Les applications créées par l'IA échouent avec de vrais utilisateurs : 3 pièges de la démo à repérer
Les applications créées par l'IA échouent avec de vrais utilisateurs lorsque les démos ignorent les cas limites. Voyez les scénarios de connexion, d'email et de paiement, ainsi que les vérifications pour durcir votre application avant le lancement.
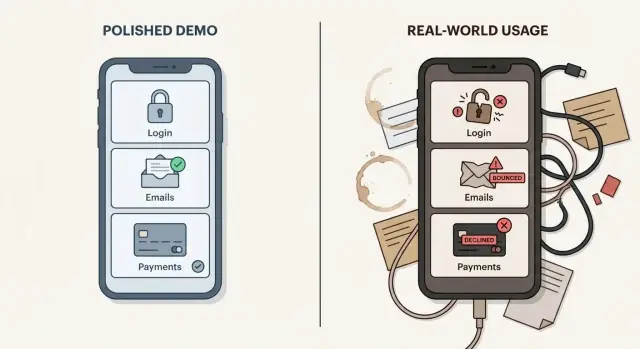
Ce qui semble correct en démo et ce qui casse en production
Une démo est un moment contrôlé. Vous utilisez un seul appareil, un seul compte, des données d'exemple propres et un parcours que vous savez déjà fonctionner. Les vrais utilisateurs font l'inverse. Ils cliquent dans le désordre, réutilisent d'anciens liens, se trompent de mot de passe, rafraîchissent au mauvais moment et essaient sur des téléphones que vous n'avez jamais testés.
C'est pourquoi les applications créées par l'IA échouent avec de vrais utilisateurs même quand la démo semble parfaite. Un prototype prouve souvent qu'une idée est possible, pas qu'elle est fiable.
Les premiers utilisateurs se comportent aussi différemment de ce que le créateur attend. Ils ne lisent pas les instructions. Ils s'inscrivent avec des emails professionnels, personnels, et parfois temporaires. Ils ouvrent l'app derrière des pare‑feux d'entreprise. Ils essaient de payer avec des cartes de différents pays. Et ils posent des questions au support le jour même, parce que tout ce qui est « en ligne » devrait juste fonctionner.
En démo, « ça marche » signifie souvent « je peux compléter le happy path une fois ». En production, « ça marche » inclut la fiabilité, la sécurité, la maintenabilité et la récupération. Les actions clés doivent réussir de façon répétée (même avec une mauvaise connexion). Les données privées doivent rester privées. Lorsqu'une chose échoue, vous devez avoir suffisamment de visibilité pour comprendre ce qui s'est passé et aider rapidement. Et vous devez avoir des moyens sûrs de réessayer, revenir en arrière ou corriger des problèmes sans tout casser.
Vous n'avez pas besoin de perdre la vitesse qui vous a mené au prototype. Gardez le même flux, mais ajoutez les vérifications peu glamour : gestion robuste des erreurs, logs, limites de débit, stockage sûr des identifiants et tests avec des données « sales ».
Pourquoi les prototypes générés par l'IA coupent des coins
Le code généré par l'IA est souvent optimisé pour « montrer quelque chose qui fonctionne » le plus rapidement possible. Les démos récompensent le happy path : un compte, un appareil, un réseau propre et des entrées prévisibles. La production récompense l'inverse : la résilience.
Les prototypes sautent souvent les parties inconfortables. Que se passe‑t‑il lorsqu'une requête expire, qu'une API renvoie une réponse partielle ou que deux actions se produisent en même temps ? En démo, vous cliquez une fois et passez à la suite. En production, les gens rafraîchissent, soumettent deux fois, changent d'onglet, perdent le signal et réessaient.
Un autre problème courant est les hypothèses cachées. Le code généré par l'IA peut coder en dur des valeurs qui semblent inoffensives le premier jour : un rôle utilisateur fixe, un seul réglage d'environnement, une clé d'API temporaire, une seule devise ou un seul fuseau horaire. Ça marche en local puis ça casse après le déploiement, l'accès en équipe ou le premier client réel.
La plupart des pièces manquantes sont ennuyeuses, mais elles empêchent l'accumulation de tickets support : gestion des timeouts et des retries, validation des entrées avec messages utiles, traitement des échecs partiels, suppression des paramètres et secrets réservés à la démo, et ajout de logs qui pointent vers la vraie cause.
Imaginez un flux simple : un utilisateur s'inscrit, reçoit un email de confirmation, puis paie. Une démo prouve que les boutons fonctionnent. La production doit prouver que toute la chaîne tient sous contrainte, et qu'elle échoue en douceur quand quelque chose en amont casse.
Scénario 1 - La connexion marche une fois, puis les utilisateurs sont bloqués
Une connexion en démo suit habituellement le chemin le plus heureux : un compte test, votre laptop, un seul navigateur, connexion stable. Vous vous connectez, arrivez sur un tableau de bord et tout le monde hoche la tête.
Les vrais utilisateurs ne se comportent pas ainsi. Ils se connectent depuis un téléphone et un ordinateur pro. Ils oublient leurs mots de passe. Ils cliquent sur « Se connecter avec Google » dans un navigateur intégré. Ils ferment l'onglet, reviennent le lendemain et s'attendent à rester connectés.
Beaucoup de bugs « ça marche une fois » viennent de quelques points de rupture :
- Les callbacks OAuth sont pointilleux. L'URL de callback doit correspondre exactement, et de petites différences de redirection peuvent casser l'étape finale après que le fournisseur a dit « Success ».
- Les cookies et sessions peuvent être configurés d'une manière qui ne fonctionne que sur localhost, uniquement dans un navigateur ou échoue sous des paramètres de confidentialité plus stricts.
- Les sessions expirent, mais l'app ne se récupère pas proprement, ce qui coince les utilisateurs dans des boucles.
Ce que les utilisateurs rapportent est presque toujours vague : « Je peux me connecter une fois, puis ça arrête de marcher. » Cette phrase unique peut masquer tout, d'un cookie mal configuré à une requête cross‑site bloquée ou une redirection qui fait tomber un token.
Avant d'inviter des gens, exécutez quelques vérifications simples (pas besoin d'un niveau technique profond). Connectez‑vous sur votre téléphone et sur un deuxième appareil et confirmez que les deux restent connectés. Fermez l'onglet et revenez dans 10 minutes, puis dans 24 heures. Essayez la réinitialisation de mot de passe et confirmez que le nouveau mot de passe fonctionne immédiatement. Testez une fenêtre en navigation privée et un autre navigateur. Et demandez à quelqu'un hors de votre réseau de s'inscrire depuis sa connexion.
Si l'un de ces tests échoue, marquez une pause et diagnostiquez. L'authentification est souvent le blocage unique qui transforme un prototype « fonctionnel » en quelque chose dont les utilisateurs se détournent immédiatement.
Scénario 2 - Les emails partent en test, mais n'atteignent jamais les clients
En démo, l'email paraît « terminé » parce que vous l'essayez une fois et il arrive dans votre boîte. Cela peut être vrai même si le système n'est pas prêt pour de vrais utilisateurs.
L'écart apparaît dès que vous envoyez à des personnes hors de votre équipe. Les boîtes filtrent agressivement, et votre domaine a une réputation (ou pas encore). Si SPF, DKIM et DMARC manquent ou sont mal configurés, de nombreux fournisseurs traitent les messages comme suspects. Du point de vue de votre app, l'email est « envoyé », mais l'utilisateur ne le voit jamais.
D'autres points de rupture sont plus simples et tout aussi pénibles. L'adresse de l'expéditeur est erronée. Le nom de l'expéditeur déclenche des règles anti‑spam. Un modèle s'affiche correctement dans un client mais casse dans un autre. Les liens pointent vers localhost ou un domaine de staging. Si vous envoyez en rafale (par exemple en important une liste d'attente), des limites de débit s'enclenchent et vous perdez des messages à moins de mettre en file d'attente et de réessayer.
L'impact pour l'utilisateur est immédiat : pas d'email de vérification signifie pas de compte. Pas de réinitialisation signifie tickets support. Pas d'email de reçu signifie que les gens pensent avoir été débités sans rien recevoir, même si le paiement a bien eu lieu.
Avant d'accuser « l'email instable », vérifiez les basiques : logs du fournisseur (accepted, deferred, rejected), événements de bounce et de plainte, alignement SPF/DKIM/DMARC, et un petit test multiplaqueforme sur Gmail, Outlook et Apple Mail. Analysez aussi les modèles pour détecter des liens cassés et tout ce qui ressemble à du staging.
Un échec courant ressemble à ceci : votre inscription fonctionne pour votre propre adresse, mais un client sur Outlook ne reçoit jamais l'email de vérification. Il clique sur « renvoyer » cinq fois, et votre app le throttled ou le bloque. Souvent le vrai problème est la délivrabilité plus un problème de template, si bien que même les emails délivrés mènent à une impasse.
Scénario 3 - Les paiements réussissent en sandbox, échouent avec de vraies cartes
Les paiements en sandbox sont conçus pour être amicaux. Les cartes de test approuvent souvent, et le « happy path » semble parfait. Les banques réelles ne se comportent pas comme une sandbox, et l'app doit gérer des issues plus complexes.
Avec de vraies cartes, des contrôles supplémentaires apparaissent. Un utilisateur peut se heurter au 3D Secure et abandonner le flux. Les contrôles AVS/CVC peuvent échouer si l'adresse de facturation diffère légèrement. Les banques refusent pour des raisons imprévisibles. Ajoutez la conversion de devises, les taxes et les règles régionales, et votre bouton « payer » devient un ensemble de branches.
La panne la plus fréquente en production n'est pas le formulaire de paiement. C'est tout ce qui l'entoure, surtout les webhooks. En démo, on a tendance à supposer « paiement réussi » et à débloquer l'accès immédiatement. En production, l'événement webhook est la source de vérité, et il peut arriver en retard, arriver deux fois ou ne jamais arriver si l'endpoint est mal configuré.
Surveillez ces motifs du premier jour :
- Accès accordé avant confirmation, puis le prélèvement échoue ou est annulé.
- Webhooks ignorés, donc les utilisateurs paient mais leur compte ne se met pas à jour.
- Pas d'idempotence, donc les retries créent des prélèvements en double.
- Conditions de concurrence entre la page « succès » et le traitement du webhook.
Les tickets support suivent le même scénario : un client voit « paiement échoué », réessaye, puis constate deux prélèvements. Ou il obtient l'accès alors que le paiement n'a jamais abouti, ce qui entraîne le chaos des remboursements.
Ce qu'il faut valider avant que de vrais utilisateurs paient est simple, mais non négociable : flux webhook bout en bout, clés d'idempotence sur les actions de création/confirmation, et chemins propres d'annulation et de remboursement. Testez volontairement des échecs (CVC incorrect, 3D Secure échoué, carte refusée) et confirmez que votre base de données reste cohérente.
Pas à pas - Transformer un prototype en version prête pour les utilisateurs
Quand les applications créées par l'IA échouent avec de vrais utilisateurs, ce n'est rarement un gros bug. Ce sont beaucoup de petits manques que la démo n'a jamais atteints. Le chemin le plus rapide est de choisir quelques parcours réels et de les rendre ennuyeusement fiables.
Commencez par écrire les cinq parcours utilisateurs les plus importants en langage simple : inscription, connexion, vérification d'email, réinitialisation de mot de passe et paiement. Pour chacun, définissez ce que « réussir » signifie pour l'utilisateur et ce qui doit être vrai dans votre base de données.
Ensuite, ajoutez des logs de base pour pouvoir répondre rapidement à trois questions : qu'est‑ce qui a échoué, pour quel utilisateur et pourquoi. Vous n'avez pas besoin de tableaux de bord sophistiqués à ce stade, juste assez de miettes de pain pour arrêter de deviner.
Une séquence pratique qui marche pour la plupart des équipes :
- Définir les cinq parcours et une courte checklist de succès pour chacun.
- Ajouter des logs autour des points risqués (callbacks d'auth, envois d'email, confirmation de paiement).
- Tester volontairement les cas limites : mauvais mot de passe, lien de réinitialisation expiré, réseau lent, double‑clic sur « Payer ».
- Ajouter des garde‑fous : timeouts, retries sûrs et messages d'erreur indiquant la marche à suivre.
- Lancer un petit pilote (5–20 utilisateurs), puis corriger ce qu'ils rencontrent avant d'inviter plus.
Un petit changement qui rapporte tout de suite : si la réinitialisation de mot de passe échoue, n'affichez pas « Quelque chose s'est mal passé. » Dites à l'utilisateur si le lien a expiré, proposez de renvoyer et consignez la raison exacte (token invalide, utilisateur non trouvé, rejet du fournisseur).
Les risques cachés - sécurité, secrets et intégrité des données
Un prototype peut sembler « terminé » parce que le happy path fonctionne. En production, beaucoup d'échecs sont en réalité des problèmes de sécurité et de cohérence des données qui se manifestent comme des « bugs aléatoires ».
Problèmes de sécurité qui ressemblent à des glitches ordinaires
Les équipes non techniques vivent souvent ces problèmes comme des comportements instables : quelqu'un est déconnecté, une fonctionnalité marche pour une personne mais pas pour une autre, ou des données « disparaissent ». En coulisses, cela peut être une faille de sécurité.
Les problèmes courants dans le code généré par l'IA incluent des secrets exposés (clés API dans les dépôts, bundles front ou logs), des autorisations cassées (un utilisateur peut accéder aux enregistrements d'un autre en changeant un ID) et des risques d'injection (des entrées insérées dans des requêtes DB sans traitement sûr). Un exemple réaliste : un écran admin semble correct en test, mais en production n'importe quel utilisateur connecté peut le charger parce que l'app vérifie « est connecté » et oublie de vérifier « est admin ».
Intégrité des données : l'app fonctionne jusqu'au moment où elle ne fonctionne plus
Les problèmes de données sont plus difficiles à repérer que les bugs UI. Vous les voyez souvent seulement après que l'utilisation réelle a créé des cas limites.
Surveillez les actions dupliquées (double‑clics ou retries créant des commandes en double), les transactions manquantes (étape 1 réussit, étape 2 échoue, laissant des données à moitié mises à jour) et les mises à jour partielles (l'UI dit « enregistré », mais seuls certains champs ont changé).
Pièges courants que les équipes manquent quand elles expédient
Une démo récompense le happy path. Les vrais utilisateurs apportent mots de passe oubliés, connexions lentes, sessions expirées et timings étranges.
Une erreur est de se fier au premier succès. Si vous avez testé la connexion une fois sur votre laptop, vous n'avez toujours pas testé ce qui arrive après une déconnexion, un rafraîchissement, un second appareil ou une session qui expire pendant la nuit. L'app peut sembler stable alors qu'elle est à un cas limite de bloquer des gens.
Un autre piège est de repousser les fonctions de récupération. Réinitialisation de mot de passe, changement d'email et récupération de compte semblent être des extras jusqu'au premier client qui ne peut plus se reconnecter. Alors le support devient votre produit, et vous patchez des flux qui touchent du code sensible à la sécurité sous pression.
Le travail d'arrière‑plan est là où beaucoup de prototypes coupent les coins. Emails, mises à jour de paiement et synchronisation des données dépendent souvent de webhooks, files d'attente et jobs planifiés. Si ces pièces manquent ou sont fragiles, tout semble correct quand vous cliquez sur des boutons, mais l'état réel du système dérive sur des heures et des jours.
Quelques pièges récurrents :
- Une fonctionnalité « marche une fois » mais échoue la deuxième fois parce que l'état est stocké dans le navigateur au lieu du serveur.
- La récupération de compte manque, si bien qu'une mauvaise tentative de connexion fait perdre un utilisateur.
- Les événements webhook ne sont pas entièrement traités, donc remboursements, paiements échoués et bounces ne mettent jamais à jour la base.
- Il n'y a pas de plan de monitoring, vous apprenez les incidents via des messages furieux et non par des alertes.
- La structure du code part en spaghetti rapidement, rendant chaque correction risquée.
Exemple : vous lancez une beta payante lundi. Mardi, la carte d'un utilisateur est refusée, mais votre app marque toujours la commande comme payée parce qu'elle n'a vérifié que la réponse initiale du checkout. Jeudi, votre boîte support est pleine et vous ne pouvez pas reproduire le problème car il dépend du timing des webhooks.
Checklist rapide avant d'inviter de vrais utilisateurs
Avant d'envoyer des invitations, faites une courte « répétition utilisateur réel ». Les démos cachent le quotidien : changer d'appareil, oublier son mot de passe, double‑cliquer sur un bouton et utiliser des données désordonnées.
Effectuez ces vérifications dans un environnement staging avec deux comptes (un tout neuf, un existant). Notez ce qui se passe et combien de temps chaque étape prend.
- Boucle compte : créez un compte, confirmez‑le (si nécessaire), déconnectez‑vous, puis reconnectez‑vous sur un autre appareil ou profil de navigateur.
- Boucle réinitialisation : déclenchez une réinitialisation, vérifiez que l'email arrive rapidement (objectif : < 2 minutes) et confirmez que le lien de réinitialisation fonctionne une seule fois.
- Boucle paiements : testez un prélèvement réussi, une carte refusée, un remboursement et un double‑clic sur Payer.
- Vérification des secrets : inspectez le build frontend et les appels réseau et confirmez qu'aucune clé API, URL de base de données ou token de service n'est exposé au navigateur.
- Vérification de visibilité : forcez une erreur (secret webhook incorrect, adresse email invalide, paiement échoué) et confirmez que vous la voyez clairement dans les logs avec assez de détails pour agir.
Un moyen pratique d'exécuter cela : demandez à un ami de faire les étapes sans aide. S'il se perd ou si vous ne pouvez pas diagnostiquer rapidement les échecs, arrêtez le lancement et comblez ces lacunes d'abord.
Exemple réaliste d'une semaine de lancement (et comment récupérer)
Un fondateur construit une app faite par l'IA, réussit la démo et invite 50 bêta‑utilisateurs lundi. La première heure est excellente. À midi, les messages support commencent à s'accumuler.
Le jour 1, trois petites fissures deviennent de vrais problèmes. Certains utilisateurs tombent dans une boucle de connexion après avoir réinitialisé un mot de passe parce que les sessions et redirections étaient gérées de manière lâche. D'autres ne reçoivent jamais les emails de vérification parce que l'app utilisait une configuration d'expéditeur de test qui fonctionnait en local mais pas dans de vraies boîtes. Quelques personnes paient, voient un écran de succès et ne peuvent toujours pas accéder à l'espace payant parce que l'app considérait « paiement réussi » et « abonnement actif » comme la même chose.
Le jour 2, le fondateur fait des corrections manuelles : suppression de comptes, basculement de flags dans la base et demande aux utilisateurs de réessayer. Des utilisateurs confus s'inscrivent deux fois, les fournisseurs d'email commencent à throttler et certains clients demandent des remboursements après avoir été débités mais bloqués. L'app n'est pas « en panne », mais la confiance est brisée.
Un sprint de réparation ciblé diffère du patching aléatoire. L'objectif est de rendre fiables les principaux parcours avant d'ajouter quoi que ce soit de nouveau :
- Reproduire les échecs bout en bout pour les flux clés (connexion, vérif email, paiement, déblocage d'accès).
- Corriger les causes racines, pas les symptômes (tokens, redirections, webhooks, vérifications d'état).
- Ajouter des garde‑fous comme limites de débit, retries sûrs et messages d'erreur clairs.
- Retester dans des conditions réelles (comptes frais, vraies boîtes, vraies cartes).
- Relancer une petite beta (5–10 utilisateurs) avant de rouvrir l'accès.
Puis prenez une décision claire sur le périmètre. Patchez quand l'architecture est majoritairement saine et les défaillances sont isolées. Refactorez quand le même modèle de bug apparaît partout. Reconstruisez quand la base de code est trop enchevêtrée pour raisonner en sécurité, ce qui est courant avec des prototypes générés par l'IA.
Prochaines étapes - clarifiez, puis corrigez les bonnes choses en priorité
Si votre app a été construite avec des outils comme Lovable, Bolt, v0, Cursor ou Replit, supposez qu'elle a été optimisée pour une démo. Cela ne signifie pas qu'elle est mauvaise. Cela signifie que vous devez vous attendre à des raccourcis autour de la connexion, des emails, des paiements et de la sécurité.
Avant de réécrire quoi que ce soit, clarifiez ce qui échoue réellement. Les équipes perdent des semaines à reconstruire les mauvaises parties lorsqu'elles partent d'opinions plutôt que de preuves.
Collectez des preuves d'utilisation réelle et réduisez‑les aux quelques parcours qui comptent. Un utilisateur ne peut pas réinitialiser son mot de passe, un autre ne reçoit jamais un email de bienvenue, et un troisième voit une erreur de paiement avec une vraie carte. C'est suffisant pour planifier le sprint suivant.
Ce qu'il faut rassembler en un court passage :
- 3–5 rapports utilisateurs avec étapes exactes (ce qu'ils ont cliqué et ce qu'ils attendaient)
- Captures d'écran des erreurs et texte complet des messages
- Les 3 flux cassés qui bloquent les inscriptions ou les revenus
- Notes sur où cela arrive (appareil, navigateur, heure)
- Accès aux logs ou à ce que votre hébergeur fournit
Ensuite, demandez un diagnostic avant de reconstruire. Un audit solide mappe les symptômes aux causes racines (gestion de session, configuration de domaine email, validations manquantes, webhooks non traités) et classe les corrections par impact.
Si vous avez hérité d'un prototype généré par l'IA qui casse en usage réel, FixMyMess (fixmymess.ai) se concentre sur le diagnostic et la réparation de ces lacunes précises : authentification, délivrabilité, logique de webhooks, durcissement de la sécurité et nettoyage qui rend le code sûr à livrer. Un audit rapide peut transformer « ça marche en démo » en une liste de corrections priorisées que vous pouvez exécuter en toute confiance.
Questions Fréquentes
Why does my app look perfect in a demo but fall apart with real users?
Une démo prouve une seule fois le « happy path », dans vos conditions. La production doit gérer une utilisation répétée, des entrées désordonnées, des réseaux lents, des sessions expirées, plusieurs appareils et des utilisateurs qui cliquent dans le « mauvais » ordre.
What should I fix first before inviting real users?
Concentrez-vous sur les parcours essentiels qui créent de la confiance et des revenus : inscription, connexion, vérification d'email, réinitialisation de mot de passe et paiement. Faites en sorte que chacun fonctionne de façon répétée et que les échecs soient compréhensibles pour que l'utilisateur puisse se rétablir sans vous contacter.
Why do users say “I can log in once, then it stops working”?
Il s'agit généralement d'un problème de session ou de redirection, pas du bouton de connexion en lui‑même. Les cookies peuvent être configurés pour ne fonctionner qu'en localhost, ou être bloqués par certains paramètres de confidentialité ou navigateurs, ce qui provoque des boucles après la première connexion réussie.
What’s the most common OAuth mistake in AI-generated apps?
Les fournisseurs OAuth exigent des URLs de callback et des comportements de redirection exacts. Une toute petite différence entre environnements peut donner « Success » côté fournisseur alors que votre application ne termine jamais correctement la session, renvoyant l'utilisateur à l'écran de connexion.
Why do emails work for me but customers never receive them?
Envoyer n'est pas synonyme de délivrer. Si votre domaine n'a pas SPF, DKIM et DMARC configurés, de nombreuses boîtes traiteront vos messages comme suspects. Ainsi, les emails de vérification et de réinitialisation n'atteignent pas les clients alors que votre application pense les avoir envoyés.
What should I check in email templates before launch?
Souvent il s'agit d'un artefact de staging : des liens qui pointent encore vers localhost ou un domaine de test, ou une identité d'expéditeur qui déclenche les filtres anti‑spam. Même si l'email arrive, un lien cassé ou un mauvais environnement transforme le message en impasse.
Why do payments succeed in sandbox but fail with real cards?
Les sandboxes sont indulgentes ; les banques réelles ne le sont pas. 3D Secure, contrôles AVS/CVC, refus bancaires et règles régionales compliquent le flux. Ne supposez pas qu'une page de paiement réussie équivaut à un paiement effectif.
What are the biggest webhook mistakes that cause billing chaos?
En production, les webhooks sont la source de vérité ; ils peuvent arriver en retard, arriver plusieurs fois ou échouer s'ils sont mal configurés. Sans idempotence et gestion cohérente des webhooks, vous verrez des doubles prélèvements, des utilisateurs payés sans accès ou l'accès accordé sans paiement réussi.
What security issues hide inside “random” production glitches?
Les prototypes générés par l'IA exposent souvent des secrets dans le frontend ou les logs, et l'autorisation est fréquemment mal gérée, permettant à des utilisateurs d'accéder à des données qu'ils ne devraient pas voir. Ces problèmes se manifestent comme des bugs aléatoires mais sont en réalité des failles de sécurité.
When should I patch vs refactor vs rebuild, and who can help?
Capturez assez de détails pour répondre : qu'est‑ce qui a échoué, pour quel utilisateur, et pourquoi. Reproduisez l'échec bout en bout. Si vous colmatez sans fin ou si le code est trop emmêlé, une audit ciblée peut classer les corrections par impact ; FixMyMess se spécialise dans la réparation d'apps générées par l'IA et peut transformer cela en plan clair rapidement, souvent en 48–72 heures après le diagnostic.