, mais dès qu'on teste de vrais utilisateurs, les fissures apparaissent.
Le problème principal est l'incohérence. Le frontend attend des champs que le backend n'envoie jamais, parce que les deux côtés ont été construits en copiant des suppositions. L'UI profil affiche displayName et plan, mais le backend renvoie name et ne renvoie jamais les données d'abonnement. Pendant ce temps, l'écran paiements envoie { amount: "20", currency: "usd" }, mais le serveur n'accepte qu'un entier amountCents et rejette les codes monnaie en minuscule.
Les API OpenAPI-first règlent ça en imposant un contrat clair, puis en faisant respecter ce contrat par les deux côtés.
Commencez petit : définissez seulement les endpoints que l'app utilise aujourd'hui, et incluez réponses de succès et d'erreur pour que l'UI gère les échecs sans deviner. Même un petit spec force des décisions importantes : plan est-il requis ? Est-ce free | pro ? À quoi ressemble « non connecté » en JSON ?
Une fois le spec établi, générez un client typé et remplacez les fetch() écrits à la main. Si l'UI tente de lire displayName alors que le spec dit name, cela échoue à la compilation plutôt qu'en production.
Ajoutez ensuite la validation des requêtes côté serveur. Quand l'écran paiements envoie { amount: "20" } au lieu de { amountCents: 2000 }, le serveur le rejette immédiatement avec une erreur 400 lisible, et non un plantage vague plus tard.
Étapes suivantes : transformer le spec en un processus de développement plus calme
Vous n'avez pas à réécrire tout votre système pour tirer parti d'OpenAPI-first. Le gain le plus rapide est de choisir un workflow que les utilisateurs touchent chaque jour et de le rendre prévisible de bout en bout.
Choisissez un flux unique et à fort trafic et livrez un spec pour celui-ci cette semaine. De bons candidats sont la connexion, le checkout, ou « créer un élément » plus « lister les éléments ». Gardez la première version petite mais complète : corps de requête clair, réponses claires, et cas d'erreur réels.
Utilisez ensuite le spec pour empêcher la dérive de revenir : régénérez le client typé pour cette portion, validez requêtes et réponses pour les mêmes endpoints, et faites de « pas de changement d'API sans changement du spec » une habitude.
Si la base de code est déjà emmêlée (auth cassée, secrets exposés, endpoints spaghetti, failles de sécurité), un audit rapide vous évitera de standardiser un mauvais contrat. FixMyMess (fixmymess.ai) se concentre sur la réparation d'apps générées par IA et peut aider à transformer un prototype dérivant en une API prête pour la production en verrouillant le contrat, en alignant le code sur lui et en durcissant les zones les plus risquées.
Questions Fréquentes
Que signifie « OpenAPI-first » en termes simples ?
Une approche OpenAPI-first signifie que vous convenez d'un contrat d'API (endpoints, entrées, sorties et erreurs) avant de vous fier au comportement actuel du code. Le backend et le frontend traitent le spec comme la vérité, ainsi les changements sont délibérés et visibles au lieu d'entraîner une dérive accidentelle.
Pourquoi les prototypes générés par IA se cassent-ils quand l'API n'est pas définie ?
Les prototypes tombent en panne quand le frontend devine les formes des réponses et que le backend change de comportement sans en garder trace. De petites différences — champs renommés, en-têtes d'authentification incohérents, formats d'erreur différents — s'accumulent jusqu'à ce que les flux principaux échouent en production.
Comment démarrer un spec OpenAPI quand mon API est déjà en désordre ?
Commencez par un seul workflow que les utilisateurs utilisent réellement, comme « inscription + création de projet » ou « paiement + confirmation ». Capturez des requêtes et réponses réelles depuis les logs réseau, rédigez un spec minimal pour ces endpoints, puis resserrez les schémas et formats d'erreur en corrigeant le code.
Que devrais-je inclure dans la version 0.1 du spec ?
La version 0.1 utile explicite le corps de la requête, la forme de la réponse, les exigences d'authentification et le format d'erreur pour les endpoints que vous utilisez aujourd'hui. Vous pouvez noter les inconnues dans les descriptions, mais évitez les schémas « tout est permis » qui forcent le frontend à deviner.
Comment gérer les incohérences de noms de champs comme `userId` vs `id` ?
Choisissez une convention de nommage et appliquez-la partout, puis mettez à jour soit le backend soit le client pour s'y conformer. Si vous ne pouvez pas changer immédiatement la sortie du backend, reflétez la réalité dans le spec pour l'instant et planifiez une migration contrôlée pour ne pas casser l'UI silencieusement.
Qu'est-ce qu'un client typé, et pourquoi vaut-il la peine d'en générer un ?
Un client typé est du code généré qui connaît vos endpoints et types depuis le spec, afin que votre éditeur et la compilation détectent les incompatibilités tôt. Il réduit le code fetch() écrit à la main et fait apparaître les changements d'API comme erreurs de type plutôt que comme bugs en production.
Ai-je encore besoin de validation runtime si j'ai des types TypeScript ?
Non, les types aident au moment de la compilation, mais ils ne protègent pas votre serveur contre du trafic réel envoyant des payloads invalides. La validation runtime vérifie les requêtes entrantes et les réponses sortantes par rapport au spec, de sorte que la dérive et les données non valides sont repérées immédiatement avec des erreurs claires.
Quelle est la manière la plus simple de standardiser les erreurs d'API ?
Utilisez un seul objet d'erreur cohérent partout, avec un code stable lisible par la machine, un court message lisible par l'humain, et des details optionnels au niveau des champs. Cette cohérence permet à l'UI d'afficher le bon message sans analyses fragiles comme vérifier si le texte « contient » quelque chose.
Quel est le flux sûr pour changer une API sans casser le frontend ?
Mettez à jour le spec en premier, régénérez le client typé dans le même changement, implémentez la modification backend pour qu'elle concorde, puis mettez à jour le frontend en utilisant les types régénérés. Si vous devez faire un changement cassant, versionnez ou fournissez une courte période de migration pour ne pas surprendre les utilisateurs en production.
Quand devrais-je demander de l'aide pour réparer une API générée par IA plutôt que la bricoler moi-même ?
Si votre prototype a une authentification cassée, des secrets exposés, des endpoints incohérents ou des formes de données floues, standardiser un spec peut en fait figer un mauvais comportement. FixMyMess peut réaliser un audit gratuit du code puis réparer rapidement le code généré par IA, l'aligner sur un contrat OpenAPI clair et sécuriser les parties les plus risquées.
Comment savoir si mon API est réellement stable ?
Un test simple : si un développeur frontend dit « j'essaie et je verrai ce que ça renvoie », vous n'utilisez pas le spec comme contrat. Le spec doit être le fichier unique utilisé pour la génération de code et la revue, et les serveurs doivent valider requêtes et réponses contre lui même en dev ou staging.