Arrêt gracieux des serveurs Node : éviter les 502 aléatoires
Apprenez l'arrêt gracieux des serveurs Node pour drainer les connexions keep-alive, finir les requêtes en cours, fermer les pools DB et éviter les 502 aléatoires lors des déploiements.
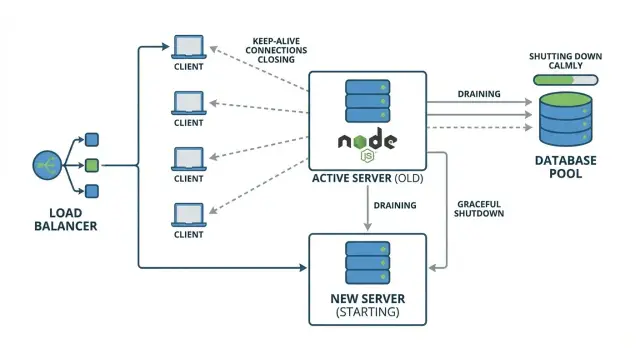
Pourquoi les déploiements peuvent provoquer des 502 aléatoires
Un « 502 aléatoire » pendant un déploiement signifie généralement que votre reverse proxy ou load balancer a envoyé une requête à une instance d'application déjà en train de s'arrêter. Pendant un bref instant, le proxy peut encore considérer cette instance comme disponible, ou il peut réutiliser une connexion existante qui n'a plus un serveur sain à l'autre bout.
Ça paraît aléatoire parce que c'est une question de timing. La plupart des utilisateurs touchent des instances encore en fonctionnement et obtiennent une réponse normale. Un plus petit groupe tombe sur la fenêtre malchanceuse : leur requête arrive au moment précis où le processus se termine, où le serveur arrête d'écouter, ou juste après qu'une connexion soit coupée.
Le keep-alive peut aggraver le problème. Les clients et les proxies réutilisent des connexions TCP existantes pour plusieurs requêtes, donc pendant un déploiement vous pouvez avoir des connexions longue durée qui envoient encore des requêtes à une instance que vous essayez de remplacer. Si l'app ferme le serveur immédiatement, ces connexions réutilisées échouent de façon déroutante, et le proxy signale souvent un 502.
L'idée centrale est l'arrêt gracieux : arrêter de prendre du nouveau travail, terminer le travail déjà en cours, puis sortir.
Un exemple simple : vous déployez une nouvelle version, votre orchestrateur envoie un signal d'arrêt, et Node sort immédiatement. Un utilisateur est en plein paiement (une requête en cours). Le navigateur d'un autre utilisateur réutilise une connexion keep-alive pour charger la page suivante. Les deux requêtes sont abandonnées. Tout le monde d'autre, routé vers d'autres instances, ne remarque rien.
Un shutdown qui draine les connexions et attend un peu pour les requêtes en vol évite ces échecs « aléatoires » et rend les déploiements prévisibles.
Ce que vous arrêtez réellement
Un serveur Node n'est pas juste « un processus qui s'arrête ». C'est un processus en pleine conversation avec des clients, tenant ouverts des ressources comme des sockets, timers et connexions de base de données. L'arrêt gracieux consiste surtout à terminer ces conversations dans le bon ordre.
Un cycle typique de requête ressemble à ceci : un client se connecte, envoie une requête, votre app exécute du code (souvent en appelant une base de données ou une API externe), puis le serveur envoie une réponse et la requête est terminée. Si vous tuez le processus au milieu, le client reçoit une réponse corrompue, et votre load balancer peut la rapporter comme un 502.
Les « requêtes en cours » sont celles qui ont démarré mais n'ont pas fini. Ce sont celles les plus susceptibles d'être coupées pendant un déploiement. Même des requêtes courtes peuvent devenir « en cours » si la base est lente, une API tierce se bloque, ou la boucle d'événements est occupée.
Le keep-alive ajoute une couche supplémentaire. Une connexion TCP peut transporter plusieurs requêtes dans le temps. Pendant le shutdown, vous voulez arrêter de prendre de nouvelles requêtes, mais vous pouvez encore avoir des sockets keep-alive ouverts qui sont inactifs ou qui attendent la prochaine requête.
Certaines tâches restent « en cours » plus longtemps et demandent plus d'attention : uploads (gros fichiers, clients lents), exports/génération de rapports, réponses en streaming et Server-Sent Events (SSE), et WebSockets (ce ne sont pas des « requêtes » classiques, mais ce sont des connexions actives).
Vous arrêtez donc trois choses : le trafic entrant nouveau, les requêtes en cours, et toute connexion longue qui maintient le processus occupé alors qu'il semble inactif.
Signaux et timing : comment le shutdown est déclenché
La plupart des problèmes de déploiement commencent de la même façon : votre processus Node reçoit l'ordre d'arrêter, mais personne n'est sûr du délai accordé pour terminer.
Sous Linux, deux signaux importent le plus :
- SIGTERM : « Veuillez quitter maintenant, mais nettoyez d'abord. » C'est ce que les plateformes envoient lors d'un arrêt ou d'un déploiement normal.
- SIGINT : « Arrêtez parce qu'un humain l'a demandé. » C'est ce que vous obtenez avec Ctrl+C dans un terminal.
Les process managers et containers suivent généralement une séquence simple : un déploiement commence, l'ancienne instance reçoit SIGTERM, et un compte à rebours démarre (souvent appelé période de grâce). Si l'app sort à temps, parfait. Sinon la plateforme envoie un kill brutal (SIGKILL) et le processus disparaît instantanément.
Si vous ne faites rien, Node continuera de tourner jusqu'à ce qu'on le force. Cela veut dire que les sockets keep-alive peuvent être coupés en plein milieu d'une requête, des travaux en cours peuvent ne jamais finir, et des connexions de base de données peuvent rester pendantes. Le résultat apparaît comme des 502 « aléatoires », même si vos logs d'app ont l'air normaux.
Rendez le comportement d'arrêt cohérent, pas au coup par coup. Décidez d'emblée quel signal vous gérez (généralement SIGTERM), combien de temps vous attendrez avant de forcer la sortie, et ce qui s'arrête en premier (le nouveau trafic) versus ce que vous essayez de finir (les requêtes en cours).
Quand le shutdown est prévisible, les déploiements ne dépendent plus de la chance.
Étape par étape : arrêter de recevoir du trafic en toute sécurité
Un déploiement ne devrait pas ressembler à tirer la prise. L'objectif est simple : arrêter le nouveau trafic d'abord, puis finir ce qui est déjà en cours.
Commencez par ajouter un simple drapeau "draining" dans votre app. Quand il passe à true, le serveur est encore en vie, mais il se prépare à sortir.
Un ordre sûr pour la plupart des API HTTP :
- Passez
draining = truedès que vous recevez le signal d'arrêt. - Faites échouer votre readiness check, afin que le load balancer cesse de router de nouvelles requêtes vers cette instance.
- Pour toute nouvelle requête qui arrive encore, renvoyez un clair
503 Service Unavailableavec un message court. - Dites au serveur HTTP d'arrêter d'accepter de nouvelles connexions.
- Gardez le processus vivant pendant que les requêtes existantes se terminent (avec un timeout, détaillé ci-dessous).
Un petit exemple (style Express) ressemble à ceci :
let draining = false;
app.get('/ready', (req, res) => {
if (draining) return res.sendStatus(503);
res.sendStatus(200);
});
app.use((req, res, next) => {
if (draining) return res.status(503).send('Server is restarting, try again');
next();
});
process.on('SIGTERM', () => {
draining = true;
server.close(); // stop accepting new connections
});
Gardez les health checks honnêtes. Pendant le shutdown, vous voulez que « ready » vire rapidement au rouge, mais vous voulez aussi qu'un check basique « alive » reste vert jusqu'à la sortie effective. Ça évite que la plateforme tue le processus trop tôt et crée les 502 que vous essayez d'éviter.
Drainer les connexions keep-alive sans couper les utilisateurs
Le keep-alive permet au navigateur (ou au load balancer) de réutiliser la même connexion TCP pour plusieurs requêtes. C'est bon pour les performances, mais ça surprend pendant les déploiements : vous arrêtez d'accepter de nouvelles connexions, et pourtant des sockets keep-alive anciennes restent ouvertes et peuvent envoyer une nouvelle requête à une instance en train de se vider.
server.close() de Node arrête les nouvelles connexions, mais ne ferme pas automatiquement les sockets keep-alive existantes. Pour drainer en toute sécurité, suivez les sockets à leur connexion, puis fermez doucement celles qui sont inactives tout en laissant les requêtes actives se terminer.
Un pattern simple :
- Gardez un
Setde sockets depuis l'événementconnectiondu serveur. - Marquez les sockets comme « occupées » pendant qu'une requête est en cours.
- Au shutdown, appelez
server.close(), puissocket.end()pour les sockets inactives. - Après un délai,
socket.destroy()pour tout ce qui reste ouvert.
Voici un exemple compact :
const sockets = new Set();
const busy = new Set();
server.on('connection', (socket) => {
sockets.add(socket);
socket.on('close', () => { sockets.delete(socket); busy.delete(socket); });
});
server.on('request', (req, res) => {
busy.add(req.socket);
res.on('finish', () => busy.delete(req.socket));
});
async function shutdown() {
server.close();
for (const s of sockets) if (!busy.has(s)) s.end();
setTimeout(() => { for (const s of sockets) s.destroy(); }, 10_000);
}
Ce délai de fermeture forcée est important. Sans lui, un client bloqué peut maintenir l'ancienne instance vivante et transformer un rollout en une série de timeouts et d'erreurs proxy intermittentes.
Terminer les requêtes en cours avec un timeout clair
Quand un déploiement commence, vous voulez que les requêtes existantes se terminent normalement, mais vous avez aussi besoin d'un arrêt forcé pour que l'ancienne instance ne traîne pas indéfiniment. L'approche la plus simple est de suivre les requêtes actives et d'utiliser un flag draining.
Voici un petit pattern qui fonctionne avec la plupart des frameworks HTTP Node :
let draining = false;
let active = 0;
app.use((req, res, next) => {
if (draining) return res.status(503).set('Connection', 'close').send('Server restarting');
active += 1;
res.on('finish', () => { active -= 1; });
res.on('close', () => { active -= 1; });
next();
});
function beginShutdown() {
draining = true;
}
Pendant le draining, évitez de lancer du travail qui survivra à la requête. Une erreur courante est de laisser une requête mettre en file des tâches en arrière-plan (emails, rapports, cleanup) après que vous avez décidé d'arrêter. Si vous devez mettre en file, protégez-le avec le même flag draining et ignorez ces actions pendant le shutdown.
Définissez un timeout de shutdown adapté à votre trafic. Beaucoup d'équipes commencent avec 10 à 30 secondes, puis ajustent selon les endpoints vraiment lents.
Le flux est simple : commencez le draining et arrêtez d'accepter de nouvelles requêtes, attendez que active === 0, et si le timer arrive à son terme, forcez la fermeture des connexions restantes et sortez.
Si une requête arrive après le début du draining, renvoyez 503 Service Unavailable et ajoutez Connection: close. Cela indique aux clients et aux load balancers de ne pas garder la socket, ce qui réduit les échecs keep-alive à moitié fermés qui apparaissent souvent comme des 502.
Fermer proprement les pools DB et autres ressources
Fermer votre serveur HTTP n'est pas la même chose que laisser le processus Node sortir. Un pool de base de données garde des sockets TCP ouverts (et parfois des timers), donc l'event loop peut encore avoir du travail. C'est pourquoi un déploiement peut sembler « terminé » alors que l'ancienne instance traîne, puis se fait tuer et produit des erreurs.
« Fermer le pool » veut dire généralement : arrêter de distribuer de nouvelles connexions, fermer les inactives, et attendre que les requêtes actives se terminent. Exemples courants :
- PostgreSQL (
pg) :await pool.end() - MySQL (
mysql2) :await pool.end() - Mongoose :
await mongoose.connection.close()(et arrêter les nouvelles opérations)
L'ordre compte. Arrêtez d'accepter le nouveau trafic en premier (pour ne pas démarrer de nouveaux travaux DB), laissez les requêtes en cours finir, puis fermez le pool DB. Après cela, fermez le reste.
Les requêtes et transactions en attente ont besoin d'une règle claire. Pendant le shutdown, bloquez les nouvelles requêtes qui démarrent des écritures, laissez les requêtes courantes finir jusqu'à un timeout, puis échouez rapidement. Si vous avez de longues transactions, visez à les terminer rapidement et à rollbacker si vous atteignez la deadline.
async function shutdown() {
server.close(); // stop new HTTP connections
await Promise.race([
waitForInFlightToFinish(),
sleep(10_000),
]);
await dbPool.end();
await redis?.quit();
await queue?.close();
}
D'autres ressources qui maintiennent un processus vivant incluent les clients Redis, les queues de jobs, les connexions Kafka/Rabbit, les timers cron et les handles fichiers ouverts. Les fermer explicitement transforme le shutdown en quelque chose de fiable.
Jobs en arrière-plan : ne pas oublier le travail caché
Le trafic HTTP n'est qu'une partie de l'histoire. Beaucoup de serveurs Node exécutent du travail en arrière-plan dans le même processus : consommateurs de queue, tâches cron, refresh planifiés et boucles workers. Pendant un déploiement, ceux-ci peuvent garder le processus vivant plus longtemps que prévu, ou continuer à toucher la base après le début du shutdown.
La première règle : une fois le shutdown lancé, arrêtez de démarrer de nouveaux travaux en arrière-plan. Mettez en pause la consommation des queues, arrêtez le polling, et empêchez le cron de lancer de nouvelles exécutions. Si vous utilisez une librairie, cherchez une vraie méthode pause/stop (pas juste disconnect), car la déconnexion peut déclencher des retries et du bruit supplémentaire.
Après avoir stoppé les nouveaux jobs, laissez les jobs en cours finir, mais seulement jusqu'à une limite claire. Sinon un job bloqué peut retarder la sortie jusqu'à ce que la plateforme tue le processus, moment où les erreurs explosent.
Annuler en sécurité vs attendre
Choisissez selon ce que fait le job :
- Attendez les travaux avec une borne supérieure connue (envoyer un email, redimensionner une image).
- Annulez les jobs longs dont la fin est incertaine (gros imports, appels tiers qui se bloquent).
- Annulez tout ce qui garde une transaction DB ouverte.
- Attendez les jobs qui peuvent checkpoint et reprendre plus tard.
- Annulez les jobs qui pourraient s'exécuter deux fois et causer des dégâts (double facturation, doubles remboursements).
Si vous annulez, faites-le volontairement : définissez un flag « isShuttingDown », arrêtez de tirer des messages, et laissez les jobs vérifier le flag à des points sûrs pour sortir proprement.
Que logger pour savoir ce qui a empêché la sortie
Loggez assez pour répondre à « qu'est-ce qui tournait encore ? » Capturez l'heure de départ du shutdown et le signal, les comptes de jobs actifs (par nom de queue), l'âge et les IDs du job le plus ancien, quel sous-système est encore ouvert (client queue, cron, timers), et si vous avez atteint la deadline et forcé des arrêts.
Cas spéciaux : WebSockets, streaming et uploads
Le shutdown est plus simple quand les requêtes sont courtes. Le problème commence quand les connexions restent ouvertes pendant des minutes.
WebSockets : fermer sans surprendre les utilisateurs
Les WebSockets sont longues par conception, donc ne tuez pas le processus sans prévenir. Pendant le shutdown, arrêtez d'accepter de nouvelles connexions socket, puis notifiez les clients actifs et donnez-leur une courte fenêtre pour se reconnecter.
Un pattern pratique : envoyer un événement « server restarting », arrêter les nouveaux messages, et fermer avec un code de fermeture normal (pas une erreur). Si vous avez un load balancer, assurez-vous qu'il arrête de router de nouvelles connexions vers l'instance avant de commencer à fermer les sockets.
Streaming, SSE et long polls
SSE et autres endpoints en streaming peuvent sembler « inactifs » pour les proxies même quand ils fonctionnent. Pendant le shutdown, terminez les streams proprement pour que le client puisse se reconnecter, et fixez un temps max de drainage pour ne pas attendre indéfiniment.
Avec le long polling, les clients refont la requête rapidement. Renvoyer une réponse claire « retry » vaut mieux que laisser la connexion mourir et apparaître comme un 502.
Une approche pratique : arrêtez d'accepter de nouvelles connexions d'abord, marquez l'instance comme draining dans votre health check, envoyez un message final et fermez les streams/sockets proprement, donnez un court délai pour les uploads puis interrompez-les, et utilisez un timeout unique pour tout afin que les déploiements se terminent.
Uploads de fichiers en cours
Si un client est en plein upload, couper la connexion peut corrompre le fichier et coûter des minutes. Préférez les uploads résumables quand c'est possible. Sinon, écrivez dans un fichier temporaire et « validez » seulement à la fin de l'upload.
Vérifiez aussi les timeouts côté reverse proxy (Nginx, ALB…). Un idle timeout plus court que votre stream ou upload peut ressembler à un 502 lié au déploiement même quand le code app est correct.
Erreurs courantes qui mènent encore à des 502
La plupart des 502 « aléatoires » pendant les déploiements ne sont pas aléatoires. Elles arrivent quand l'arrêt se passe dans le mauvais ordre, ou quand le load balancer continue de router vers un processus déjà en train de partir.
Une erreur de timing fréquente est d'attendre trop pour arrêter le nouveau trafic. Si vous ne commencez à drainer qu'après avoir commencé à fermer des choses, vous créez une fenêtre où de nouvelles requêtes arrivent mais des ressources critiques (comme les connexions DB) ne sont déjà plus disponibles. Le résultat ressemble à un réseau instable.
Un autre problème classique est de fermer le pool de base de données en premier. Les requêtes qui ont déjà passé le routage ont encore besoin de faire des queries, des sessions ou des transactions. Si le pool n'existe plus, ces requêtes échouent en plein vol.
Les environnements de déploiement envoient généralement SIGTERM, pas SIGINT. Si vous n'avez testé que Ctrl+C localement, votre handler de shutdown peut ne jamais s'exécuter en production. Cela arrive souvent dans du code Node généré par IA : ça marche localement jusqu'au premier vrai déploiement, puis la plateforme le tue parce qu'il ne répond pas au signal attendu.
Les problèmes qui cassent le plus souvent le shutdown sont simples : ne pas entrer en mode drain assez tôt, ne pas avoir de deadline de shutdown (ou en avoir une trop courte), garder la readiness verte pendant le draining de sorte que le trafic continue d'arriver, fermer les sockets keep-alive trop agressivement au lieu de les drainer, et oublier que le travail en arrière-plan peut maintenir le processus après la fermeture du serveur HTTP.
Si vous ne corrigez qu'une chose, corrigez les health checks. Dès le début du draining, l'instance doit cesser d'apparaître ready rapidement pour que le trafic aille ailleurs avant que vous ne détruisiez quoi que ce soit.
Checklist rapide avant un déploiement
Faites un run à blanc en staging juste avant une release. Quand le processus reçoit l'ordre d'arrêter, il doit arrêter de prendre du nouveau travail, finir ce qu'il a commencé, et ne laisser aucune bride.
Une checklist rapide :
- Envoyez un vrai signal d'arrêt (SIGTERM) et confirmez que l'app réagit immédiatement : une ligne de log claire, la readiness flippe, et le serveur cesse d'accepter de nouvelles connexions.
- Pendant le draining, confirmez que les nouvelles requêtes obtiennent une réponse contrôlée (par exemple 503 avec un message court) au lieu de rester pendantes jusqu'au timeout du load balancer.
- Créez une requête lente (sleep, requête lourde, rendu volumineux) et confirmez qu'elle peut se terminer. Confirmez aussi que vous avez un timeout dur pour que le processus sorte à l'heure même si quelque chose bloque.
- Vérifiez le nettoyage : le pool DB se ferme, les clients de message queue se déconnectent, et les timers s'arrêtent. Après la sortie, le processus ne doit pas rester vivant à cause de handles ouverts.
- Passez en revue les logs de shutdown de bout en bout : heure de départ, début du draining, compte de requêtes actives, et une ligne finale « shutdown complete ».
Une manière simple de détecter les problèmes est d'exécuter deux curl en même temps : une requête longue, puis une autre juste après l'envoi de SIGTERM. Si la longue se termine et que la nouvelle obtient une réponse rapide et prévisible, vous êtes proche.
Si votre serveur a été généré par un outil IA (Lovable, Bolt, v0, Cursor, Replit), ces hooks manquent souvent ou sont partiellement câblés. Les réparer tôt évite la sensation de « 502 aléatoires » pendant les déploiements.
Exemple : déploiement progressif sans perdre de requêtes
Imaginez une petite prod : deux instances Node API (A et B) derrière un load balancer. Les clients utilisent keep-alive, donc un onglet de navigateur peut réutiliser la même connexion TCP vers l'instance A pendant des minutes.
Pendant un déploiement rolling, le load balancer commence à envoyer les nouvelles requêtes vers B pendant qu'on remplace A. Le hic, c'est le keep-alive : même si le load balancer cesse de choisir A pour de nouvelles connexions, certains clients ont encore une connexion ouverte vers A et continueront d'envoyer des requêtes dessus.
C'est de là que viennent les 502 intermittents. Si A reçoit SIGTERM et sort vite, ces connexions réutilisées pointent soudain vers un processus qui n'existe plus. La requête suivante sur ce socket échoue et le proxy rapporte un 502.
Un shutdown gracieux évite cela en faisant trois choses dans l'ordre :
- arrêter d'accepter de nouvelles connexions sur A
- drainer les connexions keep-alive existantes
- attendre les requêtes en cours jusqu'à un timeout clair, puis fermer les pools DB et sortir
Pour tester en local ou en staging : ajoutez un endpoint lent (par exemple qui attend 10 secondes), envoyez des requêtes répétées avec keep-alive activé, puis redémarrez une seule instance. Si le drainage marche, la requête lente se termine et vous ne voyez pas de 502 intermittents.
Prochaines étapes : rendre les déploiements ennuyeux à nouveau
Le shutdown gracieux n'aide que si vous pouvez le voir fonctionner sous du vrai trafic. Ajoutez des logs de shutdown qui montrent l'ordre des événements : signal reçu, readiness flip, arrêt de l'acceptation des nouvelles requêtes, compte de requêtes actives, drain des keep-alive, pool DB fermé, sortie du processus.
Avant la prochaine release, faites un test « requête lente » en staging : rendez un endpoint volontairement lent (10–20 secondes), puis déployez pendant qu'une requête est en cours. Vous voulez deux résultats : la requête lente se termine avec succès, et les nouvelles requêtes vont vers la nouvelle instance sans erreur.
Si la base de code est en désordre ou générée par IA et que les déploiements restent imprévisibles, un audit ciblé peut être plus rapide que d'essayer des correctifs au hasard. FixMyMess (fixmymess.ai) aide les équipes à diagnostiquer les chemins de shutdown, le drainage des connexions et les problèmes de cleanup dans des apps Node héritées et générées par IA, afin que les rollouts cessent de produire des 502 surprises.