Audit des coûts pour prototypes générés par IA : réduire les dépenses API et DB
Un audit des coûts pour prototypes générés par IA vous aide à repérer les endpoints, requêtes et tâches d'arrière‑plan qui font grimper la facture, puis à corriger rapidement les principaux postes.
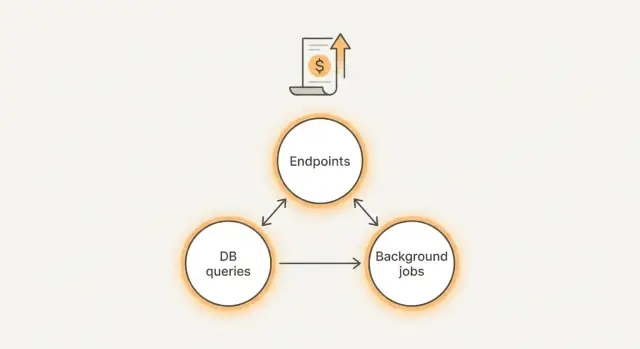
Qu'est‑ce qui fait réellement gonfler votre facture ?
Beaucoup de prototypes générés par IA deviennent chers pour une raison simple : ils fonctionnent bien en démo, mais gaspillent de l'argent en arrière‑plan. Les générateurs de code dupliquent souvent les appels, sautent la mise en cache et ajoutent du “polling utile” qui ne s'arrête jamais. Vous ne vous en rendez compte que quand de vrais utilisateurs arrivent, ou que quelques testeurs laissent l'app ouverte toute la journée.
La plupart des dépenses surprises viennent de trois endroits :
- Endpoints : un écran déclenche trop d'appels API, des retries, ou renvoie des réponses surdimensionnées.
- Requêtes : requêtes DB lentes ou non bornées qui parcourent bien plus de données que nécessaire.
- Tâches d'arrière‑plan : cron jobs, workers de queue, et webhooks qui tournent trop souvent ou ne s'arrêtent jamais.
La dépense “bonne” est ennuyeuse. Elle est prévisible et suit l'activité réelle du produit. Si vous avez 10x plus d'utilisateurs actifs, les coûts peuvent augmenter, mais la hausse est logique. La dépense “mauvaise” croît quand personne ne fait rien, ou quand une fonctionnalité déclenche discrètement des centaines d'appels.
Si vous n'avez que 30 minutes, mesurez les quelques éléments qui révèlent les problèmes rapidement :
- Endpoints principaux par nombre de requêtes et taille moyenne de réponse
- Requêtes de base de données les plus lentes et les plus fréquentes
- Tâches d'arrière‑plan par fréquence d'exécution et durée moyenne
- Appels à des API tierces par endpoint et taux d'erreur/retry
- Dépense de base pendant les heures « personne n'utilise »
Un contrôle rapide aide : ouvrez l'app, faites une action normale (par ex. charger un tableau de bord) et observez ce qui se déclenche. Si cette seule action lance 20 requêtes, trois longues requêtes et un pic de file de jobs, vous avez trouvé votre point de départ.
Reliez la dépense à des fonctionnalités réelles (pas à un vague « usage »)
Les tableaux de bord qui affichent “appels API” ou “lectures DB” ne vous disent pas quoi corriger. C'est plus simple si vous traduisez la dépense en actions produit réelles qu'un utilisateur effectue.
Faites une carte de coût simple
Notez la poignée d'actions qui sont autorisées à coûter de l'argent, et traitez tout le reste comme suspect tant que ce n'est pas justifié. Pour beaucoup de prototypes :
- Inscription et connexion (email, SMS, OAuth)
- Recherche et filtres
- Chat ou génération de contenu
- Rapports et exports
- Téléversements de fichiers et traitement
Attachez une attente approximative à chaque action : « un message de chat doit coûter moins de X », ou « un rapport doit prendre moins de Y secondes ». Pas besoin de chiffres parfaits. Il faut des cibles qui rendent le gaspillage évident.
Ensuite, séparez les coûts déclenchés par l'utilisateur des coûts toujours actifs.
Les coûts déclenchés par l'utilisateur n'arrivent que quand quelqu'un clique. Les coûts toujours actifs tournent même quand personne n'utilise l'app : cron jobs, workers de queue, polling en arrière‑plan, retries automatiques et “health checks” qui frappent des endpoints coûteux. Les coûts toujours actifs sont souvent le gain le plus rapide car ils peuvent brûler de l'argent 24/7.
Vérifiez aussi quel environnement dépense de l'argent. Les apps IA pointent souvent dev ou staging vers les mêmes services payants que la prod, ou laissent des workers de test tourner la nuit. Si vous ne pouvez pas dire clairement « ce coût est prod », supposez qu'une partie ne l'est pas.
Fixez votre objectif avant de toucher au code :
- Réduire 20% cette semaine (désactiver le plus gros gaspillage)
- Réduire 80% ce mois (revoir architecture, cache et accès aux données)
Un schéma courant : une fonctionnalité “rapport” est utilisée une fois par jour, mais une tâche d'arrière‑plan la génère toutes les 5 minutes pour chaque compte. Le tableau de bord montre “forte utilisation DB”, mais le vrai problème est une fonctionnalité que personne n'a demandée qui tourne constamment.
Étape par étape : inventairez endpoints, requêtes et jobs
L'objectif est d'arrêter de deviner. Vous voulez une carte de chaque endroit où votre app dépense de l'argent, liée à de vraies requêtes et de vrais travaux.
Choisissez un jour normal de trafic et traitez‑le comme votre baseline. Si vous n'avez pas beaucoup de trafic, utilisez un jour de tests internes où vous parcourez les principaux flux (inscription, paiement, recherche, chat, téléversements). Conservez cette baseline pour comparer après les changements.
Construire un inventaire sur une page
Parcourez l'app en trois groupes : endpoints, requêtes base de données et travail d'arrière‑plan.
- Endpoints
- Listez chaque route API (y compris les routes internes) et notez qui l'appelle : navigateur, appli mobile, cron, webhook ou un autre service.
- Ajoutez un volume approximatif et la latence. Les chiffres exacts sont top, mais “élevé/moyen/faible” et “rapide/lent” suffisent pour repérer les premiers problèmes.
- Requêtes
- Pour chaque endpoint, capturez les principales requêtes DB qu'il déclenche.
- Échantillonnez depuis les logs, le traçage ou la vue des requêtes lentes de votre DB, et décrivez la forme des requêtes (tables touchées, filtres, jointures).
- Travail d'arrière‑plan
- Écrivez chaque job planifié, handler de webhook et worker de queue.
- Indiquez à quelle fréquence il tourne et ce qu'il fait (sync, email, embeddings, nettoyage).
Rattachez tout à votre jour de baseline pour estimer le coût par 1 000 requêtes ou par utilisateur actif.
Quand vous avez cette liste, les motifs sautent aux yeux : un endpoint est appelé à chaque chargement de page, une “petite” requête scanne une grosse table, ou un job d'arrière‑plan tourne chaque minute même quand rien ne change.
Endpoints qui deviennent chers sans bruit
Certaines grosses fuites se cachent dans des endpoints “normaux” appelés toute la journée. Souvent le backend n'est pas coûteux par requête ; il l'est parce que la même requête arrive des centaines ou milliers de fois.
Un coupable fréquent est le polling : le frontend vérifie les mises à jour toutes les quelques secondes, même si rien ne change. Les boucles de rafraîchissement peuvent aussi arriver par accident, par exemple quand une page se rerend et déclenche un nouveau fetch, ou quand deux composants appellent le même endpoint sans le savoir. Si les utilisateurs laissent un onglet ouvert, cette boucle silencieuse devient un compteur constant.
Un autre motif est un endpoint qui fait trop de travail par requête. Le code généré par IA peut regrouper plusieurs lookups, jointures supplémentaires ou traitement de fichiers dans une seule route “par commodité”. Ça marche en démo, mais chaque appel déclenche une chaîne de requêtes DB et d'appels à des API externes.
Les routes principalement en lecture coûtent cher quand il n'y a pas de cache. Si un endpoint renvoie les mêmes données pour beaucoup d'utilisateurs (tarifs, réglages, liste de modèles), vous payez plusieurs fois les mêmes lectures.
Les retries multiplient rapidement les coûts. Si les timeouts sont trop courts, ou qu'il manque des limites de débit, les clients peuvent relancer agressivement. Vous payez double (ou plus) pour la même action.
Quelques signes qu'un endpoint mérite une attention en priorité :
- Il est appelé sur un timer (polling) ou à chaque frappe au clavier
- Il déclenche plusieurs appels en aval (DB plus APIs externes)
- Il renvoie souvent la même réponse mais n'a pas de cache
- Il timeout parfois et les clients relancent automatiquement
- Il n'a pas de rate limit, donc les pics se transforment en coûts élevés
Exemple : un endpoint /messages d'un prototype de chatbot est appelé toutes les 2 secondes pour vérifier de nouvelles réponses. De plus, il recalculer le contexte de conversation et frappe la base plusieurs fois. Corriger la fréquence d'appel et déplacer le travail lourd hors de la requête peut réduire immédiatement les coûts.
Requêtes qui font exploser le coût DB
La dépense DB provient souvent d'un petit nombre de requêtes exécutées bien plus souvent que vous ne le pensez. Le code généré par IA peut aussi masquer des inefficacités derrière un ORM, si bien que l'app semble correcte en test mais devient coûteuse en vraie charge.
Un des pires coupables est le pattern N+1 : vous récupérez une liste d'éléments, puis le code charge les données liées une ligne après l'autre dans une boucle. Une page affichant 50 commandes peut se transformer en 51 requêtes (ou 201 si chaque commande charge client et items), et chaque rafraîchissement répète le travail.
Les index manquants sont un autre multiplicateur courant. Si vous filtrez par user_id, created_at ou status, ou que vous joignez sur des clés étrangères, la DB ne doit pas scanner toute la table à chaque fois. Quand l'index manque, les coûts augmentent avec la taille des données, donc ça empire chaque semaine.
Surveillez aussi les requêtes qui extraient trop de données. Sélectionner toutes les colonnes, charger de gros blobs JSON, ou retourner des milliers de lignes alors que l'UI n'affiche que les 20 premières gaspille CPU, mémoire et réseau. Recherche, fils d'activité et tables admin sont des coupables fréquents, surtout quand la pagination est oubliée.
Cinq vérifications qui trouvent généralement les pires pics :
- Cherchez des lectures répétées dans des boucles (N+1) dans les logs ou traces
- Vérifiez que des index existent pour les filtres et clés de jointure courants
- Sélectionnez seulement les colonnes nécessaires, pas
SELECT * - Ajoutez pagination et limites strictes pour le scroll et la recherche
- Confirmez que le connection pooling est configuré pour ne pas ouvrir une connexion DB par requête
Exemple : un prototype de chatbot stocke les messages et “charge les 5 000 derniers” à chaque vue de page pour construire le contexte. Le changer pour ne récupérer que les 30 derniers messages, indexer conversation_id et regrouper les lookups liés réduit rapidement la charge DB.
Tâches d'arrière‑plan qui tournent plus que vous ne le pensez
Les tâches d'arrière‑plan sont une raison courante pour laquelle un prototype IA semble bon marché en test puis cher en production. Elles tournent quand personne n'utilise l'app et touchent souvent les parties les plus coûteuses de votre stack : APIs externes, base de données et stockage de fichiers.
Commencez par lister chaque job qui tourne sur un timer et notez son planning en langage clair. « Toutes les minutes » et « toutes les 5 minutes » sont des tueurs de budget courants, surtout si le job appelle des APIs payantes ou scanne de grosses tables.
Ensuite, cherchez les jobs qui tournent même quand il n'y a rien à faire. Un exemple typique est une tâche de « sync » qui vérifie des nouveautés mais récupère quand même des milliers de lignes ou appelle une API alors que rien n'a changé. De simples gardes avant les parties coûteuses suffisent souvent à arrêter la fuite.
Le fan‑out est l'autre multiplicateur silencieux. Un job planifié peut enchaîner en créant un job par utilisateur, par workspace ou par enregistrement. S'il tourne toutes les heures et que vous avez 2 000 utilisateurs, vous exécutez soudainement 48 000 jobs par jour.
Quelques corrections qui coupent souvent la dépense rapidement :
- Ajoutez un contrôle « pas de travail » (longueur de file, timestamp de dernière mise à jour ou un petit count) avant toute requête lourde ou appel API
- Limitez le fan‑out avec du batching (traiter 100 enregistrements à la fois) et backoff si le système est chargé
- Rendez les jobs idempotents pour que les retries ne répètent pas le travail coûteux (utilisez une clé unique de job ou un marqueur processed)
- Enregistrez dans les logs les comptes et durées : items traités, appels API effectués, lignes scannées, runtime total
Comment choisir les quelques correctifs qui coupent vite la dépense
Un audit ne sert que si il devient un plan court et ciblé. Le but n'est pas de tout rendre parfait, mais d'éliminer les quelques hotspots qui produisent la majeure partie de la facture.
Pour chaque changement candidat, notez deux choses : sa difficulté et combien il pourrait économiser. Restez léger pour décider vite.
- Ajouter des limites de requêtes aux endpoints coûteux (effort faible, économies élevées)
- Mettre en cache des réponses en lecture intense pendant 60 secondes (effort faible, économies moyennes à élevées)
- Ajouter un index DB sur une requête principale (effort moyen, économies élevées)
- Réduire la fréquence de polling dans un worker ou l'UI (effort faible, économies moyennes à élevées)
- Refactorer tout un module (gros effort, économies incertaines)
Priorisez les correctifs qui réduisent un des éléments suivants :
- Nombre d'appels API (moins de requêtes, moins de retries, réponses plus petites)
- Lignes scannées (requêtes plus rapides, moins de scans full table)
- Fréquence des jobs (moins de polling, moins d'exécutions planifiées)
Les garde‑fous rapides gagnent souvent en premier. Mettez un plafond sur les patterns abusifs (rate limits, timeouts, taille max de page). Ajoutez du cache pour les données qui ne changent pas toutes les secondes. Pour le travail d'arrière‑plan, passez de « vérifier toutes les minutes » à « exécuter quand nécessaire » ou à un planning plus long.
Utilisez une règle d'arrêt claire : livrez 2–3 changements, puis re‑mesurez pendant un jour (ou un cycle business normal). Si vous ne voyez pas une baisse significative, retournez à l'inventaire. Les gros refactors sont tentants mais ratent souvent le vrai driver de coût.
Exemple : si un chatbot prototype renvoie toute la conversation à chaque message, une petite modification comme résumer les anciens messages ou limiter l'historique peut réduire la dépense en tokens plus vite que de reconstruire toute la fonctionnalité de chat.
Exemple : un prototype de chatbot avec des coûts incontrôlés
Un cas courant : un prototype Lovable ou Bolt avec un écran de chat simple et un tableau de bord pour « usage » et « historique ». Ça marche en démo, mais la facture augmente plus vite que le nombre d'utilisateurs.
Voici le pattern. Chaque chargement de page déclenche plusieurs appels IA « au cas où » (résumés, suggestions, sentiment, génération de titre). En parallèle, le tableau de bord reconstruit des stats en scannant toute la table. Quelques testeurs actifs créent des centaines d'appels par heure et la base commence à effectuer des lectures lourdes qui ressemblent à des pics aléatoires.
Souvent il y a un coupable principal : un endpoint de chat qui refait des embeddings à chaque message, parfois plus d'une fois par requête. Il embed le texte utilisateur, ré‑embed les N derniers messages et re‑embed les mêmes morceaux de base de connaissance parce que rien n'est mis en cache. Si l'endpoint sauvegarde tout puis interroge immédiatement “tous les messages pour cet utilisateur” sans limites, le coût des requêtes augmente avec chaque conversation.
Les correctifs efficaces sont ennuyeux mais efficaces :
- Debounce des triggers UI pour qu'une action utilisateur fasse une requête, pas cinq
- Mettre en cache les embeddings et les réutiliser quand le texte n'a pas changé
- Ajouter pagination et limites à l'historique des messages et aux tables du dashboard
- Déplacer le travail IA “agréable à avoir” (titres, résumés) dans des jobs planifiés moins fréquents
- Ajouter des garde‑fous : timeouts, max tokens et rate limits par utilisateur
Le résultat attendu est moins d'appels par action utilisateur et une courbe de coût plus plate. Après ces changements, vous devriez pouvoir prédire la dépense à partir des utilisateurs actifs, au lieu d'être surpris par un seul après‑midi chargé.
Erreurs courantes à éviter pendant un audit des coûts
Un audit peut partir en sucette si vous le traitez comme un exercice de tableur au lieu d'une chasse aux quelques éléments qui génèrent la majeure partie de la facture. L'objectif n'est pas une mesure parfaite mais des économies rapides et sûres.
Un piège est de collecter beaucoup de métriques tout en manquant l'évidence. Les équipes suivent chaque route, chaque table, chaque tableau, puis n'agissent jamais sur les pires coupables. En pratique, vos 5 endpoints et 5 requêtes principaux expliquent souvent la majeure partie de la dépense.
Une autre erreur est d'optimiser la mauvaise couche. Vous pouvez accélérer une requête lente, mais si un job d'arrière‑plan l'appelle chaque minute (ou s'exécute deux fois à cause de retries), la facture ne bougera pas. Confirmez toujours ce qui déclenche le travail : actions utilisateurs, cron, webhooks, retries ou workers de queue.
Surveillez ces motifs d'échec :
- Vous désactivez une fonctionnalité pour couper les coûts, alors que le vrai problème est une boucle d'appels accidentelle ou un client qui poll trop souvent
- Vous optimisez une requête alors qu'un job d'export ou de sync exécute la même requête des milliers de fois
- Vous courez après des économies et cassez la cohérence (données partielles, écritures manquantes, cache périmé)
- Vous sautez les vérifications de sécurité et déployez des secrets exposés, une auth faible ou des risques d'injection
- Vous « corrigez » le coût en baissant les limites sans traiter pourquoi l'app les atteint
Exemple : une fonctionnalité “notifications” paraît coûteuse, elle est désactivée. Plus tard vous découvrez que le vrai coupable était un worker qui renvoyait le même lot parce que le job n'enregistrait jamais son checkpoint.
Checklist rapide : avant et après chaque changement
Considérez ceci comme une petite expérimentation : mesurez d'abord, changez une chose, puis mesurez à nouveau. Sinon vous risquez d'« économiser » sur le papier tout en cassant la connexion, en ralentissant les pages, ou en provoquant des retries qui coûtent encore plus.
Choisissez un jour baseline (ou une fenêtre de 24 heures typique) et notez vos chiffres au même endroit : dépense API totale, dépense DB et dépense workers, plus quelques principaux coupables.
Avant de changer le code, assurez‑vous de pouvoir répondre à :
- Quels sont les 3 endpoints principaux par coût et par volume (requêtes) ?
- Quelles sont les 3 requêtes principales par temps total ou lignes scannées ?
- Avez‑vous la liste complète des jobs planifiés, des queues et des cron tasks, avec leur fréquence ?
- Avez‑vous enregistré des chiffres “avant” pour une fenêtre baseline (dépense, latence, taux d'erreur, retries) ?
- Savez‑vous à quoi ressemble le « bon » pour les utilisateurs (temps de chargement, temps à la première réponse, taux de checkout ou de connexion réussi) ?
Après vos changements, revérifiez la même fenêtre et ajoutez deux contrôles : retries et expérience utilisateur. Un piège courant est de réduire le compute par requête mais d'introduire des 500, timeouts ou échecs d'auth qui déclenchent des retries automatiques. Un endpoint cassé peut doubler le trafic et les coûts sans nouveaux utilisateurs.
Vérifiez aussi que vous n'avez pas simplement déplacé le coût ailleurs (par ex. moins d'appels API mais des requêtes DB plus lourdes, ou moins de lectures DB mais plus de jobs d'arrière‑plan).
Prochaines étapes si votre prototype IA est difficile à démêler
Si votre audit dit « tout est cher », le problème est généralement le code, pas le cloud. Les projets générés par IA arrivent souvent avec un routage embrouillé, une logique copiée‑collée et des retries cachés. Avant d'optimiser ligne par ligne, faites un diagnostic rapide pour cartographier ce qui tourne réellement en production et comment les requêtes circulent.
Commencez par trouver les hotspots. Si vous avez 1–3 coupables clairs (un endpoint bruyant, une requête lente, un job suractif), un patch est souvent le gain le plus rapide. Si vous découvrez une douzaine de problèmes moyens dispersés dans de nombreux fichiers, vous passerez plus de temps à chasser des symptômes qu'à soigner la cause ; une petite refonte est souvent moins coûteuse.
Une règle simple :
- Patchez quand le fix est isolé et testable (limiter un endpoint, ajouter du cache, corriger un N+1)
- Refactorez quand le même pattern de bug se répète (chargement de données copié‑collé, plusieurs endpoints faisant le même travail, jobs s'appelant entre eux)
- Reconstruisez quand les bases sont cassées (auth instable, secrets exposés, architecture qui bloque les corrections sûres)
Si vous faites appel à de l'aide externe, la passation importe plus que de longues explications. Apportez une journée baseline (24 heures normales de trafic) et un petit pack de faits :
- Liste d'endpoints avec comptes de requêtes et pires coupables
- Top requêtes avec temps moyen et fréquence
- Liste des jobs d'arrière‑plan avec plannings et nombres d'exécutions réels
- Notes de déploiement récentes (quoi a changé quand la dépense a monté)
Si le code vient d'outils comme Lovable, Bolt, v0, Cursor ou Replit et qu'il est difficile de tracer ce qui appelle quoi, FixMyMess (fixmymess.ai) peut faire un audit de code gratuit pour cartographier endpoints, requêtes et jobs avant que vous ne touchiez quoi que ce soit. À partir de là, l'objectif est une remédiation simple : correction logique, renforcement de la sécurité, refactor et préparation au déploiement pour que le prototype se comporte comme un logiciel de production, pas une démo.
Questions Fréquentes
Ma facture prototype IA est élevée — que dois‑je vérifier en premier ?
Commencez par vérifier ce qui continue à dépenser de l'argent quand personne n'utilise activement l'app. Comparez une fenêtre tranquille pendant la nuit à une heure chargée, puis repérez un petit ensemble de points chauds : quelques endpoints avec un très grand nombre de requêtes, quelques requêtes de base de données qui dominent le temps total, et des tâches d'arrière-plan qui s'exécutent selon un calendrier serré. Si les coûts ne baissent pas pendant les heures « personne n'utilise », le gain le plus rapide vient généralement du travail toujours actif, pas des fonctionnalités utilisateur.
Comment définir une baseline avant de commencer à modifier le code ?
Choisissez une période normale de 24 heures et enregistrez les chiffres que vous pourrez vérifier facilement ensuite : dépenses API totales, dépenses DB et dépenses des workers, plus les principaux coupables par volume et latence. Le but n'est pas une comptabilité parfaite mais d'avoir un instantané « avant » pour savoir si vos changements ont réellement réduit le coût au lieu de le déplacer ailleurs.
Comment relier les dépenses cloud à une fonctionnalité réelle au lieu de métriques vagues ?
Transformez « usage » en actions utilisateur concrètes comme charger un tableau de bord, envoyer un message de chat, lancer un rapport ou téléverser un fichier. Puis surveillez ce que chaque action déclenche en production : requêtes émises, requêtes SQL exécutées, pics de jobs et appels à des services tiers. Quand une action simple déclenche une chaîne de travail surprenante, vous avez trouvé ce qu'il faut corriger ensuite.
Pourquoi le polling fait‑il exploser les coûts même avec peu d'utilisateurs ?
Le polling paraît inoffensif car chaque requête est petite, mais il tourne constamment et se multiplie selon les onglets ouverts et les utilisateurs. Si l'UI vérifie toutes les quelques secondes des mises à jour qui changent rarement, les coûts montent même si le produit est « idle ». La solution habituelle est de réduire ou supprimer le polling et de ne récupérer que lorsqu'il y a un changement effectif, ou quand l'utilisateur le demande explicitement.
Comment les retries et timeouts augmentent-ils silencieusement ma dépense ?
Les retries peuvent doubler ou tripler votre facture car vous payez plusieurs fois le même travail. Cela arrive quand les timeouts sont trop courts, que les erreurs ne sont pas gérées proprement, ou que les clients rejouent automatiquement sans limites. La correction consiste à utiliser des timeouts raisonnables, ajouter des limites de débit, rendre les requêtes idempotentes et s'assurer que les appels échoués n'entraînent pas de travail coûteux répété en aval.
Qu'est‑ce que le problème N+1 et comment le repérer ?
Le pattern N+1 survient quand votre code récupère une liste puis charge les données liées une ligne à la fois dans une boucle. Ça passe en test mais ça scale très mal et coûte vite cher. La solution pratique est de regrouper ces recherches pour qu'un affichage de page n'engendre pas des dizaines ou centaines de requêtes séparées.
Quand ajouter un index DB est‑il le meilleur correctif de coût ?
Si vous filtrez ou faites des jointures sur des champs comme user_id, created_at ou status et que la base scanne une grosse table à chaque fois, vous verrez des requêtes lentes qui empirent avec la croissance des données. Ajouter le bon index donne généralement une baisse directe et mesurable du temps de requête et de l'utilisation CPU. L'important est d'indexer selon ce que vos endpoints principaux filtrent et joignent réellement, pas ce qui semble important.
Pourquoi les jobs d'arrière-plan causent‑ils des dépenses pendant les heures d'inactivité ?
Parce qu'elles tournent même quand personne n'utilise l'app et touchent souvent les parties les plus coûteuses : DB, APIs payantes et stockage. Un job qui s'exécute chaque minute peut devenir une fuite 24/7, surtout s'il scanne beaucoup de lignes ou se déploie par utilisateur. Ajoutez une vérification « pas de travail » simple et stoppez le fan‑out inutile pour réduire rapidement la dépense sans toucher aux fonctionnalités visibles.
Comment décider entre patche, refactor ou rebuild ?
Commencez par des changements faciles à tester et qui réduisent un driver clair comme le nombre de requêtes, les lignes scannées ou la fréquence des jobs. Patchez quand le fix est isolé et vérifiable (limiter un endpoint, ajouter du cache, corriger un N+1). Refactorez quand le même motif d'erreur revient partout. Reconstruisez quand les bases (auth, gestion des secrets, architecture) empêchent des corrections sûres.
Que dois‑je remettre si je demande à quelqu'un de réparer un codebase généré par IA coûteux ?
Apportez une journée baseline (24 heures normales) et un petit dossier des éléments coûteux : quels endpoints sont bruyants, quelles requêtes sont lentes et fréquentes, quelles tâches s'exécutent trop souvent. Si le code provient d'outils comme Lovable, Bolt, v0, Cursor ou Replit et qu'il est difficile de tracer ce qui appelle quoi, FixMyMess peut démarrer par un audit de code gratuit puis remédier aux points chauds avec vérification humaine. La plupart des projets sont complétés en 48–72 heures, avec un taux de réussite élevé, l'objectif étant de rendre le code demo apte à la production sans factures surprises.